AI
Predicting High-precision Depth on Low-Precision Devices Using 2D Hilbert Curves
Introduction
Dense depth prediction is widely utilized in such areas as scene understanding [1, 2], autonomous driving [3, 4], robotics [5], AR/VR [6], IoT [7]. Usually, applications in these areas have strong limitations on hardware capabilities. However, the impressive progress made so far in the domain of monocular [8-11] and binocular [12, 13] depth estimation comes at the expense of a significant increase in the complexity, which typically demands considerable computational and memory resources.
The efficiency of Deep Neural Networks (DNNs) inference on low-end devices is achieved by using low-precision computations [14, 15] and low-bit representation of DNN weights and activations. Considerable research has been devoted towards reducing quantization error. However, the problem of data precision loss is largely unexplored, presumably because it does not pose a problem for models predicting RGB images, which are naturally presented as three eight-bit channels. In contrast, depth maps require at least ten or eleven bit for accurate representation (representation of range 0.5…10 m with 1cm accuracy requires ten bits). Consequently, low-end devices with low-precision computations necessarily lead to on-device depth quality loss. Solution to this problem can be in usage on mixed-precision quantization. Mixed-precision quantization is less power efficient as compared to uniform quantization and not always supported on low-end devices.
In the Visual Intelligence Team of SRUKR, we developed solution that allows using efficient uniform low-bit quantization of depth prediction DNNs and reconstruct higher bit-precision depth [16]. To overcome low-precision arithmetic limitation we use depth representation as points on a 2D Hilbert curve. This transform codes high dynamic range depth as two low dynamic range Hilbert curve components that can be represented in low-bit precision with minimum quality loss. Our method adds a computationally simple on-device post-processing step that converts low-bit precision Hilbert components to higher precision depth.
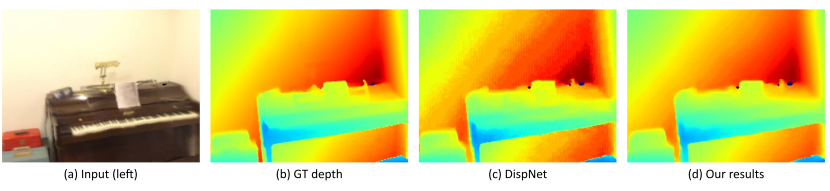
Figure 1. Illustration of DispNet [17] quantization to INT8 precision (W8A8). Running inference of the quantized model on Qualcomm Hexagon DSP results in depth precision loss and quantization artifacts (c). Our method increases depth bit-width and reduces quantization error (d).
In this blog post, we explain our solution including idea of depth representation in the form of two components of Hilbert curve, full precision model modification, training process modification, on-device inference and obtained performance gain.
Proposed approach
Let us consider a DNN that predicts disparity (or depth) $d$ normalized to the range [0, 1]. A quantized model runs on a low-end device that has an efficient DNN inferencing module (e.g. NPU or DSP) with $b$-bit output data representation and a general-purpose CPU with full-precision arithmetic. We seek to increase the bit-width of the predicted value of $d$ with minimum computational overhead.
Due to DSP limitations, the bit-width of the model output cannot be increased, so we can operate only with the number and structure of the output channels. These channels should be transferred from DSP to CPU and used to reconstruct disparity in higher bit precision. To make this scheme effective, the amount of data transferred from DSP to CPU and complexity of post-processing run on CPU should be minimized.
Our idea is to represent disparity $d$ as a point on a 2D parametric curve $(x(d), y(d))$ with length $L>1$, where both $x$ and $y$ are bounded in range [0, 1] (Figure 2). The full-precision DNN is trained to directly predict $x(d)$ and $y(d)$. When running inference on DSP, the value of d is calculated from $x$ and $y$ values predicted in $b$-bit precision. The parametric curve of length $L$ will pass through approximately $L·2^b$ discreet points $(x(d), y(d))$ effectively increasing precision of reconstructed value of $d$ by $log_2L$ bits. In this implementation, the amount of data to transfer from DSP to CPU increases only twofold, post-processing on CPU is simple and implemented using LUT.
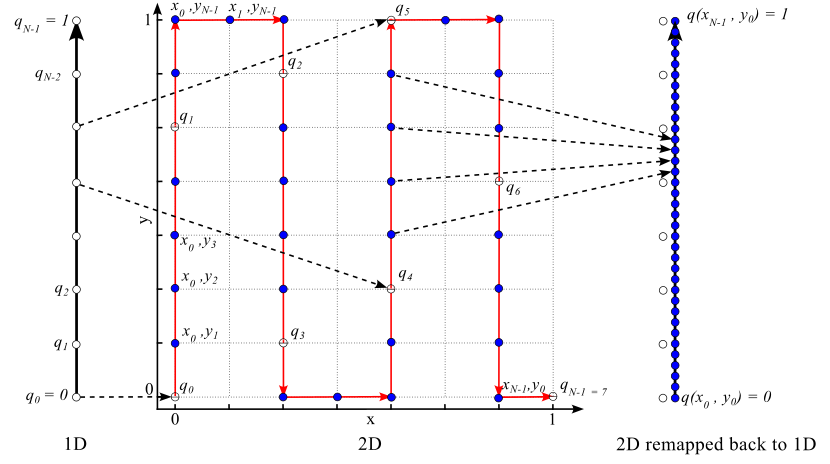
Figure 2. Idea illustration. 1D range is quantized to $N = 8$ values $q_0 = 0$ ... $q_{N-1} = 1$ marked by white circles. The 1D range is mapped to a 2D curve shown in red color. Both x and y axes are also quantized into $N = 8$ values yielding 64 2D points. Among them, 36 points lie on the curve (shown in blue color). Mapping the 2D curve back to the 1D range results in 36 different quantization values. Quantization error has effectively been reduced by the factor equal to the curve length $L = 35 / 7 = 5$
On-device deployment of the modified depth prediction DNN consists of the following steps: (a) training the full-precision model to directly predict the Hilbert curve components of depth representation, (b) applying standard quantization methods (either PTQ or QAT; QAT should be applied at the training stage), (c) running inference of the quantized model on-device and obtaining Hilbert curve components in low-bit precision, (d) applying post-processing to Hilbert curve components and reconstruct depth in higher-bit precision.
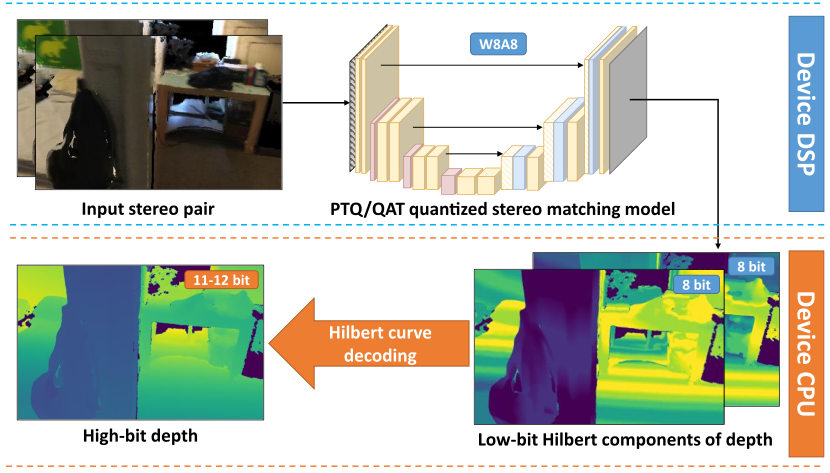
Figure 3. Scheme of the proposed method’s inference pipeline on device
Selection of the parametric curve is crucial for successful implementation of the proposed idea. We selected low-order Hilbert curve [18, 19] which is continuous fractal space-filling curve constructed as a limit of piece-wise linear curves. It possesses the following properties: continuity, non-self-intersection, boundedness and self-avoidance enabling efficient training of the full precision model and following quantization process. Curve length is $Lp=(2^p+1)(1+2k)$ , where p is the curve order, $k=0.1$ is scaling factor to avoid boundary effects. Curves of the second order with $L_2=4$ and third order with $L_3=7.2$ allows increasing bit precision by 2-3 bits. In this case, predicting Hilbert curve components in eight bit precision will provide necessary 10-11 bits for the final disparity/depth map.

Figure 4. Illustration of disparity transforms: (a) disparity map; (b) mapping to 2D with second order Hilbert curve; (c, d) x and y components of the Hilbert curve; (e, f) coarse and fine details of disparity map. Fine details in (f) are the least significant byte of disparity (a) represented in 16-bit format.
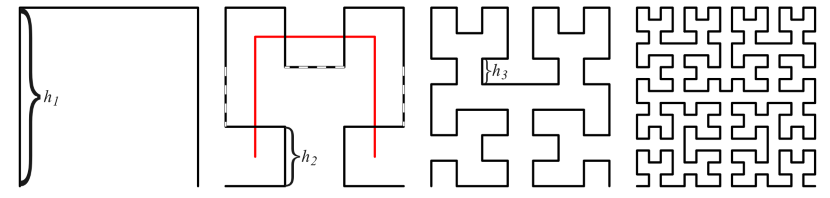
Figure 5. Hilbert curves for orders $p=1,2,3,4$ (from left to right). Every order is formed by the replacement of every node by an elementary 3-segment sequence.
To implement the proposed approach, a DNN with one head predicting disparity should be modified to have two heads predicting Hilbert curve components $x$ and $y$. Training is performed with a modified loss function that includes original disparity/depth loss and additional terms applied directly to the Hilbert curve components.
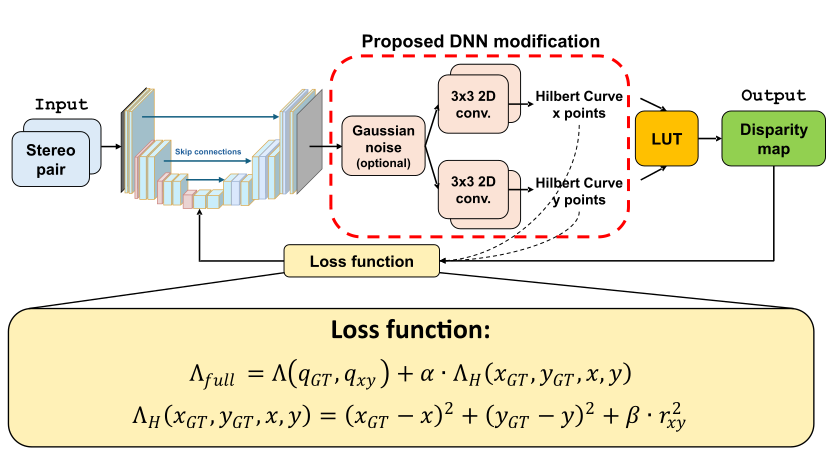
Figure 6. DispNet [17] model modification required by the proposed approach and proposed loss function
Experimental results
We validated our method on the stereo matching task. Training dataset is based on ScanNet v2 [1]. The DispNet [17] and Dense Prediction Transformer (DPT) [8] models are selected for the experiments. Modified models with third order Hilbert curve ($L=7.3$) dubbed as h3DispNet and h3DPT. All models were quantized to INT8 precision using SNPE SDK v.2.24 [20] and tested on Samsung S24 device. We characterize the quality of predicted depth maps using mean absolute relative error (Abs Rel) [21] and cosine similarity [22] between discrete cosine transform (DCT) [23] coefficients of ground truth and predicted depth maps, $S_c$. The measure $S_c$ takes values less than 1, with 1 corresponding to the perfect match between GT and predicted depth maps. Experimental results show that $S_c$ is sensitive to bit-precision loss. For the full precision and quantized models we confirmed that training the modified model that predicts Hilbert components is possible without quality degradation (See Figure 7).
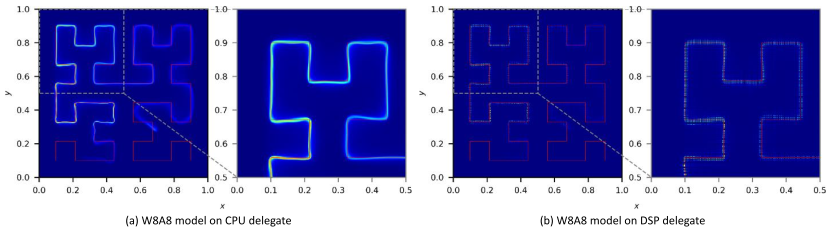
Figure 7. 2D histogram of h3DispNet W8A8 model output for CPU and DSP delegates
Quantitative results are presented in Table 1. For both DispNet and DPT models, quantization leads to quality degradation on DSP. The modified DispNet model in W8A8 format shows better quality than the original model in W8A16 format while simultaneously reducing energy consumption by 35% and latency by 30%. Compared to the original model in W8A16 format, the modified DPT model in W8A8 format shows significantly better Abs Rel metric and only slightly worse Sc. It also lowers energy demands by 34% and processing time by 54%. Examples for predicted depth maps and quantization error reduction are shown in Fig. 8.
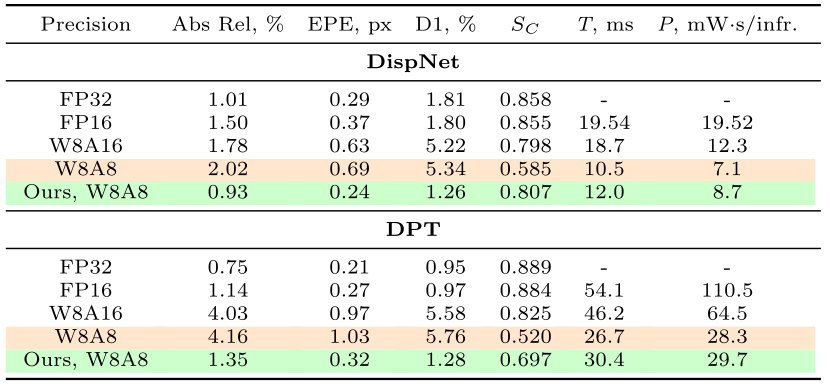
Table 1. On-device performance of the original and modified models including runtime (T) and power consumption (P). Measurements for our method include data transfer from DSP to CPU and Hilbert components post-processing on CPU. The overhead of our method is in runtime and power consumption increase between modified and original W8A8 models (compare lines marked by orange and green colors). Models in FP32 format are run on CPU; models in FP16, W8A16, W8A8 formats are run on DSP
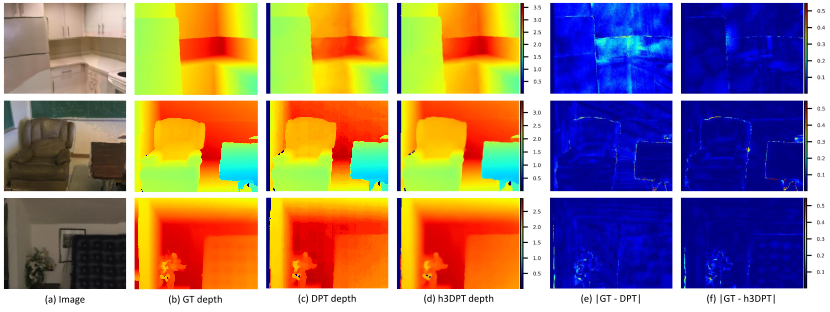
Figure 8. Depth errors of DPT and h3DPT models on DSP on ScanNet scenes. All values are presented in meters
We evaluate our approach on KITTI 2012 [24] dataset. KITTI 2012 is a real-world dataset for autonomous driving domain with sparse ground-truth disparities collected with a LiDAR system. Our evaluation is based on 194 images in the training part of KITTI 2012. Training dataset is composed of ScanNet and Virtual KITTI 2 [25] datasets with 25/75% balancing. The DispNet and h2DispNet models were trained in 256 by 1152 px input resolution and 128 by 576 px output disparity resolution. Training settings are the same as for the ScanNet experiment.
For the original DispNet model we reached EPE 1.38 px and D1 9.13%. Interestingly, h2DispNet shows better results with EPE 1.07 px and D1 5.22%. The DispNet model quantized to W8A8 format and run on DSP shows degradation of both EPE (to 1.63 px) and D1 (to 9.95%). At the same time the h2DispNet in W8A8 format on DSP shows very minor quality degradation (EPE 1.09 px and D1 5.36%). Measured as EPE between disparity predicted by FP32 and W8A8 models, quantization error is 1.01 px for the DispNet and 0.38 px for the h2DispNet. It corresponds to gain in disparity prediction quality on device of 2.6 times. Overall, on DSP the h2DispNet improves D1 by approximately 4.6% and EPE by about 33% compared to the original DispNet model. Examples of predicted disparity are given in Fig. 9. This experiment demonstrates that the proposed approach can be successfully applied to real datasets.
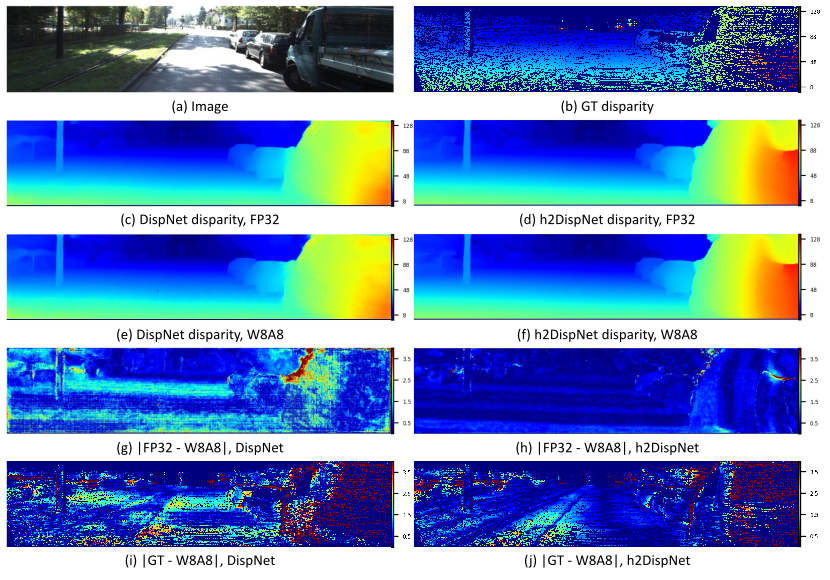
Figure 9. Comparison of DispNet and h2DispNet on KITTI 2012 dataset. Differences between disparity maps predicted by FP32 (CPU) (c, d) and W8A8 (DSP) (e, f) models are shown in (g) and (h); absolute disparity prediction errors for W8A8 (DSP) models are shown in (i) and (j). All values are presented in pixels
Conclusions
We proposed a novel method for high dynamic range depth prediction on devices with low-precision arithmetic that exploits depth representation as points on a 2D Hilbert curve. Experiments demonstrate that for the stereo matching task our method reconstructs depth in 10-11 bits for a model in W8A8 format and with quality similar to or even better than the original model in W8A16 format. In this manner, depth can be predicted on-device 1.4-2 times faster and with 65% of power consumption without sacrificing its quality. The proposed approach is beneficial for on-device application of different dense depth prediction methods including monocular and stereo depth prediction, Multi-View-Stereo, depth completion, depth quality enhancement, and depth inpainting. It can also be extended to other domains such as HDR images prediction on Human Pose Estimation with heatmaps.
Link to the paper
References
1. Dai, A., Chang, A. X., Savva, M., Halber, M., Funkhouser, T., and Nießner, M. ScanNet: richly-annotated 3D reconstructions of indoor scenes. In IEEE Conf. Comput. Vis. Pattern Recog., 2017. doi: 10.1109/CVPR.2017.261.
2. Yeshwanth, C., Liu, Y.-C., Nießner, M., and Dai, A. ScanNet++: A high-fidelity dataset of 3D indoor scenes. In Int. Conf. Comput. Vis., pp. 12–22, 2023. doi: 10.1109/ICCV51070.2023.00008.
3. Wang, Y., Chao, W.-L., Garg, D., Hariharan, B., Campbell, M., and Weinberger, K. Q. Pseudo-LiDAR from visual depth estimation: Bridging the gap in 3D object detection for autonomous driving. In IEEE Conf. Comput. Vis. Pattern Recog., pp. 8437–8445, 2019b. doi: 10.1109/CVPR.2019.00864.
4. You, Y., Wang, Y., Chao, W.-L., Garg, D., Pleiss, G., Hariharan, B., Campbell, M. E., and Weinberger, K. Q. Pseudo-LiDAR++: Accurate depth for 3D object detection in autonomous driving. In Int. Conf. Learn. Represent., 2020. https://openreview.net/forum?id=BJedHRVtPB.
5. Wofk, D., Ma, F., Yang, T.-J., Karaman, S., and Sze, V. FastDepth: Fast monocular depth estimation on embedded systems. In Int. Conf. on Robotics and Automation (ICRA), pp. 6101–6108, 2019. doi: 10.1109/ICRA.2019.8794182.
6. Rasla, A. and Beyeler, M. The relative importance of depth cues and semantic edges for indoor mobility using simulated prosthetic vision in immersive virtual reality. In Proc. of ACM Symp. on Virtual Reality Software and Tech., New York, NY, USA, 2022. Association for Computing Machinery. ISBN 9781450398893. doi: 10.1145/3562939.3565620.
7. Ignatov, A., Malivenko, G., Timofte, R., Treszczotko, L., Chang, X., Ksiazek, P., Lopuszynski, M., Pioro, M., Rudnicki, R., Smyl, M., Ma, Y., Li, Z., Chen, Z., Xu, J., Liu, X., Jiang, J., Shi, X., Xu, D., Li, Y., Wang, X., Lei, L., Zhang, Z., Wang, Y., Huang, Z., Luo, G., Yu, G., Fu, B., Li, J., Wang, Y., Huang, Z., Cao, Z., Conde, M. V., Sapozhnikov, D., Lee, B. H., Park, D., Hong, S., Lee, J., Lee, S., and Chun, S. Y. Efficient single-image depth estimation on mobile devices, mobile ai & aim 2022 challenge: Report. In Eur. Conf. Comput. Vis., pp. 71–91, 2022. doi: 10.1007/978-3-031-25066-8 4.
8. Ranftl, R., Bochkovskiy, A., and Koltun, V. Vision transformers for dense prediction. In Int. Conf. Comput. Vis., pp. 12179–12188, October 2021. doi: 10.1109/ICCV48922.2021.01196.
9. Ke, B., Obukhov, A., Huang, S., Metzger, N., Daudt, R. C., and Schindler, K. Repurposing diffusion-based image generators for monocular depth estimation. IEEE Conf. Comput. Vis. Pattern Recog., pp. 9492–9502, 2023. doi: 10.1109/CVPR52733.2024.00907.
10. Yang, L., Kang, B., Huang, Z., Xu, X., Feng, J., and Zhao, H. Depth anything: Unleashing the power of large-scale unlabeled data. IEEE Conf. Comput. Vis. Pattern Recog., pp. 10371–10381, 2024a. doi: 10.1109/CVPR52733.2024.00987.
11. Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., and Zhao, H. Depth anything v2. arXiv, 2024. doi: 10.48550/arXiv.2406.09414.
12. Lipson, L., Teed, Z., and Deng, J. RAFT-stereo: Multilevel recurrent field transforms for stereo matching. In Int. Conf. on 3D Vision (3DV), pp. 218–227, 2021. doi: 10.1109/3DV53792.2021.00032.
13. Xianqi, W., Gangwei, X., Hao, J., and Xin, Y. Selective-stereo: Adaptive frequency information selection for stereo matching. In IEEE Conf. Comput. Vis. Pattern Recog., pp. 19701–19710, 2024. doi: 10.1109/CVPR52733.2024.01863.
14. Li, G., Xue, J., Liu, L., Wang, X., Ma, X., Dong, X., Li, J., and Feng, X. Unleashing the low-precision computation potential of tensor cores on gpus. In IEEE/ACM Int. Symp. on Code Generation and Optimization (CGO), pp. 90–102, 2021. doi: 10.1109/CGO51591.2021.9370335.
15. Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., Adam, H., and Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In IEEE Conf. Comput. Vis. Pattern Recog., pp. 2704–2713, 2018. doi: 10.1109/CVPR.2018.00286.
16. Uss, M., Yermolenko, R., Shashko, O., Kolodiazhna, O., Safonov, I., Savin, V., Yeo, Y., Ji, S., and Jeong, J. Predicting High-precision Depth on Low-Precision Devices Using 2D Hilbert Curves. In Int. Conf. Mach. Learn., 2025. URL https://icml.cc/virtual/2025/poster/44496.
17. Mayer, N., Ilg, E., Häusser, P., Fischer, P., Cremers, D., Dosovitskiy, A., and Brox, T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In IEEE Conf. Comput. Vis. Pattern Recog., June 2016. doi: 10.1109/cvpr.2016.438.
18. Sagan, H. Space-filling curves. Springer Science & Business Media, 2012.
19. Bader, M. Space-filling curves: an introduction with applications in scientific computing, volume 9. Springer Science & Business Media, 2012. doi: 10.1007/978-3-642-31046-1.
20. Qualcomm Technologies, Inc. Snapdragon neural processing engine SDK, 2025. URL https://www.qualcomm.com/developer/software/neural-processing-sdk-for-ai.
21. Eigen, D., Puhrsch, C., and Fergus, R. Depth map prediction from a single image using a multi-scale deep network. Adv. Neural Inform. Process. Syst., pp. 2366–2374, 2014. doi: 10.5555/2969033.2969091.
22. Lahitani, A. R., Permanasari, A. E., and Setiawan, N. A. Cosine similarity to determine similarity measure: study case in online essay assessment. In Int. Conf. on Cyber and IT Service Management, pp. 1–6, 2016. doi: 10.1109/CITSM.2016.7577578.
23. Ahmed, N., Natarajan, T., and Rao, K. R. Discrete cosine transform. IEEE Trans. on Computers, 23(1):90–93, 1974. doi: 10.1109/T-C.1974.223784.
24. Geiger, A., Lenz, P., and Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In IEEE Conf. Comput. Vis. Pattern Recog., pp.3354–3361, 2012. doi: 10.1109/CVPR.2012.6248074.
25. Cabon, Y., Murray, N., and Humenberger, M. Virtual KITTI 2., arXiv, 2020. doi: 10.48550/arXiv.2001.10773.





