AI
Multi-task Learning for Speech Emotion Recognition in Naturalistic Conditions
1. Introduction
Speech Emotion Recognition (SER) is a crucial task in human-computer interaction, enabling applications such as mental health monitoring, affective computing, and customer service automation. Despite significant advancements in deep learning and signal processing, SER in naturalistic conditions remains a challenge due to factors such as background noise and speaker variability [1].
Various approaches have been explored for emotion classification, ranging from traditional linear classifiers and hidden Markov model-based to more advanced deep learning methods [2, 3, 4]. Early techniques relied on linear models to differentiate emotional states, while later advancements introduced recurrent neural networks to capture temporal dependencies in speech data [5]. Additionally, spectrogram-based convolutional neural networks (CNNs) have been widely used to extract spatial and frequency-based features, demonstrating significant improvements in performance [6, 7].
Since the introduction of the Transformer [8], deep neural networks based on this architecture have become the leading choice for sequence modeling. Pretrained encoder-only models, such as BERT [9] and RoBERTa [10], have proven highly effective when fine-tuned for various downstream tasks, including sentence classification and question answering. Emotion recognition is a case of sequence modeling, as emotions are typically influenced by prior contextual events across different modalities. Recent advancements in SER have prominently featured self-supervised learning (SSL) models, such as Wav2Vec2, which have demonstrated superior performance on benchmark datasets such as IEMOCAP [11].
The fundamental task in SER involves classifying emotions based on either a predefined set of categories or continuous emotional dimensions. In the latter approach, the valence-arousal model is widely used to analyse emotions along these two core dimensions [12]. Valence refers to the intrinsic positivity or negativity of an emotion, while arousal measures the intensity or activation level of the emotional experience [13]. This model allows for a nuanced representation of emotions beyond categorical labels, facilitating a more comprehensive understanding of affective states. For example, emotions such as excitement and anger can share high arousal levels but differ in valence, with excitement being positive and anger negative. Conversely, emotions such as sadness and calmness may both exhibit low arousal but differ in valence [13, 14]. A widely recognized extension of the valence-arousal framework is the Arousal-Valence-Dominance (AVD) model, which introduces a dominance dimension to account for the degree of control a person feels over their emotional state [15].
Multi-task learning (MTL) is a deep learning approach that optimizes a model for multiple related tasks simultaneously. By sharing representations across tasks, MTL can improve generalization, reduce overfitting, and enhance performance. This approach has been explored in various domains, including natural language processing, computer vision, and speech processing [16, 17]. Previous research highlights the benefits of MTL for emotion classification [18]. In [19] and [20], the authors employ a bi-encoder architecture combined with MTL to classify emotions in images, while [21] introduces a CNN-based MTL model for both classification and regression in speech-based emotion recognition. These studies demonstrate that MTL can effectively improve performance by leveraging shared knowledge across tasks.
In this paper, we propose a multi-task learning framework for speech emotion recognition that integrates the Whisper encoder with WavLM and RoBERTa models to classify speaker emotions and estimate speech attributes efficiently using both text and audio modalities. We design our system for the Speech Emotion Recognition in Naturalistic Conditions Challenge [22], and achieve a top 10 spot in categorical emotion classification and 2nd place in emotional attribute prediction. Additionally, we demonstrate the significance of multi-task learning in enhancing model performance on both tasks.
2. Dataset
The dataset used in this study is the MSP-Podcast corpus [23], which contains emotional speech samples with transcripts from podcast recordings labelled through crowdsourcing. The dataset consists of a total of 119,421 samples, of which 116,221 are labelled and 3,200 are provided with audio only, to be used as test data in the Challenge. The provided labelled samples were split into training and development sets, containing 84,260 and 31,961 samples, respectively. Each sample was annotated by at least five persons, with most, more than 100,000 samples, receiving exactly five annotations. The dataset was labelled by 13,087 annotators, of whom the majority (12,526) annotated fewer than 100 samples. For emotion classification, the annotators selected a single primary emotion from nine categories: anger, sadness, happiness, surprise, fear, disgust, contempt, neutral, and other, while secondary emotions were chosen from an expanded set. The unlabelled test set did not contain any samples that should be classified as “other”. For emotional attributes, samples were rated on a seven-point Likert scale for arousal (calm to active), dominance (weak to strong), and valence (negative to positive) [24]. The final ground truth labels were determined using majority voting for categorical emotion recognition and averaging for emotional attribute prediction.
3. Methodology
This section discusses the architecture of the proposed solution and the details of the joint training process for both Challenge tasks.
3.1. System architecture
Emotion classification and attribute estimation are complex tasks that depend on both the speaking style and content of the speech. To capture these aspects effectively, we process both the audio recording and its transcription simultaneously. However, training a deep learning solution for such a task on a relatively small dataset presents significant challenges. To address this, we leverage pre-trained expert models that extract latent space features from both text and audio modalities, enabling more robust and generalizable representations. In this paper, we propose an architecture leveraging three pre-trained encoders: Whisper Encoder [25], WavLM [26], and RoBERTa [10].
Whisper is an automatic speech recognition (ASR) model based on an encoder-decoder architecture, designed to perform well in noisy environments. It is trained to generalize effectively across various languages, accents, and audio qualities, making it particularly suitable for tasks involving spontaneous and emotionally expressive speech. Recent research has leveraged Whisper Encoder as an advanced feature extractor for downstream tasks such as SER, demonstrating its ability to capture both linguistic and acoustic cues [27].
Complementing Whisper, WavLM is a Transformer-based SSL model trained on large-scale speech data using masked speech prediction. It excels at capturing both local and global speech representations, making it highly effective for tasks such as speaker recognition, speech enhancement, and SER. WavLM has been shown to improve emotion recognition performance by providing rich prosodic and phonetic features that contribute to more accurate affective modeling [26, 28].
To analyse speech transcriptions extracted by Whisper we utilize RoBERTa, a Transformer-based model designed for natural language processing tasks [10]. It builds upon BERT by optimizing training strategies, including dynamic masking, larger batch sizes, and more extensive pretraining on diverse text datasets [9]. These enhancements allow RoBERTa to capture richer contextual representations, making it highly effective for tasks such as sentiment analysis and text classification.
To aggregate and interpret the outputs from multiple encoder models, we propose a fusion module consisting of attentive statistics pooling (ASP) layers [29], projection layers, and a LSTM model. We employ the ASP mechanism to reduce the dimensionality of the outputs from each encoder. Next, dense layers are used to project the embeddings into a common dimensionality. To enable the model to capture relationships between embeddings from different experts, we incorporate LSTM layers. Finally, a single linear layer predicts both emotion logits and speech attribute values, with a scaled sigmoid function applied to constrain attribute values within the dataset’s range of 1–7. The architectural diagram of the proposed solution is presented in the Figure 1.
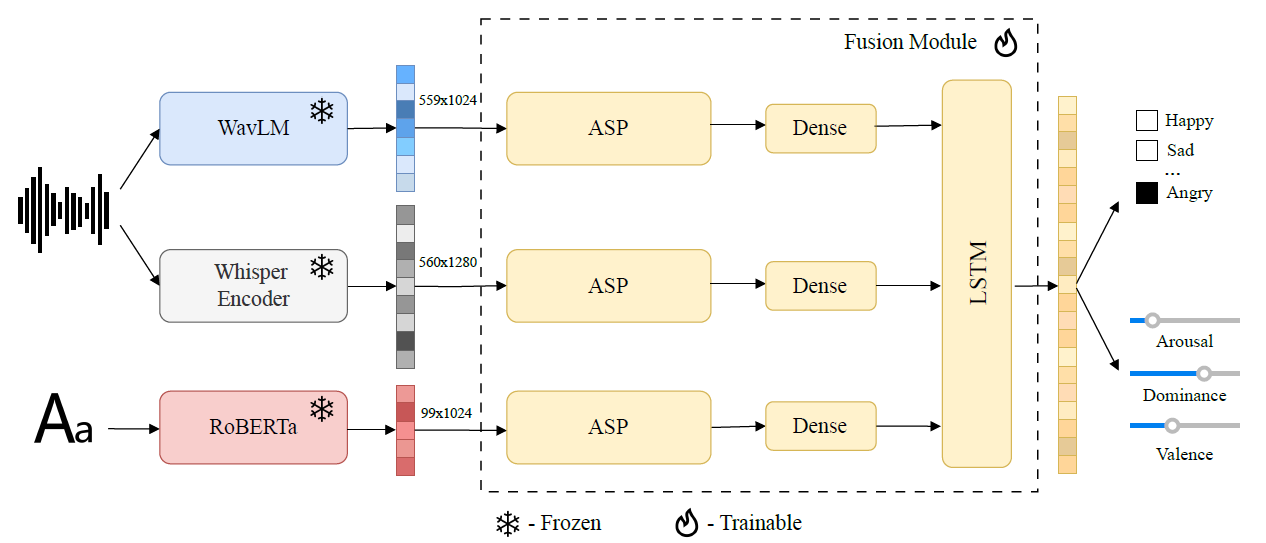
Figure 1. Block diagram of the proposed multi-encoder, multi-task system for joint classification and regression.
3.2. Training strategy
Speech emotion recognition and speech attribute prediction are highly correlated tasks, as both rely on similar latent features of the audio. To leverage this relationship, we design our training process in two phases: multi-task pre-training and task-specific fine-tuning.
To train the model simultaneously on both tasks, we use a weighted sum of loss functions, where the weights are treated as training hyperparameters. For model optimization, we employ two loss functions: weighted cross-entropy loss for emotion classification and mean squared error for speech attribute prediction. The loss function is defined as follows:
$L_{total}=α·L_{reg}+β·L_{class}$ (1)
where $α$ and $β$ are the weights for regression and classification, respectively. $L_{reg}$ represents the mean squared error loss computed over the three predicted attributes, while $L_{class}$ denotes the weighted cross-entropy loss for the classification task.
The second stage of training is task-specific fine-tuning. For the classification task, we use a standard cross-entropy loss. In the regression task, the label distribution of the attribute values caused the model to focus on predictions close to the mean. To address this, we modify the loss function by incorporating a Gaussian penalty. The final formulation of the loss function is presented below.
$L_{reg}=\frac{1}{N}\sum_{i=1}^{N}exp (-\frac{(\hat{y}_i-µ)²}{2σ²})·(y_i-\hat{y}_i)²$ (2)
where $y_i$ is the true value, $\hat{y}_i$ is the predicted value, $µ = 4$ and $σ$ are set as the mean and standard deviation of the Gaussian function and $N$ is the number of samples in the batch.
Scaling the loss function penalises the model for predicting values close to the mean that are actually far from the true values. This approach significantly expanded the model prediction value range.
4. Experiments
This section provides a detailed overview of the conducted experiments, covering the encoder models, hyperparameter settings, data processing and training setup. Additionally, we examine the joint training strategy and its impact on model performance.
4.1. Data
The utilization of multiple-annotator data presents significant methodological challenges in model training across both classification and regression tasks. We decided to use a consensus-based approach that takes into account all annotators’ votes. Consequently, the final models were trained on majority consensus labels, with the exclusion of instances of ambiguous annotations classified with label “X”. For classification task, model fine-tuning excluded instances labelled “other”.
After excluding the ambiguously labelled instances, we split the remaining 94,328 samples into a training set of 68,428 samples and a validation set of 25,900 samples, following the same train-development split as the original dataset. These splits were used to train and validate the models submitted to the Challenge. For our ablation studies, we further split the labelled dataset into three parts due to the lack of explicit access to original test set labels. We divide the original training dataset into two subsets: a new training set with 61,495 samples and a validation set with 6,833 samples. The original development dataset, containing 25,900 samples, was reserved as a test set for evaluating our models.
To address the lack of transcripts for the unlabelled test data, we employ the Whisper v3 large model to transcribe the audio files. Additionally, we apply a range of augmentations to the training dataset. We add random noise, reverberation and apply gain adjustments ranging from -5 dB to +5 dB.
4.2. Encoders
In our final system we decided to use the expert encoder variants outlined in Chapter 3.1. The key technical specifications of these variants are as follows:
The WavLM consists of 24 transformer layers with approximately 310 million parameters and a model dimensionality of 1024. For training, we utilized pretrained weights from the HuggingFace transformers library (“microsoft/wavlm-large”) [30].
The Whisper Encoder consists of 32 transformer layers and approximately 635 million parameters, with a model dimensionality of 1280. We used the “openai/whisper-large-v3” checkpoint from HuggingFace transformers.
The RoBERTa was utilized to process the transcribed speech, generating feature vectors of size 1024. The model consists of 12 transformer layers and approximately 355 million parameters. For training, we used the pretrained weights from the HuggingFace transformers library (“FacebookAI/roberta-large”).
To help prevent overfitting, we decided to use frozen encoders during training. Additionally, to optimize resource usage during the experiments, we saved the embeddings to disk. This approach helped to speed up the training process by reducing memory usage and computational demands.
4.3. Fusion module
Each encoder generates a sequence of embeddings of varying lengths. To reduce the temporal dimension, we applied ASP. To ensure a uniform representation, each output is processed through a dedicated dense layer, mapping the embeddings to a standardized dimension of 1028. Next, Layer Normalization is applied to normalize the embedding sequence before passing it through two LSTM layers with an input dimension of 1028. This component of the model is responsible for aggregating information and capturing dependencies within the multimodal input. The internal LSTM dimension was set to 2048, resulting in a total of about 60M parameters. Finally, the last output embedding is utilized for both classification and regression tasks via an additional dense layer.
4.4. Multi-task training
To evaluate the effectiveness of the proposed multi-expert multi-task training approach, we compared three joint trainings with varying weights for each task’s loss importance against two single-task training procedures, where the weight of loss for the other task was set to zero. The models were trained for 50 epochs with a batch size of 128, using 32,000 samples per epoch. Training was conducted with the AdamW optimizer, setting a maximum learning rate of 2e-5. To adjust the learning rate dynamically, we employed a cosine annealing scheduler with a three-epoch warm-up phase, gradually reducing it to a minimum of 1e-7. In this ablation study, data augmentation was not applied.
4.5. Ablation study results
The results presented in Table 1 demonstrate the effectiveness of our joint training approach, which outperforms separate training procedures in terms of overall performance. The weights $α$ and $β$ were chosen from 0 to 1 range with a 0.25 step. Specifically, we observe a 5% increase in the F1 macro metric and a 3% increase in the average Concordance Correlation Coefficient for the chosen $α$ and $β$ weights. This suggests that joint training allows the model to capture the complex relationships between classification and regression tasks, leading to more accurate and robust predictions.
One of the key advantages of joint training is the ability to balance classification and regression performance using the $α$ and $β$ parameters as hyperparameters. By adjusting these parameters, we can tailor the model’s performance to prioritize either task. This flexibility is particularly useful in scenarios where computational resources are limited, as it enables the deployment of a single, unified model that can efficiently perform both tasks simultaneously.
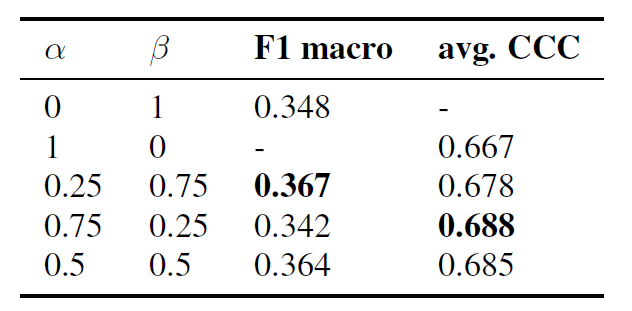
Table 1. Evaluation performance on MSP-Podcast dev split for different loss function weight configurations.
5. Challenge submissions
For the Speech Emotion Recognition in Naturalistic Conditions Challenge, we participated in two independent tasks. The first task, categorical emotion recognition, involved classifying data into one of eight emotional categories. In the second task, emotional attribute prediction, our goal was to predict emotional attributes along three dimensions: arousal, valence, and dominance. These attributes were labelled with continuous values between 1 and 7. In this section, we present our approach to training and the preparation of final submissions for both tasks.
The training procedure for models submitted for both tasks followed a two-stage process: pre-training and fine-tuning. The pre-training phase was conducted in the same manner as the experiment described in chapter 4.4. However, in this case, the model was trained on the whole training dataset and validated on the dev set. The parameters $α$ and $β$ were set to 0.25 and 0.75, respectively, for Task 1, and to 0.75 and 0.25 for Task 2.
5.1. Task 1: Categorical emotion recognition
We selected the top-performing pre-trained model based on its macro F1 score and fine-tuned it for Task 1. After removing samples labelled as “other” as described in Section 4.1, we explored three fine-tuning approaches. These included setting the maximum learning rate to 1e-5 (1), reducing it to 1e-6 (2), and using weighted loss penalization to address classes that were frequently misclassified (3). We evaluated the performance of each method on the development split after 20 epochs and present the results in Table 2. The third approach, which used weighted loss penalization, yielded the best results, with a macro F1 score of 0.3995 on the development set. We submitted this model to the Challenge’s Task 1, where it achieved a macro F1 score of 0.3784 on the test set. This placed us 9th among all teams participating in Task 1.
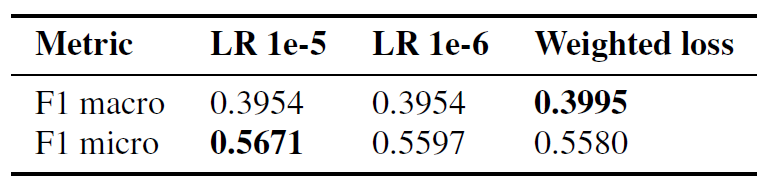
Table 2. Results of models fine-tuned for Task 1
5.2. Task 2: Emotional attribute prediction
For further fine-tuning for Task 2, we utilized the two best-performing pre-trained models. One model was trained in the same manner as the experiment explained in Section 4.4, while the second was trained using average pooling instead of ASP. These models achieved average CCC scores of 0.689 and 0.690, respectively. We used a maximum learning rate of 5e-6 for 30 epochs with a cosine annealing scheduler, setting the minimum learning rate to 1e-7. To introduce diversity among the fine-tuned models, we incorporated the Gaussian penalty into the loss function, as described in Section 3.2. We conducted three experiments per pre-trained model, varying the $σ$ parameter at 3, 5, and 7. Additionally, we performed fine-tuning without the Gaussian penalty.
For the final submission, we employed an ensemble of the top-performing models for each attribute. For valence, we utilized the three top-performing checkpoints after fine-tuning, along with the pre-trained model that incorporated attention pooling. For the arousal and dominance attributes, we selected the three most effective models for each respective attribute, combined with Challenge baseline predictions [22]. The performance of the proposed system is shown in Table 3. Our submission was ranked third on the provided leaderboard, securing second place among competing teams.
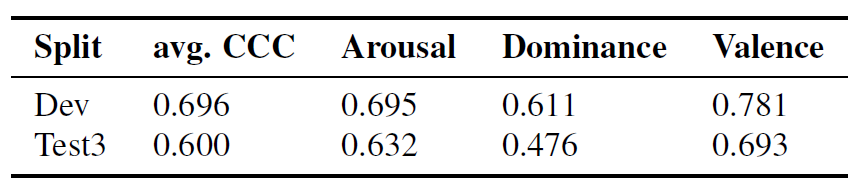
Table 3. Results of ensamble system fine-tuned for Task 2
6. Conclusions and limitations
In this paper, we presented our solution for the Interspeech 2025 Speech Emotion Recognition Challenge under naturalistic conditions. Our approach is based on a multi-task learning framework with a multi-encoder model architecture. Experimental results demonstrate that training jointly on emotion classification and speech attribute prediction improves performance compared to training each task separately.
Moreover, our system consistently outperforms the Challenge baseline in both tasks. For Task 1 (speech emotion classification), our model achieved an F1 score of 0.378, surpassing the baseline score of 0.329 and securing a top-10 position in the Challenge. For Task 2 (emotional attribute prediction), our approach attained an average concordance correlation coefficient of 0.60, outperforming the baseline score of 0.58 and earning 2nd place among competing teams. These results further validate the effectiveness of our proposed architecture and training framework in enhancing speech emotion recognition performance.
References
[1] S. M. George and P. M. Ilyas, “A review on speech emotion recognition: A survey, recent advances, challenges, and the influence of noise,” Neurocomputing, vol. 568, p. 127015, 2 2024.
[2] C. Yu, Q. Tian, F. Cheng, and S. Zhang, “Speech emotion recognition using Support Vector Machines,” in Advanced Research on Computer Science and Information Engineering, G. Shen and X. Huang, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2011, pp. 215–220.
[3] L. Sun, S. Fu, and F. Wang, “Decision tree SVM model with Fisher feature selection for speech emotion recognition,” EURASIP Journal on Audio, Speech, and Music Processing, vol. 2019, p. 2, 12 2019.
[4] B. Schuller, G. Rigoll, and M. Lang, “Hidden Markov model-based speech emotion recognition,” in 2003 International Conference on Multimedia and Expo. ICME ’03. Proceedings (Cat. No.03TH8698), vol. 1, 2003, pp. I–401.
[5] D. Li, J. Liu, Z. Yang, L. Sun, and Z. Wang, “Speech emotion recognition using recurrent neural networks with directional self-attention,” Expert Systems with Applications, vol. 173, p. 114683, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S095741742100124X
[6] C. Wei, X. Sun, F. Tian, and F. Ren, “Speech emotion recognition with hybrid neural network,” in 2019 5th International Conference on Big Data Computing and Communications (BIGCOM), 2019, pp. 298–302.
[7] Y. Zhao and X. Shu, “Speech emotion analysis using convolutional neural network (CNN) and gamma classifier-based error correcting output codes (ECOC),” Scientific Reports, vol. 13, p. 20398, 11 2023.
[8] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proceedings of the 31st International Conference on Neural Information Processing Systems, ser. NIPS’17. Red Hook, NY, USA: Curran Associates Inc., 2017, p. 6000–6010.
[9] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1. Minneapolis, Minnesota: Association for Computational Linguistics, Jun. 2019, pp. 4171–4186. [Online]. Available: https://aclanthology.org/N19-1423/
[10] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “RoBERTa: A robustly optimized BERT pretraining approach,” 2020. [Online]. Available: https://openreview.net/forum?id=SyxS0T4tvS
[11] L.-W. Chen and A. Rudnicky, “Exploring wav2vec 2.0 fine tuning for improved speech emotion recognition,” in ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5.
[12] L. F. Barrett, “Discrete emotions or dimensions? the role of valence focus and arousal focus,” Cognition and Emotion, vol. 12, no. 4, pp. 579–599, 1998. [Online]. Available: https://doi.org/10.1080/026999398379574
[13] J. A. Russell, “Affective space is bipolar,” Journal of personality and social psychology, vol. 37, no. 3, p. 345, 1979.
[14] S. Buechel and U. Hahn, “Emobank: Studying the impact of annotation perspective and representation format on dimensional emotion analysis,” in Conference of the European Chapter of the Association for Computational Linguistics, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:11509125
[15] A. Mehrabian, “Pleasure-arousal-dominance: A general framework for describing and measuring individual differences in temperament,” Current Psychology, vol. 14, pp. 261–292, 12 1996.
[16] J. Lu, V. Goswami, M. Rohrbach, D. Parikh, and S. Lee, “12-in-1: Multi-task vision and language representation learning,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 6 2020, pp. 10434–10443.
[17] S. Sigtia, E. Marchi, S. Kajarekar, D. Naik, and J. Bridle, “Multi-task learning for speaker verification and voice trigger detection,” in ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, May 2020. [Online]. Available: http://dx.doi.org/10.1109/ICASSP40776.2020.9054760
[18] X. Cai, J. Yuan, R. Zheng, L. Huang, and K. Church, “Speech emotion recognition with multi-task learning,” in Interspeech 2021, 2021, pp. 4508–4512.
[19] I. Bendjoudi, F. Vanderhaegen, D. Hamad, and F. Dornaika, “Multi-label, multi-task CNN approach for context-based emotion recognition,” Information Fusion, vol. 76, pp. 422–428, 12 2021.
[20] S. Ghosh, U. Tyagi, S. Ramaneswaran, H. Srivastava, and D. Manocha, “MMER: Multimodal Multi-task Learning for Speech Emotion Recognition,” 2023, pp. 1209–1213.
[21] N. K. Kim, J. Lee, H. K. Ha, G. W. Lee, J. H. Lee, and H. K. Kim, “Speech emotion recognition based on multi-task learning using a convolutional neural network,” in 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2017, pp. 704–707.
[22] L. Goncalves, A. N. Salman, A. R. Naini, L. Moro-Velázquez, T. Thebaud, P. Garcia, N. Dehak, B. Sisman, and C. Busso, “Odyssey 2024 - speech emotion recognition challenge: Dataset, baseline framework, and results,” in The Speaker and Language Recognition Workshop (Odyssey 2024), 2024, pp. 247–254.
[23] R. Lotfian and C. Busso, “Building naturalistic emotionally balanced speech corpus by retrieving emotional speech from existing podcast recordings,” IEEE Transactions on Affective Computing, vol. 10, no. 4, pp. 471–483, 2019.
[24] R. Likert, “A technique for the measurement of attitudes,” Archives of Psychology, vol. 22, no. 140, pp. 5–55, 1932.
[25] A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” in International Conference on Machine Learning, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:252923993
[26] S. Chen, C. Wang, Z. Chen, Y. Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y. Qian, Y. Qian, M. Zeng, and F. Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, pp. 1505–1518, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:239885872
[27] X. Qu, Z. Sun, S. Feng, C. Chen, and T. Tian, “Breaking the silence: Whisper-driven emotion recognition in AI mental support models,” in 2024 IEEE Conference on Artificial Intelligence (CAI). Los Alamitos, CA, USA: IEEE Computer Society, 2024, pp. 290–291. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/CAI59869.2024.00063
[28] J. Yang, J. Liu, K. Huang, J. Xia, Z. Zhu, and H. Zhang, “Single- and cross-lingual speech emotion recognition based on WavLM domain emotion embedding,” Electronics, vol. 13, no. 7, 2024. [Online]. Available: https://www.mdpi.com/2079-9292/13/ 7/1380
[29] K. Okabe, T. Koshinaka, and K. Shinoda, “Attentive statistics pooling for deep speaker embedding,” in Interspeech 2018. ISCA, 2018. [Online]. Available: http://dx.doi.org/10.21437/ Interspeech.2018-993
[30] T. Wolf, L. Debut, V. Sanh et al., “Transformers: State-of-the-art natural language processing,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Online: Association for Computational Linguistics, Oct. 2020, pp. 38–45. [Online]. Available: https://www.aclweb.org/anthology/2020.emnlp-demos.6



