AI
Differentially Private Clustered Federated Learning with Privacy-Preserving Initialization and Normality-Driven Aggregation
|
The IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) is an annual flagship conference organized by IEEE Signal Processing Society. ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. It features a broad technical program showcasing the latest developments in research and technology, attracting thousands of professionals from both academia and industry. In this blog series, we highlight our research papers presented at ICASSP 2026. Below is a list of our contributions. #1. Whisper-Fest: Single-Channel Far-Field Enhanced Speech-to-Text Without Parallel Data #2. Triage Knowledge Distillation for Speaker Verification #4. DeMo-Pose: Depth-Monocular Modality Fusion for Object Pose Estimation #5. GalaxyEdit: Large Scale Image Editing Dataset with Enhanced Diffusion Adapter #6. ADORE: Asymmetric Relational Distillation with Reranking for Instance Level Image Retrieval #7. T-GEMS: Text-Guided Exit Modules for Decreasing CLIP Image Encoder #8. SmoGVLM: A Small, Graph-Enhanced Vision-Language Model #9. On the Importance of a Multi-Scale Calibration for Quantization #10. Differentially Private Clustered Federated Learning with Privacy-Preserving Initialization and Normality-Driven Aggregation #11. Self Attention Decomposition for Training Free Diffusion Editing |
Introduction
Federated learning (FL) enables training of shared models across distributed edge devices while keeping raw data on-device. Despite this, recent research has shown that FL can still leak private user information through exchanged model updates. To protect against this, it is often coupled with methods such as differential privacy (DP). However, in realistic cross-device deployments, data is highly heterogeneous (non-IID), which causes vanilla FL to converge slowly. The situation deteriorates further when DP is imposed: the added DP noise amplifies the impact of data heterogeneity, exacerbating the performance degradation caused by non-IID data.
Clustered Federated Learning (CFL) mitigates this by segregating users into clusters, but coupling CFL with DP remains challenging because the injected DP noise makes client updates excessively noisy. This makes it difficult for the server to initialize cluster centroids or preserve the cluster structure.
To address this challenge, we propose PINA, a two-stage framework that first lets each client fine-tune a lightweight low-rank adaptation (LoRA) adapter and privately share a small subset of the update. The server leverages these sketches to construct robust cluster centroids. In the second stage, PINA introduces a novel model update scaling mechanism that improves convergence and robustness. We believe that these advancements bring clustered FL closer to practical adoption.
Method
Our proposed method, PINA, consists of two stages: (1) Cluster Model Initialization and (2) Clustered Model Training. The workflow of PINA is outlined in Figure 1 and Figure 2.
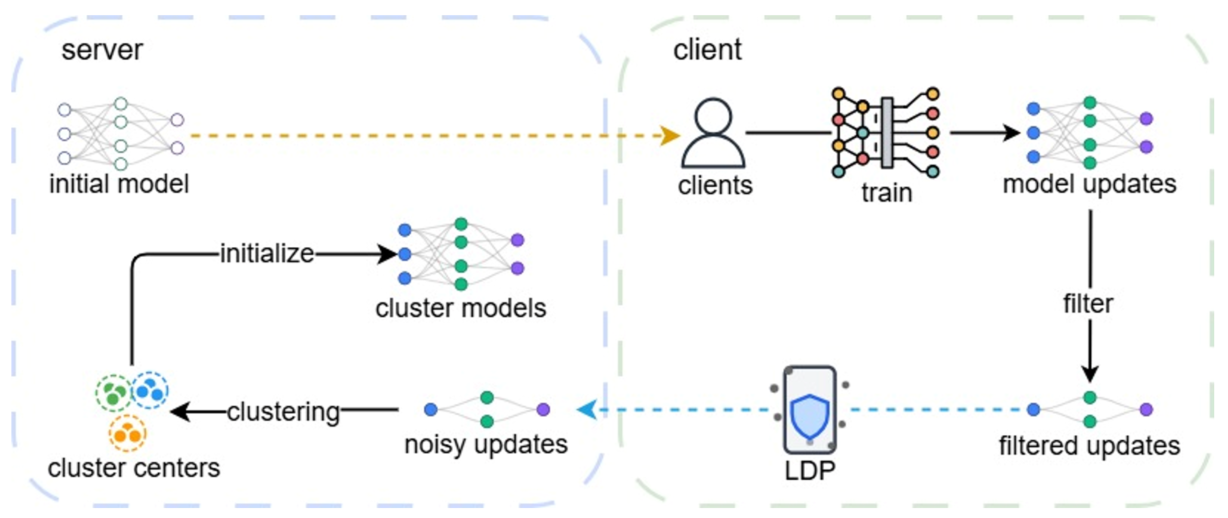
Figure 1. Stage 1 of PINA. Global cluster models are initialized in a privacy-preserving manner.
In the initialization stage, we use pre-trained transformer-based models. Clients apply LoRA with a small rank (r=1) to the value projection matrix of the last attention layer. This significantly reduces the number of trainable parameters. Each sampled client then applies Local Differential Privacy (LDP) to the model updates, specifically to the largest positive/negative values and setting the rest to zero. These vectors with limited non-zero values are then shared with the server, which runs a clustering algorithm to obtain initial cluster models. Since the server requires individual updates for clustering, LDP is essential to preserve privacy. By minimizing the number of non-zero values transmitted, we maximize the signal-to-noise ratio, thereby enabling the server to derive meaningful clustering results.
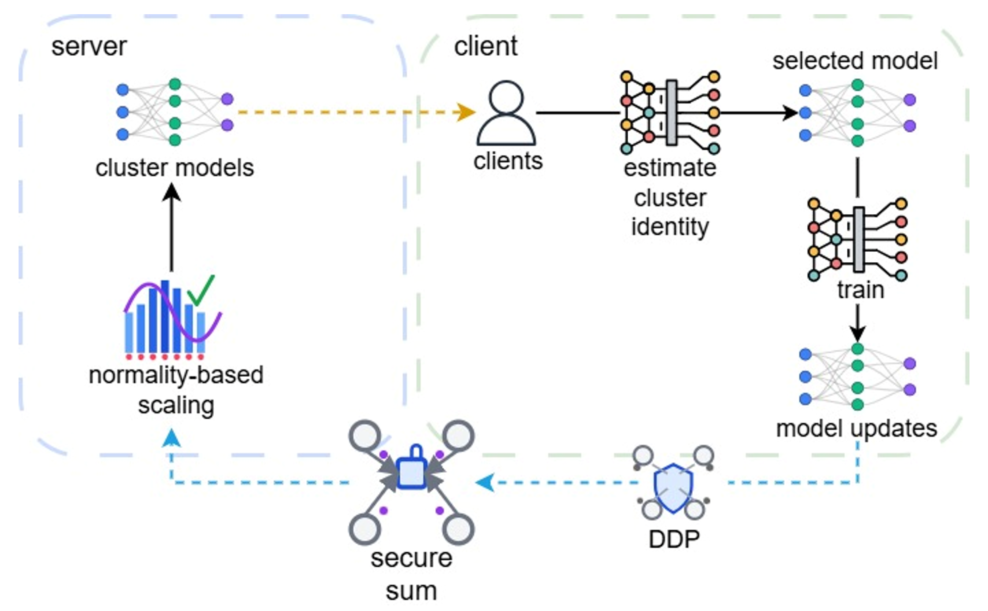
Figure 2. Stage 2 of PINA with normality-based update scaling.
In the training stage, clients perform cluster identification based on training loss and train the selected cluster model on local data. Updates are clipped, noised and aggregated using a secure sum protocol (e.g., SecAgg) with Distributed DP (DDP), ensuring the server only has access to aggregated noisy updates. A key innovation is the "normality-driven aggregation" mechanism. After receiving aggregated noisy updates, the server scales the magnitude of each aggregate. For early training, this is done by scaling to the smallest ℓ2 norm. For later rounds, we scale updates based on their normality, estimated via the Shapiro-Wilk test statistic:
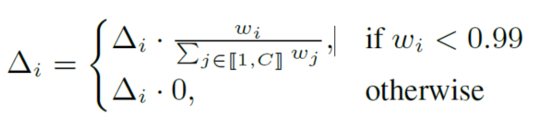
This scaling mechanism addresses imbalanced client contributions by restoring the intended ℓ2 norm of updates to global cluster models. Since some clusters may be chosen by only a few clients, their aggregated updates experience significantly reduced magnitudes, leading to slow convergence. Our scaling mechanism restores the intended ℓ2 norm of the updates to global cluster models, improving both the robustness and fairness of the framework.
Experiments
We use privacy budgets of ϵ ∈ {2, 8} where smaller values correspond to stricter privacy constraints, and simulate a cohort of 10,000 clients. Experiments are run on rotated CIFAR-10 (C = 2), rotated FMNIST (C = 4), and FEMNIST (C = 2), with C denoting the number of clusters. We use a 22M-parameter ViT-Small model pre-trained on ImageNet-21k and compare our algorithm with state-of-the-art (SOTA) methods including FedAvg, FedProx, FedNova, and IFCA.
Results
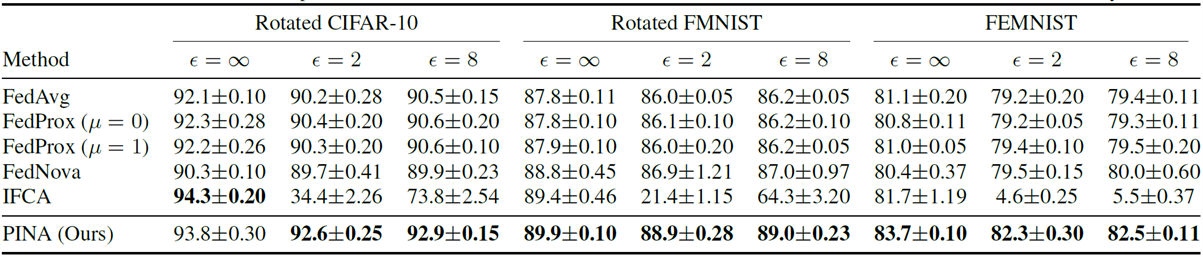
Table 1. Results and comparisons on rotated CIFAR-10, rotated FMNIST and FEMNIST. We boldface the best accuracy.
Table 1 shows results for different methods with non-private FL (ϵ = ∞) and DP-FL (ϵ ∈ {2, 8}). The results demonstrate that PINA consistently outperforms SOTA methods across all three datasets. In particular, for ϵ = 2, PINA achieves up to 2.9%, 2.9%, and 3.1% improvements on rotated CIFAR-10, rotated FMNIST, and FEMNIST, respectively. Notably, the improvements are most pronounced on the naturally non-IID dataset FEMNIST, highlighting the ability of our proposed method to handle real-world data heterogeneity.
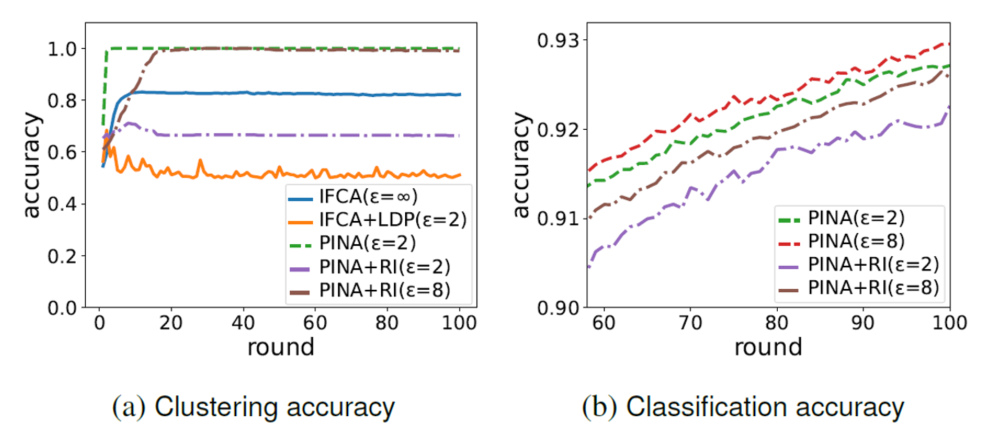
Figure 3. Comparison of clustering and classification accuracy on CIFAR-10. PINA+RI denotes our proposed method with random initialization.
Ablation studies (Figure 3a) illustrate that our method achieves optimal clustering with a stringent privacy budget of ϵ = 2. In contrast, incorporating LDP into standard IFCA throughout the entire training process has a detrimental effect on the clustering structure. Furthermore, as shown in Figure 3b, our novel initialization mechanism enables the algorithm to converge to the optimal clustering structure significantly faster than random initialization.
Conclusion
In this blog post, we present PINA, a privacy-preserving clustered FL framework that effectively mitigates data heterogeneity in DP-FL. By combining privatized client sketches for robust initialization and a normality-driven aggregation mechanism that accounts for imbalanced contributions, PINA achieves superior performance on non-IID data without requiring server-side privileged data or random restarts. Extensive experiments show that PINA consistently outperforms SOTA DP-FL methods under non-IID settings, achieving an average improvement of 2.9% in test accuracy.
References
[1] Brendan McMahan, EiderMoore, Daniel Ramage, Seth Hampson, et al., “Communication-efficient learning of deep networks from decentralized data,” in Annual Conference on Artificial Intelligence and Statistics, 2017.
[2] H Brendan McMahan, Daniel Ramage, Kunal Talwar, and Li Zhang, “Learning differentially private recurrent language models,” in Proceedings of International Conference on Machine Learning, 2018.
[3] Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith, “Calibrating noise to sensitivity in private data analysis,” in Theory of Cryptography, 2006.
[4] Tian Li, Anit Kumar Sahu, Ameet Talwalkar, and Virginia Smith, “Federated learning: Challenges, methods, and future directions,” in IEEE Signal Processing Magazine, 2020.
[5] Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, et al., “Practical secure aggregation for privacypreserving machine learning,” in ACM Conference on Computer and Communications Security, 2017.
[6] Avishek Ghosh, Jichan Chung, Dong Yin, and Kannan Ramchandran, “An efficient framework for clustered federated learning,” in Advances in Neural Information Processing Systems, 2020.





