AI
Self-Attention Decomposition for Training Free Diffusion Editing
|
The IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) is an annual flagship conference organized by IEEE Signal Processing Society. ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. It features a broad technical program showcasing the latest developments in research and technology, attracting thousands of professionals from both academia and industry. In this blog series, we highlight our research papers presented at ICASSP 2026. Below is a list of our contributions. #1. Whisper-Fest: Single-Channel Far-Field Enhanced Speech-to-Text Without Parallel Data #2. Triage Knowledge Distillation for Speaker Verification #4. DeMo-Pose: Depth-Monocular Modality Fusion for Object Pose Estimation #5. GalaxyEdit: Large Scale Image Editing Dataset with Enhanced Diffusion Adapter #6. ADORE: Asymmetric Relational Distillation with Reranking for Instance Level Image Retrieval #7. T-GEMS: Text-Guided Exit Modules for Decreasing CLIP Image Encoder #8. SmoGVLM: A Small, Graph-Enhanced Vision-Language Model #9. On the Importance of a Multi-Scale Calibration for Quantization #11. Self-Attention Decomposition for Training Free Diffusion Editing |
1. Introduction
Diffusion models have established themselves as the state-of-the-art for generative modeling, producing high-fidelity images through iterative denoising. However, making precise, targeted edits—such as changing someone's age or adjusting a hairstyle—remains a significant challenge.
Our approach demonstrates that the key to semantic editing has been present inside pretrained diffusion models all along. No additional training. No massive image datasets. The solution lies in applying eigen decomposition to self-attention weight matrices. This approach enables quick and precise editing of image attributes without requiring time-consuming fine-tuning of the diffusion models. Figure 1 shows the training-free editing capabilities of our method.

Figure 1. Illustration of editing capabilities with our method. The first row demonstrates the linear editing property as the perturbation strength α is varied. The second row highlights the ability of our method to perform precise edits to facial attributes.
2. The Challenge with Current Approaches
To understand the solution, we first need to examine why editing diffusion model outputs is challenging.
2.1 The Unstructured Latent Space
Unlike GANs, which have a well-structured latent space, diffusion models operate through a multi-step denoising process. This iterative approach creates an unstructured latent space where semantic attributes (such as age, gender, or expression) are entangled, making them difficult to isolate and manipulate independently.
2.2 Limitations of Existing Methods
Current methods for discovering editing directions typically fall into two categories:
A comparison of the drawbacks in existing methods is provided in Table 1. Our method is independent of sample, allows localized edit and requires no supervised training.
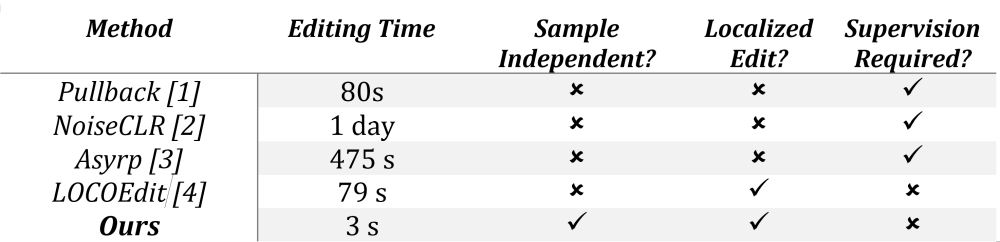
Table 1. Drawbacks of existing methods for diffusion editing
3. The Key Insight: Self-Attention Weights as Semantic Priors
The breakthrough came from examining the self-attention layers [5] more closely.
Self-attention layers in diffusion models are known to encode rich structural and semantic information. The key insight is that the
3.1 Why Self-Attention?
In a self-attention block, input features are transformed via three learned projection matrices:
$Queries (Q): ZW_Q; Key (K): ZW_K; Value (V): ZW_v$
Here, Z denotes a latent feature map, and $W_Q$,$W_k$,$W_v$ are learnt weight matrices. These matrices encode how the model attends to different parts of an image. By performing eigen decomposition on these weight matrices, we can extract the principal directions that correspond to semantic attributes.
During training, the model learns to associate certain patterns with specific semantic concepts. These associations are mathematically encoded in the eigenvectors of the attention weights.
4. The Method: Eigen Decomposition for Editing Directions
The approach can be broken down into four key steps.
4.1 Step 1: Defining the perturbation objective
The goal is to find a direction $\boldsymbol n$ in the latent space that maximizes the change in the attention output when we perturb the input:
$ Z^\prime=Z+α \boldsymbol n ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ (1)~~~~~~~~~~~~~~~~~~$
Where α controls the edit strength and $\boldsymbol n$ is the direction to be discovered. The change in self attention output due to this perturbation is
$ ΔAttn=Attn(Z^\prime)-Attn(Z) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(2)~~~~~~~~~~~~~~~~~~$
Our objective is to derive directions $\boldsymbol n^*$ that maximize the impact on the attention output, thus directly correspond to axes of semantic variation.
$ \boldsymbol n^*=arg max||ΔAttn||_2^2 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(3)~~~~~~~~~~~~~~~~~~$
4.2 Step 2: Leveraging Latent Whitening
During early denoising steps (specifically when 0.8T ≥ t ≥ 0.5T) (t is the timestep of diffusion process), the intermediate representations in the U-Net are approximately whitened—their feature covariances are close to the identity matrix.
$E[Z^T Z] \thicksim I ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(4)~~~~~~~~~~~~~~~~~~$
This property is crucial because it allows us to isolate the effect of self-attention from the data distribution, enabling a clean mathematical derivation.
4.3 Step 3: Weight Space Eigen Decomposition
Our analysis shows that the optimal editing directions emerge from the principal eigenvectors of a combined weight matrix:
$C=W_Q^T W_Q+W_K^T W_K+W_V^T W_v ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(5)~~~~~~~~~~~~~~~~~~$
The eigenvectors of this matrix C, correspond to semantically meaningful editing directions. The proof for this result is provided in the main paper.
4.4 Applying the Edit
Once the eigenvectors are computed, an edit can be applied using Eq. 1. Following the latent whitening assumption, this edit is most effective when applied at early denoising timesteps, before the image content forms. We empirically apply the edits for timesteps $ 0.5T \lt t \lt 0.8T $, where $T$ is the maximum value of the the timestep.
5. Results: Fast, Precise and Generalizable
The method achieves notable improvements over existing approaches:
5.1 Qualitative Results
Our method supports diverse edits on facial attributes as shown in Figure 2.

Figure 2. Our method supports a diverse range of edits with improved disentanglement, enabling precise single-step manipulation of the target attribute beyond existing benchmarks.
It can be seen that our method enables precise editing of facial attributes compared to the existing methods. For example, our method is able to precisely control the eye size while keeping other identity preserving aspects intact.
As shown in Figure 3, Our formulation also allows to control the strength of the transformation being applied by varying the value of α. The approach exhibits a linear property: by varying α from -0.4 to 0.4, you obtain smooth, predictable changes in attribute intensity. A value of α produces subtle changes, while α = 0.4 creates more pronounced edits.

Figure 3. Illustration of how the edit strength parameter α controls the linear change in attribute intensity.
5.2 Quantitative Comparisons
In our quantitative analysis, we measure both image‐level fidelity and semantic alignment to the intended edits. We measure pixel- and structure-level consistency using SSIM and PSNR, identity preservation via FaceNet [6] cosine similarity, and semantic alignment with the Directional CLIP, For evaluation, we test 15 semantic editing directions on 100 image samples, resulting in 1500 test cases.
As shown in Table 2, On the CelebA-HQ dataset, the method outperforms all baselines. Higher SSIM and PSNR indicate better image quality preservation. Higher ID-Similarity indicates that the person's identity is maintained. Higher Directional CLIP score indicates better alignment with the intended semantic change.

Table 2. Comparisons against existing methods. Our method outperforms the state-of-the-art on all metrics
5.3 Generalization Across Datasets
Our method is universally applicable across models pretrained on various datasets, as demonstrated in Figure 4, showcasing its effect on models pretrained on the LSUN dataset [5] (Cars, Cats, and Rooms). The principal vectors in these models represent variations in body pose and shape.

Figure 4. Effect of our proposed editing method on pretrained models across multiple datasets.
6. Conclusion
This work demonstrates that pretrained diffusion models already contain the components needed for controllable editing—we just need the appropriate mathematical approach to extract them.
By treating self-attention weights as a source of semantic information rather than just computational machinery, the method achieves:
When working with diffusion models, the solution for semantic editing may already be present in the weights, requiring only eigen decomposition to reveal it.
References
[1] Yong-Hyun Park, Mingi Kwon, Jaewoong Choi, Junghyo Jo, and Youngjung Uh, “Understanding the latent space of diffusion models through the lens of riemannian geometry,” in Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS), 2023.
[2] Yusuf Dalva and Pinar Yanardag, “Noiseclr: A contrastive learning approach for unsupervised discovery of interpretable directions in diffusion models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, p.24209–24218.
[3] Mingi Kwon, Jaeseok Jeong, and Youngjung Uh, “Diffusion models already have a semantic latent space,” in Proceedings of the 11th International Conference on Learning Representations (ICLR), 2023.
[4] Mingi Kwon, Jaeseok Jeong, and Youngjung Uh, “Diffusion models already have a semantic latent space,” in Proceedings of the 11th International Conference on Learning Representations (ICLR), 2023.
[5] Ashish Vaswani et.al, “Attention is all you need”, in Advances in neural information processing systems, 2023.
[6] Florian Schroff, Dmitry Kalenichenko, and James Philbin, “Facenet: A unified embedding for face
recognition and clustering,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 815–823.




