AI
T-GEMS: Text-Guided Exit Modules for Decreasing CLIP Image Encoder
|
The IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) is an annual flagship conference organized by IEEE Signal Processing Society. ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. It features a broad technical program showcasing the latest developments in research and technology, attracting thousands of professionals from both academia and industry. In this blog series, we highlight our research papers presented at ICASSP 2026. Below is a list of our contributions. #1. Whisper-Fest: Single-Channel Far-Field Enhanced Speech-to-Text Without Parallel Data #2. Triage Knowledge Distillation for Speaker Verification #4. DeMo-Pose: Depth-Monocular Modality Fusion for Object Pose Estimation #5. GalaxyEdit: Large Scale Image Editing Dataset with Enhanced Diffusion Adapter #6. ADORE: Asymmetric Relational Distillation with Reranking for Instance Level Image Retrieval #7. T-GEMS: Text-Guided Exit Modules for Decreasing CLIP Image Encoder #8. SmoGVLM: A Small, Graph-Enhanced Vision-Language Model #9. On the Importance of a Multi-Scale Calibration for Quantization #10. Differentially Private Clustered Federated Learning with Privacy-Preserving Initialization and Normality-Driven Aggregation #11. Self-Attention Decomposition for Training Free Diffusion Editing |
Introduction
In the rapidly evolving landscape of artificial intelligence, multimodal deep neural networks have become a key approach for bridging visual perception and language understanding. Models such as CLIP [1], ALIGN [2], and Florence [3] have demonstrated remarkable capabilities by projecting different modalities, including images and text, into a shared latent space where similarity can be computed through contrastive learning. However, this capability comes at a significant computational cost. As these models scale to meet real-world demands, their resource-intensive inference pipelines pose a major challenge for deployment on edge devices and in latency-sensitive applications.
The primary issue lies in the static inference process used by many large-scale multimodal architectures. In standard CLIP implementations, every input image passes through the full transformer stack regardless of its complexity. To address this inefficiency, researchers have turned to Early Exit (EE) methods [4], which add auxiliary classifiers at intermediate layers and allow models to stop computation once they are sufficiently confident. While Early Exit has proven effective for single-modality tasks, extending it to multimodal data remains challenging because multimodal models rely on alignment between image and text embeddings rather than on visual features alone.
In this post, we present our work, “T-GEMS: Text-Guided Exit Modules for Decreasing CLIP Image Encoder Size”. We investigate the semantic distributions present in intermediate layers of encoders such as CLIP and show how these distributions can be inferred from textual descriptions. We introduce Text-Guided Exit Modules (T-GEMs) and a rate-based regularizer to control encoder usage cost while preserving cross-modal performance. Specifically, our work analyzes how intermediate representations vary across classes with respect to the text embedding, introduces class-rate as a training regularizer, and designs a module that predicts intermediate image-encoder activations using only text embeddings.
Leveraging Text Guidance for Efficient Exits
To reduce computational load while maintaining performance, we developed a framework that integrates text guidance directly into the inference path of multimodal models such as CLIP. Our approach moves beyond simple sampling and confidence-based heuristics by modeling the statistical properties of intermediate-layer activations conditioned on class semantics. The core insight is that intermediate layers in encoders such as CLIP contain semantic distributions that can be inferred from textual descriptions.
Given an image $x$ and a text description $d$ corresponding to a class $c$, let $l^{ij}$ denote the output of the $j-$th neuron in the $i-$th intermediate layer. We aim to estimate the posterior probability $p_{x,d∼c} (l^{ij})$. Since activations in these models are often well approximated by Gaussian distributions [5], we impose a Gaussian prior. This reduces the problem to estimating the mean $(μ_c^{ij})$ and variance $(σ_c^{ij^2})$ for each class $c$, giving the distribution
$ p_{x,d∼c}(l^{ij}│x,d)∼N_c^{ij}(μ_c^{ij},σ_c^{ij^2}) $
Once these Gaussian parameters are estimated, we use them to perform classification at intermediate layers.
Rather than relying on a calibration set, which requires storing samples for each class, our preferred approach uses the text encoder to estimate distribution parameters without requiring sample images at inference time. This is accomplished through a learnable network called T-GEM, denoted by $Ψ^i$. The role of $Ψ^i$ is to map the output of the text encoder ($d_t$) directly to the Gaussian parameters:
$ Ψ^i(d_t,φ)=(μ^{i:},σ^{i:^2})∈ \Bbb R^{2×N} $
This learning-based approach contrasts with naïve sampling methods as shown in Fig. 1. To ensure that the module learns a discriminative space, we introduce an auxiliary component called Jumper, denoted by $J^i$. Jumper projects the intermediate-layer activation $l^{i:}$ into a more suitable representation, $ \tilde l^{i:}= J(l^{i:};φ) \Bbb R^K$, where $K≤N$. The architecture of both modules is depicted in Fig. 1.

Figure 1. Comparison between naive sampling vs. learning-based estimation for distribution parameters, T-GEM architecture $(Ψ^i)$ and Jumper module $(J^i)$.
A critical component of our methodology is the class-rate metric, denoted by $R_c^i$. Derived from the Gaussian assumption, this metric represents the “surprisal”, or information content, associated with observing a specific activation under a given class hypothesis. For each class $c$ and layer $i$, we compute
$ R_c^i= \frac {1}{N} \sum_{j=1}^N \left \lbrack log_2(σ_c^{ij^2})+ \frac {(l^{ij}-μ_c^{ij})^2}{2σ_c^{ij^2}} \right \rbrack $
Taking the minimum in our prediction rule, $y^i=\underset{\rm c}{\rm argmin} (R_c^i )$, means selecting the class that yields the greatest compression. To further improve discriminative capability, we combine the rate-based loss with a cross-modal similarity constraint, $L = L_r + L_s$. The rate loss ($L_r$) minimizes entropy to project representations into a discriminative space, while the similarity loss ($L_s$) encourages alignment between the text embedding and the projected image activation using cosine similarity. We optimize this combined loss with the Adam optimizer for 120 epochs, training both $Ψ^i$ and $J^i$ so that the intermediate layers become increasingly discriminative over time.
Performance Gains and Model Compression
In this section, we present experimental results comparing T-GEM modules with standard CLIP inference and sampling-based early-exit methods. Our experiments focus on image-classification tasks on the CIFAR-10 dataset using two model variants, ViT-B-32 and ViT-L-14. We evaluate both accuracy retention and computational efficiency to demonstrate the viability of static Early Exiting in multimodal settings.
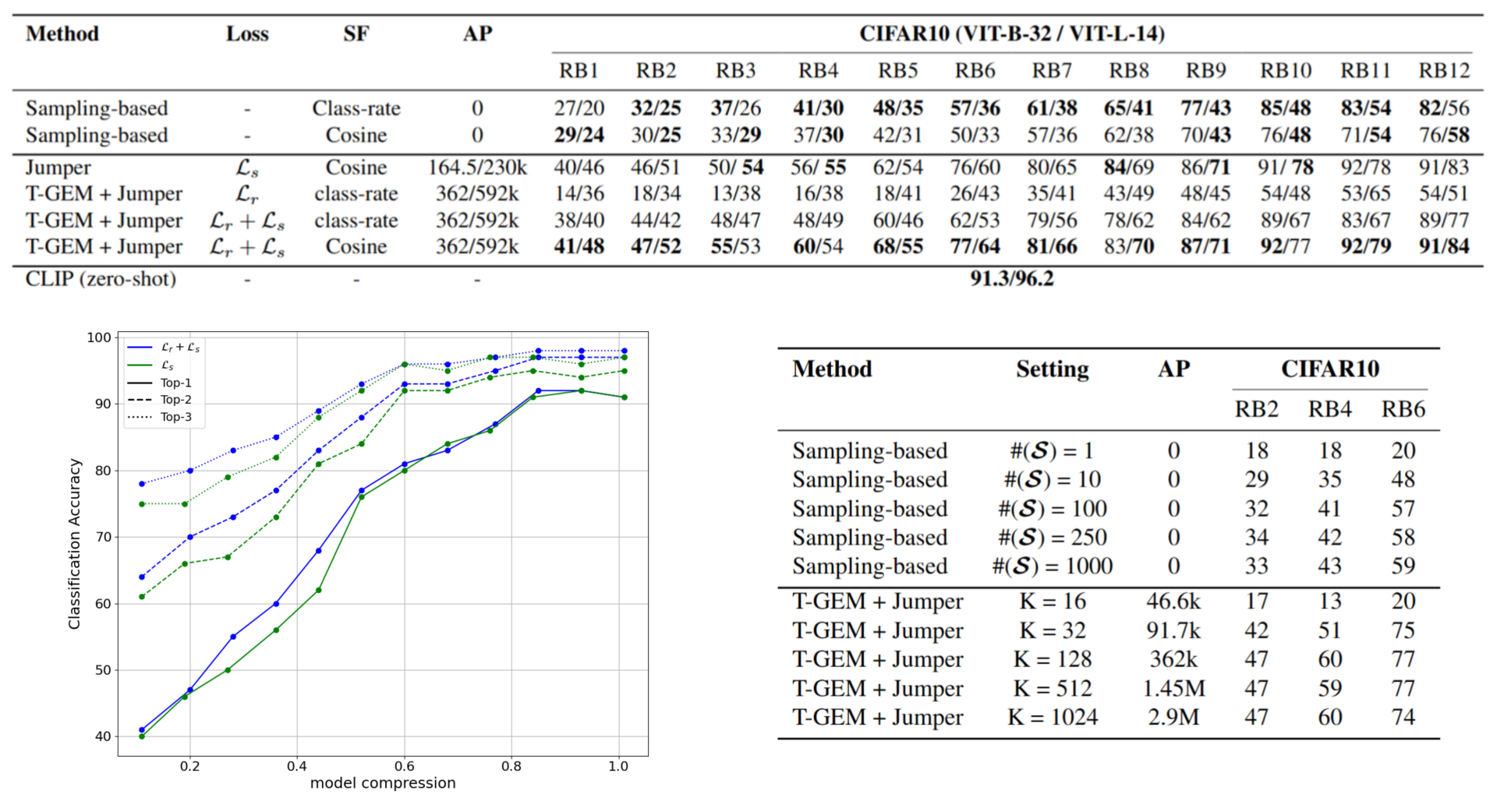
Figure 2. Consolidated results showing classification accuracy across residual blocks (RBs), model compression trade-offs, and sensitivity analysis for sampling size ( $\cal S$) and projection dimension ($K$).
Fig. 2 summarizes the classification accuracy achieved at different exit points relative to the full CLIP inference baseline, alongside sensitivity analyses for key hyperparameters. Our results show consistent performance gains for the learning-based approach over sampling-based methods, particularly in the early-to-middle stages of the network (RB3 to RB5). The T-GEM + Jumper method significantly outperforms naïve sampling techniques, which rely on a fixed calibration set. We also observed that incorporating the class-rate regularizer alongside cosine-similarity loss improves performance, with accuracy gains reaching up to 6% when the combined loss is used.
A primary goal of this research is to reduce the size of the image encoder without compromising semantic understanding. The results reveal a favorable trade-off: both the T-GEM module and the Jumper module add only a few hundred thousand parameters, representing approximately 4% of a single RB for ViT-B-32. Consequently, adding an EE module after the fifth layer yields an equivalent encoder with roughly 52 million fewer parameters while maintaining high accuracy. When examining top-{2, 3} accuracy, we found that even when our method does not immediately select the correct class, it often identifies plausible alternatives with high confidence. This behavior is valuable for applications such as clustering or conformal prediction.
We also investigated how robust our methods are to changes in hyperparameters. Reliable results for the sampling method required a reasonable amount of data per class ($\cal S ≥100 $), suggesting diminishing returns as the calibration set size increases. For the learning-based approach, performance stabilized at $ K=128 $, indicating that large models are not necessary for the exit modules to function effectively. These findings suggest that T-GEMs offer a practical path toward deploying lightweight multimodal models in resource-constrained environments while retaining the robustness of larger encoders.
Why This Matters
Our experimental results provide compelling evidence that intermediate layers in multimodal encoders such as CLIP retain substantial semantic value, even when accessed early in the network. By analyzing activation distributions and leveraging text guidance, we show that inference depth can be decoupled from image complexity without relying on dynamic, per-sample confidence scores. One of the most intriguing findings is the discriminative power of early layers: a preliminary “Oracle” experiment achieved 94% accuracy, with 53.6% of cases resolved before the sixth residual block. These results suggest that, for more than half of the inputs, full encoder processing is unnecessary.
The introduction of the class-rate regularizer was a pivotal design choice. Our results indicate that optimizing solely for cosine similarity is insufficient for training robust exit modules. By incorporating $L_r$, we encourage the model to project intermediate latent representations into a space in which semantic classes are more easily separated. This finding confirms that rate-based optimization serves as a strong proxy for information content in signal-compression settings.
The low parameter overhead of our method makes it well suited for edge deployment. With only 4% additional parameters relative to a single RB, T-GEMs effectively “shrink” the image encoder for task-specific use. Finally, our models' top-{2, 3} accuracy opens new application areas beyond standard classification. Even when the top-1 prediction is incorrect at an early exit point, the model often identifies plausible alternatives with high confidence, a property that is particularly valuable for tasks such as clustering and conformal prediction.
Conclusion
In this work, we introduced a practical approach for leveraging intermediate layers in multimodal models such as CLIP by using activation-rate computations across successive layers. Our method, based on Text-Guided Exit Modules (T-GEMs) and the Jumper module, achieves strong performance while reducing the size of the image encoder without compromising image-text similarity.
We demonstrated that static EE methods can be successfully applied to contrastive dual-encoder models using text guidance, representing a first step toward dynamic optimization in this domain. By predicting intermediate image-encoder activations based solely on text embeddings, we revealed a bounded relationship between modalities that enables effective exit decisions without per-sample calibration data. Furthermore, the introduction of the class-rate regularizer significantly improves the accuracy of EE modules by encouraging more discriminative representations during training.
While our current implementation focuses on static early exiting, there is significant room for further improvement. A natural next step is to convert this framework into a dynamic method in which a confidence score is computed for each sample, enabling the selection of the optimal intermediate layer for exit on a per-instance basis. The proposed rate-based EE method could also serve as a loss signal or training constraint for fine-tuning, or even for training lightweight multimodal encoders from scratch, rather than only pruning existing ones. By bridging the gap between computational efficiency and semantic fidelity, T-GEMs pave the way for faster, more accessible multimodal applications.
References
[1] Alec Radford, et al. “Learning transferable visual models from natural language supervision”, International Conference on Machine Learning (ICML), 2021.
[2] Chao Jia, et al. “Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”, International Conference on Machine Learning (ICML), 2021.
[3] Lu Yuan, et al. “Florence: A New Foundation Model for Computer Vision”, ArXiv, 2021.
[4] Surat Teerapittayanon, et al. “BranchyNet: Fast inference via early exiting from deep neural networks”, International Conference on Pattern Recognition (ICPR), 2016.
[5] David Peer, et al. “Improving the Trainability of Deep Neural Networks through Layerwise Batch-Entropy Regularization”, Trans. Mach. Learn. Res., 2022.




