AI
SmoGVLM: A Small, Graph-Enhanced Vision-Language Model
|
The IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) is an annual flagship conference organized by IEEE Signal Processing Society. ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. It features a broad technical program showcasing the latest developments in research and technology, attracting thousands of professionals from both academia and industry. In this blog series, we highlight our research papers presented at ICASSP 2026. Below is a list of our contributions. #1. Whisper-Fest: Single-Channel Far-Field Enhanced Speech-to-Text Without Parallel Data #2. Triage Knowledge Distillation for Speaker Verification #4. DeMo-Pose: Depth-Monocular Modality Fusion for Object Pose Estimation #5. GalaxyEdit: Large Scale Image Editing Dataset with Enhanced Diffusion Adapter #6. ADORE: Asymmetric Relational Distillation with Reranking for Instance Level Image Retrieval #7. T-GEMS: Text-Guided Exit Modules for Decreasing CLIP Image Encoder #8. SmoGVLM: A Small, Graph-Enhanced Vision-Language Model #9. On the Importance of a Multi-Scale Calibration for Quantization #10. Differentially Private Clustered Federated Learning with Privacy-Preserving Initialization and Normality-Driven Aggregation #11. Self-Attention Decomposition for Training Free Diffusion Editing |
Introduction
Large vision-language models (VLMs) have achieved impressive performance across a wide range of multimodal tasks, from visual question answering (VQA) to reasoning over images and text [1, 2]. However, these models often suffer from hallucinations and poor grounding when faced with knowledge-intensive queries. It is especially problematic for smaller models, which lack sufficient capacity to internalize factual world knowledge. Scaling model size offers improvements, but incurs prohibitive costs in training, inference, and deployment. Knowledge graphs (KGs) provide structured context that can guide reasoning and reduce hallucination.
In this blog, we propose SmoGVLM, a small graph-enhanced VLM that integrates structured knowledge with vision and language representations.
We extract compact sub-graphs from ConceptNet [3] and encode them using a lightweight Graph Neural Network (GNN), which are then fused with image and text embeddings. This enables the model to reason in a chain-of-thought style while remaining efficient. Crucially, our sub-graph extraction is simple and fast, avoiding the excessive cost of prior methods such as QA-GNN [4], which rank every concept against the query.
Our contributions are threefold:
We evaluate SmoGVLM's performance on ScienceQA [5] and A-OKVQA [6], both requiring multimodal reasoning and external knowledge. Results show that even the 1.3B SmoGVLM significantly outperforms larger VLMs such as LLaVA-7B [1] by 5.8%. These findings show that structured KG augmentation allows smaller VLMs to match larger models while reducing hallucinations and computational cost.
Method
Task Formulation
We consider the task of multimodal question answering, where a question q with answer options ${a_1,a_2,…,a_k }$ is given along with an image $X_{img}$ and optional textual context $c$. The objective is to generate both a rationale $r$ and a final answer $\hat{a}$. Formally, given language, image and graph inputs $X_{lang}$,$X_{img}$,$X_{kg}$, the model learns to maximize the likelihood of generating reference text $Y=[r;\hat{a}]$ of length $N$:
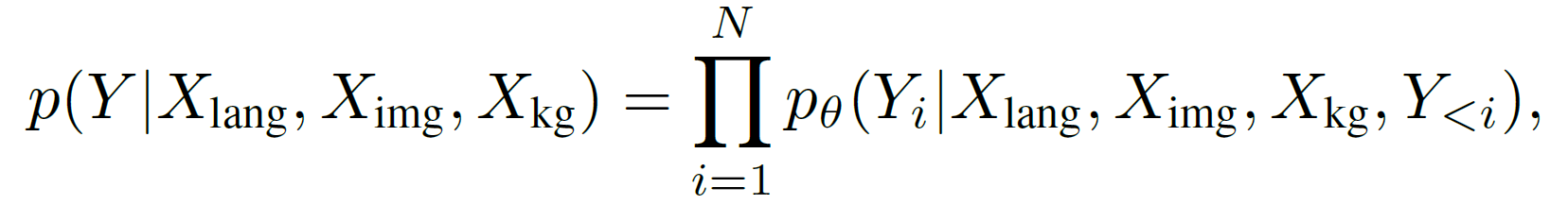
where θ denotes model parameters. This encourages the model to first generate reasoning steps and then the answer.
Encoding Images and Text Modalities
We begin by encoding language and visual inputs into a shared d-dimensional space. For text input $X_{lang}$, we use a trainable embedding layer:
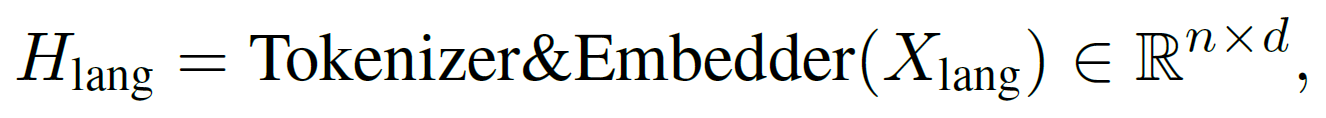
where $n$ is the number of tokens. For image input $X_{img}$, we use an encoder followed by a trainable linear projection:
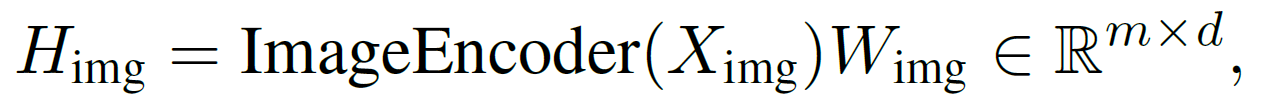
where $m$ is the number of image patches. In our method, we adopt LLaVA [1] as the backbone, with LLaMA [7] as the language model and CLIP [8] as our ImageEncoder(∙).
Sub-graph Extraction
To incorporate structured knowledge, we extract a relevant sub-graph from ConceptNet [3]. The complete graph contains ~800k English entities and 2M triples, spanned across 34 relation types. We then use BLIP-2 [2] to compute embeddings of all triples and compare them against the multimodal embeddings of the given question-image pair using cosine similarity.
The top-k ranked triples (up to 200 nodes) are retained to form a compact sub-graph $X_{kg}$. This simple, lightweight extraction avoids the excessive computational costs of ranking every concept with the question, as required in QA-GNN [4] and KAM-CoT [9]. We quantify this speedup in the Experiments Section.
Encoding the sub-graph
The sub-graph $X_{kg}$ is encoded using a stack of GNNs. For each concept node, we average its span embeddings across all occurrences in the complete KG. This is a one-time pre-processing step and gives node embeddings with the same dimensionality as the language model.
Relation types are represented using a trainable lookup table of size 34×64, where 34 is the number of relation categories. The KGEncoder(∙) is made of a Relational Graph Attention Network (RGAT) [10], followed by a Graph Convolutional Network (GCN) [11], with a LeakyReLU activation in between.
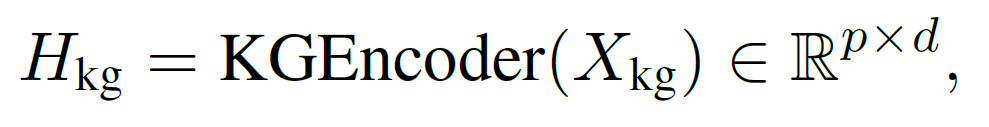
where $p$ is the number of nodes. This representation captures both entity semantics and relational structure.
Model Overview
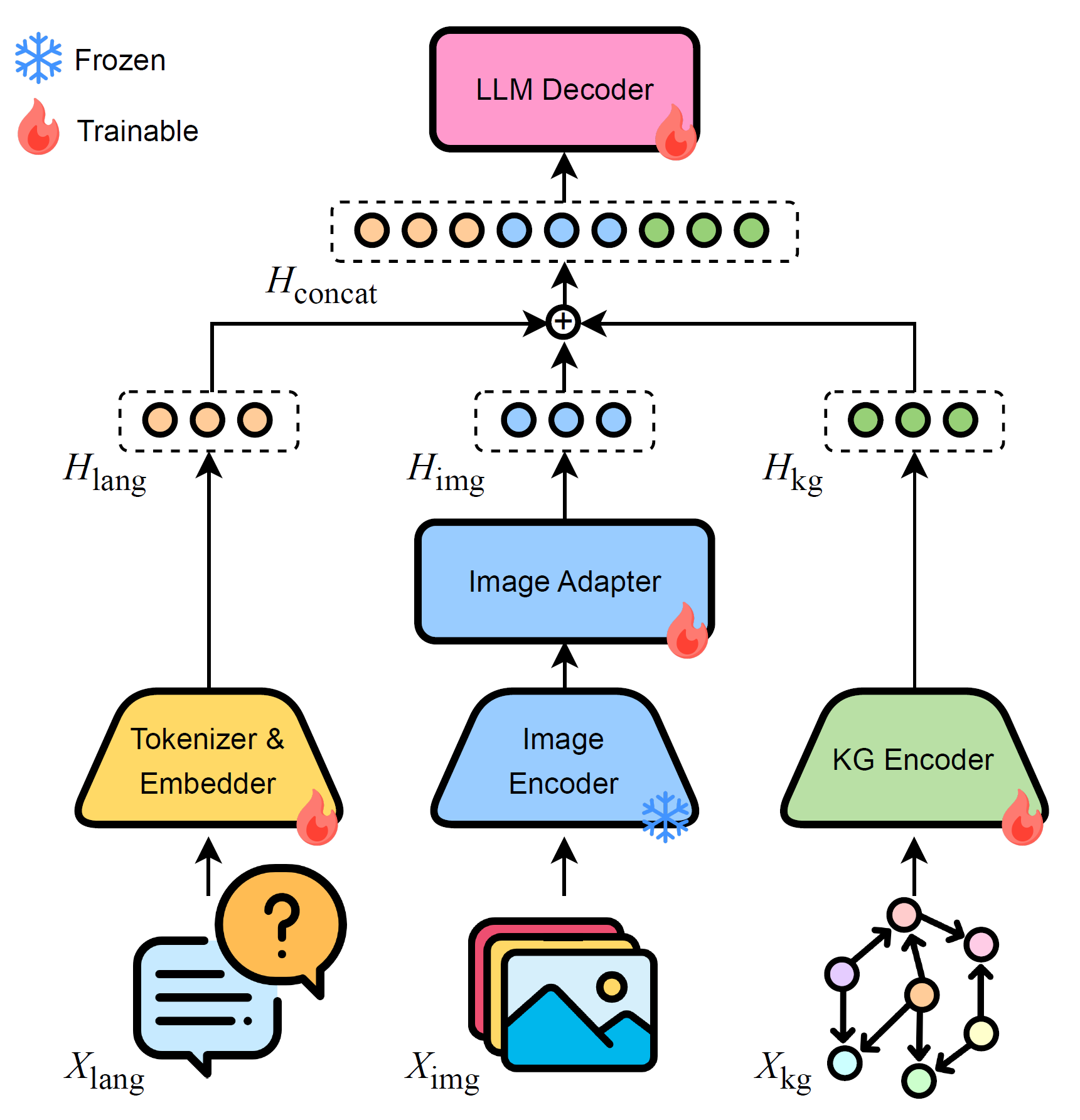
Figure 1. Overview of SmoGVLM. Language, Image and KG inputs are encoded, fused into a joint representation, and decoded into rationale and answer.
Finally, we integrate all modalities. The encoded representations are concatenated:
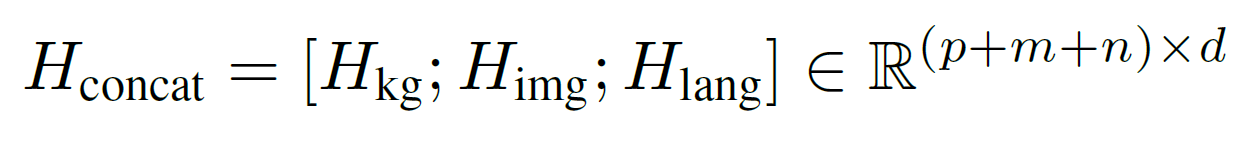
This joint representation is passed to a transformer decoder, which generates the rationale and answer autoregressively:
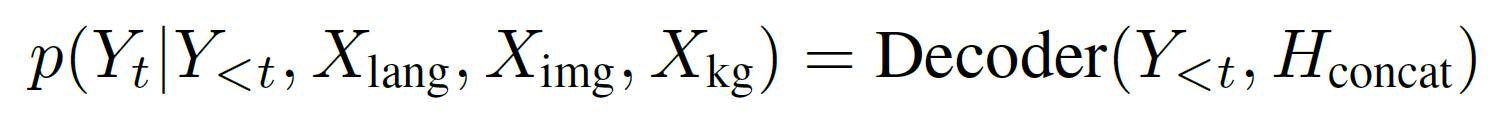
By conditioning the answer on the generated rationale, the model ensures reasoning consistency and reduces hallucination. An overview of the architecture is shown in Figure 1.
Experiments
Datasets
We evaluate SmoGVLM on two multimodal benchmarks.
ScienceQA [5] contains 21.2k multiple-choice questions across natural, social, and language sciences, with accompanying text, images, and explanations. It comes with 12.7k train, 4.2k validation, and 4.2k test examples.
A-OKVQA [6] consists of 25k open-ended visual questions requiring commonsense and world knowledge, with 17k training, 1.1k validation, and 6.7k test samples. Since test labels are not publicly available, we follow prior work and treat the original validation set as test data. The training set is further split into 12,726 train and 4,330 validation samples.
Baselines
To quantify the effectiveness of adding KG, we perform experiments in the following settings:
Experiments are conducted across model sizes from 1.3B to 13B parameters, using both full fine-tuning (FFT) and parameter-efficient Low-Rank Adaptation (LoRA).
For sub-graph extraction, we compare our lightweight top-k retrieval with QA-GNN [4], which ranks every concept against the question, enabling a direct analysis of both accuracy and time required.
Training Details
All experiments are performed on a cluster of 8 A100 40GB GPUs. To fit models of sizes ≥7B, we employ FSDP. We use a learning rate of $2×10^{-5}$ and cosine decay scheduling. For parameter-efficient tuning, we adopt LoRA with (r,α) = (128,128) and a dropout rate of 0.05. All models are trained in bfloat16 precision. We train for a maximum of 20 epochs with an early stopping patience of 3 epochs.
Results
We assess the efficacy of sub-graph extraction methods using two metrics:
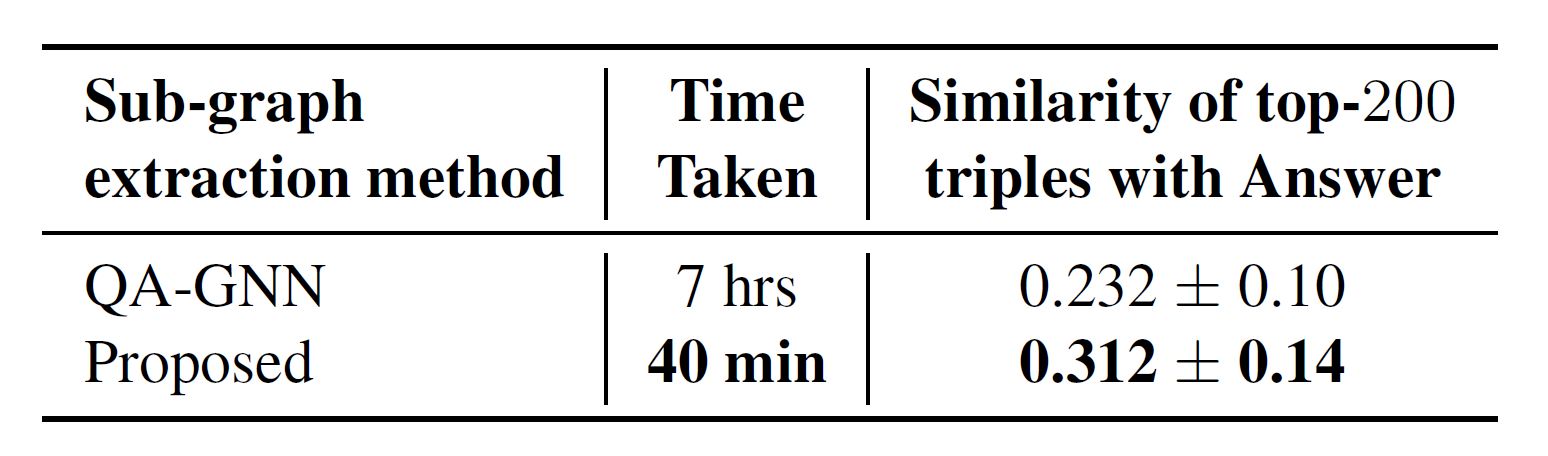
Table 1. Comparison of sub-graph extraction methods. Our strategy is much faster and yields higher answer similarity.
Table 1 shows that our method is over 10× faster than QA-GNN and closer to the answer by 34%. This efficiency comes from ranking only triples, whereas QA-GNN ranks every grounded concept and its 2-hop neighbors against the question.
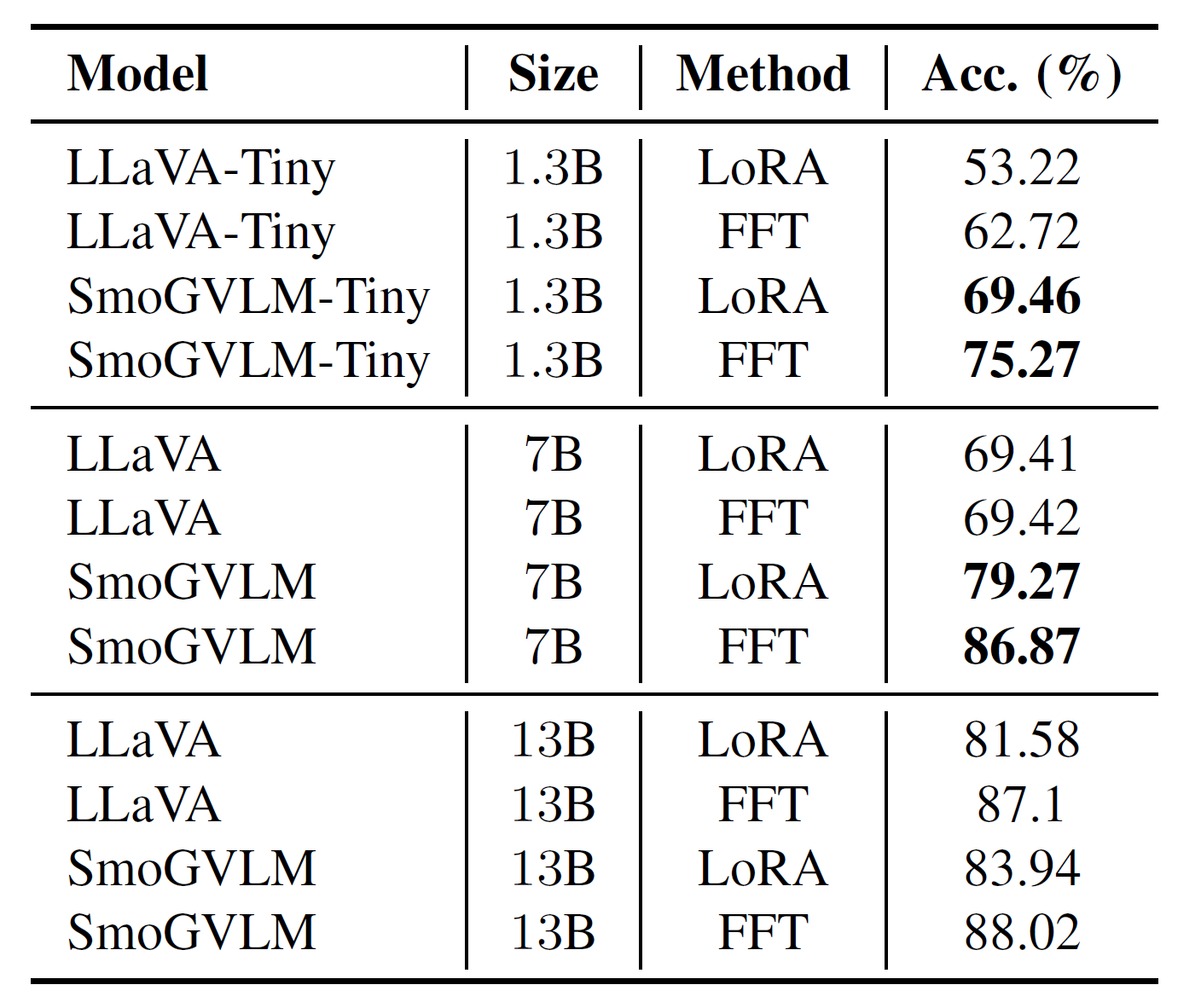
Table 2. Performance on ScienceQA test split.
Table 2 presents results on ScienceQA. SmoGVLM improves over LLaVA by 12.55%, 17.45%, and 0.92% for the 1.3B, 7B, and 13B FFT models respectively. The gains are most pronounced for smaller models (≤7B). This is expected since larger models are trained on broader corpora. Notably, SmoGVLM-Tiny (1.3B), being 5.5× smaller, surpasses LLaVA-7B by 5.85% on FFT.
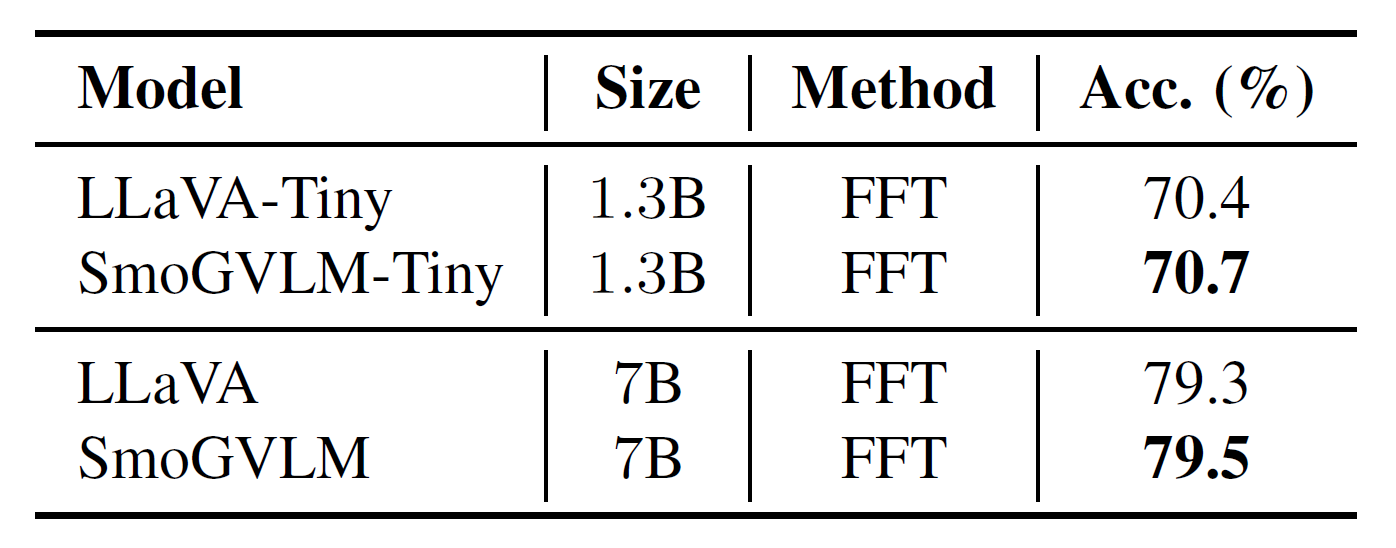
Table 3. Performance on A-OKVQA validation split.
Table 3 shows A-OKVQA results with a similar trend: SmoGVLM outperforms LLaVA across model sizes.
These findings highlight the benefits of injecting structured knowledge in VLMs. However, ConceptNet's focus on scientific facts limits its effectiveness for A-OKVQA, which relies more on common-sense reasoning.
Discussion
Analysis of extracted Triples
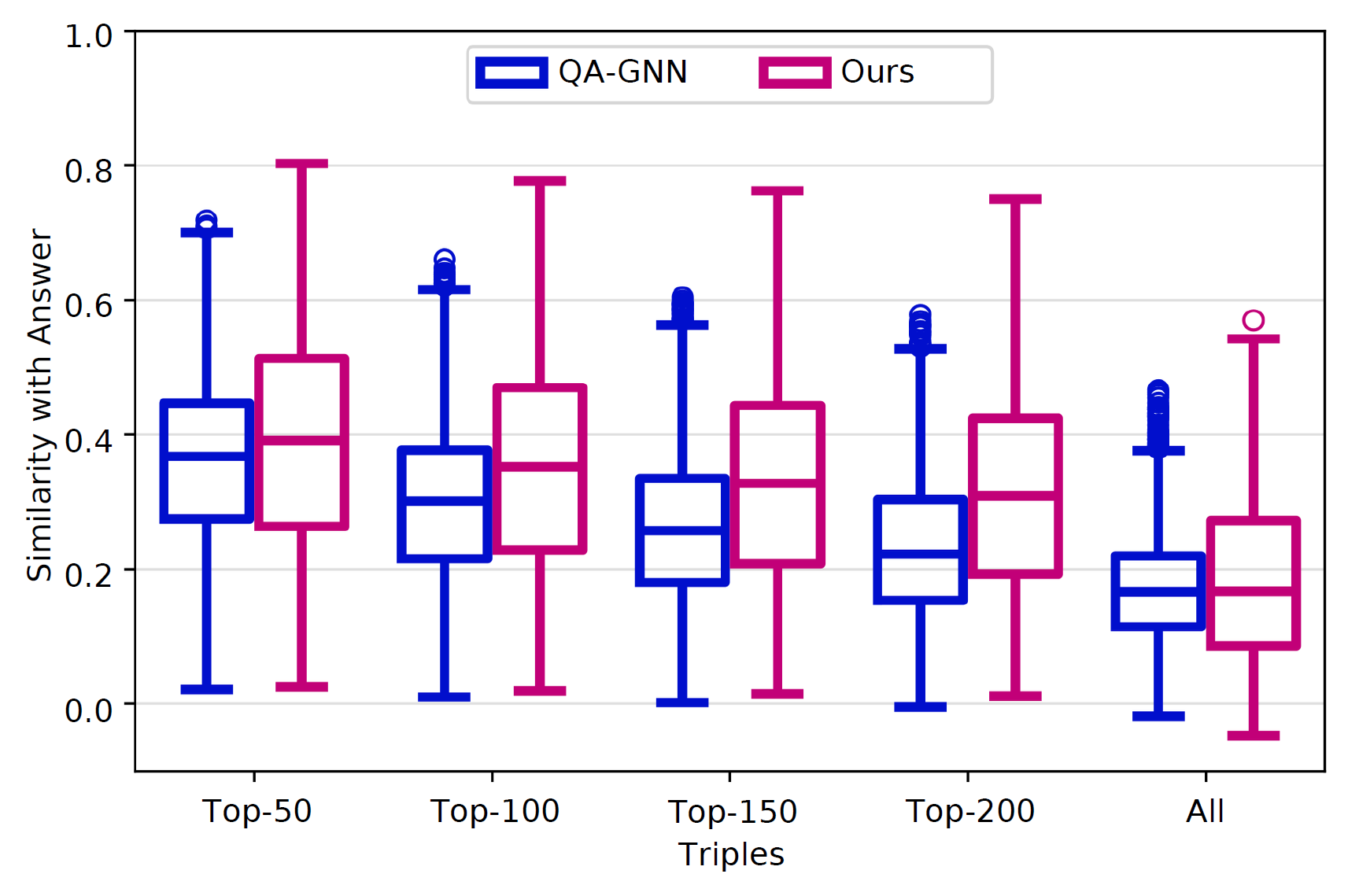
Figure 2. Similarity of top-k triples to the correct answer.
We evaluate the relevance of retrieved triples by measuring their similarity with ground-truth answers using sentence-transformers/all-mpnet-base-v2 to compute sentence embeddings. Each triple is verbalized in subject-relation-object form and compared with the correct answer using cosine similarity. For each sample, we average these similarities to obtain a proximity score, and then take the mean over all samples to quantify overall relevance.
As shown in Table 1, our method achieves higher similarity and is an order of magnitude faster.
Figure 2 further reports similarities as the number of retained triples increases. We observe steadily higher relevance with larger sub-graphs, but the gain saturates beyond 200 triples, suggesting that compact graphs capture most of the useful knowledge. Compared to QA-GNN, our method achieves higher similarity, and an order of magnitude faster, showing that efficiency and quality need not be traded off.
Effect of Sub-graph size
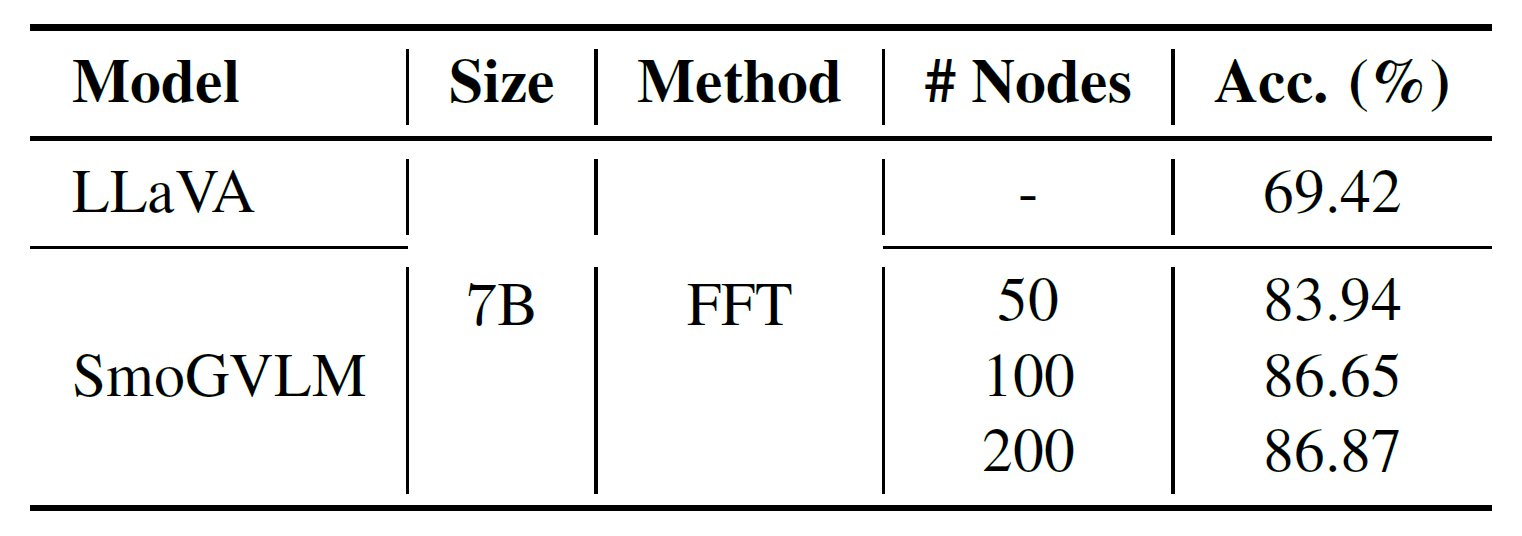
Table 4. Impact of sub-graph size on accuracy. Small graphs are sufficient, with performance saturating beyond 200 nodes.
Table 4 shows that performance improves steadily as the sub-graph grows, but saturates around 200 nodes. This suggests that relatively small graphs already provide sufficient signal for reasoning, supporting the efficiency of our lightweight extraction strategy. We hypothesize that larger graphs may only add noise with little benefit, and reserve a more comprehensive examination of this phenomenon for future research.
Qualitative Samples
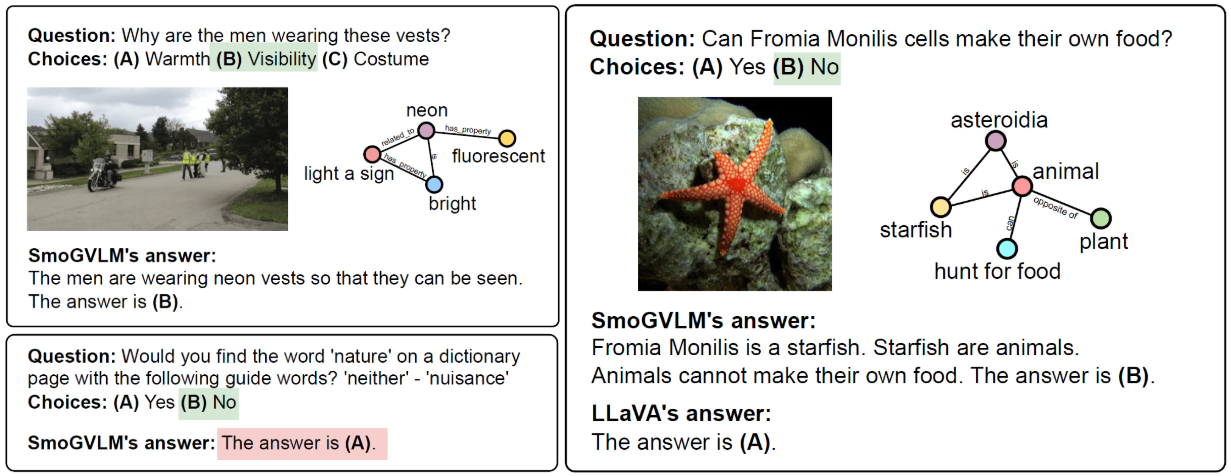
Figure 3. A few qualitative samples showing the strengths and limits of structured knowledge with VLMs.
Figure 3 shows qualitative examples. In the first sample, SmoGVLM retains strong visual reasoning while leveraging structured knowledge for a grounded answer. The second case shows how the availability of relevant triples allows SmoGVLM to predict the correct answer where LLaVA fails. The third example involves a definitional ('dictionary') question, where KG-based augmentation provides limited benefit.
Together, these examples show how structured knowledge can enhance reasoning while also revealing tasks where it provides little benefit.
Conclusion
We introduce SmoGVLM, a small, graph-enhanced VLM for knowledge-intensive question answering. By incorporating structured KGs with GNNs, SmoGVLM enables smaller models to outperform larger baselines. This highlights a promising path towards efficient, knowledge-grounded intelligence. Despite these gains, limitations remain. KGs like ConceptNet offer incomplete coverage, and our fusion strategy is based on simple concatenation.
In the future, we plan to explore richer fusion mechanisms and broader benchmarks.
References
[1] Haotian Liu, Chunyuan Li, QingyangWu, and Yong Jae Lee, “Visual instruction tuning,” 2023.
[2] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi, “Blip-2: Bootstrapping language-image pretraining with frozen image encoders and large language models,” arXiv preprint arXiv:2301.12597, 2023.
[3] Robyn Speer, Joshua Chin, and Catherine Havasi, “Conceptnet 5.5: An open multilingual graph of general knowledge,” 2017.
[4] Michihiro Yasunaga, Hongyu Ren, Antoine Bosselut, Percy Liang, and Jure Leskovec, “QA-GNN: Reasoning with language models and knowledge graphs for question answering,” in Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, June 2021, pp. 535–546, Association for Computational Linguistics.
[5] Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan, “Learn to explain: Multimodal reasoning via thought chains for science question answering,” in Advances in Neural Information Processing Systems, Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, Eds., 2022.
[6] Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi, “Aokvqa: A benchmark for visual question answering using world knowledge,” arXiv, 2022.
[7] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al., “Llama 2: Open foundation and fine-tuned chat models, arXiv preprint arXiv:2307.09288, 2023.
[8] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever, “Learning transferable visual models from natural language supervision,” in Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, Marina Meila and Tong Zhang, Eds. 2021, vol. 139 of Proceedings of Machine Learning Research, pp. 8748–8763, PMLR.
[9] Debjyoti Mondal, Suraj Modi, Subhadarshi Panda, Rituraj Singh, and Godawari Sudhakar Rao, “Kam-cot: Knowledge augmented multimodal chain-of-thoughts reasoning,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2024, vol. 38, pp. 18798–18806.
[10] Dan Busbridge, Dane Sherburn, Pietro Cavallo, and Nils Y. Hammerla, “Relational graph attention networks,” 2019.
[11] Thomas N. Kipf and Max Welling, “Semi-supervised classification with graph convolutional networks,” in 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. 2017, OpenReview.net.




