AI
[INTERSPEECH 2025 Series #5] SPCODEC: Split and Prediction for Neural Speech Codec
|
Interspeech is one of the premier international conferences dedicated to advancing and disseminating research in the field of speech science and technology. It serves as a global platform where researchers, engineers, and industry professionals can share cutting-edge innovations, methodologies, and applications related to speech communication. In this blog series, we are introducing some of our research papers at INTERSPEECH 2025 and here is a list of them. #5. SPCODEC: Split and Prediction for Neural Speech Codec (Samsung R&D Institute China-Beijing) #6. Efficient Streaming TTS Acoustic Model with Depthwise RVQ Decoding Strategies in a Mamba Framework (AI Center-Seoul) #7. Robust Unsupervised Adaptation of a Speech Recogniser Using Entropy Minimisation and Speaker Codes (AI Center-Cambridge) #8. A Lightweight Hybrid Dual Channel Speech Enhancement System under Low-SNR Conditions (Samsung R&D Institute China-Nanjing) #9. Fairness in Dysarthric Speech Synthesis: Understanding Intrinsic Bias in Dysarthric Speech Cloning using F5-TTS (Samsung R&D Institute India-Bangalore) |
Introduction
Speech coding is essential for voice communication and streaming media, ensuring efficient compression while maintaining perceptual quality. A typical speech codec consists of an encoder, a quantizer, and a decoder. The encoder analyzes the input speech and extracts latent representations, the quantizer compresses the latent features, and the decoder reconstructs the output speech signal.
In recent years, neural network-based codecs have become a popular research topic in the fields of speech, audio, image, and video compression. However, existing neural speech codecs still face several challenges and limitations:
To address these issues, we propose SPCODEC, a time-domain, end-to-end neural speech codec. SPCODEC builds upon a model comprising a fully convolutional encoder-decoder and a group-residual vector quantization module enhanced with a split-and-prediction module. Our contributions are summarized as follows:
Proposed Method
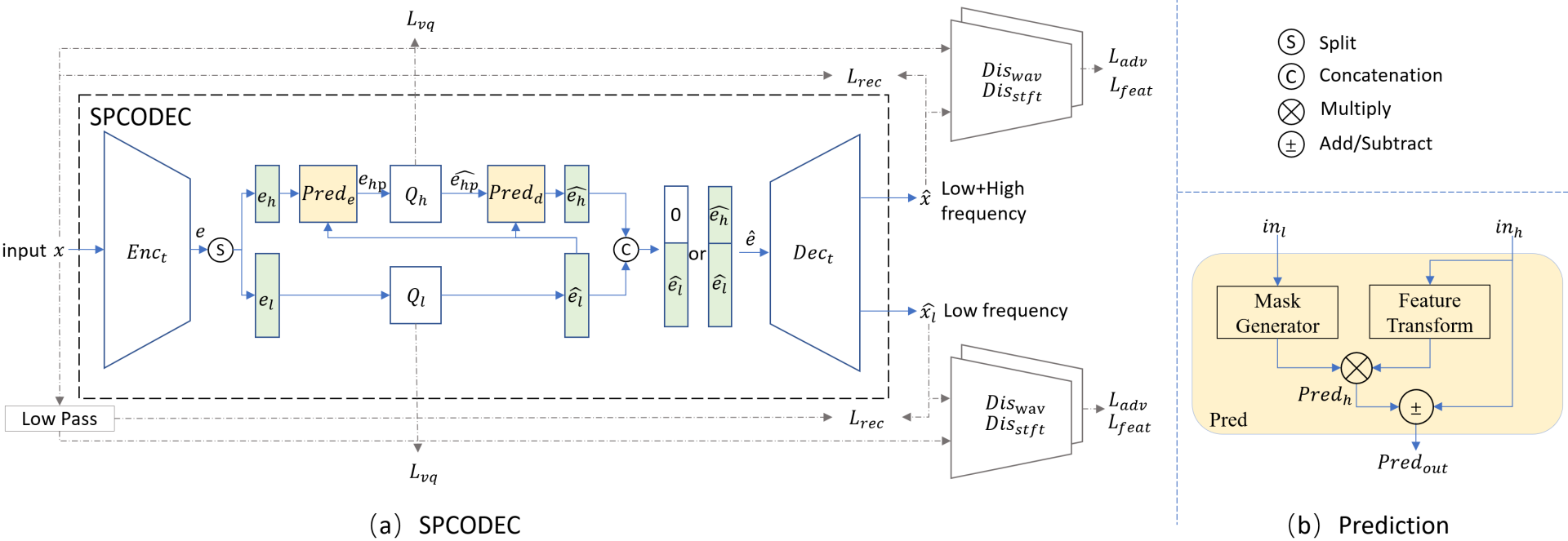
Figure 1. (a) SPCODEC: a time domain encoder-quantizer-decoder codec architecture which is trained end-to-end with reconstruction loss, VQ loss, adversarial loss and feature matching loss for both reconstructed low frequency waveform and ‘low+high’ frequency waveform. Latent embedding is split into disentangled two parts, which are supervised to contain high and low frequency information, respectively. (b) Prediction module: high frequency feature ($Pred_h$) is predicted from input low and high frequency information ($in_l$/$in_h$) for encoder’s feature redundancy removal (‘-’) and decoder’s feature fusion (‘+’)
We consider a single-channel time-domain input signal $x$. An end-to-end (E2E) neural codec consists of three sequential components: an encoder ($Enc_t$), a quantizer ($Q$) and a decoder ($Dec_t$). The encoder transforms x to a sequence of latent embeddings. The quantizer assigns each embedding to a finite set of codebook entries, thereby compressing it using a codebook index. The decoder reconstructs the time-domain signal using the quantized latent embeddings.
$e=Enc_t(x)$
$e ̂=Q(e)$
$x ̂=Dec_t (e ̂ )=Dec_t (Q(Enc_t (x)))$
Since lower frequencies play a dominant role in subjective quality, while higher frequencies can often be predicted from them, we propose:
The latent embedding is divided into two groups, $split(e)=[e_l,e_h]$, whose dimensions are adjustable to optimize spectral representation. $e_l$ contains features for reconstructing low-frequency portion of the signal and $e_h$ contains features for reconstructing high-frequency portion of the signal. The high-frequency embedding can be predicted from the quantized low-frequency embedding. The latent embedding that requires quantization is predicted from the unquantized high-frequency embedding and the quantized low-frequency embedding.
$e_{hp}=Pred_e (\widehat{e_l},e_h)$
We employ two separate quantizers for the low- and high-frequency components.
$\widehat{e_l}=Q_l (e_l ),\widehat{e_{hp}}=Q_h (e_{hp} )$
The high frequency embedding synthesized after quantization for decoder is:
$\widehat{e_h}=Pred_d (\widehat{e_l},\widehat{e_{hp}})$
$\widehat{e_l},\widehat{e_h}$ can either be concatenated to reconstruct the complete signal or used separately to reconstruct the respective low- or high- frequency portion of the signal by decoder $Dec_t$.
$\hat{x}=Dec_t ([\widehat{e_l},\widehat{e_h}])$
$\widehat{x_l}=Dec_t ([\widehat{e_l},0])$
We facilitate feature disentanglement through supervising the reconstructed waveform generated from the split latents, explicitly establishing a correspondence between latent features and the spectral range of the reconstructed waveform. To ensure that the resolution and content of low-frequency features contribute a larger share to $e$, the dimension of $e_l$ is made greater than $e_h$.
An attention-based module is employed for feature prediction from low frequency feature to high frequency feature. Low frequency feature input $in_l$ is used to generate a mask which will be used to predict high frequency feature $Pred_h$. The predicted high-frequency feature serves to eliminate feature redundancy in the encoder or facilitate feature merging in the decoder. By doing so, the high-frequency feature predictable from the low-frequency feature won’t be included in the bitstream. The feature transform (FT) linearly transforms the input high frequency feature using a convolution layer. The mask generator (MG) calculates the attention mask using a convolution layer and nonlinear activation function.
$Pred_h=FT(in_h)$∙$MG(in_l)$
$Pred_{out}=in_h±Pred_h$
The SPCODEC model is trained end-to-end alongside discriminators, combining adversarial and reconstruction losses to attain both signal reconstruction accuracy and perceptual quality between the reconstructed waveform and its reference. The overall loss of SPCODEC applies to both $x ̂$ and $\widehat{x_l}$. Explicit supervision of $\widehat{x_l}$ ensures that the embedding $e_l$ contains only low-frequency-related features.
Experiments
To assess the proposed SPCODEC, we conduct experiments and analysis from the following perspectives: (1) Evaluation of overall codec quality by comparing SPCODEC against existing classic and neural codecs based on subjective and objective MOS score assessment. (2) Ablation study on split-and-prediction module for it’s capability to enhance codec quality on both reconstructed low frequency result and overall ‘low+high’ frequency result.
For objective MOS score assessment, SPCODEC achieved MOS-POLQA scores of 4.0 and 4.5 at approximately 6 kbps and 10.66 kbps for wideband (WB) speech, and scores of 4.0 and 4.5 at 8 kbps and 16 kbps for super-wideband (SWB) speech. SPCODEC outperformed both existing neural speech codecs and traditional codecs for WB and SWB speech. In subjective MOS evaluations, SPCODEC achieved results aligned with the objective outcomes from POLQA.
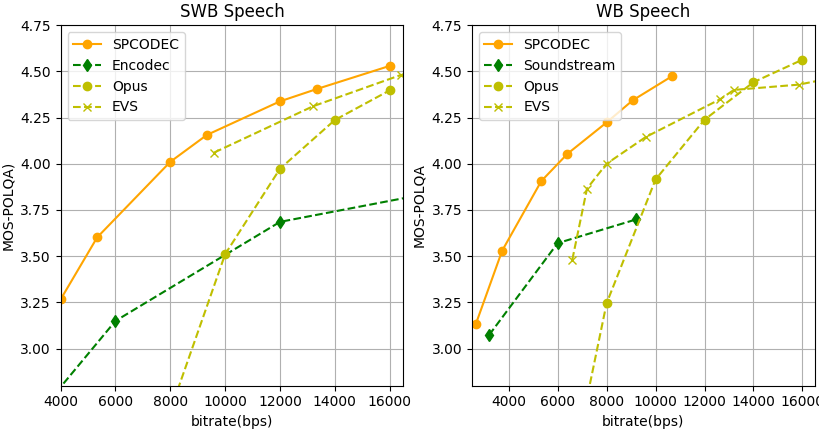
Figure 2. MOS-POLQA of SPCODEC
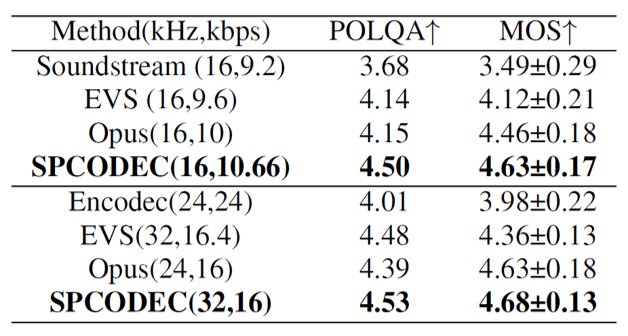
Table 1. Subjective MOS of SPCODEC
To evaluate the effectiveness of the proposed split-and-prediction module, we employ MelDistance, STOI (Short-Time Objective Intelligibility), and POLQA as metrics to assess performance improvements in the reconstructed low-frequency results and the full ‘low+high’ frequency results. We observed the following: (1) the split-and-prediction (SP) module consistently improves MelDistance, STOI, and MOS-POLQA scores. This suggests that SPCODEC produces less distortion, delivers a better sound quality experience, and enhances speech clarity and intelligibility. Furthermore, SPCODEC simultaneously improves the quality of both the reconstructed low-frequency signal and the combined ‘low+high’-frequency signal. (2) Particularly noteworthy is the significant improvement in POLQA scores observed for SPCodec at elevated bitrates, suggesting that this methodology facilitates the extension of the existing neural network encoder to attain enhanced performance under these conditions. In contrast, neither SRCodec nor HiFiCodec exhibits a consistent increase in POLQA scores as bitrate rises. Our analysis attributes SPCODEC’s superior performance to two key factors: first, the predictive module benefits from the enhanced quality of lower frequencies at higher bitrates; second, the split strategy allocates more bits to lower frequencies, further contributing to overall performance gains.
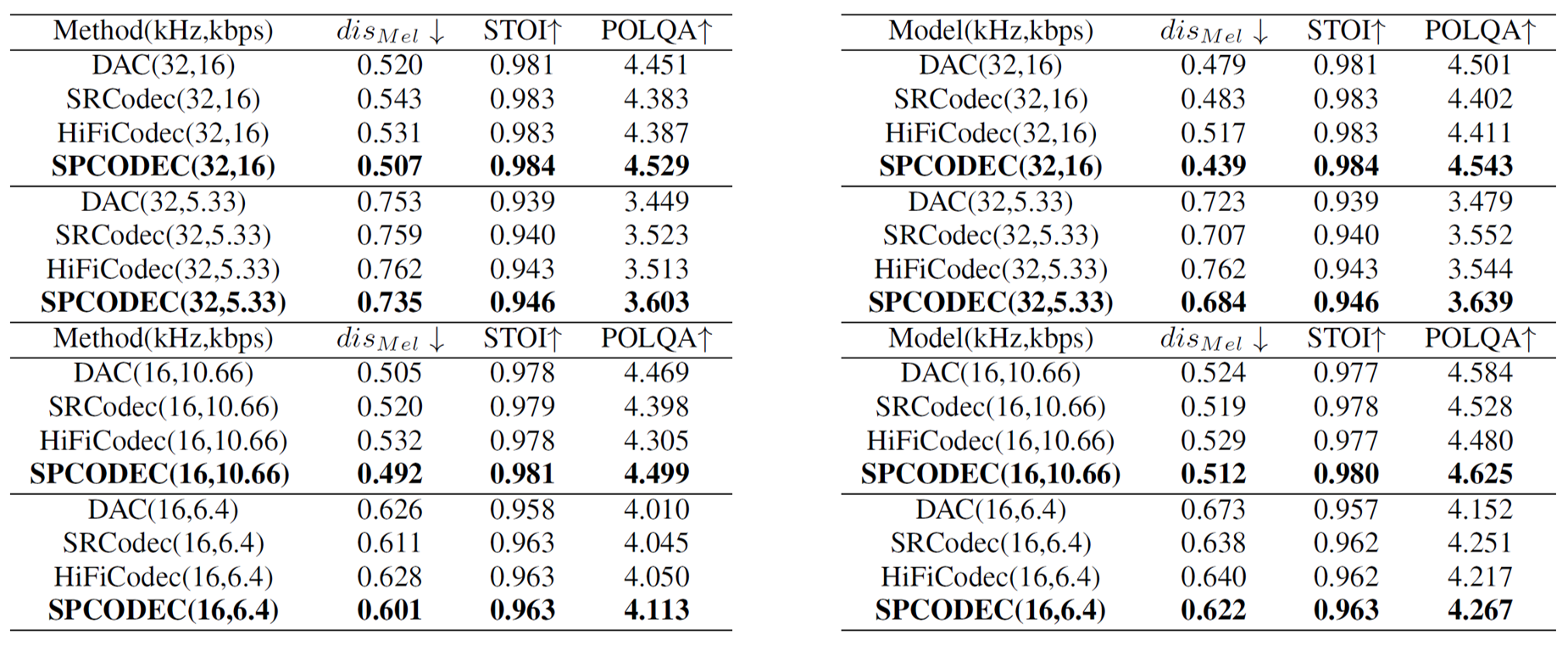
Table 2. Ablation study of SP module for reconstructed ‘low+high’ (Left) and ‘low’ (Right) frequency result
Conclusion
We proposed a split-and-prediction method for a causal time-domain, end-to-end speech codec (SPCODEC), which demonstrates superior performance compared to state-of-the- art models for both wideband and super-wideband speech coding. SPCODEC supports multi-band encoding within a single model, efficiently handling diverse frequency ranges. The proposed latent split-and-prediction scheme reduces redundancy in latent embeddings and optimizes overall coding performance. By explicitly disentangling low- and high-frequency features in split embeddings, SPCODEC also improves the interpretability of end-to-end neural speech coding. SPCODEC consistently achieves superior MOS-POLQA scores, reaching 4.0 at 6/8 kbps and 4.5 at 10.66/16 kbps for WB and SWB speech, respectively.
References
[1] N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 495–507, 2021.
[2] A. D´efossez, J. Copet, G. Synnaeve, and Y. Adi, “High fidelity neural audio compression,” arXiv preprint arXiv:2210.13438, 2022.
[3] R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved rvqgan,” Advances in Neural Information Processing Systems, vol. 36, 2024.
[4] D. Yang, S. Liu, R. Huang, J. Tian, C. Weng, and Y. Zou, “Hificodec: Group-residual vector quantization for high fidelity audiocodec,” arXiv preprint arXiv:2305.02765, 2023.
[5] Y. Zheng, W. Tu, L. Xiao, and X. Xu, “SRCODEC: Split-residual vector quantization for neural speech codec,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 451–455.



