AI
DeMo-Pose: Depth–Monocular Modality Fusion for Object Pose Estimation
|
The IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) is an annual flagship conference organized by IEEE Signal Processing Society. ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. It features a broad technical program showcasing the latest developments in research and technology, attracting thousands of professionals from both academia and industry. In this blog series, we highlight our research papers presented at ICASSP 2026. Below is a list of our contributions. #1. Whisper-Fest: Single-Channel Far-Field Enhanced Speech-to-Text Without Parallel Data #2. Triage Knowledge Distillation for Speaker Verification #4. DeMo-Pose: Depth-Monocular Modality Fusion for Object Pose Estimation #5. GalaxyEdit: Large Scale Image Editing Dataset with Enhanced Diffusion Adapter #6. ADORE: Asymmetric Relational Distillation with Reranking for Instance Level Image Retrieval #7. T-GEMS: Text-Guided Exit Modules for Decreasing CLIP Image Encoder #8. SmoGVLM: A Small, Graph-Enhanced Vision-Language Model #9. On the Importance of a Multi-Scale Calibration for Quantization #10. Differentially Private Clustered Federated Learning with Privacy-Preserving Initialization and Normality-Driven Aggregation #11. Self-Attention Decomposition for Training Free Diffusion Editing |
Introduction
Accurate estimation of the 9-DoF object pose—comprising 3D position, orientation, and absolute size—is a fundamental problem in computer vision. Robust pose prediction enables critical applications in robotic manipulation, autonomous navigation, and AR/VR scene understanding, where reliable 3D reasoning is essential. 3D pose estimation is widely used in AR/VR with head-mounted displays (HMDs), smartphones, and gaming. However, inaccurate 9-DoF pose (rotation, translation, size) degrades AR user experience and poses risks in critical tasks like autonomous navigation, highlighting the need for robust pose estimation.

Figure 1. Impact of inaccurate rotation, scale, and translation when overlaying a virtual keyboard template on a physical keyboard in mixed reality. The bottom image shows correct alignment using pose estimation for improved user experience, as seen through the HMD.
While significant progress has been made in 6D pose estimation, most existing approaches remain limited to instance-level settings, often requiring precise CAD models at inference. Such methods fail to generalize to category-level pose estimation, where unseen objects from known categories must be localized and scaled. Recent works have explored this problem, but depth-only approaches typically outperform RGB-D methods, indicating that current RGB–Depth fusion strategies are suboptimal.
Instance-Level Pose Estimation
Significant progress has been made in 6D instance-level pose estimation, where methods predict the pose of known objects with CAD models available. Existing approaches include direct regression [1,2], learning latent embeddings for pose retrieval [3], correspondence-based methods with Perspective-n-Point (PnP) solvers [4], and fusion-based techniques [5]. Despite strong performance, these methods are limited in practice: they require precise CAD models and typically handle only a small set of object instances.
Category-Level Pose Estimation
Category-level methods aim to generalize pose estimation to unseen objects from known categories, without relying on CAD models. Early works introduced canonical spaces such as NOCS [6] and its extensions [7,8], while later approaches incorporated geometric priors or dual networks [9,10]. Depth-only methods have shown superior accuracy compared to RGB-D fusion [11], highlighting a gap in leveraging semantic cues from RGB images. Recent self-supervised strategies [12,13] reduce annotation cost but still lag behind supervised baselines in accuracy and efficiency.
In summary, prior work either sacrifices generalization (instance-level) or fails to exploit RGB–Depth complementarity effectively (category-level). Our work addresses this gap by fusing monocular RGB features with depth-based representations, coupled with a novel geometry-aware loss, to achieve robust and real-time category-level 9-DoF pose estimation.
Contributions:
We introduce DeMo-Pose, a hybrid framework for category-level 9-DoF object pose estimation. Our key contributions are:
Method
We propose DeMo-Pose, a novel hybrid architecture that fuses semantic information derived from RGB input with features obtained from a depth-based pose estimation model. Given an RGB image as input, we propose a single-stage detector architecture that can predict projected 3D-keypoints and relative size of objects. The network learns pose-rich semantic and object-related cues through end-to-end training. These spatial features are used to accurately predict and improve the depth-based pose estimation model. To further improve geometry reasoning, we introduce a Mesh-Point Loss (MPL) that leverages mesh structure during training without increasing inference cost.
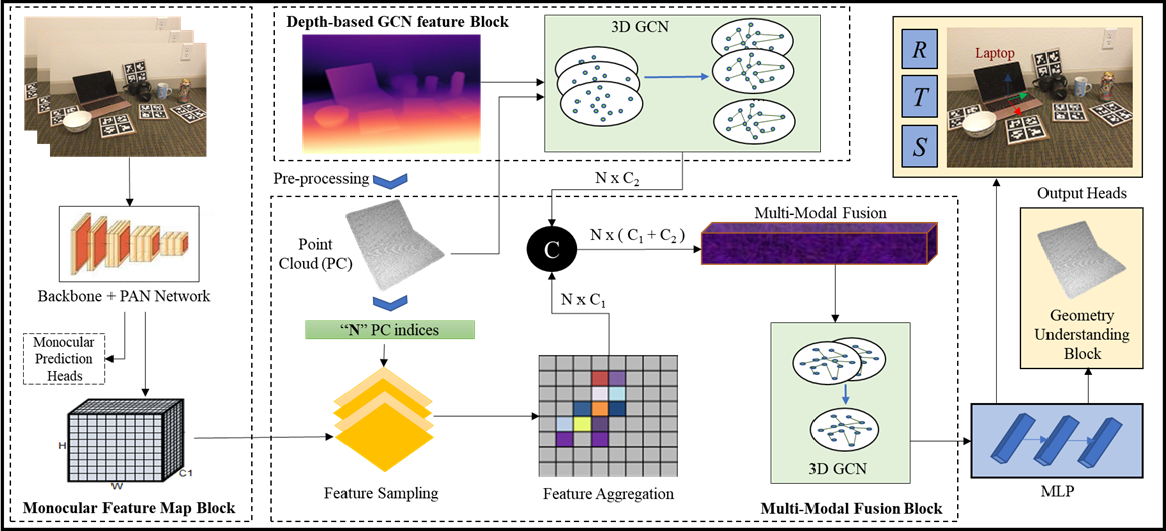
Figure 2. Fusion module architecture: RGB features obtained from the monocular detection model are fused with depth-based GCN features. At inference, the system achieves real-time performance suitable for device deployment.
2.1 Monocular Detection
Given an RGB input, our monocular method targets category-level 3D object pose estimation. Unlike approaches such as CenterPose [14], which employ separate networks per category, we adopt a generic single-stage detector scalable across object classes. Following prior works [1,9], we predict 2D projections of 3D cuboid corners and apply a Perspective-n-Point (PnP) algorithm to recover object pose. We leverage FCOS [15] backbone and pyramid features to predict 2D keypoints, class labels, and relative object size.
Training explicitly exploits RGB semantics to learn rich pose cues by predicting relative object dimensions instead of absolute depth, thereby addressing the ill-posed nature of monocular depth estimation. The monocular network consists of a Backbone, Path Aggregation Network (PAN), and three Monocular Prediction Heads. We use GhostNet [16] as the backbone, where the Ghost module efficiently generates feature maps through inexpensive linear transformations — a strong choice for embedded devices due to its balance of accuracy and efficiency.
Three prediction heads jointly perform: (i) regression of 8 projected 2D keypoints of a cuboid enclosing the object, (ii) classification of the object, and (iii) regression of its relative dimensions. These heads share stages for efficient learning. The network is trained end-to-end with GIoU loss, quality focal loss, and distributional focal loss [17].
Once the monocular model is trained, it is frozen and the semantically rich PAN features are used as the Monocular Feature Map for fusion in the hybrid model.
2.2 Depth-Based Backbone and Fusion
Depth information is essential for 9-DoF pose estimation. Recently, 3D graph convolution (3DGC) [18] has gained popularity due to its robustness to point cloud shift and scale. GPV-Pose [11] employs 3DGC as a backbone to extract global and local features, enabling confidence-driven closed-form 3D rotation recovery. It achieves ~20 FPS on standard benchmarks, making it an effective depth-based baseline for our Depth–Monocular fusion approach.
Following GPV-Pose, we pre-process depth maps with Mask-RCNN [19] to segment objects, back-project to 3D, and sample 1028 points as input. The 3DGC extracts global and per-point features, which are fed to regression heads to predict pose {r, t, s} (Rotation, Translation, Size). However, depth-only features are sensitive to noise, occlusion, sampling, and segmentation. In contrast, RGB images provide contextual and semantic cues (e.g., occlusion and background information) useful for pose estimation.
Monocular features (H×W×C₁) and depth-based features (N×C₂) lie in different spaces. We align them via a feature sampling module: using indices of N sampled point cloud points, their spatial locations are bilinearly interpolated on the monocular feature map to form an N×C₁ tensor. This makes features dimensionally compatible with depth-based features for fusion. While we adopt concatenation for simplicity, our approach generalizes to other fusion strategies such as addition, Hadamard multiplication, or MLP-based fusion.
2.3 Geometry-Aware Mesh-Point Loss (MPL)
To further regularize pose estimation, we introduce the Mesh-Point Loss (MPL). During training, a subset of vertices is sampled from the ground-truth object mesh using Poisson disk sampling [20]. The network predicts corresponding mesh points, and the L2 distance between predicted and ground-truth vertices is minimized:
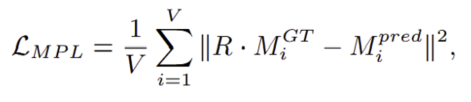
where Mᵢᴳᵀ and Mᵢᵖʳᵉᵈ are ground-truth and predicted vertices, and R is the ground-truth rotation. MPL is inspired by PoseLoss proposed in PoseCNN [21], but unlike PoseLoss, MPL can handle object symmetries since it directly supervises 3D point distributions rather than rotation parameters. Since mesh predictions are only required during training, MPL introduces no overhead at inference. The total loss combines the base loss with MPL:
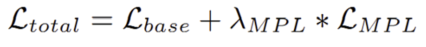
where λ_MPL is a hyperparameter and ℒ_base denotes the standard GPV-Pose regression loss supervising rotation, translation, and scale.
The proposed architecture achieves three desirable properties: (i) effective fusion of semantic RGB and depth-based geometry, (ii) geometry-aware training via MPL, and (iii) efficient inference, as monocular features can also be used standalone in resource-constrained scenarios.
Experiments
3.1 Implementation Details
To ensure fair benchmarking, we train our method purely on real data, following prior work [3,9,11], and generate instance masks using Mask-RCNN [19]. Adopting the GPV-Pose setup, 1028 points are uniformly sampled from the back-projected depth map as input to the depth-based model. Multi-modal fused features are trained with existing losses using default hyperparameters. For Mesh-Point Loss, we introduce a scalar weight λ_MPL empirically set to 2000. Training is conducted in PyTorch on the REAL275 dataset with a single model across all categories.
3.2 Dataset and Evaluation Metrics
We evaluate DeMo-Pose on the widely used REAL275 benchmark [6], which consists of 13 challenging real-world scenes covering six object categories: bottle, bowl, camera, can, laptop, and mug. Following standard protocol, 7 scenes (~4.3k images) are used for training and 6 scenes (~2.7k images) for testing.
We report: (i) 3D IoU at 25%, 50%, and 75% thresholds (3D₂₅, 3D₅₀, 3D₇₅) to evaluate joint translation, rotation, and size accuracy; (ii) pose accuracy under combined rotation and translation thresholds: 5°2cm, 5°5cm, 10°5cm, and 10°10cm; and (iii) frame rate (FPS) for each method.
3.3 Results
Table 1 compares DeMo-Pose with representative instance and category-level baselines on REAL275. Our method achieves consistent improvements across most metrics (5 out of 6). Notably, DeMo-Pose surpasses the strong depth-only baseline GPV-Pose by 3.2% on 3D₇₅ IoU and 11.1% on 5°5cm pose accuracy. Furthermore, for the 10°5cm and 10°10cm metrics, we surpass prior art by a relative increase of 8.1% and 7.4% respectively, while running at nearly real-time speed (FPS ≈ 18).
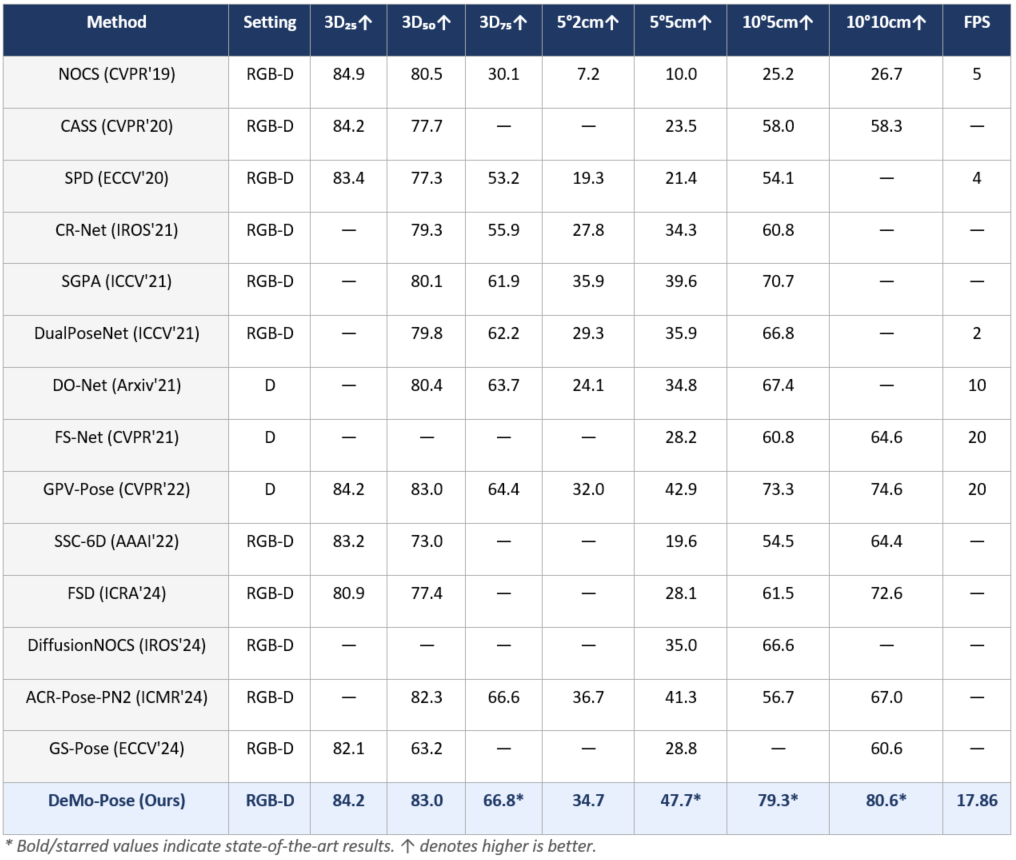
Table 1. Comparison with State-of-the-Art Methods on REAL275
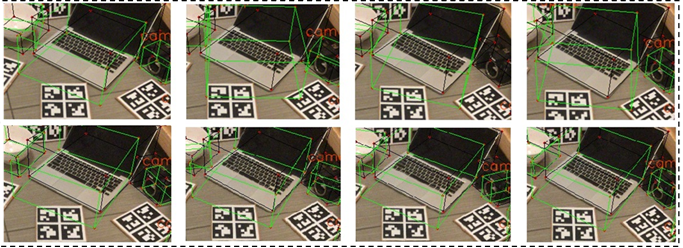
Figure 3-a. Comparison of predictions across video frames: GPV-Pose exhibits temporal instability for the laptop category (top row), while DeMo-Pose fusion yields stable predictions (bottom row).

Figure 3-b. Predictions (green boxes) vs. ground truth (black boxes): our method produces tighter, more accurate bounding boxes for laptop and mug.
Qualitative analysis reveals that our fusion strategy produces more stable predictions than GPV-Pose. For a given sequence of video frames, GPV-Pose predictions flicker for the laptop category, while DeMo-Pose exhibits improved temporal consistency and stability. The results highlight that: (i) RGB cues provide complementary semantics missing in depth-only pipelines, (ii) MPL improves geometry awareness and robustness, and (iii) the hybrid model achieves real-time inference, making it suitable for deployment in AR/VR and robotics.
3.4 Ablation on Mesh-Point Loss (MPL)
To understand the efficacy of the proposed MPL, we analyze performance through an ablation study. Adding MPL consistently improves performance across all metrics, demonstrating that explicitly supervising geometry strengthens category-level pose prediction.

Table 2. Ablation Study – Mesh-Point Loss on REAL275
3.5 Ablation on RGB-D Fusion Strategies
We conducted an ablation study on different fusion mechanisms: (i) Concatenation — RGB and depth features are directly concatenated; (ii) MLP-based fusion with skip connection — features are projected into a common space; and (iii) Attention-based fusion with skip connection — cross-modal attention adaptively weighs RGB and depth features. Results are summarized in Table 3.
Simple concatenation remains the most effective strategy for RGB-D integration in the proposed framework, without introducing any additional complexity.

Table 3. Ablation Study – RGB-D Fusion Strategies
4. Conclusion
We presented DeMo-Pose, a hybrid framework for category-level 9-DoF object pose estimation that fuses semantic RGB features with depth-based geometric representations. By introducing a novel Mesh-Point Loss (MPL), our method strengthens geometry awareness during training without adding inference overhead.
Extensive experiments on the REAL275 benchmark demonstrate that DeMo-Pose achieves state-of-the-art performance, surpassing strong depth-only baselines by 3.2% on 3D IoU and 11.1% on pose accuracy, while maintaining efficient inference (FPS ≈ 18). These results highlight the effectiveness of multi-modal fusion and geometry-aware training for robust 3D vision.
In future work, we plan to extend DeMo-Pose towards generative frameworks and large-scale datasets for holistic 3D scene understanding, enabling broader applications in AR/VR and robotics.
References
[1] Kehl, W. et al. (2017). SSD-6D: Making RGB-based 3D detection and 6D pose estimation great again. ICCV 2017.
[2] Hu, Y. et al. (2020). Single-stage 6D object pose estimation. CVPR 2020.
[3] Tian, M. et al. (2020). Robust 6D object pose estimation by learning RGB-D features. ECCV 2020.
[4] Park, K. et al. (2019). Pix2Pose: Pixel-wise coordinate regression of objects for 6D pose estimation. ICCV 2019.
[5] He, Y. et al. (2021). FFB6D: A full flow bidirectional fusion network for 6D pose estimation. CVPR 2021.
[6] Wang, H. et al. (2019). Normalized object coordinate space for category-level 6D object pose and size estimation. CVPR 2019.
[7] Chen, W. et al. (2020). CASS: Learning canonical shape space for category-level 6D object pose and size estimation. CVPR 2020.
[8] Lin, J. et al. (2021). DualPoseNet: Category-level 6D object pose and size estimation using dual pose network with refined learning of pose consistency. ICCV 2021.
[9] Chen, K. et al. (2021). SGPA: Structure-guided prior adaptation for category-level 6D object pose estimation. ICCV 2021.
[10] Lin, J. et al. (2021). DualPoseNet: Category-level 6D object pose and size estimation using dual pose network. ICCV 2021.
[11] Di, Y. et al. (2022). GPV-Pose: Category-level object pose estimation via geometry-guided point-wise voting. CVPR 2022.
[12] Peng, J. et al. (2022). Self-supervised category-level 6D object pose estimation with deep implicit shape representation. AAAI 2022.
[13] Lunayach, M. et al. (2024). FSD: Fast self-supervised single RGB-D to categorical 3D objects. ICRA 2024.
[14] Lin, J. et al. (2022). Single-stage keypoint-based category-level object pose estimation from an RGB image. ICRA 2022.
[15] Tian, Z. et al. (2019). FCOS: Fully convolutional one-stage object detection. ICCV 2019.
[16] Han, K. et al. (2020). GhostNet: More features from cheap operations. CVPR 2020.
[17] Li, X. et al. (2020). Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. NeurIPS 2020.
[18] Lin, H. et al. (2020). Convolution in the cloud: Learning deformable kernels in 3D graph convolution networks for point cloud analysis. CVPR 2020.
[19] He, K. et al. (2017). Mask R-CNN. ICCV 2017.
[20] Yuksel, C. (2015). Sample elimination for generating Poisson disk sample sets. Computer Graphics Forum 2015.
[21] Xiang, Y. et al. (2017). PoseCNN: A convolutional neural network for 6D object pose estimation in cluttered scenes. RSS 2018.
[22] Di, Y. et al. (2021). SO-Pose: Exploiting self-occlusion for direct 6D pose estimation. ICCV 2021.
[23] Wang, C. et al. (2021). Category-level 6D object pose estimation via cascaded relation and recurrent reconstruction networks. IROS 2021.
[24] Chen, X. et al. (2021). FS-Net: Fast shape-based network for category-level 6D object pose estimation with decoupled rotation mechanism. CVPR 2021.
[25] Lin, J. et al. (2021). DualPoseNet: Category-level 6D object pose and size estimation. ICCV 2021.




