AI
[INTERSPEECH 2025 Series #7] Robust Unsupervised Adaptation of a Speech Recogniser Using Entropy Minimisation and Speaker Codes
|
Interspeech is one of the premier international conferences dedicated to advancing and disseminating research in the field of speech science and technology. It serves as a global platform where researchers, engineers, and industry professionals can share cutting-edge innovations, methodologies, and applications related to speech communication. In this blog series, we are introducing some of our research papers at INTERSPEECH 2025 and here is a list of them. #5. SPCODEC: Split and Prediction for Neural Speech Codec (Samsung R&D Institute China-Beijing) #7. Robust Unsupervised Adaptati on of a Speech Recogniser Using Entropy Minimisation and Speaker Codes (AI Center-Cambridge) #8. A Lightweight Hybrid Dual Channel Speech Enhancement System under Low-SNR Conditions (Samsung R&D Institute China-Nanjing) #9. Fairness in Dysarthric Speech Synthesis: Understanding Intrinsic Bias in Dysarthric Speech Cloning using F5-TTS (Samsung R&D Institute India-Bangalore) |
Introduction
When an Australian says “below”, it can sound like an American saying “blur”. For an automatic speech recogniser, it is therefore useful to remember how a speaker sounds. Making a speech recogniser expect a specific speaker’s voice (or, for example, speaking style, or a specific background noise) is called “adaptation”. Figure 1 depicts how this works. The system keeps old utterances around and computes values for a set of adaptation parameters. When a new utterance comes in, the speech recogniser is primed for the correct speaker, and the hypothesis it comes up with is more likely to be correct.
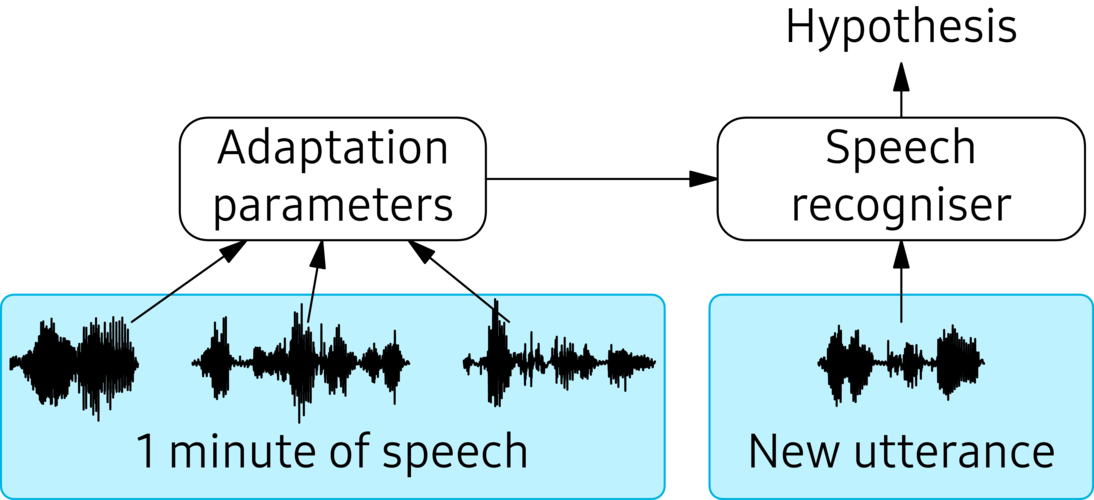
Figure 1. Adapting a speech recogniser. The adaptation parameters are tuned on previously-heard speech. A new utterance is then processed by the adapted speech recogniser to reach a higher-quality transcription hypothesis.
The problem is that adaptation requires data. On a device like a phone, it is possible to collect audio data, but usually only a minute or two. On top of that, getting labels, the text of what the person actually said, is usually impossible, so the recogniser’s own transcription, a “pseudolabel”, has to substitute. Both the scarcity of data and the absence of labelling makes adaptation hard.
And adaptation has become harder since speech recognisers have been based on neural networks, even though these work better overall. A neural-network model has no model of what speech sounds like, unlike the “hidden Markov models” of old. When the recogniser is adapted to its own transcription, errors in the transcription get reinforced. Neural networks also have many parameters, which makes it riskier to adapt them on little data: they can easily learn things that do not generalise. This work proposes two new methods to make a speech recogniser robust against these two dangers.
First, the lack of labels. The standard method for dealing with this problem is to run the speech recogniser unadapted to generate a single hypothesis which is used as “pseudolabel”. However, adaptation is not robust to errors in the pseudolabel. The next section will therefore propose to exploit the fact that a speech recogniser outputs a distribution over word sequences, by minimising the entropy of this distribution [1, 2, 3]. Minimum-entropy adaptation has an effect similar to pseudolabel adaptation in the case where the recogniser is certain, but it will hedge its bets where there are multiple plausible hypotheses. Minimum-entropy adaptation is therefore more robust.
The second problem, the small amount of adaptation data, brings the risk of overfitting the adaptation parameters. A popular adaptation method for neural networks, low-rank adaptation (LoRA) [4], may train only, say, 1% of model parameters, but they still number in the hundreds of thousands. This work will propose to use speaker codes [5,6] to make adaptation more robust. Speaker codes are small conditioning vectors, in this work of length 1024, learned with backpropagation. Speaker codes are different from other types of embedding vectors in that they are learned with a speech recognition objective.
Minimum-entropy adaptation
One problem that makes adaptation of a speech recogniser less robust is the reliance on a single hypothesis per utterance. Standard adaptation runs a speech recogniser on an utterance, treats the resulting hypothesis as a “pseudolabel”, and then adapts the parameters to make the pseudolabel more likely. Instead, this work proposes minimising the conditional entropy, which takes multiple hypotheses into account and therefore can exploit the uncertainty about the actual hypothesis.

Figure 2. The input vectors for illustrating the effect of minimising the entropy. The vectors are two-dimensional, and the two bars indicate the values of the two dimensions.
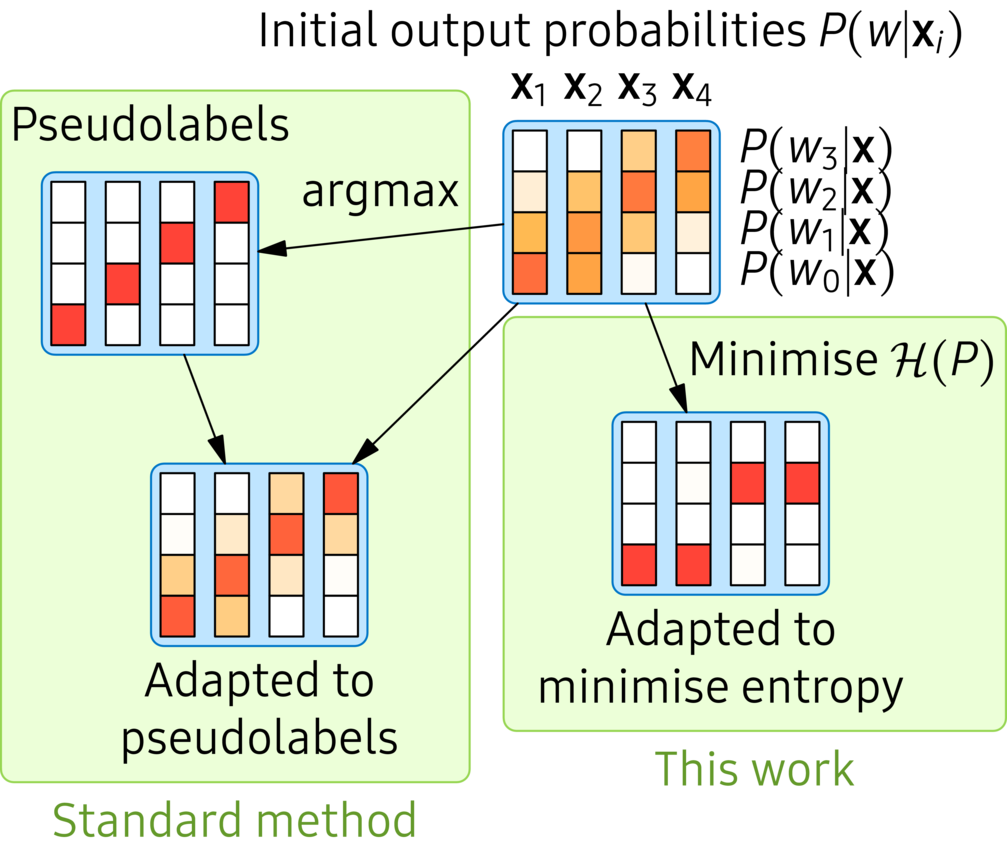
Figure 3. The effect of minimising the entropy, like in this work, compared to the standard method of using pseudolabels.
Figures 2 and 3 contain a toy example to show the effect of minimising the entropy. The data points are two-dimensional as shown in Figure 2. Note that the first two data points look a bit similar, as do the last two examples. Figure 3 shows initial classification probabilities from a small neural network. The plate on the left illustrates pseudolabel adaptation. First, for each data point, the current highest-probability class is determined, and then the network is fine-tuned (using the cross-entropy criterion) to output these classes. The plate on the right, on the other hand, uses the entropy criterion to fine-tune the model. The fine-tuning is guided both by making the output distributions more peaky, but also by the initial structure of the network. It ends up classifying the first two examples as the same class, and the final two, which is probably the correct result.
Minimising the entropy (but conditioned on the audio) of a speech recogniser is more complicated. A speech recogniser classifies an audio sequence into one of a potentially infinite number of classes: any sequence of words. This is possibly why no previous work has minimised the conditional entropy of a speech recogniser properly. In this work, only a few word sequences are considered explicitly during adaptation. This requires a bit of mathematical manipulation to work correctly: see the paper for more detail. As the experiments section will show, this method turns out very effective.
Adaptation using speaker codes
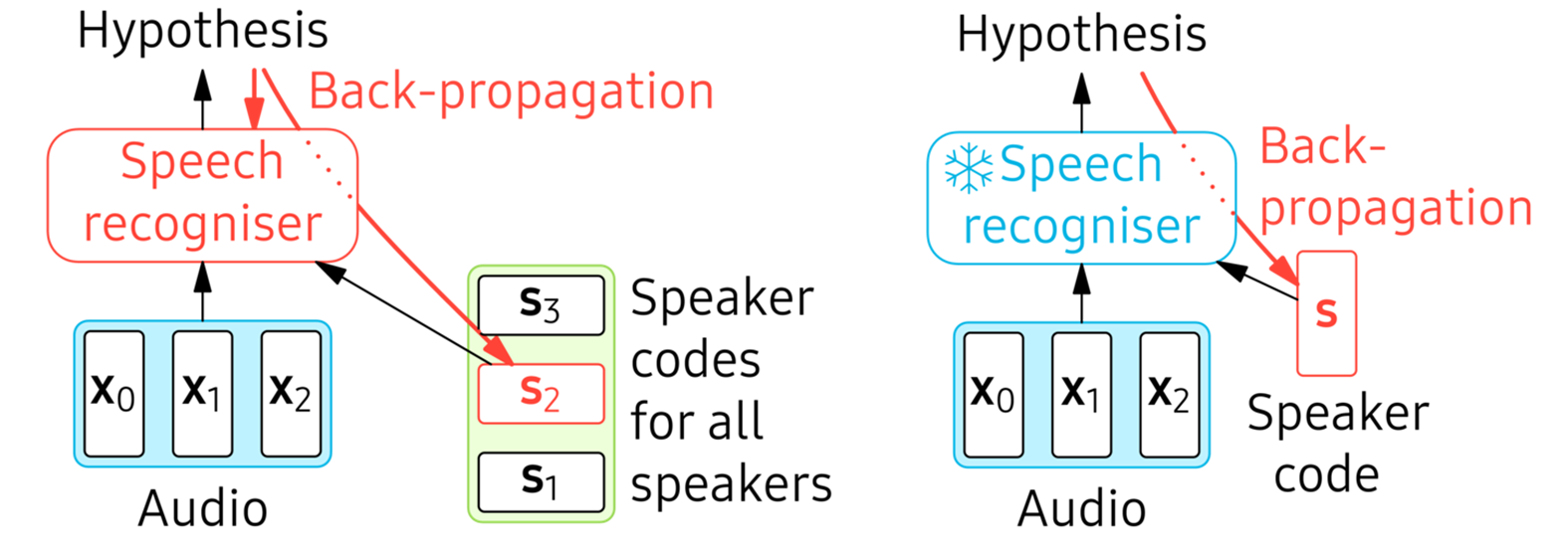
Figure 4. Using speaker codes, at a high level. Left: jointly training the speech recogniser and all speaker codes. Right: Adaptation to a speaker by fine-tuning the speaker code.
The second problem highlighted in the introduction is that the more parameters are estimated, the greater the risk of over-fitting. Therefore, this work adapts only 1024 parameters, contained in a vector called a “speaker code” [5,6]. To make this handful of parameters meaningful, their space is optimised during training. The left image in Figure 4 shows how training with speaker codes works. For each speaker in the training set, a separate speaker code vector is added to the trainable parameters. The appropriate speaker code (for each speaker in the batch) is trained with backpropagation, jointly with the speech recogniser. Thus, the speaker code space learns to capture inter-speaker variability, at the same time as the speech recogniser learns to exploit the speaker code to improve recognition.
In adaptation, the right image in Figure 4, only the speaker code is fine-tuned, using a pseudolabel or the more sophisticated conditional entropy objective from the previous section. Before adaptation, the recogniser must come up with a hypothesis in a speaker-independent mode. To support this, this work uses multi-task learning to train the speech recogniser in speaker-independent and speaker-dependent mode at the same time. For a fraction of utterances (half, in the experiments), the speaker code is set to 0 and not trained.
Experiments
To evaluate speaker adaptation, a large data set that keeps track of speaker identities is necessary. This work uses the Common Voice dataset [7], but augmented with noise and room simulation to make it similar to a realistic farfield scenario. The recognition system is based on a SpeechBrain recipe [8].
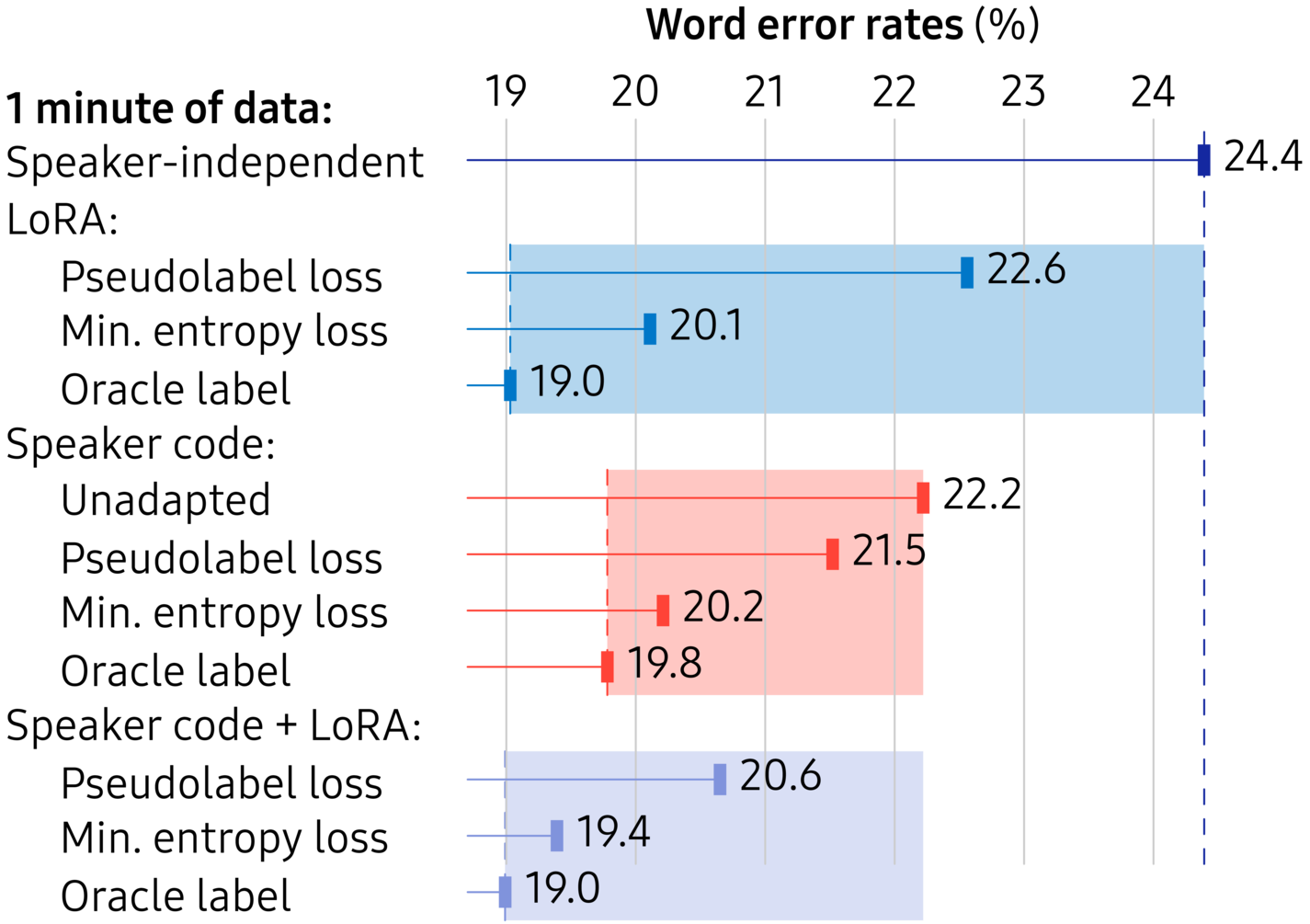
Figure 5. Average word error rates on CommonVoice-Farfield; adaptation on only one minute of data.
The headline results for adaptation on only one minute of data are shown in Figure 5. There are two aspects to the results: the adaptation parameters (LoRA, speaker code, or both) and the loss function (pseudolabel, minimum-entropy, or oracle label). The shaded areas show the windows of opportunity for each choice of adaptation parameters, between unadapted and oracle label, i.e. supervised, adaptation. Without adaptation, on CommonVoice-Farfield, a hard task, the word error rate is 24.4%. Intriguingly, training with speaker codes helps the system even if the speaker codes are set to zero (“Unadapted”), with performance at 22.2%. The hypothesis is that training with speaker codes has an effect like multi-task learning, but instead of having the speaker identity as an additional output, the speaker identity is given as a conditioning vector.
Two aspects stand out from Figure 5. First, irrespective of which parameters are adapted, the minimum-entropy loss outperforms pseudolabel adaptation. The minimum-entropy loss exploits uncertainty in the recogniser output and thus makes adaptation robust to initial recognition errors. When adapting both speaker codes and LoRA, the word error rate drops to 19.4%, a 20% relative improvement compared to the baseline. Second, with the pseudolabel loss it is noticeable that adapting the 1024-dimensional speaker code instead of LoRA is more robust. The space of speaker codes, learned while training, is clearly a much terser description of speaker variation than LoRA matrices.
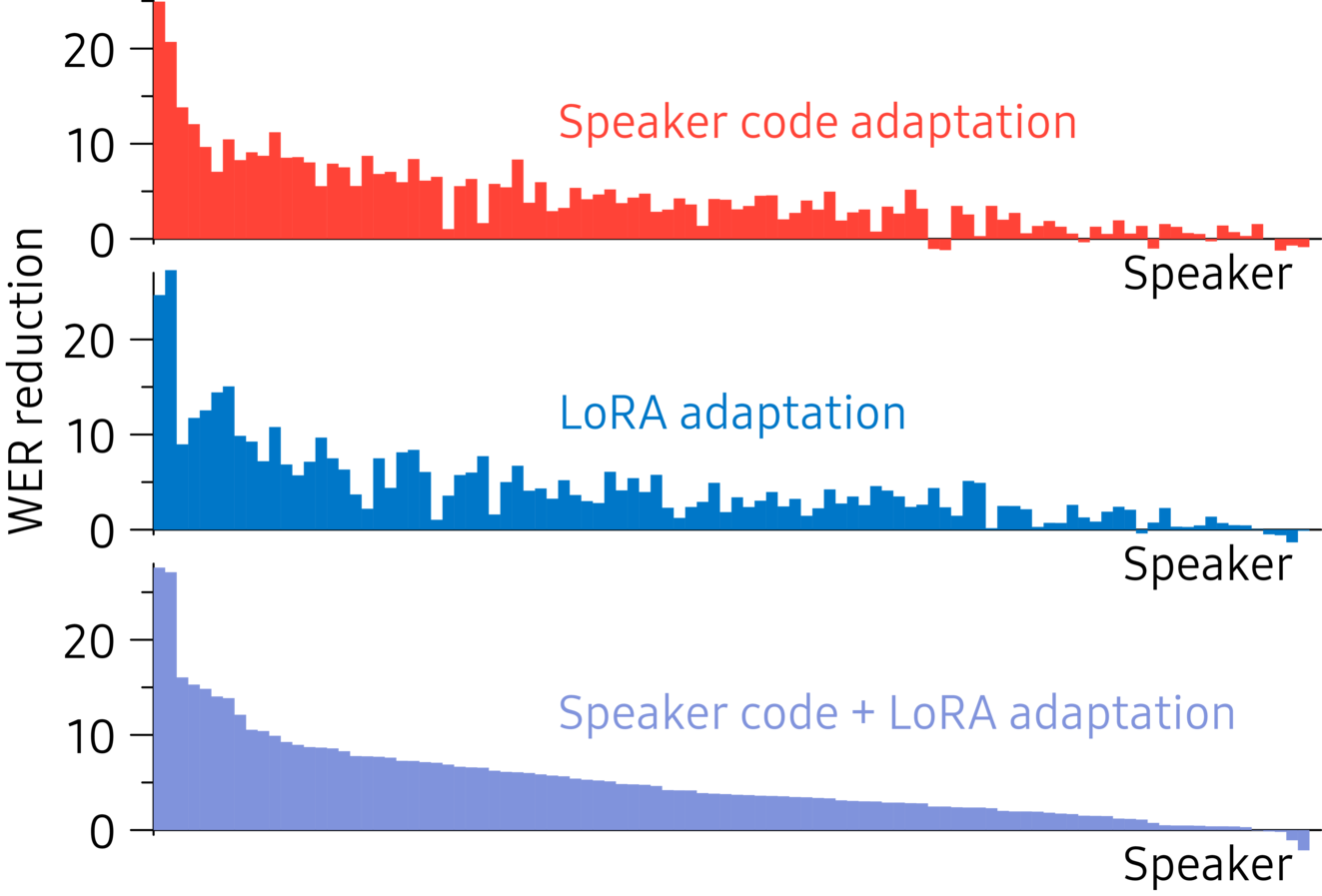
Figure 6. Per-speaker improvement in word error rate from adapting with the minimum-entropy loss on one minute of data. Speakers are sorted by descending average improvement.
Figure 6 shows the improvement per speaker. For all sets of adaptation parameters, performance improvements are seen for the vast majority of speakers, which underlines the robustness of the minimum-entropy loss.
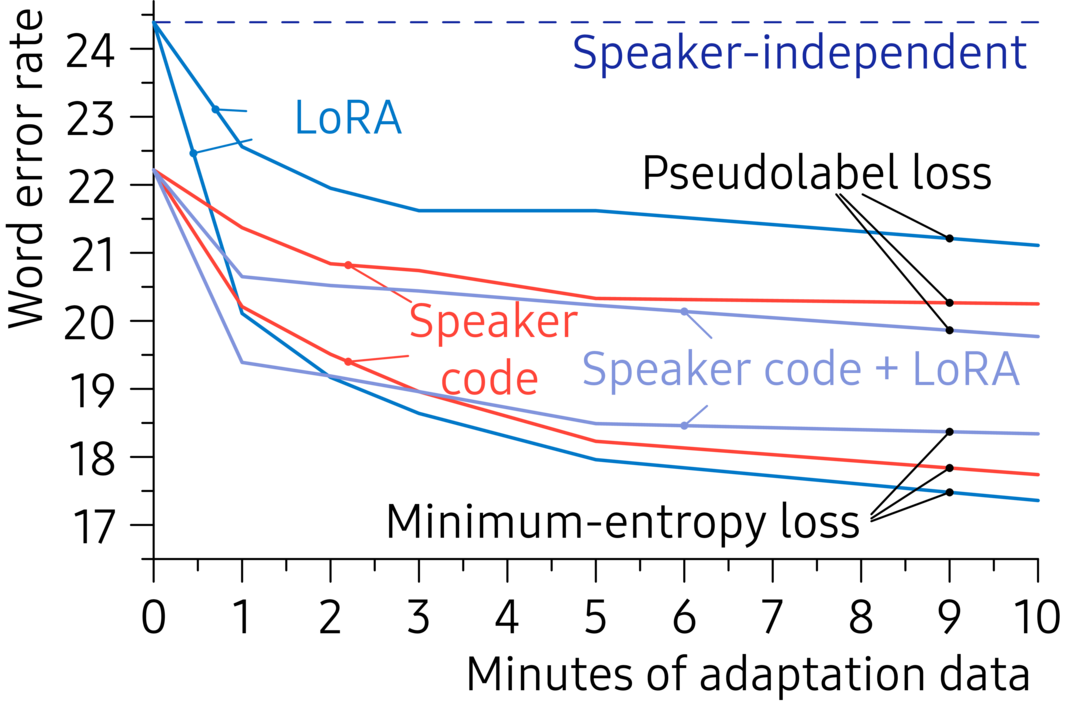
Figure 7. Average word error rates on CommonVoice-Farfield for adaptation with different amounts of adaptation data.
Figure 7 shows word error rates as a function of the amount of adaptation data. The improvement that the minimum-entropy loss gives is consistent for all amounts of adaptation data. For best performance, if there is a small amount of adaptation data, about one minute, it is useful to adapt both speaker code as well as LoRA. As more adaptation data becomes available, it is worthwhile switching to just LoRA.
Conclusion
This blogpost has examined how to adapt a speech recogniser to an unseen speaker, using only a small amount of unlabelled adaptation data. It has proposed two methods to improve robustness of adaptation. First, instead of using the standard pseudolabel loss, a new loss, the conditional entropy over the sequence of words that the speech recogniser outputs has been proposed. Second, it has proposed to use speaker codes on an encoder-decoder recogniser. Both methods help improve performance on small amounts of data.
References
[1] Y. Grandvalet and Y. Bengio, “Semi-supervised learning by entropy minimization,” in Advances in Neural Information Processing Systems, 2004.
[2] D. Wang, E. Shelhamer, S. Liu, B. Olshausen, and T. Darrell, “Tent: Fully test-time adaptation by entropy minimization,” in Proceedings of Conference on Learning Representations, 2021.
[3] M. Zhang, S. Levine, and C. Finn, “MEMO: Test time robustness via adaptation and augmentation,” in Advances in Neural Information Processing Systems, 2022.
[4] E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” in Proceedings of Conference on Learning Representations, 2022.
[5] O. Abdel-Hamid and H. Jiang, “Fast speaker adaptation of hybrid NN/HMM model for speech recognition based on discriminative learning of speaker code,” in Proceedings of International Conference on Acoustics, Speech, and Signal Processing, 2013.
[6] S. Xue, O. Abdel-Hamid, H. Jiang, and L. Dai, “Direct adaptation of hybrid DNN/HMM model for fast speaker adaptation in LVCSR based on speaker code,” in Proceedings of International Conference on Acoustics, Speech, and Signal Processing, 2014.
[7] R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Henretty, R. Morais, L. Saunders, F. Tyers, and G. Weber, “Common Voice: A massively-multilingual speech corpus,” in Proceedings of the Language Resources and Evaluation Conference, May 2020. [Online]. Available: https://aclanthology.org/2020.lrec-1.520/
[8] M. Ravanelli, T. Parcollet, A. Moumen, S. de Langen, C. Subakan, P. Plantinga, Y. Wang, P. Mousavi, L. D. Libera, A. Ploujnikov, F. Paissan, D. Borra, S. Zaiem, Z. Zhao, S. Zhang, G. Karakasidis, S.-L. Yeh, P. Champion, A. Rouhe, R. Braun, F. Mai, J. Zuluaga-Gomez, S. M. Mousavi, A. Nautsch, H. Nguyen, X. Liu, S. Sagar, J. Duret, S. Mdhaffar, G. Laperrière, M. Rouvier, R. D. Mori, and Y. Estève, “Open-source conversational AI with SpeechBrain 1.0,” Journal of Machine Learning Research, vol. 25, no. 333, pp. 1–11, 2024. [Online]. Available: http://jmlr.org/papers/v25/24-0991.html




