AI
ADORE: Asymmetric Relational Distillation with Reranking for Instance Level Image Retrieval
|
The IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) is an annual flagship conference organized by IEEE Signal Processing Society. ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. It features a broad technical program showcasing the latest developments in research and technology, attracting thousands of professionals from both academia and industry. In this blog series, we highlight our research papers presented at ICASSP 2026. Below is a list of our contributions. #1. Whisper-Fest: Single-Channel Far-Field Enhanced Speech-to-Text Without Parallel Data #2. Triage Knowledge Distillation for Speaker Verification #4. DeMo-Pose: Depth-Monocular Modality Fusion for Object Pose Estimation #5. GalaxyEdit: Large Scale Image Editing Dataset with Enhanced Diffusion Adapter #6. ADORE: Asymmetric Relational Distillation with Reranking for Instance Level Image Retrieval #7. T-GEMS: Text-Guided Exit Modules for Decreasing CLIP Image Encoder #8. SmoGVLM: A Small, Graph-Enhanced Vision-Language Model #9. On the Importance of a Multi-Scale Calibration for Quantization #10. Differentially Private Clustered Federated Learning with Privacy-Preserving Initialization and Normality-Driven Aggregation #11. Self-Attention Decomposition for Training Free Diffusion Editing |
Introduction
Instance-level image retrieval aims to identify exact object or scene matches from large image collections, unlike object-level retrieval which targets broader categories. While deep models have significantly improved retrieval performance, deploying them in practical settings requires balancing accuracy with computational efficiency.
In real-world visual search scenarios, queries must be processed efficiently on-device, while large-scale image collections can be indexed offline. Using a single heavy model for both query and database images is computationally expensive, whereas lightweight models alone often degrade accuracy. This motivates asymmetric retrieval, where database descriptors are computed using a powerful model offline, and queries are processed using a lightweight model.
A key challenge in this setup is aligning the representations produced by the two models. Knowledge distillation (KD) is commonly used to transfer knowledge from teacher to student, but existing approaches primarily focus on aligning individual representations and often overlook the relational structure of the embedding space.
Re-ranking further improves retrieval by incorporating fine-grained matching, but existing methods based on geometric verification or transformer-based models are computationally expensive. In asymmetric settings, re-ranking is additionally challenged by discrepancies between teacher and student representations.
This blog post explains how we tackle the above-mentioned problems using the following novel contributions:
Background and Related Work
Global vs Local Representations
Recent retrieval methods such as CV-Net and AMES leverage both global and local features to achieve high accuracy, but incur significant computational and memory overhead due to complex matching or transformer-based designs. In contrast, Super-Global relies purely on global descriptors, offering efficiency but lacking fine-grained matching capability.
Asymmetric Retrieval and Knowledge Distillation.
To address efficiency constraints, asymmetric retrieval uses lightweight models for queries and stronger models for database images. Prior distillation approaches, including asymmetric metric learning and contrastive methods, focus on aligning individual representations but do not explicitly preserve relational structure in the embedding space.
Re-ranking Strategies.
Re-ranking improves retrieval through local feature matching. Traditional approaches rely on geometric verification methods such as RANSAC and DELG. More recent methods, including CV-Net, R2Former, and AMES, model richer correspondences but remain computationally expensive, limiting their practicality in resource-constrained settings.
Methodology
Our approach ADORE, addresses asymmetric retrieval through two components: knowledge distillation for aligning query and database representations and efficient asymmetric re-ranking.
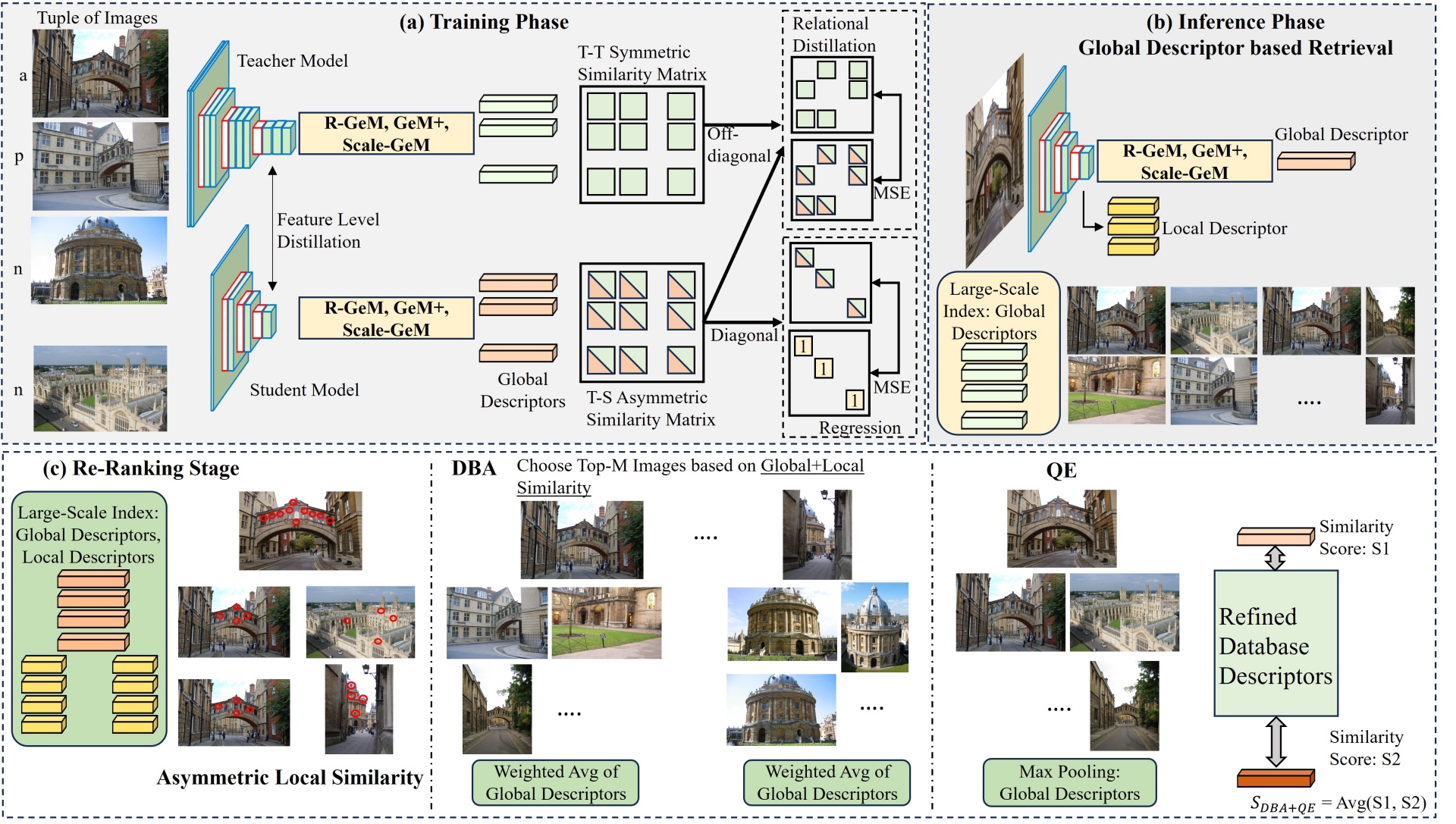
Figure 1. Illustration of the ADORE framework: (a) asymmetric training with distillation losses, (b) Initial retrieval using global descriptors, and (c) asymmetric re-ranking with local similarity, DBA, and QE.
Aligning Query and Database Representations
We use a large teacher model f(.) to encode database images and train a lightweight student model g(.) to generate query embeddings in the same space. For training, we use tuples consisting of an anchor, a positive sample, and multiple negative samples, along with three loss functions (Refer to Figure 1).
For the same image (say t) student and teacher representations should be as close as possible.
$ L_{abs}=(1-cosine(f(t),g(t)))^2 $
Two images (say t and t') closer (or farther) in the teacher space, should also be closer (or farther) in the student space.
$ L_{rel}=(cosine(f(t),f(t^\prime))-cosine(g(t),g(t^\prime)))^2 $
This aligns mid-level representations by computing MSE between feature maps from teacher and student layers with matching spatial dimensions. This is helpful for generating aligned local descriptors.
The final objective is a weighted combination of the above three losses.
Efficient Asymmetric Re-Ranking
After the initial retrieval using global descriptors, we refine the top K results using an asymmetric re-ranking strategy. This includes the following:
For each local feature in the query, we identify its best matching feature in the database image and note their similarity. The final local similarity score between query and any database image is obtained by aggregating these best matches across all query features. This process emphasises images with consistent local correspondences, helping filter out false positives that may appear at a global level, but differ in fine details.
We further refine the global database embeddings using Database Augmentation (DBA). Each database embedding is updated by incorporating information from its top M nearest neighbours (among the top K results from coarse retrieval). Contribution of each top M embedding is weighted based on a combination of local and global similarity scores between the top M embedding and the given database embedding. This distinguishes our approach from prior methods, which rely solely on global similarity for weighting. This ensures that only visually consistent neighbors contribute to the refinement.
Similarly, we refine the global query embedding by incorporating information from its top M nearest neighbours (among the top K results from coarse retrieval). Like DBA, Query Expansion (QE) also uses both local and global similarity scores for weighing the contributions.
Both DBA and QE ensure that the query and candidate database embeddings are robust to noise and variations in viewpoint, scale and illumination.
The final re-ranking score combines local similarity and global similarity (between refined global descriptors).
Experiments and Results
Experimental Setup
Our framework is trained on SfM120k and GLDv2, with evaluation on ROxford5k and RParis6k benchmarks. The teacher model uses pretrained ResNet-101 (R101)-GeM on SfM120k and R101-CVNet on GLDv2, generating 2048-dimensional global descriptors. The student model (ComRes) starts as R101 and is progressively compressed by removing one residual block every two epochs during training.
Results

Figure 2. Qualitative comparison of retrieval results from Super-Global and ADORE reranking
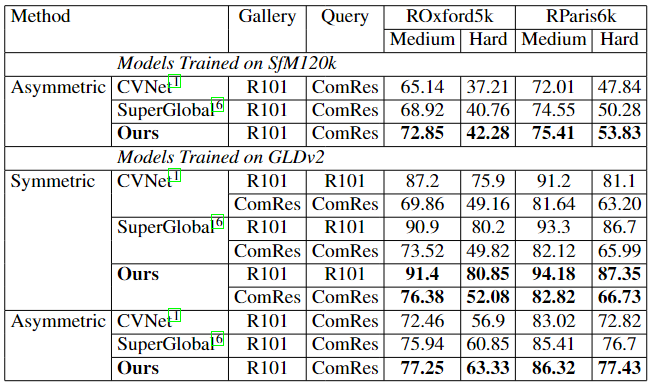
Table 1. Quantitative comparison (mAP values) of asymmetric retrieval with prior methods
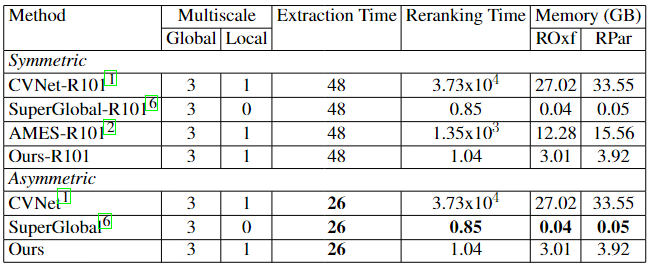
Table 2. Comparison of computational efficiency (time in ms) of asymmetric retrieval methods
Conclusion
We presented ADORE, an asymmetric image retrieval framework that combines hybrid knowledge distillation with efficient re-ranking to address the accuracy–efficiency trade-off in instance-level retrieval. By aligning both individual representations and their relational structure, the student model remains compatible with a high-capacity gallery representation.
The proposed re-ranking further improves retrieval quality through efficient local matching and descriptor refinement, without the high cost of prior methods. Experiments show strong performance across both asymmetric and symmetric settings with significantly improved efficiency.
From an application perspective, ADORE is well-suited for image-to-image search in on-device photo collections, where queries must be processed under strict latency constraints. The design enables heavier models to run in the background to build high-quality gallery representations, while lightweight models handle queries efficiently at runtime. This makes ADORE a practical building block for improving retrieval quality in privacy-preserving, real-world settings.
References
[1] S. Lee, H. Seong, S. Lee, and E. Kim, “Correlation verification for image retrieval,” in Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition, New Orleans, USA, 2022, pp. 5374–5384.
[2] P. Suma, G. Kordopatis-Zilos, A. Iscen, and G. Tolias, “Ames: Asymmetric and memory-efficient similarity estimation for instance-level retrieval,” in Proceedings of the European Conference on Computer Vision, Milano, Italy, 2024, pp. 307–325.
[3] M. Budnik and Y. Avrithis, “Asymmetric metric learning for knowledge transfer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8228–8238.
[4] F. Tan, J. Yuan, and V. Ordonez, “Instance-level image retrieval using reranking transformers,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 12 105–12 115.
[5] S. Zhu, L. Yang, C. Chen, M. Shah, X. Shen, and H. Wang, “R2former: Unified retrieval and reranking transformer for place recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023, pp. 19 370–19 380.
[6] S. Shao, K. Chen, A. Karpur, Q. Cui, A. Araujo, and B. Cao, “Global features are all you need for image retrieval and reranking,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris,France, 2023, pp. 11 036–11 046.




