AI
Whisper-Fest: Single-Channel Far-Field Enhanced Speech-to-Text without Parallel Data
|
The IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) is an annual flagship conference organized by IEEE Signal Processing Society. ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. It features a broad technical program showcasing the latest developments in research and technology, attracting thousands of professionals from both academia and industry. In this blog series, we highlight our research papers presented at ICASSP 2026. Below is a list of our contributions. #1. Whisper-Fest: Single-Channel Far-Field Enhanced Speech-to-Text Without Parallel Data #2. Triage Knowledge Distillation for Speaker Verification #4. DeMo-Pose: Depth-Monocular Modality Fusion for Object Pose Estimation #5. GalaxyEdit: Large Scale Image Editing Dataset with Enhanced Diffusion Adapter #6. ADORE: Asymmetric Relational Distillation with Reranking for Instance Level Image Retrieval #7. T-GEMS: Text-Guided Exit Modules for Decreasing CLIP Image Encoder #8. SmoGVLM: A Small, Graph-Enhanced Vision-Language Model #9. On the Importance of a Multi-Scale Calibration for Quantization #10. Differentially Private Clustered Federated Learning with Privacy-Preserving Initialization and Normality-Driven Aggregation #11. Self-Attention Decomposition for Training Free Diffusion Editing |
Introduction
At Samsung R&D Institute India-Bangalore and Samsung Research America, we investigate the fundamental speech technologies that power everyday devices. One of the most pressing challenges we address is far‑field speech recognition, where users converse with their devices from a distance or in noisy environments, as illustrated in Figure 1.
Figure 1. An user conversing with device with some distance in room environment (Distances shown for representative purpose only)
When spoken speech is captured from a distance, the audio signal becomes weak, echoey, and noisy. Modern speech‑to‑text systems such as Whisper [1] are primarily trained on close‑up recordings, which means they perform best with near‑field speech. In typical indoor environments, far‑field speech leads to a pronounced decline in transcription accuracy. As the distance between the speaker and the microphone increases, the quality of the transcription deteriorates further [2]. This degradation hampers the reliability of conversational voice commands and captioning on edge devices like smart speakers and smartphones. Consequently, enhancing far‑field performance is crucial for enabling robust voice interactions in real‑world scenarios.
Practical Challenges:
Achieving robust far‑field automatic speech recognition (ASR) or speech‑to‑text (S2T) remains a significant challenge since the world’s first commercial speech‑recognition system was introduced in 1984 [3], especially for single‑channel systems that lack beamforming capabilities and spatial information.
In practice, while data‑augmentation techniques [4,5] and joint training of speech‑enhancement [6] with S2T can improve performance, they require substantial computational resources and often compromise accuracy for near‑field speech. Moreover, creating large volumes of paired near‑field and far‑field recordings is labor‑intensive, costly, and impractical at scale. Consequently, there is a strong demand for a lightweight, plug‑and‑play front‑end enhancement that can operate efficiently on edge devices. In real‑world deployments, existing S2T engines are difficult to retrain without sacrificing performance, and their processing pipelines cannot be easily modified due to complex inter‑module dependencies, further emphasizing the need for a simple, effective solution.
In this blog, we propose Whisper-Fest, a small frontend that enhances S2T accuracy for far-field conversational speech scenarios, in Whisper S2T framework.
Our contributions are manifold:
We evaluate Whisper-Fest performance on standard conversational AMI [7] and VOiCES [8] far-field datasets, and also on standard DNS dataset [9]. The proposed front‑end improves far‑field recognition while maintaining near‑field accuracy, addressing the typical trade‑off seen in DA or SE‑based methods. Now, let’s dive deep into further details.
Proposed Methodology
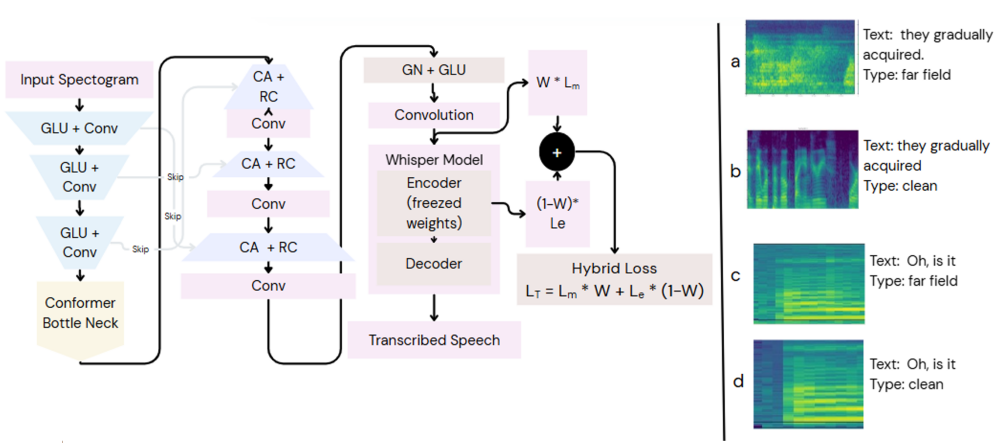
Figure 2. The proposed TU-Net architecture, detailing the encoder, conformer bottleneck with self-attention, and decoder with attention-based skip connections. (CA - Cross Attention, RC - Residual Connection, Conv - Convolution, GN - GroupNorm, GLU - Gated Linear Unit). (a-b): far field and clean spectrograms [VOiCES]. (c-d): SDM and IHM spectrograms [AMI]).
The TU‑Net model is a feature‑to‑feature speech‑enhancement architecture that operates on mel‑spectrogram inputs. Its encoder begins with a 7 × 7 two‑dimensional convolution that captures a broad time‑frequency context. This is followed by three down‑sampling stages; each stage consists of a residual block and a strided 4 × 4 convolution that halves the spatial resolution while doubling the channel depth, progressing from 64 channels to 128, then 256, and finally 512 channels. At the bottleneck, a conformer block combines two residual blocks (to model local patterns) with a self‑attention mechanism (to capture global dependencies), enabling the network to handle noise, reverberation, and long‑range acoustic events. The decoder mirrors the encoder with three transposed‑convolution up‑sampling blocks. At every up‑sampling level, features from the encoder are concatenated with the decoder features via skip connections, and a self‑attention layer fuses the high‑resolution details with the abstract bottleneck representation. The final output layer applies a 3 × 3 convolution to collapse the 64‑channel feature map into a single‑channel enhanced mel‑spectrogram, ready for downstream speech‑to‑text processing, as illustrated in Figure 2.
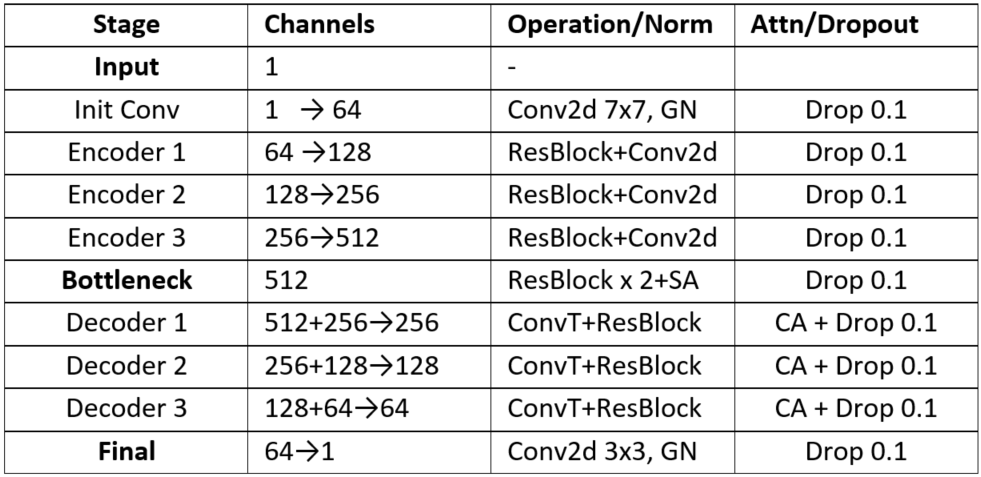
Table 1. TU-Net architecture data-dimension flow structure
Model Training
The training is organized into two stages. In the pre‑training stage, the model learns only to denoise, minimizing a time‑frequency loss Lm defined as the mean absolute error between the generated mel‑spectrogram and the clean reference. The fine‑tuning stage performs speech‑to‑text transfer learning, adding an encoder‑space loss Le that measures the mean‑squared error between the model’s intermediate features and those produced by a frozen Whisper‑tiny.en encoder. This frozen Whisper encoder acts as a fixed teacher, guiding the enhancement network to output spectrograms that are both visually clean and friendly to the downstream ASR system, thereby preserving information crucial for machine intelligibility. The hybrid loss balances these objectives: Lt = W·Lm + (1‑W)·Le, where Lm ensures structural fidelity in the time‑frequency domain and Le heavily penalizes deviations in the encoder’s feature space. Training data consist of a composite mix of AMI spontaneous conversations, VOiCES realistic reverberation recordings, and DNS diverse real‑world noises such as babble, all presented at signal‑to‑noise ratios of at least 0 dB to capture fundamental degradations while avoiding over‑fitting. The models are implemented in PyTorch and trained on a single NVIDIA A100 GPU.
Whisper Models & Fusion Strategy
The TU‑NET architecture enhances mel‑spectrograms so they can be fed directly into pretrained Whisper speech‑to‑text models, yielding better recognition performance for far‑field and noisy recordings. In our experiments we evaluated two English‑only Whisper variants: the tiny.en model, which comprises roughly 39 million parameters, a 4‑layer Transformer, and a model dimension of 384; and the small.en model, which contains about 244 million parameters, a 12‑layer Transformer, and a model dimension of 768. Both models accept the standard 80‑channel log‑mel input (shape 80 × T); for instance, a 30‑second audio clip is represented as a feature tensor of shape (80, 3000).
Datasets
AMI Dataset:
The AMI Meeting Corpus serves as a standard benchmark for far‑field speech‑to‑text research. It contains synchronized recordings from individual headsets (IHM) and multiple distant microphones (MDM). For training, approximately 50.7 hours of parallel data are provided, pairing the IHM speech with the corresponding distant speech captured by the first microphone of the MDM array, effectively forming a single distant‑microphone (SDM) configuration. Evaluation is performed on a distinct subset of about 1.2 hours of audio, which is reserved exclusively for testing the models.
VOiCES Dataset:
The VOiCES corpus is designed to assess speech technologies under realistic, reverberant, and noisy home‑environment conditions, offering roughly 120 hours of recordings per microphone. For our experiments we selected two specific channels from the studio setup: the first microphone, which captures near‑field speech, and the third microphone, which records distant (far‑field) speech. From these recordings we constructed a 14‑hour training set. The evaluation set comprises 48 hours of audio derived from a distinct 5‑hour subset that has been augmented with babble‑noise perturbations. This evaluation set is carefully balanced across four conditions: 18 hours of far‑field noisy speech (FF‑N), 6 hours of far‑field clean speech (FF‑C), 18 hours of near‑field noisy speech (NF‑N), and 6 hours of near‑field clean speech (NF‑C).
DNS Dataset:
The Deep Noise Suppression (DNS) Challenge dataset from Microsoft, is a large‑scale collection designed for robust speech enhancement research. It provides separate recordings of clean speech and a wide variety of real‑world noises. For training, the dataset includes approximately 81.2 hours of clean speech that has been mixed with babble and music noise sources, enabling models to learn to suppress diverse background sounds. The test set consists of a distinct 1.7‑hour segment, also formed by mixing clean speech with babble and music noises, which is used to evaluate how well a trained system generalizes to unseen noisy conditions.
Model Evaluation:
The proposed front‑end enhancement was evaluated against Whisper models on three demanding corpora—VOiCES, AMI, and DNS. On the VOiCES dataset it achieved a 64.7 % relative reduction in word‑error rate (WER) for reverberant far‑field‑clean (FF‑C) recordings and a 16.0 % relative reduction for far‑field noisy (FF‑N) conditions (Table 2). Near‑field recognition performance remained unchanged or improved slightly, confirming that the enhancement module can be inserted without degrading existing pipelines. When paired with the Whisper small.en model on the AMI meeting corpus, the approach yielded a 30.3 % relative WER reduction (Table 3), demonstrating robustness to the complex, overlapping‑speaker far‑field acoustics of that dataset. Three model variants were explored, differing in bottleneck channel dimension: Model‑A (128 channels), Model‑B (256 channels), and Model‑C (512 channels). Experiments also showed that pre‑training on clean targets is essential for the AMI corpus, whose challenging acoustic conditions benefit from a clean‑target initialization.

Table 2. WER/CER Comparisons in (%), { [Train: VOiCES train corpus NF+FF, Test: VOiCES eval corpus, SNR≥0dB, Models -A,B,C params/size=(12M/49.3MB),(19M/75MB),(43M/164MB)]}
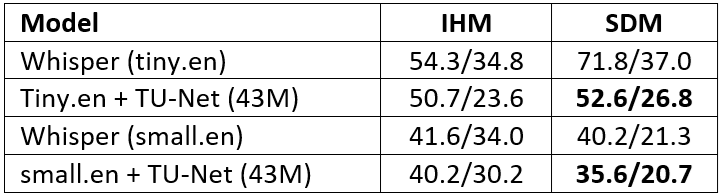
Table 3. WER/CER Comparisons in (%), {[Train: DNS (clean) + AMI (IHM+SDM) train corpus, Test: AMI (IHM,SDM], WER: word error rate, CER: character error rate}
Analysis & Ablations:
The proposed model employs a 7 × 7 convolutional kernel together with multiple repeated attention heads, which together create a large time–frequency receptive field. This design captures a broad temporal and spectral context, enabling the system to effectively dereverberate far‑field speech while leaving near‑field recordings untouched. Empirical results demonstrate substantial improvements: the word‑error rate (WER) for far‑field clean speech drops from 24.6 % to 8.6 %, and for far‑field noisy speech from 46.2 % to 38.8 %. Near‑field performance remains stable or even shows slight gains, confirming that the enhancement does not degrade, and may slightly improve, near‑field recognition. Figure 3 further illustrates that across a range of signal‑to‑noise ratios, the model’s near‑field curves overlap the baseline for both clean and noisy conditions, indicating no loss in accuracy. Overall, the combination of a large receptive field and repeated attention yields robust dereverberation for far‑field audio while preserving the integrity of near‑field speech.
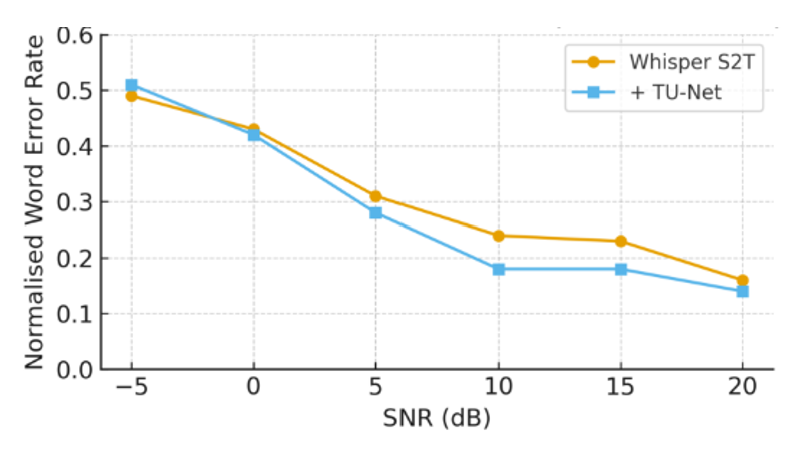
Figure 3. Ablations: DNS dataset near-field S2T performance Vs. SNR≥-5dB
State-of-the-art (SOTA) in Far-field S2T:
Even in today’s state‑of‑the‑art AI/ML deep‑tech landscape, the long‑standing far‑field speech‑to‑text challenge remains both open and demanding, especially when evaluated on real‑world datasets. Here, we made an attempt to significantly reduce ASR performance gaps for both near-field and far-field simultaneously. The difficulty of this task is most clearly illustrated by the word‑error rates (WERs) reported in Table 4, which highlight the substantial performance gaps still persist under distant speech and noisy conditions!!
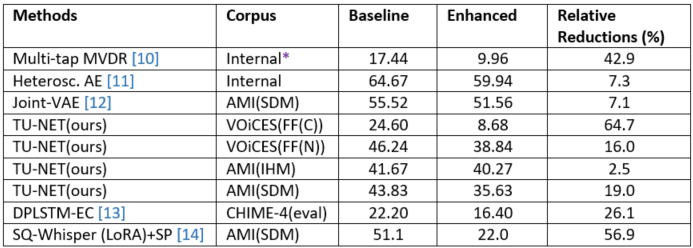
Table 4. Far-field Task Complexity WER Comparisons in (%), {*: multi-channel, otherwise single channel}
Discussion & Conclusions:
Link to the paper
1. https://ieeexplore.ieee.org/document/114610382. https://www.cmsworkshops.com/ICASSP2026/view_paper.php?PaperNum=9917&bare=1
References
[1] Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In Proceedings of the 40th ICML'2023, Vol. 202. JMLR.org, Article 1182, 28492–28518. Github: https://huggingface.co/openai/whisper-tiny
[2] R. Haeb-Umbach, J. Heymann, L. Drude, S. Watanabe, M. Delcroix and T. Nakatani. Far-Field Automatic Speech Recognition," in Proceedings of the IEEE, vol. 109, no. 2, pp. 124-148, Feb. 2021
[3] Höge, H., Ney, H., Schmidtbauer, O., Ziegenhain, U., Thurmair, G., Bunt, H. (2024) SPICOS - the first speech driven dialogue system. Proc. Sixth International Workshop on the History of Speech Communication Research (HSCR 2024), 198-207, doi: 10.21437/HSCR.2024-13
[4] T. Ko and et al. A Study on Data Augmentation of Reverberant Speech for Robust Speech Recognition. In ICASSP, pages 5220–5224, 2017
[5] T. Niu, Y. Chen, D. Qu, and H. Hu. Enhancing Far-Field Speech Recognition with Mixer: A Novel Data Augmentation Approach. Applied Sciences, 15(7), 2025.
[6] G.Woo Lee, H. Kook Kim, and D.-J. Kong. Knowledge Distillation-Based Training of Speech Enhancement for Noise-Robust Automatic Speech Recognition. IEEE Access, 12:72707–72720, 2024
[7] J. Carletta. Unleashing The Killer Corpus: Experiences in Creating The Multi-Everything AMI Meeting Corpus. Lang. Resource Evaluation, 41(2):181–190, 2007.
[8] C. Richey and et al. Voices Obscured in Complex Environmental Settings (VOiCES) Corpus. In Interspeech, pages 1566–1570, 2018.
[9] H. Dubey and et al. Deep Noise Suppression Challenge. In ICASSP, Rhodes Island, Greece, June 2023.
[10] Y. Xu and et al. Neural Spatio-Temporal Beamformer for Target Speech Separation. arXiv preprint arXiv:2005.03889, 2020.
[11] S. Kumar and et al. Far-Field Speech Enhancement Using Heteroscedastic Autoencoder for Improved Speech Recognition. In INTERSPEECH, pages 446–450, 2019.
[12] S. Kumar, S. P. Rath, and A. Pandey. Improved far-field speech recognition using joint variational autoencoder. arXiv preprint arXiv:2204.11286, 2022.
[13] X. Chang and et al. Module-Based End-to-End Distant Speech Processing: A case study of far-field automatic speech recognition. IEEE Signal Processing Magazine, 41(6):39–50, 2024.
[14] P. Guo, X. Chang, H. Lv, S. Watanabe, L. Xie. SQ-Whisper: Speaker-Querying based Whisper Model for Target-Speaker ASR, IEEE/ACM Transactions on Audio, Speech and Language Processing, Pages:175-186, vol. 33, doi={10.1109/TASLP.2024.3510526}, 2025.




