AI
Triage Knowledge Distillation for Speaker Verification
|
The IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) is an annual flagship conference organized by IEEE Signal Processing Society. ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. It features a broad technical program showcasing the latest developments in research and technology, attracting thousands of professionals from both academia and industry. In this blog series, we highlight our research papers presented at ICASSP 2026. Below is a list of our contributions. #1. Whisper-Fest: Single-Channel Far-Field Enhanced Speech-to-Text Without Parallel Data #2. Triage Knowledge Distillation for Speaker Verification #4. DeMo-Pose: Depth-Monocular Modality Fusion for Object Pose Estimation #5. GalaxyEdit: Large Scale Image Editing Dataset with Enhanced Diffusion Adapter #6. ADORE: Asymmetric Relational Distillation with Reranking for Instance Level Image Retrieval #7. T-GEMS: Text-Guided Exit Modules for Decreasing CLIP Image Encoder #8. SmoGVLM: A Small, Graph-Enhanced Vision-Language Model #9. On the Importance of a Multi-Scale Calibration for Quantization #10. Differentially Private Clustered Federated Learning with Privacy-Preserving Initialization and Normality-Driven Aggregation #11. Self-Attention Decomposition for Training Free Diffusion Editing |
Introduction
Speaker verification (SV) is the task of determining whether two speech utterances belong to the same speaker. Recent advances have been driven by high-capacity deep neural networks trained on large-scale datasets. However, these large models present a significant challenge for real-time, on-device deployment due to their substantial computational and memory requirements.
Knowledge distillation (KD) [1] offers a practical solution: a compact student network is trained to replicate the behavior of a larger teacher network by matching its soft posterior distributions. Through this process, the student inherits the teacher's generalization ability and its "dark knowledge" — fine-grained inter-class similarities and decision-boundary structure that are not captured by hard labels alone.
In this blog, we introduce Triage Knowledge Distillation (TRKD), a novel distillation framework that operationalizes the medical triage principle — assess, prioritize, focus — to selectively transfer the most informative knowledge from teacher to student. We show that TRKD consistently outperforms existing KD methods across diverse teacher–student architectures on the VoxCeleb benchmark.
Background: Limitations of Existing KD
Classical KD minimizes a single KL divergence between teacher and student posteriors over all classes. This single objective entangles two distinct supervision signals: (1) the teacher's confidence in the ground-truth class (reflecting sample difficulty), and (2) the relational structure among non-target classes (reflecting inter-class similarities). When the teacher is highly confident, the target class dominates, suppressing the informative non-target structure.
Decoupled KD (DKD) [2] addresses this by decomposing the loss into two separate terms: target-class KD (TCKD), which transfers per-example difficulty, and non-target-class KD (NCKD), which transfers relational structure among remaining classes. However, DKD still treats all non-target classes uniformly.
In large-scale classification tasks (e.g., SV with thousands of speakers), the teacher's probability mass concentrates on the target and a few confusable impostors, leaving a long tail of near-zero probabilities. Aligning the student to this entire long tail dilutes supervision: individually negligible classes carry little information yet their accumulated gradients impede optimization.
Grouped KD (GKD) [3] mitigates this by transferring only a high-probability subset of non-target classes, but it relies on a static cutoff and does not adapt supervision scope during training.
Proposed Method: Triage KD (TRKD)
We propose Triage KD (TRKD), which applies the medical triage principle — assess, prioritize, focus — to knowledge distillation, building on difficulty-aware curricula [15] and selective supervision [16]:
Figure 1 illustrates the conceptual difference between the three KD paradigms. Classical KD aligns the full distribution; DKD separates target and non-target terms; TRKD further partitions the non-target mass into a confusion-set and a background-set, focusing supervision on the most confusable classes while discarding long-tail noise.
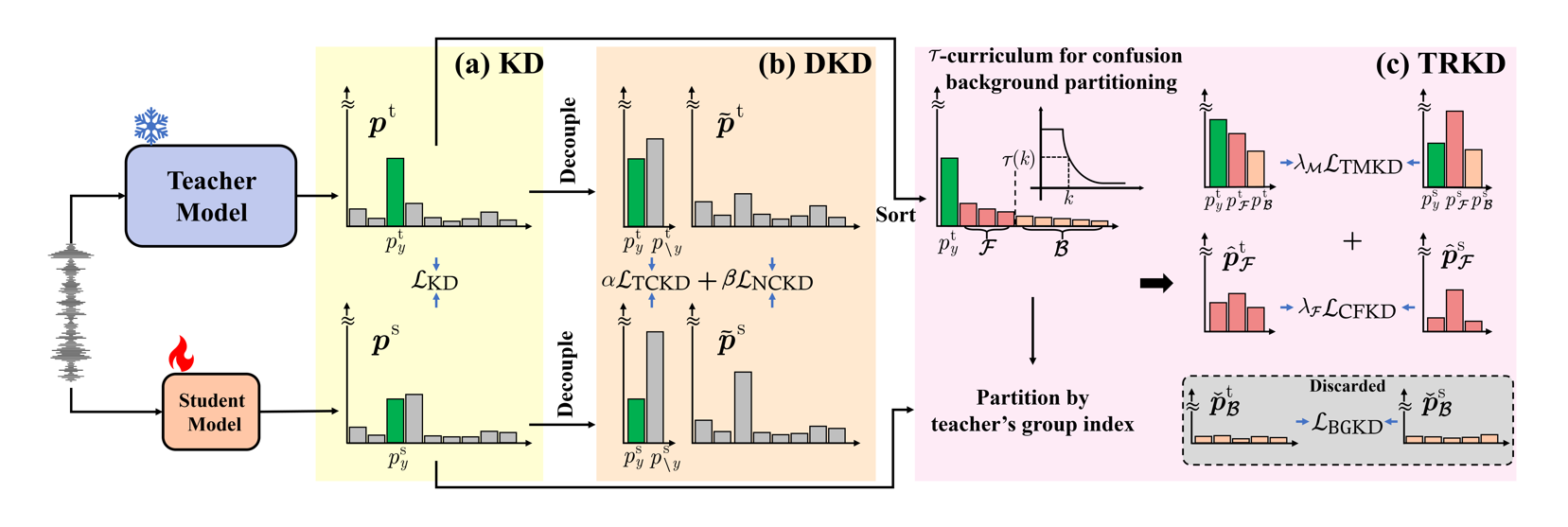
Figure 1. Comparison of KD vs. DKD vs. TRKD. (a) Classical KD aligns teacher and student posteriors via a single KL divergence. (b) DKD decouples the loss into target and non-target terms. (c) TRKD partitions probabilities into three masses (target, confusion-set, background-set) and shrinks the confusion-set via a cumulative-probability cutoff τ(k) that decreases during training.
Three-Mass Partition and Loss Design
At each training step, the cutoff τ determines the partition. We sort non-target classes in descending order of teacher probability and define the confusion-set ℱ as the smallest subset whose cumulative probability exceeds τ. The remaining non-target classes form the background-set ℬ.
This partition enables a two-level decomposition of the classical KL divergence into three components:
The final TRKD objective combines the three-mass and confusion-set terms with fixed weights λM and λℱ:
ℒTRKD = λM · ℒTMKD + λℱ · ℒCFKD
The overall training loss is the sum of the standard AAM-Softmax [14] classification loss and the TRKD loss.
τ-Curriculum Scheduling
A key insight behind TRKD is that the scope of non-target supervision should evolve during training. Enforcing fine-grained alignment over a small confusion-set too early can overwhelm the student and destabilize training (we observed training divergence when τ was fixed at a small value). Conversely, keeping a large confusion-set throughout training dilutes later-stage supervision.
TRKD addresses this with an exponential curriculum schedule on τ: τ starts at τ_init = 1.0 (equivalent to DKD — all non-targets in the confusion-set) and exponentially decays to τ_final = 0.05 between training epochs 10 and 60. This stabilizes the student's optimization in early training and sharpens decision boundaries later, without requiring any architectural changes or additional data.
Experimental Setup
Datasets and evaluation. All models were trained on the VoxCeleb2 [12] development set and evaluated on VoxCeleb1 [13] original (O), extended (E), and hard (H) trials. Performance was measured using Equal Error Rate (EER, %).
Architectures. To assess generality, we explored diverse teacher–student pairs spanning ECAPA-TDNNs [4], ResNets [5], ReDimNets [6], CAM++ [7], X-vector [8], MobileNetV2 [9], SAM-ResNet[10], and Res2Net[11] — covering both homogeneous (same architecture family) and heterogeneous (cross-architecture) transfer scenarios.
Baselines. TRKD was compared against embedding-level methods (MSE, Cosine distance) and logit-level methods (classical KD, DKD, and Grouped KD). We set the softmax temperature to 4 for logit-based methods, and used λM = 1, λℱ = 8 for TRKD.
Training details. All models were trained for 150 epochs with batch size 512 on 4×A100 GPUs using SGD with momentum 0.9. Learning rate was linearly warmed up from 0 to 0.1 over 6 epochs, then exponentially decayed to 5×10⁻⁵. Additional training details followed the WeSpeaker [17] pipeline.
Results
We validated TRKD across six different teacher–student pairings, covering both homogeneous and heterogeneous transfer scenarios. Table 1 summarizes the EER (%) results on VoxCeleb1.
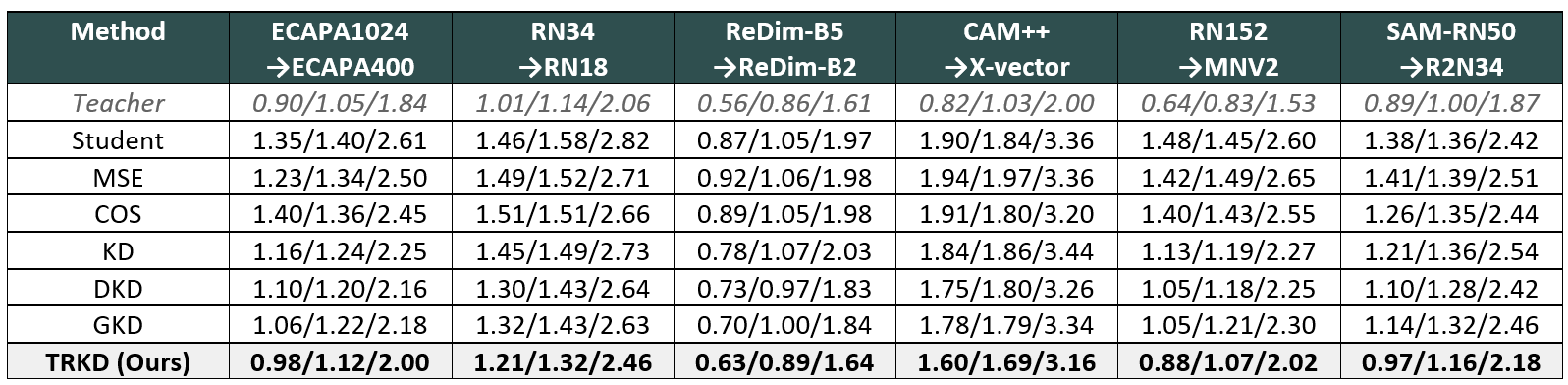
Table 1. VoxCeleb1 EER (%) for O/E/H trials across six teacher→student pairs. TRKD achieves the lowest EER on all 18 evaluations.
Key observations:
Figure 2 further isolates the effect of student capacity by fixing the teacher at ReDimNet-B5 and varying the student across ECAPA-TDNN and ResNet families.
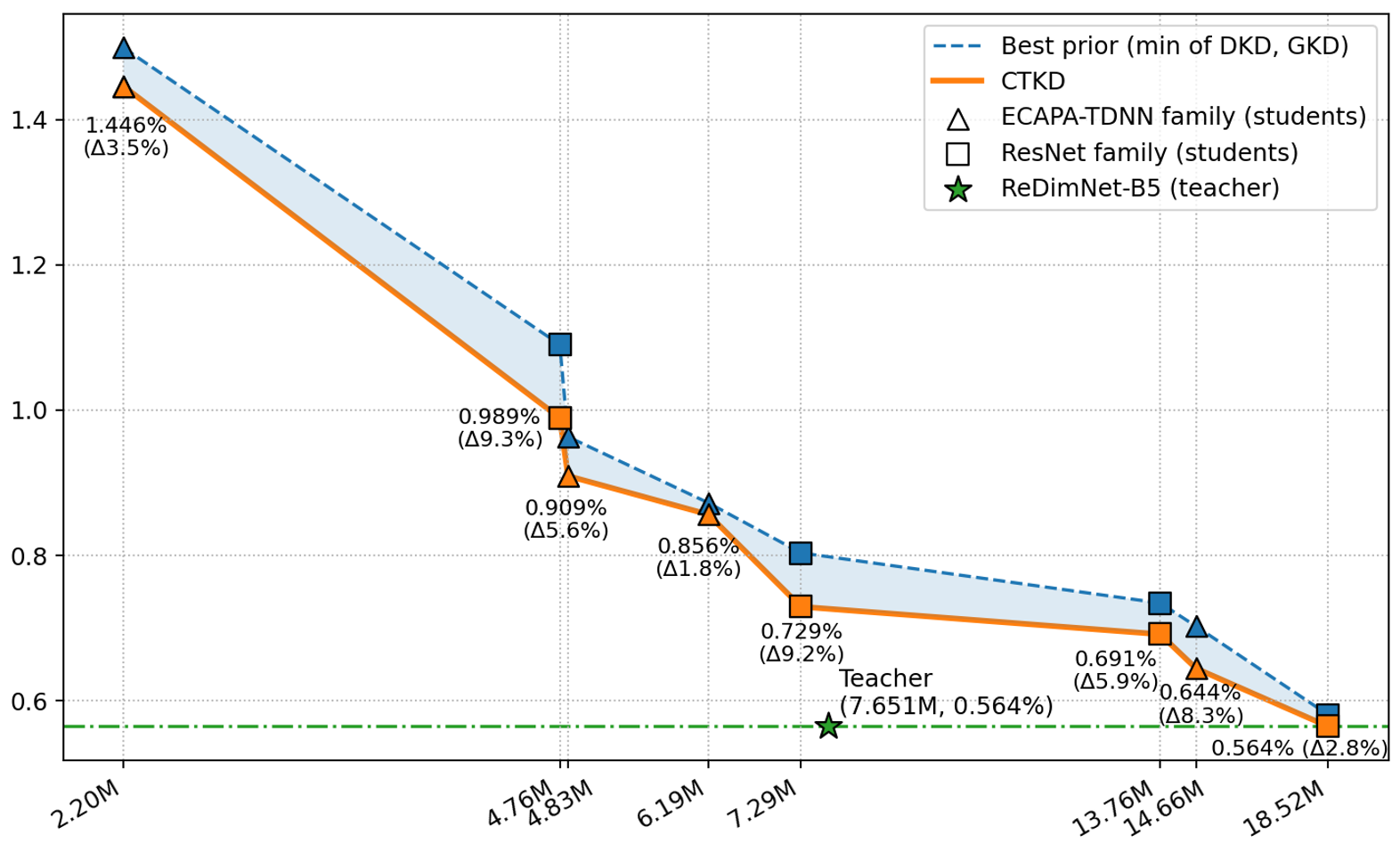
Figure 2. EER (%) versus student parameter count (log scale). The teacher is fixed at ReDimNet-B5. TRKD (solid line) consistently improves over the best prior method (dashed line) across all model scales, with gains of 2–9% (macro-average ≈ 5.8%).
Key findings:
Ablation Study
We conducted an ablation study on VoxCeleb1-O (ReDimNet-B5 → ReDimNet-B2) to disentangle the contributions of each TRKD component. Table 2 summarizes the results.
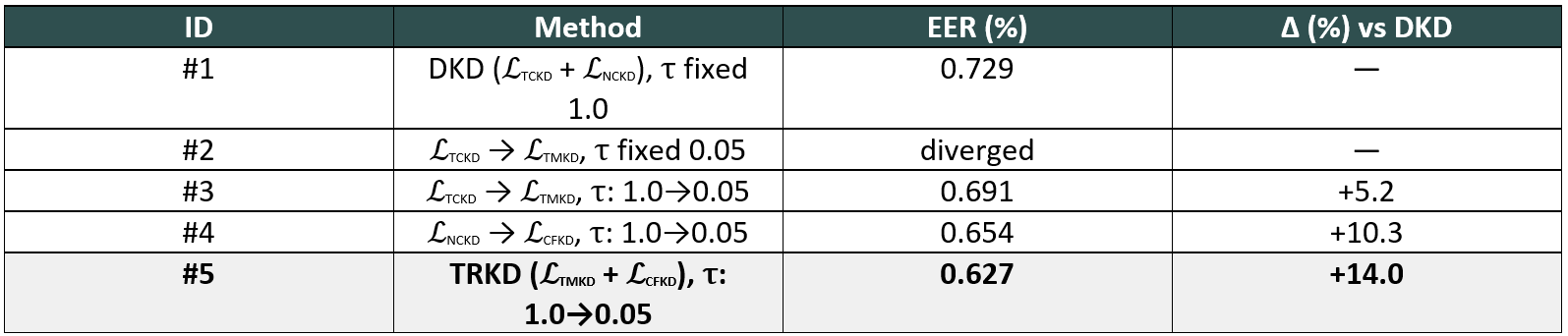
Table 2. Ablation of TRKD components on VoxCeleb1-O (ReDimNet-B5 → ReDimNet-B2). DKD is algebraically equivalent to TRKD with a fixed τ = 1.0.
Key takeaways from the ablation:
Conclusion
This blog introduced Triage Knowledge Distillation (TRKD) for speaker verification — a distillation framework built on the assess–prioritize–focus triage principle. By combining a coarse three-mass alignment with a fine-grained confusion-set conditional, and scheduling the cumulative-probability cutoff τ via a curriculum, TRKD stabilizes training and concentrates supervision on the most confusable impostors while suppressing long-tail noise.
In comprehensive experiments on VoxCeleb with six diverse teacher–student pairs, TRKD attained the lowest EER across all 18 evaluations and achieved an average relative improvement of 18.7% compared to students trained without KD. Ablation studies confirmed that (i) a τ-curriculum is critical for stability, and (ii) the three-mass and confusion-set terms provide complementary gains.
Future work will explore extending TRKD to variable-length and far-field speaker verification and applying the framework to other domains such as computer vision and natural language processing.
References
[1] G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” in NIPS 2014 Deep Learning and Representation Learning Workshop, 2014.
[2] B. Zhao, Q. Cui, R. Song, Y. Qiu, and J. Liang, “Decoupled knowledge distillation,” in IEEE/CVF conference on computer vision and pattern recognition, 2022.
[3] W. Zhao, X. Zhu, K. Guo, X.-Y. Zhang, and Z. Lei, “Grouped knowledge distillation for deep face recognition,” in AAAI Conference on Artificial Intelligence, 2023.
[4] B. Desplanques, J. Thienpondt, and K. Demuynck, “Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification,” in Interspeech 2020, 2020.
[5] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in IEEE/CVF conference on computer vision and pattern recognition, 2016.
[6] I. Yakovlev, R. Makarov, A. Balykin, P. Malov, A. Okhotnikov, and N. Torgashov, “Reshape dimensions network for speaker recognition,” in Interspeech 2024, 2024.
[7] H. Wang, S. Zheng, Y. Chen, L. Cheng, and Q. Chen, “Cam++: A fast and efficient network for speaker verification using context-aware masking,” in Interspeech 2023, 2023.
[8] D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudanpur, “X-vectors: Robust dnn embeddings for speaker recognition,” in 2018 IEEE international conference on acoustics, speech and signal processing, 2018.
[9] M. Sandler, A. Howard,M. Zhu, A. Zhmoginov, and L.-C. Chen,“Mobilenetv2: Inverted residuals and linear bottlenecks,” in
IEEE/CVF conference on computer vision and pattern recognition, 2018.
[10] X. Qin, N. Li, C. Weng, D. Su, and M. Li, “Simple attention module based speaker verification with iterative noisy label
detection,” in ICASSP 2022-2022 IEEE international conference on acoustics, speech and signal processing, 2022.
[11] S.-H. Gao, M.-M. Cheng, K. Zhao, X. Zhang, M.-H. Yang, and P. Torr, “Res2net: A new multi-scale backbone architecture,” IEEE
transactions on pattern analysis and machine intelligence, vol. 43, no. 2, pp. 652–662, 2019.
[12] J. S. Chung, A. Nagrani, and A. Zisserman, “Voxceleb2: Deep speaker recognition,” Interspeech 2018, 2018.
[13] A. Nagrani, J. S. Chung, and A. Zisserman, “Voxceleb: A large-scale speaker identification dataset,” in Interspeech 2017, 2017.
[14] J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” in IEEE/CVF conference on computer vision and pattern recognition, 2019.
[15] Y. Bengio, J. Louradour, R. Collobert, and J.Weston, “Curriculum learning,” in International conference on machine learning, 2009.
[16] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Doll´ar, “Focal loss for dense object detection,” in IEEE international conference on
computer vision, 2017.
[17] H.Wang, C. Liang, S.Wang, Z. Chen, B. Zhang, X. Xiang, Y. Deng, and Y. Qian, “Wespeaker: A research and production oriented
speaker embedding learning toolkit,” in ICASSP 2023-2023 IEEE international conference on acoustics, speech and signal processing, 2023.




