AI
On the Importance of a Multi-Scale Calibration for Quantization
|
The IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) is an annual flagship conference organized by IEEE Signal Processing Society. ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. It features a broad technical program showcasing the latest developments in research and technology, attracting thousands of professionals from both academia and industry. In this blog series, we highlight our research papers presented at ICASSP 2026. Below is a list of our contributions. #1. Whisper-Fest: Single-Channel Far-Field Enhanced Speech-to-Text Without Parallel Data #2. Triage Knowledge Distillation for Speaker Verification #4. DeMo-Pose: Depth-Monocular Modality Fusion for Object Pose Estimation #5. GalaxyEdit: Large Scale Image Editing Dataset with Enhanced Diffusion Adapter #6. ADORE: Asymmetric Relational Distillation with Reranking for Instance Level Image Retrieval #7. T-GEMS: Text-Guided Exit Modules for Decreasing CLIP Image Encoder #8. SmoGVLM: A Small, Graph-Enhanced Vision-Language Model #9. On the Importance of a Multi-Scale Calibration for Quantization #11. Self-Attention Decomposition for Training Free Diffusion Editing |
1. Post-Training Quantization
With the widespread adoption of Large Language Models (LLMs), quantization techniques have become essential for efficient inference across both on-device environments and large-scale server clusters. In particular, Post-Training Quantization (PTQ) has proven highly effective at compressing models using only a small number of calibration samples while ensuring stable performance at 4-bit integer (INT4) precision (GPTQ [1], Aespa [2], BoA [3], TurboBoA [4]). This enables the deployment of custom models directly on local devices using frameworks like llama.cpp , eliminating the need for server infrastructure.
However, existing PTQ research has focused almost exclusively on optimizing the quantization algorithms. For instance, GPTQ [1] reduced computational complexity through a strong assumption of layer-wise independence. Our previous works [2, 3, 4] expanded upon this by designing a Hessian that reflects cross-layer dependencies, achieving reasonable accuracy even at 2-bit precision. OmniQuant [5] and SpinQuant [6] also introduced algorithmic improvements for outlier handling, a characteristic challenge in LLMs. Despite these algorithmic advancements, the conventional practice of using fixed-length random sampling to construct the calibration set remains largely unchallenged, leaving the critical aspect of sequence length diversity unexplored.
2. The Critical Role of Calibration Data in Hessian Approximation
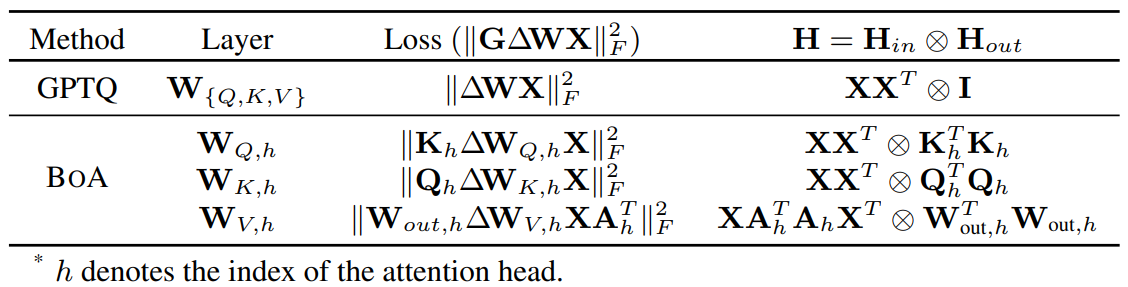
Table 1. Loss used to approximate Hessians and the corresponding Hessians in GPTQ and BoA
The quantization reconstruction error is approximated as a quadratic loss, $L∝Δw^T HΔw$, where $Δw$ is the weight perturbation and $H$ is the second-order curvature of the loss function (i.e., the Hessian with respect to the $w$). While GPTQ [1] approximates H using the input activation covariance $E[xx^T]$, BoA [3] provides more refined approximation by considering cross-layer dependencies (see Table 1). Since the activation x is directly determined by the input, the calibration set is a core element in constructing the Hessian matrix, which approximates the sensitivity of each weight within the model. If the calibration data captures the true distribution of real-world data, robust and accurate quantization might be achievable without algorithmic modification. Therefore, optimal quantization hinges on a precise Hessian approximation, which in turn requires the calibration set to faithfully follow the true data distribution. Although random sampling helps prevent data bias, it is also critical to account for the variance introduced by diverse sequence lengths—a factor completely overlooked in previous studies.
3. Multi-Scale Calibration: MaCa (Matryoshka Calibration)
Based on our observations, the specific channels activated within LLMs vary significantly depending on sequence length. Consequently, conventional fixed-length calibration (e.g., 2048 tokens) causes the Hessian to overfit specific channels primarily activated by long contexts. To overcome this limitation and construct a more sophisticated Hessian, this study introduces 'length diversity' to the calibration samples.
The proposed MaCa (Matryoshka Calibration) evenly samples multi-scale sequence lengths (e.g., 128, 512, 1024, and 2048 tokens). Instead of simply aggregating these lengths, it treats them as independent samples, applies regularization, and computes an integrated Hessian.
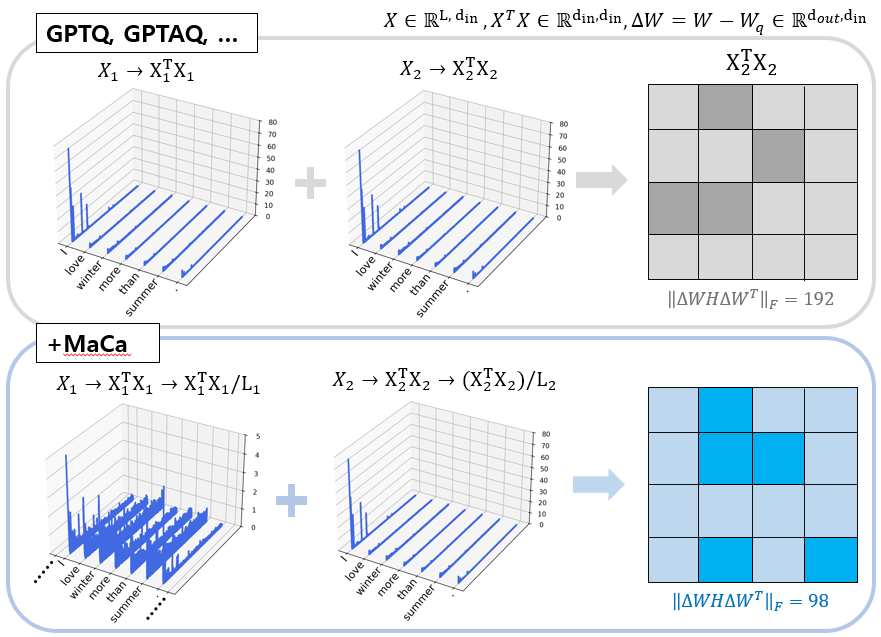
Figure 1. Visualization of diagonals of Hessian
As illustrated in Figure 1, fixed-length-based calibration (Top) results in a sparse Hessian, where the diagonal components are heavily biased toward a few channels. In contrast, MaCa (Bottom) integrates multi-scale information to produce a richer Hessian that evenly captures the sensitivities of diverse channels across the model.
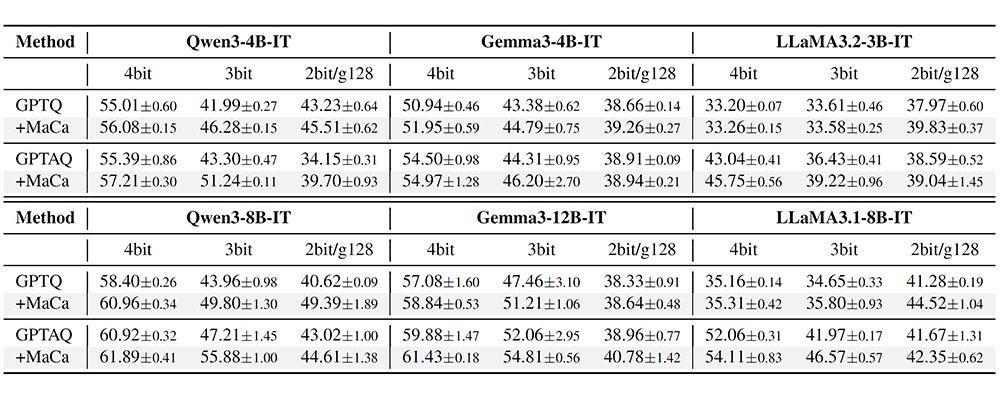
Table 2. Average accuracy (%) over 8 zero-shot benchmark tasks for GPTQ and GPTAQ [7], with and without MaCa, at 4bit, 3bit, and 2bit/g128 across Qwen3, Gemma3, and LLaMA3. Results are reported as mean ± std over 3 seeds
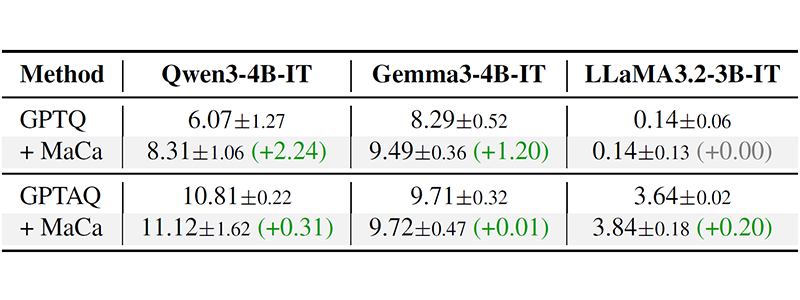
Table 3. LongBench overall scores (higher is better) for GPTQ and GPTAQ with and without MaCa on 4bit quantized models. Results are reported as mean ± std over 3 seeds
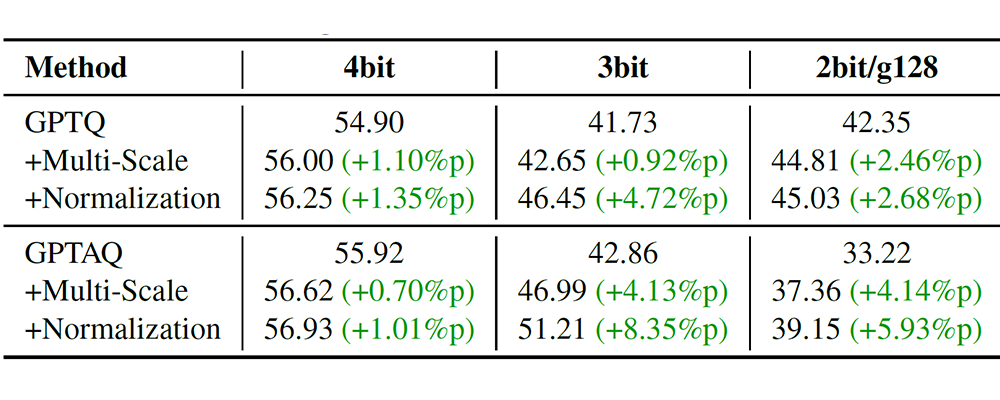
Table 4. Ablation of MaCa’s multi-scale length aggregation (“+Multi-Scale”) and per-sequence normalization (“+Normalization”) sequentially starting from GPTQ and GPTAQ at 4bit, 3bit, and 2bit/g128
As shown in Tables 2, 3, and 4, experiments on state-of-the-art LLMs—including Qwen3, Gemma3, and LLaMA3—demonstrate consistent performance gains across zero-shot benchmarks and extreme low-bit environments over existing methods. Notably, MaCa acts as a seamless drop-in replacement; it enables immediate performance boosts by simply updating the initial Hessian computation without altering the underlying quantization pipeline.
4. Conclusion and Future Work
This study advocates for a data-centric approach to Hessian optimization, shifting focus from algorithmic refinements to the intrinsic quality of calibration data. Having established the impact of sequence length diversity on quantization, we intend to extend our research into comprehensive sample diversity optimization. Future work will move beyond random sampling to develop sophisticated extraction strategies aimed at capturing the most informative samples for quantization.
Link to the paper
[2] Kim, Junhan, et al. "Towards next-level post-training quantization of hyper-scale transformers." Advances in Neural Information Processing Systems 37 (2024): 94292-94326.
[3] Kim, Junhan, et al. "BoA: Attention-aware Post-training Quantization without Backpropagation." International Conference on Machine Learning. PMLR, 2025.
[4] Kim, Junhan, et al. "TurboBoA: Faster and Exact Attention-aware Quantization without Backpropagation." International Conference on Representation Learning, 2026
[5] Shao, Wenqi, et al. "OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models." The Twelfth International Conference on Learning Representations.
[6] Liu, Zechun, et al. "SpinQuant: LLM Quantization with Learned Rotations." The Thirteenth International Conference on Learning Representations.
[7] Li, Yuhang, et al. "GPTAQ: Efficient Finetuning-Free Quantization for Asymmetric Calibration." Forty-second International Conference on Machine Learning.





