AI
LANTERN: Language Model Assessmenton Noisy and Transformed Tasks for Understanding Error and Robustness Nuances
|
The IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) is an annual flagship conference organized by IEEE Signal Processing Society. ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. It features a broad technical program showcasing the latest developments in research and technology, attracting thousands of professionals from both academia and industry. In this blog series, we highlight our research papers presented at ICASSP 2026. Below is a list of our contributions. #1. Whisper-Fest: Single-Channel Far-Field Enhanced Speech-to-Text Without Parallel Data #2. Triage Knowledge Distillation for Speaker Verification #3. LANTERN: Language Model Assessmenton Noisy and Transformed Tasks for Understanding Error and Robustness Nuances #4. DeMo-Pose: Depth-Monocular Modality Fusion for Object Pose Estimation #5. GalaxyEdit: Large Scale Image Editing Dataset with Enhanced Diffusion Adapter #6. ADORE: Asymmetric Relational Distillation with Reranking for Instance Level Image Retrieval #7. T-GEMS: Text-Guided Exit Modules for Decreasing CLIP Image Encoder #8. SmoGVLM: A Small, Graph-Enhanced Vision-Language Model #9. On the Importance of a Multi-Scale Calibration for Quantization #10. Differentially Private Clustered Federated Learning with Privacy-Preserving Initialization and Normality-Driven Aggregation #11. Self-Attention Decomposition for Training Free Diffusion Editing |
Introduction
Large Language Models (LLMs) such as GPT‑3, LLaMA, and ChatGPT have made significant strides in natural language generation, reasoning, and instruction following. These advancements have been fuelled by scaling laws, massive pretraining, and alignment techniques such as supervised fine‑tuning and preference optimization.
Despite their growing ubiquity, evaluating LLMs remains a complex challenge. Traditional evaluation methods are often designed for earlier NLP tasks and fail to capture the reasoning depth, factuality, and instruction adherence expected from modern models. Recent benchmarks attempt to address this gap: MMLU and MMLU‑Pro assess domain‑level reasoning via MCQs; GPQA targets expert‑level science questions; MUSR introduces reasoning through complex narratives; and IfEval evaluates instruction adherence. While these offer progress, static test sets and rigid formats still leave key evaluation aspects unexamined.
Recent works have highlighted vulnerabilities in LLM behaviour due to input sensitivity and structural biases. Modifying prompt phrasing or order can significantly affect outputs. Additionally, LLMs show biases toward certain output tokens or positions in MCQs. Adversarial evaluations demonstrate that small input changes like character‑level noise or value alterations, can degrade model performance. Most prior efforts focus narrowly on prompts or MCQ structure, overlooking the interplay between questions, choices, and instructions in more generalized settings. In our work we identify three significant underexplored factors:
We propose LANTERN, a comprehensive framework for evaluating LLM robustness through controlled perturbations across input dimensions:
Our findings reveal persistent weaknesses in model generalization under surface‑level changes and highlight the importance of more fine‑grained, flexible evaluation protocols.
Methodology
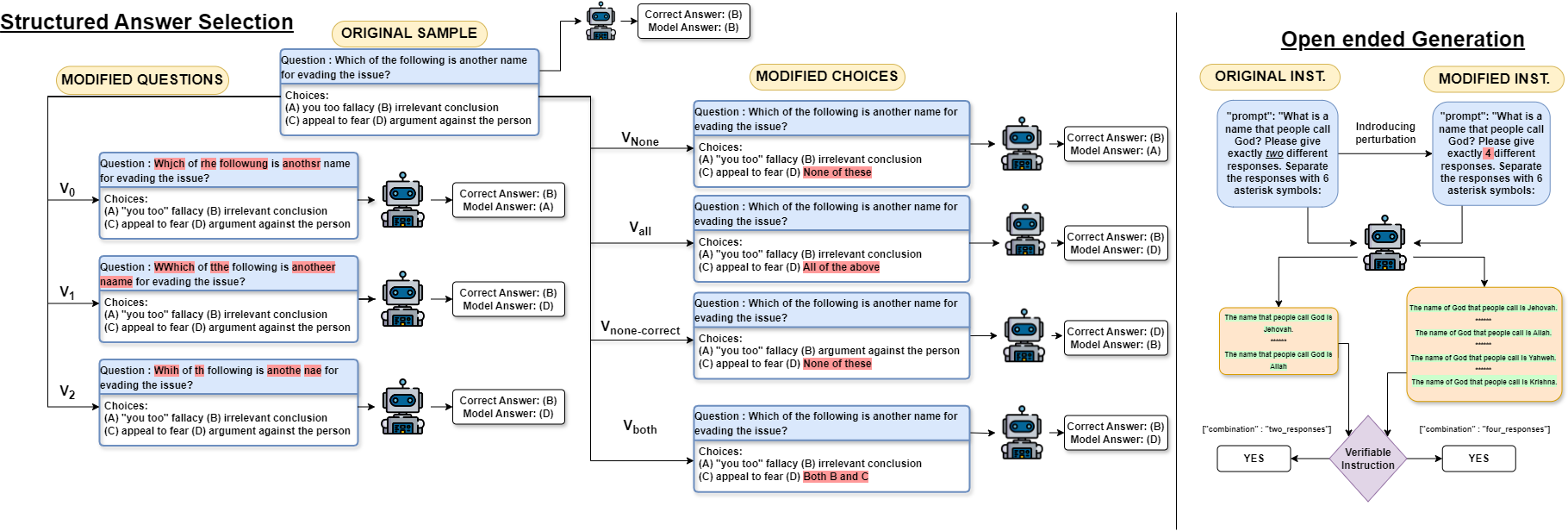
Figure 1. Examples showcasing the original and perturbated sample for closed and open-ended generations.
We investigate the robustness of LLMs based on two paradigms: structured answer selection and open‑ended generation as shown in Figure 1.
Let D = {(q, C, y, S)} represent a dataset where each instance consists of a question q, a set of candidate answer choices C = {c₁, c₂, ..., cₙ}, a ground truth y ∈ C, and optionally a supporting context S that provides additional information to aid in selecting the correct answer. The objective of a model is to learn the function f: (q, C, S) → C such that f(q, C, S) maximizes the likelihood of predicting y. In this work, we investigate the robustness of such models by introducing controlled perturbations in the dataset. Specifically, we define a perturbation function P that operates on either the questions or the answer choices, resulting in a transformed dataset. When perturbations are applied to the questions, the modified dataset is represented as D' = {(P(q), C, y, S)}, whereas perturbations to the answer choices yield D'' = {(q, P(C), y, S)}. The function P introduces adversarial modifications, each designed to assess the specific vulnerabilities in model predictions.
Perturbation in Choices: We investigate the impact of perturbations introduced to the answer choices on the model's performance. For a given dataset D, we apply perturbations to the set of answer choices. Specifically, let P(C) represent a perturbation function that modifies the original set of answer choices C into a perturbed version C'. We define the modified dataset D'' as: D'' = {(q, P(C), y, S)}. The perturbations consist of replacing one of the answer choices with predefined phrases such as None of These, All of the Above, or Both A and B, as well as permutations of the answer choices. For a given sample with a question q and a set of answer choices C = {c₁, c₂, c₃, c₄}, where A, B, C, D represent the indices of these choices, and c₂ is the correct answer, the perturbation is applied to the choices in C. The modified answer set C' is constructed by selecting one of the answer choices and replacing it with one of the predefined phrases or by permuting the existing choices. We generate four distinct synthetic datasets based on specific perturbations applied to the answer choices, ensuring that each dataset contains exactly one correct answer choice.
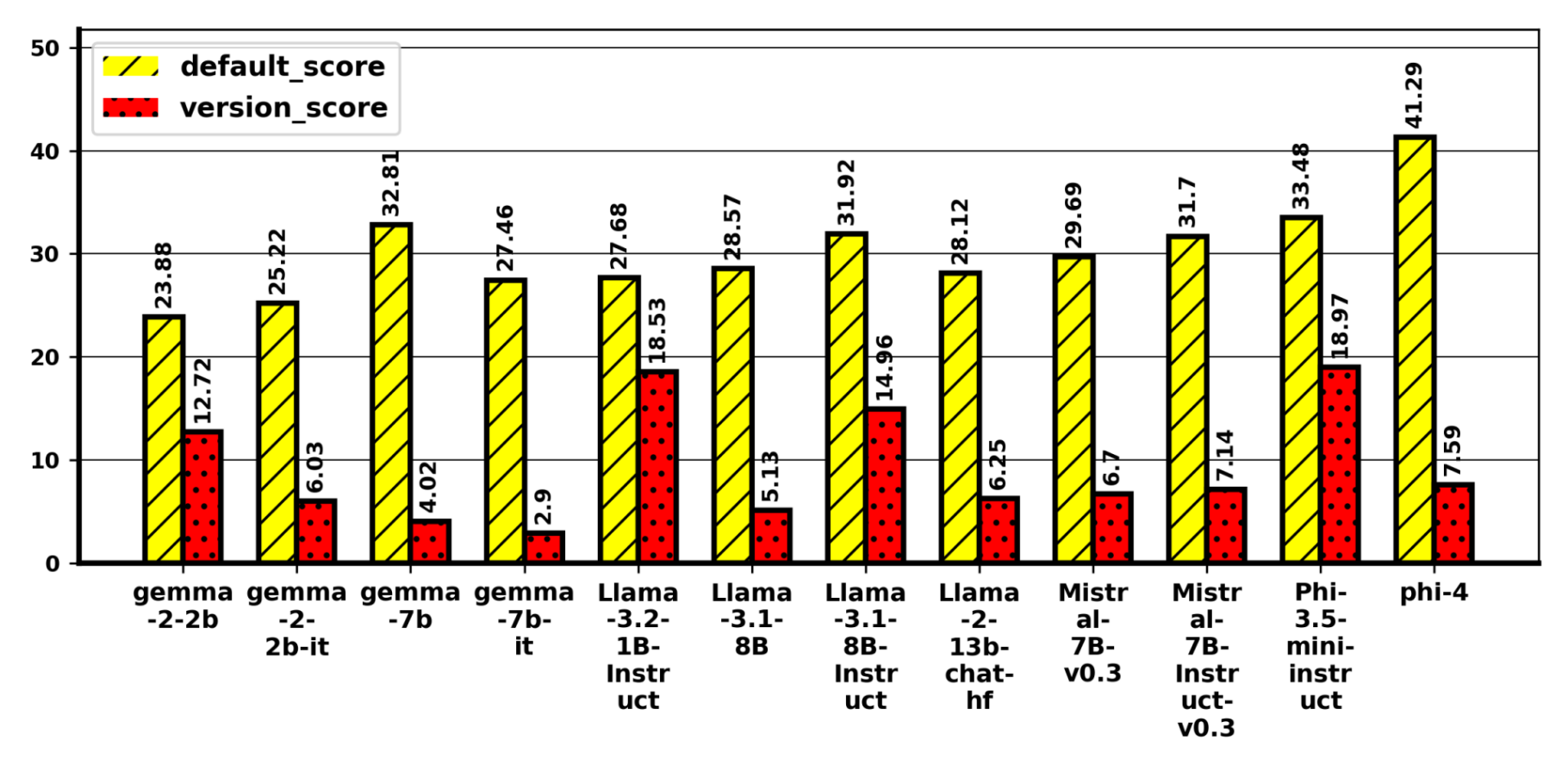
Figure 2. v_none−correct results for GPQA benchmark. Similar trend of significant accuracy drops is observed across benchmarks, models when a correct option is replaced with “None of these”, except for MUSR where accuracies improved.
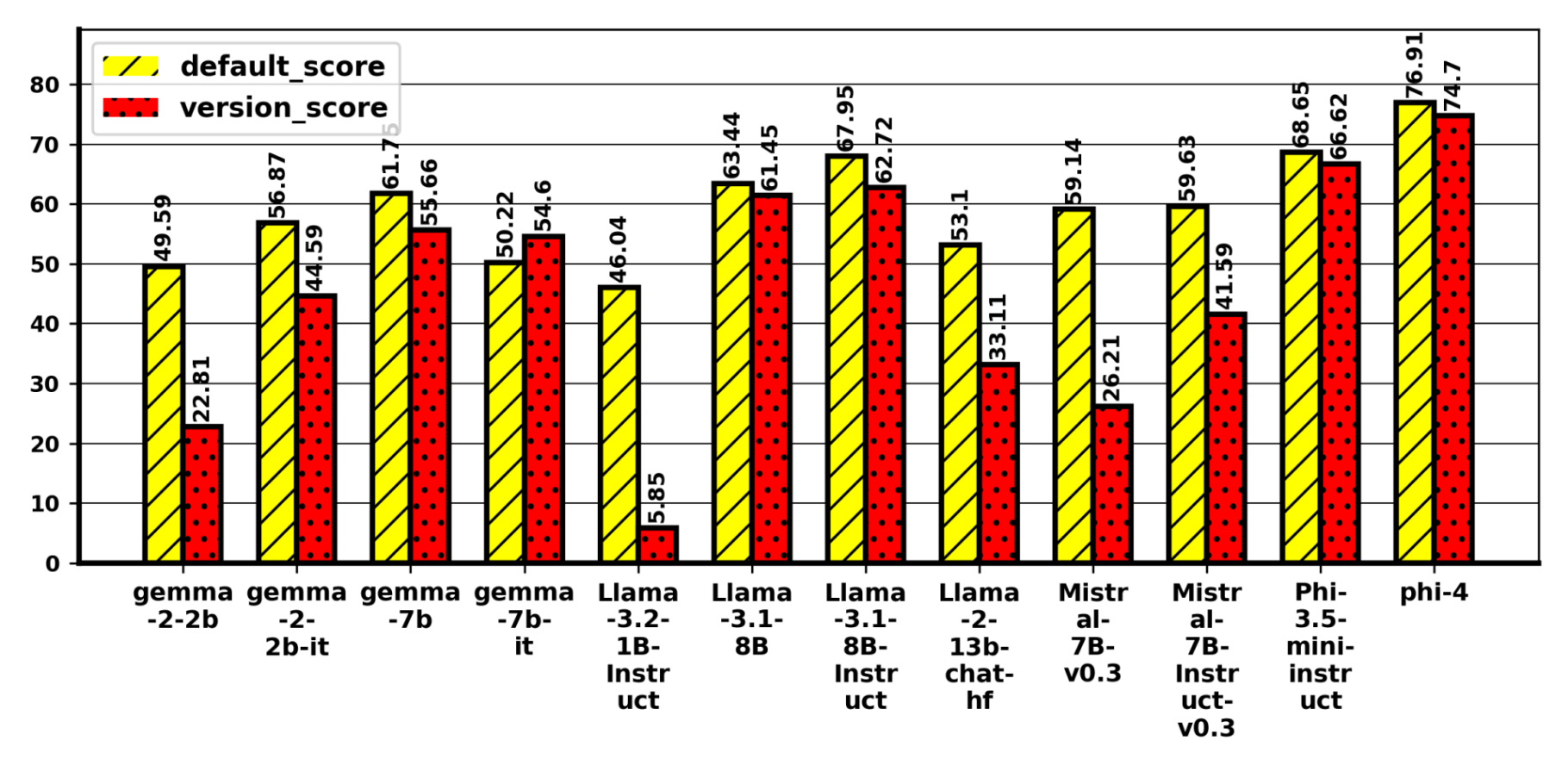
Figure 3. v_all results for MMLU benchmark. Similar drops are observed across benchmarks and models, when an incorrect option is replaced with “All of the Above”, ignoring a few exceptions like gemma-7b-it in the above image.
Perturbation in Questions: We investigate the performance of LLMs under perturbations applied at both the character and word levels to the questions in data samples. The approach is inspired by related works that explore similar techniques at the prompt level, such as in [1] and [2]. Let P: q → q' be a perturbation function that modifies the original question q into a perturbed version q'. The modified dataset D' is then defined as D' = {(P(q), C, y, S)}. Here, each perturbed question q' = P(q) is derived by applying one of several perturbation strategies. We construct three distinct variants of the dataset by introducing specific types of perturbation function P to the questions. The perturbations are designed to modify the structure, integrity, and readability of the questions in controlled ways, simulating potential real-world distortions in input data.
Each of these perturbations is designed to evaluate the model's ability to handle subtle and often noisy distortions in input data, reflecting real-world scenarios where input text may be corrupted or imperfect. For each of the aforementioned perturbation variants, we introduce modifications at three distinct levels. Specifically, we apply perturbations to 10%, 30%, and 50% of randomly selected words in each question, which allows us to assess the sensitivity of the model to varying intensities of input noise. For the original dataset D, we generate a total of nine synthetic datasets by applying all combinations of the three perturbation types v₀, v₁, and v₂ at three perturbation levels. At 50%, the questions often become unreadable, but we include it to characterize how the performance degrades, which interestingly is not always linear across benchmarks, specifically in GPQA, the degradation is irregular as shown in Figure 5.
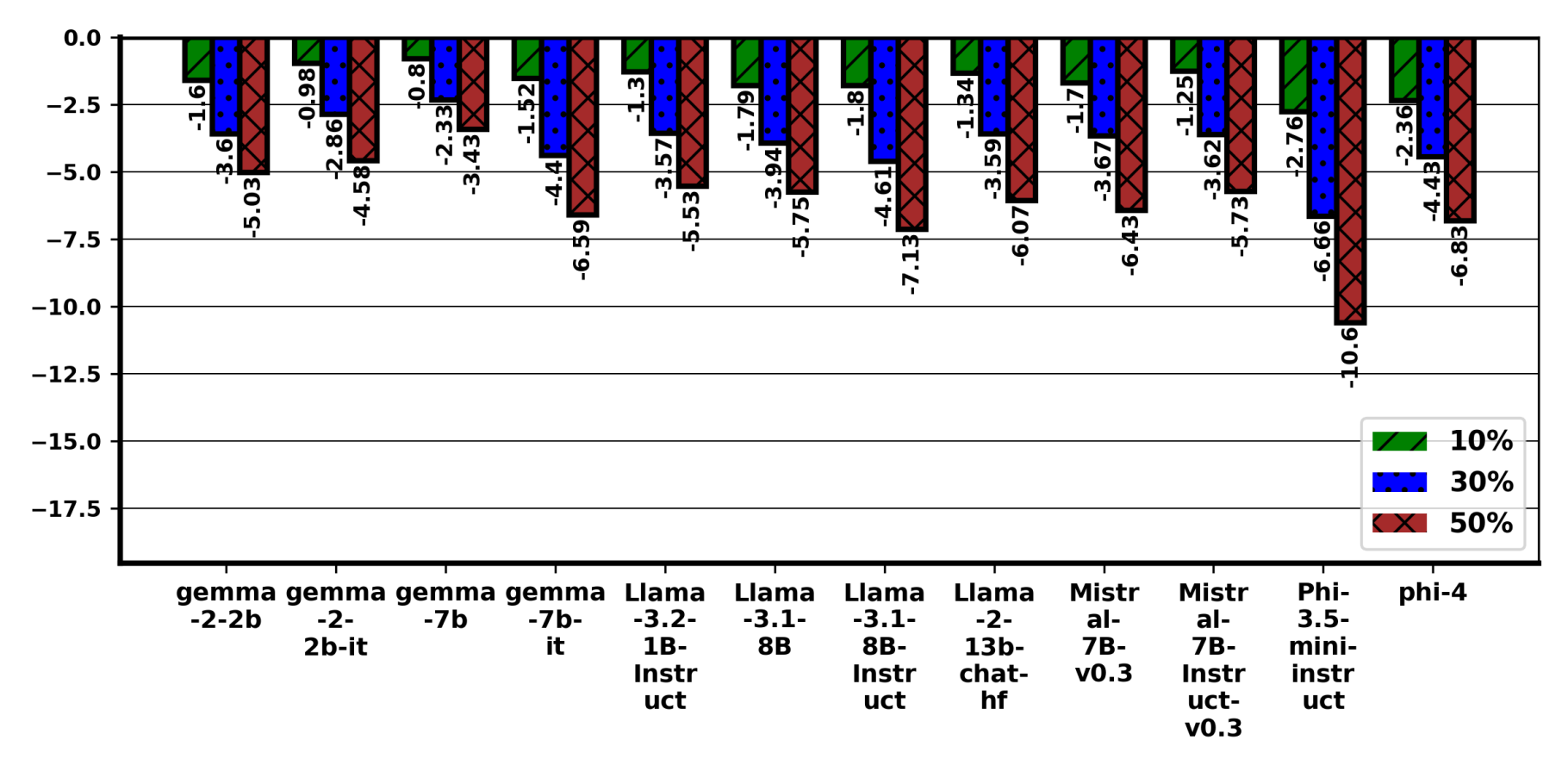
Figure 4. v₀ (Typographical errors) results on MMLU. Linear trend of accuracy drop is observed with increased level of perturbation from 10% to 50% in MMLU.
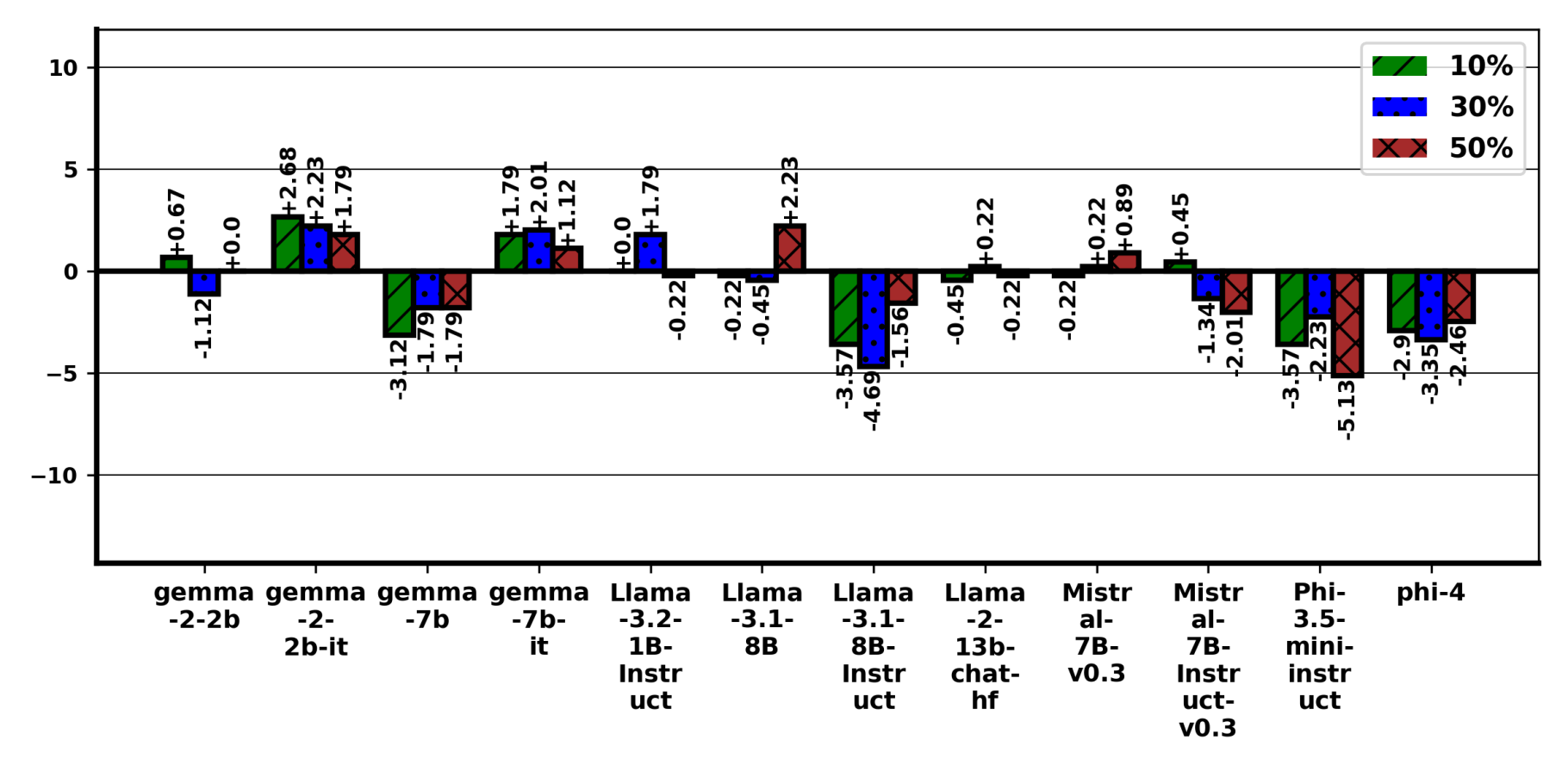
Figure 5. v₀ (Typographical errors) results on GPQA. Irregular trend observed with GPQA benchmark across models. Surprisingly, LLAMA-3.1-8B performed better at 50% perturbation compared with its base performance.
Open‑ended generation
Unlike structured tasks with predefined answer choices, open-ended generation allows a diverse range of outputs, making evaluation more challenging. To systematically analyse the behaviour of the model M under such conditions, we define the dataset as a structured collection of samples, each incorporating various elements that influence the generation process.
In open-ended generation, each structured sample in the dataset comprises a prompt, a set of instruction identifiers, and corresponding verifiable functions. Let the dataset be represented as D = {(pr, I, Vr)}. Here, pr is the input to the model M, potentially containing one or more instructions. I = {i₁, i₂, ..., iₙ} is a set of instruction identifiers, where each iⱼ corresponds to a specific guideline that the model must follow. Vr = {Vr₁, Vr₂, ..., Vrₙ} is a set of verifiable functions, where each Vrⱼ is associated with the instruction iⱼ and verifies whether the model's generated output complies with the corresponding instruction. Given a prompt pr to the model M, the model generates a text output out. Each verifiable function Vrⱼ ∈ Vr then evaluates out to verify adherence to the associated instruction iⱼ.
To study the robustness of the model under varied conditions, we introduce a perturbation function P that modifies both the prompt and the instruction identifiers. Let P: pr → pr' and I → I' be a perturbation function that transforms the original prompt pr into a perturbed version pr' and the original set of instruction identifiers I into I'. The perturbed dataset D' is then defined as D' = {(P(pr), P(I), P(Vr))}. Here, each perturbed prompt pr' = P(pr) is derived by applying specific perturbations based on defined constraints such as "Number of words," "Number of Sentences," "No Comma," etc. Corresponding instruction identifiers and verifiable functions are adjusted to I' = P(I) and Vr' = P(Vr), respectively, ensuring consistency with the perturbed prompts.
The presence of explicit instruction identifiers allows for systematic control over task definitions. The interplay between pr, I, and Vr enables a rigorous assessment of the model's capability to follow instructions and balance creativity with accuracy in an open-ended setting.
Experiments
We evaluate structured answer selection on widely adopted benchmarks: MMLU [3], MMLU-Pro [4], GPQA [5], and MUSR [6], while using IfEval [7] for open-ended generation. We select a diverse set of open-source LLMs, ranging in size from 2B to 13B parameters, including both base and instruction-tuned versions. The chosen models include gemma-2-2b, gemma-2-2b-it, gemma-7b, gemma-7b-it, Llama-3.2-1B-Instruct, Llama-3.1-8B, Llama-3.1-8B-Instruct, Llama-2-13b-chat-hf, Mistral-7B-v0.3, Mistral-7B-Instruct-v0.3, phi-4, and Phi-3.5-mini-instruct. For the IfEval dataset, we implement a set of custom verification functions to handle various perturbations. We conduct experiments on 4 NVIDIA A100 GPUs (40GB). We adopt a zero-shot evaluation setup for GPQA, MMLU, MUSR, and IfEval, while MMLU-Pro is evaluated using a few-shot setup with n = 5, where n denotes the number of few-shot examples.
Results
Structured answer selection
Impact of Perturbation in Questions: On MMLU, accuracy declines monotonically with perturbation rate for typos v₀, letter duplication v₁, and v₂. Phi-3.5-mini-Instruct is most sensitive with a drop of 10.6% on v₀ (see Figure 4); 8.85% on v₂; LLaMA-3.1-8B-Instruct also degrades, indicating size alone does not ensure robustness. MMLU-Pro, Gemma-2-2B and Gemma-2-2B-it are consistently robust and sometimes exceed baseline. With a few models, GPQA surprisingly shows improvement in accuracy upon introducing perturbations. In fact, Llama-3.1-8B improved accuracy for 50% perturbation but showing drop in 10% and 30% as seen in Figure 5. In MUSR, Phi-4 shows the largest drops 9.79%, 6.88%, 7.28% across v₀–v₂, while smaller instruction-tuned models (e.g., LLaMA-3.2-1B-Instruct, Mistral-7B-it) occasionally improve. Within families, larger models can be more robust for v₁, but overall robustness is model and dataset dependent, with pretraining data quality and instruction tuning mattering more than scale.
Impact of Perturbation in Choices: Replacing an incorrect option with "None of these" (v_none) slightly improves accuracy on MMLU, MMLU-Pro, and GPQA but degrades for MUSR. Replacing an incorrect option with "All of the above" (v_all) reduces accuracy on MMLU (Figure 3) and MUSR; MMLU-Pro is largely unchanged; GPQA is mixed, with Gemma-2-2B dropping by ~12%. Replacing the correct option with "None of these" (v_none-correct) yields the largest declines across benchmarks (Figure 2), except MUSR, which improves. Introducing "Both A and B" (v_both) generally lowers accuracy on MMLU and MUSR, has minor effects on MMLU-Pro, and is mixed on GPQA (Phi models and Gemma-7B-it slightly improve; Gemma-2-2B drops 9.71%). Models also show a bias toward "None/All" when only 2–3 options are present, contributing to atypical MUSR behaviour. Overall, edits that alter the logical structure of choices or remove the correct answer yield inconsistency.
Open‑ended generation
On IfEval, perturbations reduce accuracy by 2.85% on average. Size alone does not guarantee robustness (e.g., Phi-4 underperforms despite 14B parameters). Base LLaMA-family models show the largest variability (~4% drop on average), highlighting sensitivity to distribution shift. We find that while perturbations introduce performance degradation across models, instruct-tuned models are more resilient, whereas base models, particularly those in the LLaMA family, exhibit significant variability under perturbations.
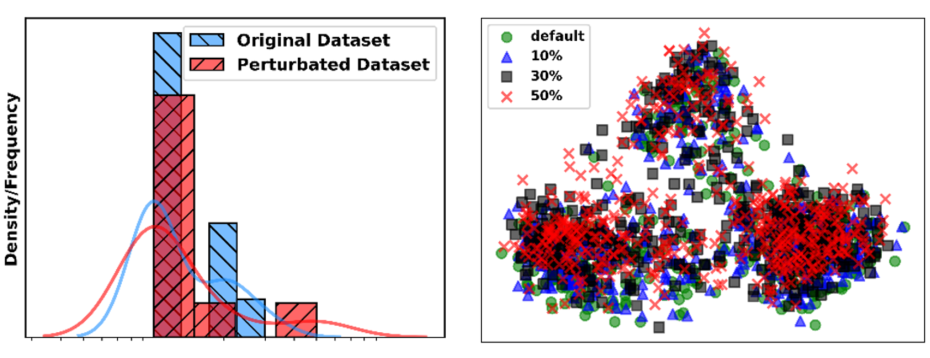
Figure 6. Log-scaled frequency differences and PCA-projected embedding distributions show minimal divergence, indicating no significant shift and confirming that the controlled edits preserve semantics as compared to original dataset.
Distributional and Semantic Consistency
We test whether perturbations alter dataset statistics using a two-sample Kolmogorov-Smirnov (K-S) test on MMLU-Pro: after removing special characters and stop words and lemmatizing, we compare word-frequency distributions of original vs. perturbed questions. The test yields p = 0.9750 ≥ 0.05, indicating no significant shift; log-scaled frequency differences and PCA-projected embeddings show minimal divergence (Figure 6), confirming controlled edits that preserve semantics. Stability is further supported by three seeded runs with MMLU standard deviation of 0.47, 0.48, and 1.01.
Conclusion
Through systematic perturbations—including typographical errors, choice modifications, and instruction variability—we observe that LLMs exhibit varying degrees of robustness depending on the nature of the perturbation. Some perturbations, such as minor typographical errors, lead to moderate accuracy drops, while others, such as replacing correct choices with “None of These,” cause significant performance degradation. Larger models do not consistently demonstrate higher robustness, suggesting that scale alone does not confer stability under perturbed conditions. The findings underscore the need for improved training strategies and evaluation methodologies that account for real‑world input variability. Future work will explore adaptive fine‑tuning and adversarial training techniques to enhance LLM resilience against structured perturbations.
References
[1] Zhu, Kaijie, et al. "Promptrobust: Towards evaluating the robustness of large language models on adversarial prompts." Proceedings of the 1st ACM workshop on large AI systems and models with privacy and safety analysis. 2023.
[2] Gan, Esther, et al. "Reasoning robustness of llms to adversarial typographical errors." Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024.
[3] Hendrycks, Dan, et al. "Measuring massive multitask language understanding." arXiv preprint arXiv:2009.03300 (2020).
[4] Wang, Yubo, et al. "Mmlu-pro: A more robust and challenging multi-task language understanding benchmark." Advances in Neural Information Processing Systems 37 (2024): 95266-95290.
[5] Rein, David, et al. "Gpqa: A graduate-level google-proof q&a benchmark." First conference on language modeling. 2024.
[6] Sprague, Zayne, et al. "Musr: Testing the limits of chain-of-thought with multistep soft reasoning." arXiv preprint arXiv:2310.16049 (2023).
[7] Zhou, Jeffrey, et al. "Instruction-following evaluation for large language models." arXiv preprint arXiv:2311.07911 (2023).




