AI
GalaxyEdit: Large Scale Image Editing Dataset with Enhanced Diffusion Adapter
|
The IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) is an annual flagship conference organized by IEEE Signal Processing Society. ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. It features a broad technical program showcasing the latest developments in research and technology, attracting thousands of professionals from both academia and industry. In this blog series, we highlight our research papers presented at ICASSP 2026. Below is a list of our contributions. #1. Whisper-Fest: Single-Channel Far-Field Enhanced Speech-to-Text Without Parallel Data #2. Triage Knowledge Distillation for Speaker Verification #4. DeMo-Pose: Depth-Monocular Modality Fusion for Object Pose Estimation #5. GalaxyEdit: Large Scale Image Editing Dataset with Enhanced Diffusion Adapter #6. ADORE: Asymmetric Relational Distillation with Reranking for Instance Level Image Retrieval #7. T-GEMS: Text-Guided Exit Modules for Decreasing CLIP Image Encoder #8. SmoGVLM: A Small, Graph-Enhanced Vision-Language Model #9. On the Importance of a Multi-Scale Calibration for Quantization #10. Differentially Private Clustered Federated Learning with Privacy-Preserving Initialization and Normality-Driven Aggregation #11. Self-Attention Decomposition for Training Free Diffusion Editing |
Introduction
Have you ever wished you could easily add or remove objects in your photos—like adding a candle on the top of your birthday cake, or removing that background person from your photo? Modern AI models, called diffusion models, are really good at these kinds of advanced image edits. But teaching these models to edit images well requires a lot of high-quality examples, which are expensive and time-consuming to make by hand.

Figure 1. Visual illustration of our proposed model outputs
To solve this, we created GalaxyEdit, a large dataset for instruction-based image editing, where each photo comes with multiple natural language instructions for adding or removing objects from an image. What makes GalaxyEdit special is that it was created using a completely automated pipeline—no human labelling is needed. This not only makes it much faster and cheaper to build, but also allows us to include a wide variety of objects, positions, and descriptions, as well as multiple objects edited at the same time.
Most existing datasets have limits—they usually show only one object being edited at a time, or the instructions are simple and repetitive. GalaxyEdit overcomes this by providing multiple ways to describe the same edit, like “add a dog to the left of blue couch” and “add a puppy sitting left of the blue sofa”. This makes AI models trained on GalaxyEdit much more flexible and realistic in following human instructions.
Editing images with AI is tricky because the model must apply the requested changes—like adding or removing objects—while keeping the rest of the image intact. A common approach is to fine-tune the main model, but this can be slow and may cause the model to forget what it already knows. Another approach uses a control network on top of main network to guide the edits without changing the main model. Existing methods, like ControlNet-xs [8], let information flow between the main network and the control network, but they can overload the control network, which has to handle both the input and the communication between networks. To address this, we developed ControlNet-Vxs, a lightweight adapter that uses Volterra Neural Network (VNN) layers as non-linear bridges between networks. These layers allow richer information exchange, capturing more complex relationships and significantly improving the accuracy and realism of image edits.
In this work, we make three key contributions:
1.) We present GalaxyEdit, a large-scale dataset designed for instruction-based image editing, enabling a wide variety of add and remove instructions.
2.) We propose ControlNet-Vxs, a new variant of ControlNet-xs that uses VNN layers to enable high-capacity information exchange between the control network and the main model, improving edit fidelity.
Background
Image editing methods can be broadly categorized into mask-based approaches [1], [2], that require explicit object masks and mask-free, instruction-driven approaches [10], [11], [4]. Recent efforts [12], [7], [13], [8] have further explored control-guided generation, where pre-trained diffusion models are modulated by image-based signals. Volterra Neural Networks (VNNs) [9], [14] introduce higher-order convolutions to capture nonlinear dependencies beyond standard activations, and have been applied to restoration tasks through cascaded or U-Net-integrated designs. Prior editing datasets [3], [5], [6] synthesize paired examples with instructions, but often emphasize single-object edits and depend on external datasets like RefCOCO or GQA. Our work differs by systematically generating a diverse add and remove dataset with varying complexity and spatial reasoning cues, while introducing a compact nonlinear adapter for improved IIE.
Proposed Work
GalaxyEdit Dataset
We aim to build a comprehensive dataset for object add and remove tasks, enabling edits across a wide range of objects with diverse instructions. We use COCO dataset [15] (118k images with object labels and masks) as the source, and process each image through detection, masking, inpainting, and filtration to form source–edit pairs for the remove task, and swapping pairs yields training data for the add task. An instruction generation module then produces various natural-language edit instructions as shown in Figure 2(a).
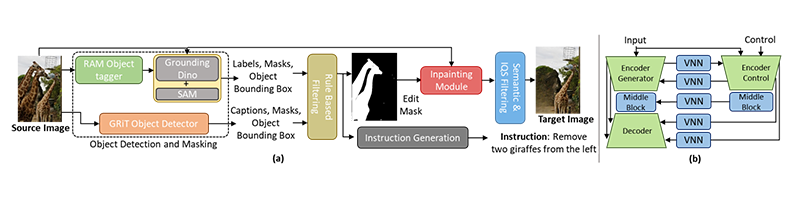
Figure 2. (a) Proposed data generation pipeline for GalaxyEdit dataset. (b) ControlNet-Vxs Model Architecture
Object Detection and Masking enable diverse instruction generation by integrating multiple detectors. RAM [16] supplies open-set categories, aligned with GroundingDINO [17] and COCO annotations to cover 2887 categories. The resulting boxes and labels support mask generation, while GRiT [18] provides dense, attribute-rich captions for descriptive instructions. Rule-Based Filtering removes trivial or uninformative cases, such as masks covering <0.18% or >50% of an image, as well as sensitive categories (e.g., medical, violent, or personal content). Mask-based inpainting uses LaMa [19] for object removal, chosen for its robustness on large masks and high resolutions. Diffusion-based inpainting was also tested but introduced hallucinations and artifacts [6]. Semantic filtering suppresses noisy or implausible edits by applying CLIP [20] similarity between original and inpainted images to remove semantically misaligned pairs. While CLIP filtering removes semantically incorrect edits, it fails to detect low-level inpainting artifacts such as texture smearing or poor boundary blending. To address this, we further introduce IQS filtering, integrating texture similarity via local binary patterns, colour distribution consistency using histogram distance, and edge continuity across masked boundaries to explicitly measure the visual plausibility of the inpainted regions. Scores from these components are normalized and averaged, with low-IQS samples discarded.
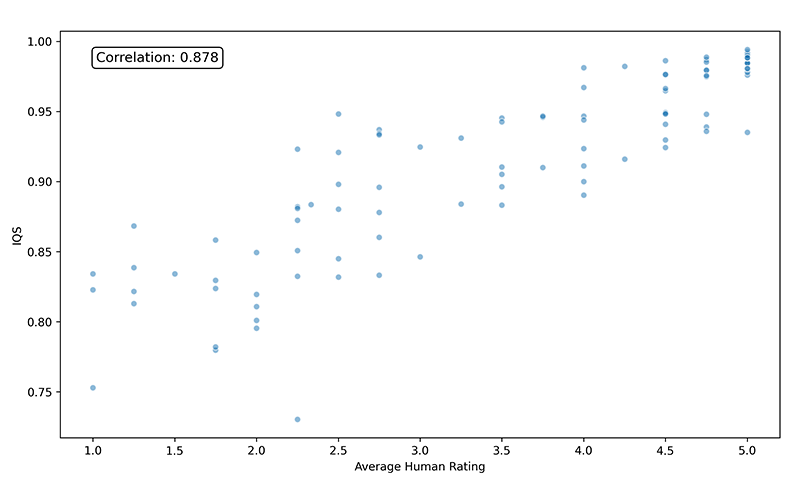
Figure 3. (a) Correlation of Inpainting Quality Score (IQS) with Average Human Rating
As shown in Figure 3, human evaluation confirms that IQS correlates strongly with perceptual quality (Pearson r ≈ 0.878), enabling automated large-scale quality control. Instruction generation produces diverse edit commands aligned with visual edits through four categories. Simple instructions use template-based add and remove commands with object labels from RAM/COCO. Attribute instructions enrich these with properties such as colour or size from GRiT captions. Spatial instructions are derived from depth and 3D analysis to assign left/right/front/behind relations (e.g., <obj1> to the left of <obj2> ). Multi-instance instructions target multiple instances (e.g., remove k < objects > from <direction> ), generated by grouping object masks and composing them via logical OR. Together, these strategies yield a broad distribution of edit types, extending coverage beyond generic templates.
Enhanced Diffusion Adapter
Problem Formulation
Given an image editing dataset with images $ X_I=x_I^1,…,x_I^N $ and edit instructions $ E=e^1,…,e^N $,
the goal is to learn an editing function G that maps them to edited images $ X_E=x_E^1,…,x_E^N $.
Specifically, we are interested in a class of functions in which the output of a frozen base model $F_b (x_b;Θ_b )$ is modulated using a control network $F_c (x_c;Θ_c )$ through an interaction function
$Φ(.,.)$.
Volterra Filters for Optimal Information Exchange
In our proposed methodology, we utilize a Volterra Neural Network (VNN) to implement the interaction function. A Volterra layer is defined based on the second-order approximation of the Volterra Series [14]. The output of the l^th Volterra layer in a VNN is then calculated as
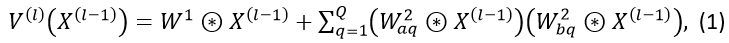
where, $ W^k $ denotes the filter weights of the k-th order Volterra term, $ Q$ denotes the rank of the approximation, and ⊛ denotes the convolution operation.
We incorporate the enhanced interaction function in ControlNet-xs and propose a new variant ControlNet-Vxs. In our approach, the feature map from the control block is fused into the feature map of the base neural block through a VNN layer. The non linear fusion output from the VNN is merged with the base model features by taking a weighted combination of the two. Mathematically, the fusion into the base neural block can be expressed as
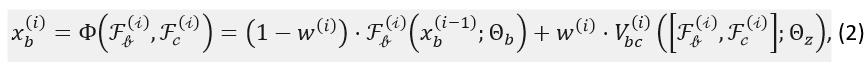
where, [.,.] represents the concatenation of features along the channel dimension, w^((i) ) is the learnable fusion weight, $ V_bc (.;.)$ is a zero initialized VNN layer connecting control to the base. Similarly, the fusion from the base neural block into the control block is computed as $ x_c^i=Φ(F_c^{(i)},F_b^{(i)}) $. Equation (2) uses a single VNN layer for ease of notation. However, multiple VNN layers may be cascaded to realize complex non-linear fusion functions.
Model training
We follow the training setup of [8], initializing control parameters randomly while freezing the Stable Diffusion v1.5 backbone, as the base model in all experiments. Models are trained with canny conditioning for canny-to-image generation and image conditioning for add and remove tasks, using the standard diffusion objective
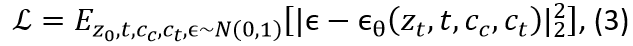
where, $ z_0$ represents the target image latent, $z_t$ represents the noisy latent at time step t, $c_c$ represents the control conditioning and $ c_t$ represents the text conditioning.
Results and discussion
Experimental Setup
We fine-tune Stable Diffusion v1.5 on 800K GalaxyEdit samples and compare against models trained on PIPE [6] Inst-Inpaint [5], InstructPix2Pix [3]. For fairness, all baselines are re-trained on SD v1.5 following the procedure in [3]. Evaluation is performed on two benchmarks: (i) GalaxyEdit Test Set - 1,000 source–target–instruction pairs generated using the pipeline discussed in Section GalaxyEdit Dataset (ii) MagicBrush Test Set - 130 add and 62 remove edits filtered from the public MagicBrush dataset. We evaluate edits using L2 to evaluate pixel-level global fidelity, CLIP-T [21] to assess the instruction and edited image alignment. We also use CLIP-I [20] and FID [22] to evaluate the semantic similarity and distance between the distributions of reference and edited images, respectively.
We base our study on Type-B ControlNet-xs with 55M parameters [8] and compare it to ControlNet-Vxs on two tasks: (i) Instruction-based editing - trained on GalaxyEdit and evaluated on its test set using the metrics mentioned above. (ii) Canny-to-image generation - trained on 1M LAION dataset using canny edges with random thresholds as control inputs, and evaluate with CLIP-T, CLIP-Aes, LPIPS, and FID.
Performance Comparison on GalaxyEdit
We evaluate the quality of GalaxyEdit by fine-tuning SD v1.5 on benchmark add and remove datasets and the GalaxyEdit dataset. The model trained on GalaxyEdit shows consistent improvements on both add and remove tasks, with particularly strong gains in removal, suggesting superior dataset quality.

Figure 4. Qualitative results for object removal (left) and addition (right), comparing our model with baselines
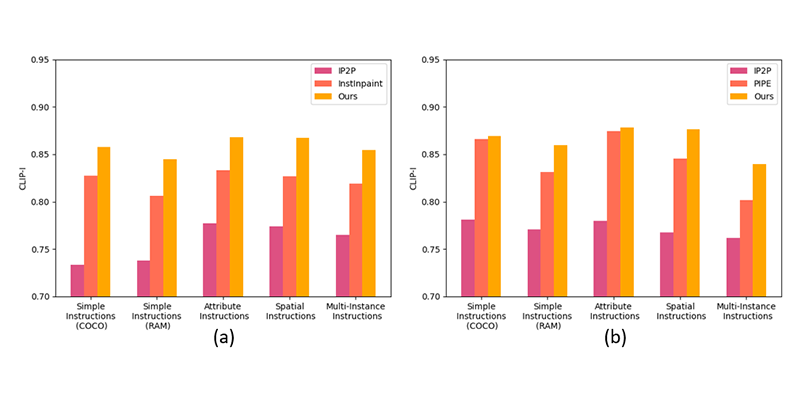
Figure 5. Category-wise performance on GalaxyEdit test set
Split-wise analysis Figure 5 confirms robust performance across instruction types. For the object addition task, the PIPE model performs comparably to ours on simple and attribute-rich instructions, but falls short in others. Notably, all three models exhibit subpar performance when handling multi-instance instructions compared to other types of instructions. Our overall observation indicates that performance tends to be relatively better for instruction categories that are more specific, such as spatial and attribute-based instructions. We further assess the generalization capacity of a model trained on our dataset to publicly available datasets. For this, we train all models on their respective datasets and evaluate on the MagicBrush test set. As shown in Table 1 (bottom), our model outperforms the baseline methods in most cases. The diversity of GalaxyEdit enables stronger cross-dataset generalization, with qualitative results Figure 4 showing accurate execution of user instructions across varying complexities.
Human evaluation (HE) on 100 randomly sampled test pairs further supports these findings: 25 raters, blinded to model identity, scored each output (1–5) for quality and instruction fidelity, and GalaxyEdit-trained models consistently received higher ratings as shown in Table 1 (top), reflecting superior instruction following and realism.
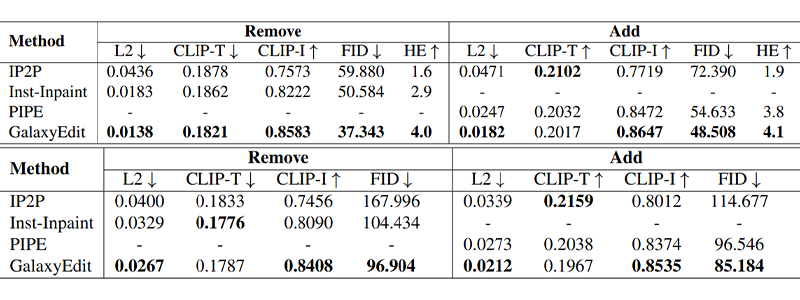
Table 1. Performance of different SOTA methods for add and remove evaluated on GalaxyEdit (top) and MagicBrush (bottom) test sets. (-) denotes dataset not proposed for the task
Comparison of ControlNet-xs Variants

Figure 6. Qualitative results on canny-to-image and add–remove tasks. Each row shows results for a different task, with the corresponding prompt shown alongside
We assess the integration of Volterra fusion into ControlNet-xs across instruction-based editing and canny-to-image generation. Results in Table 2 and Figure 6 show that the proposed ControlNet-Vxs achieves substantial improvements, including an 11.4% FID reduction on removal, consistent gains in addition, and enhanced performance on canny-to-image generation (Table 3). This demonstrates ControlNet-Vxs consistently outperforms ControlNet-xs under the same data, isolating the benefit of Volterra fusion from dataset effects.

Table 2. Performance of adapter-based methods on GalaxyEdit test set (Our model and ControlNet-xs trained on GalaxyEdit dataset)

Table 3. Canny-to-Image results on COCO val. set using best performing add-concat configuration of ControlNet-xs
Ablation Study
We analyse the impact of increasing the rank of approximation Q and VNN layers N in ControlNet-Vxs, evaluated on GalaxyEdit test set for add and remove tasks Figure 7.
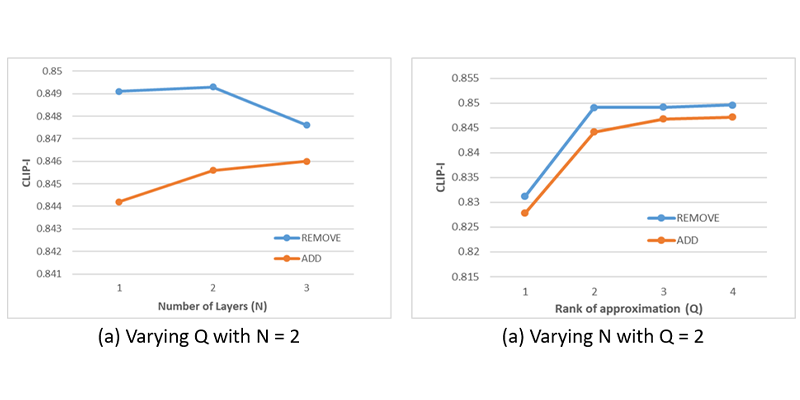
Figure 7. Effect of (a) rank of approximation Q and (b) number of volterra layers N on editing performance
Performance improves notably as Q ranges from 1 to 2, followed by a gradual growth that eventually saturates. Varying N has little effect on removal, with performance declining beyond N=2, while addition benefits from increased non-linearity, reflecting the higher complexity of the task.
Conclusion
We introduced GalaxyEdit, a large-scale dataset for object addition and removal, and ControlNet-Vxs, a Volterra fusion variant of ControlNet-xs that enables richer non-linear conditioning between networks. Models trained on GalaxyEdit consistently outperform leading baselines, and ControlNet-Vxs demonstrates clear advantages in handling complex editing tasks with higher fidelity and realism. While performance is naturally constrained by individual network modules, and GalaxyEdit is currently derived from COCO, the data generation process is fully automated and adaptable to other image datasets, making it easy to expand or specialize for new tasks.
Current Samsung devices rely on third-party, cloud-based multimodal image editing solutions, which introduce latency, privacy concerns, and recurring operational costs. Our work enables a shift toward high-quality, on-device instruction-based image editing through the combination of GalaxyEdit and the lightweight ControlNet-Vxs adapter. The proposed approach improves edit fidelity while remaining parameter-efficient and deployment-friendly, making it well-suited for mobile constraints.
References
[1] Omri Avrahami, Dani Lischinski, and Ohad Fried, “Blended diffusion for text-driven editing of natural images,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). June 2022, IEEE.
[2] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi, “Photorealistic text-to-image diffusion models with deep language understanding,” 2022.
[3] Tim Brooks, Aleksander Holynski, and Alexei A. Efros, “Instructpix2pix: Learning to follow image editing instructions,” 2023.
[4] Shu Zhang, Xinyi Yang, Yihao Feng, Can Qin, ChiaChih Chen, Ning Yu, Zeyuan Chen, Huan Wang, Silvio Savarese, Stefano Ermon, Caiming Xiong, and Ran Xu, “Hive: Harnessing human feedback for instructional visual editing,” 2024.
[5] Ahmet Burak Yildirim, Vedat Baday, Erkut Erdem, Aykut Erdem, and Aysegul Dundar, “Insinpaint: Instructing to remove objects with diffusion models,” 2023.
[6] Navve Wasserman, Noam Rotstein, Roy Ganz, and Ron Kimmel, “Paint by inpaint: Learning to add image objects by removing them first,” 2024.
[7] Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, and Xiaohu Qie, “T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models,” 2023.
[8] Denis Zavadski, Johann-Friedrich Feiden, and Carsten Rother, “Controlnet-xs: Designing an efficient and effective architecture for controlling text-to-image diffusion models,” 2023.
[9] Siddharth Roheda, Hamid Krim, and Bo Jiang, “Volterra neural networks (vnns),” Journal of Machine Learning Research, vol. 25, no. 182, pp. 1–29, 2024.
[10] Tao Yu, Runseng Feng, Ruoyu Feng, Jinming Liu, Xin Jin, Wenjun Zeng, and Zhibo Chen, “Inpaint anything: Segment anything meets image inpainting,” 2023.
[11] Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord, “Diffedit: Diffusion-based semantic image editing with mask guidance,” 2022.
[12] Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang, “Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models,” 2023.
[13] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala, “Adding conditional control to text-to-image diffusion models,” 2023.
[14] Siddharth Roheda, Amit Unde, and Loay Rashid, “Mrvnet: Media restoration using volterra networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 6098–6107.
[15] Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Doll´ar, “Microsoft coco: Common objects in context,” 2015.
[16] Youcai Zhang, Xinyu Huang, Jinyu Ma, Zhaoyang Li, Zhaochuan Luo, Yanchun Xie, Yuzhuo Qin, Tong Luo, Yaqian Li, Shilong Liu, Yandong Guo, and Lei Zhang, “Recognize anything: A strong image tagging model,” 2023.
[17] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang, “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” 2023.
[18] Jialian Wu, Jianfeng Wang, Zhengyuan Yang, Zhe Gan, Zicheng Liu, Junsong Yuan, and Lijuan Wang, “Grit: A generative region-to-text transformer for object understanding,” 2022.
[19] Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky, “Resolution-robust large mask inpainting with fourier convolutions,” 2021.
[20] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever, “Learning transferable visual models from natural language supervision,” 2021.
[21] Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan LeBras, and Yejin Choi, “Clipscore: A reference-free evaluation metric for image captioning,” 2022.
[22] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” 2018.




