AI
[INTERSPEECH 2025 Series #6] Efficient Streaming TTS Acoustic Model with Depthwise RVQ Decoding Strategies in a Mamba Framework
|
Interspeech is one of the premier international conferences dedicated to advancing and disseminating research in the field of speech science and technology. It serves as a global platform where researchers, engineers, and industry professionals can share cutting-edge innovations, methodologies, and applications related to speech communication. In this blog series, we are introducing some of our research papers at INTERSPEECH 2025 and here is a list of them. #5. SPCODEC: Split and Prediction for Neural Speech Codec (Samsung R&D Institute China-Beijing) #6. Efficient Streaming TTS Acoustic Model with Depthwise RVQ Decoding Strategies in a Mamba Framework (AI Center-Seoul) #7. Robust Unsupervised Adaptation of a Speech Recogniser Using Entropy Minimisation and Speaker Codes (AI Center-Cambridge) #8. A Lightweight Hybrid Dual Channel Speech Enhancement System under Low-SNR Conditions (Samsung R&D Institute China-Nanjing) #9. Fairness in Dysarthric Speech Synthesis: Understanding Intrinsic Bias in Dysarthric Speech Cloning using F5-TTS (Samsung R&D Institute India-Bangalore) |
Introduction
Recent advancements in neural codec-based text-to-speech (TTS) systems have revolutionized speech synthesis quality, achieving remarkable naturalness and fidelity. However, these sophisticated models come with a significant challenge: their computational demands and large model sizes make deployment on CPU-based on-device applications particularly difficult. In this post, we introduce a groundbreaking solution that bridges this gap: a Mamba-based streaming acoustic model featuring innovative depthwise decoding strategies specifically designed for efficient, real-time TTS deployment on resource-constrained devices.
Proposed method
The Challenge: Bridging Quality and Efficiency
The shift toward discrete token-based TTS [1, 2, 3, 4] systems has brought substantial improvements in speech synthesis quality. These systems leverage residual vector quantization (RVQ)-based codecs [6, 7, 8, 9] to represent speech as multiple streams of discrete tokens, enabling more fine-grained acoustic modeling. However, while these advancements excel in high-resource, server-based environments, they do not inherently address the long-standing challenges of computational cost and real-time performance, which are critical for on-device applications. The computational demands of large models remain a bottleneck when deploying TTS systems on resource-constrained hardware, where latency and efficiency are important.
Our Solution: Mamba-Based Streaming with Depthwise Decoding
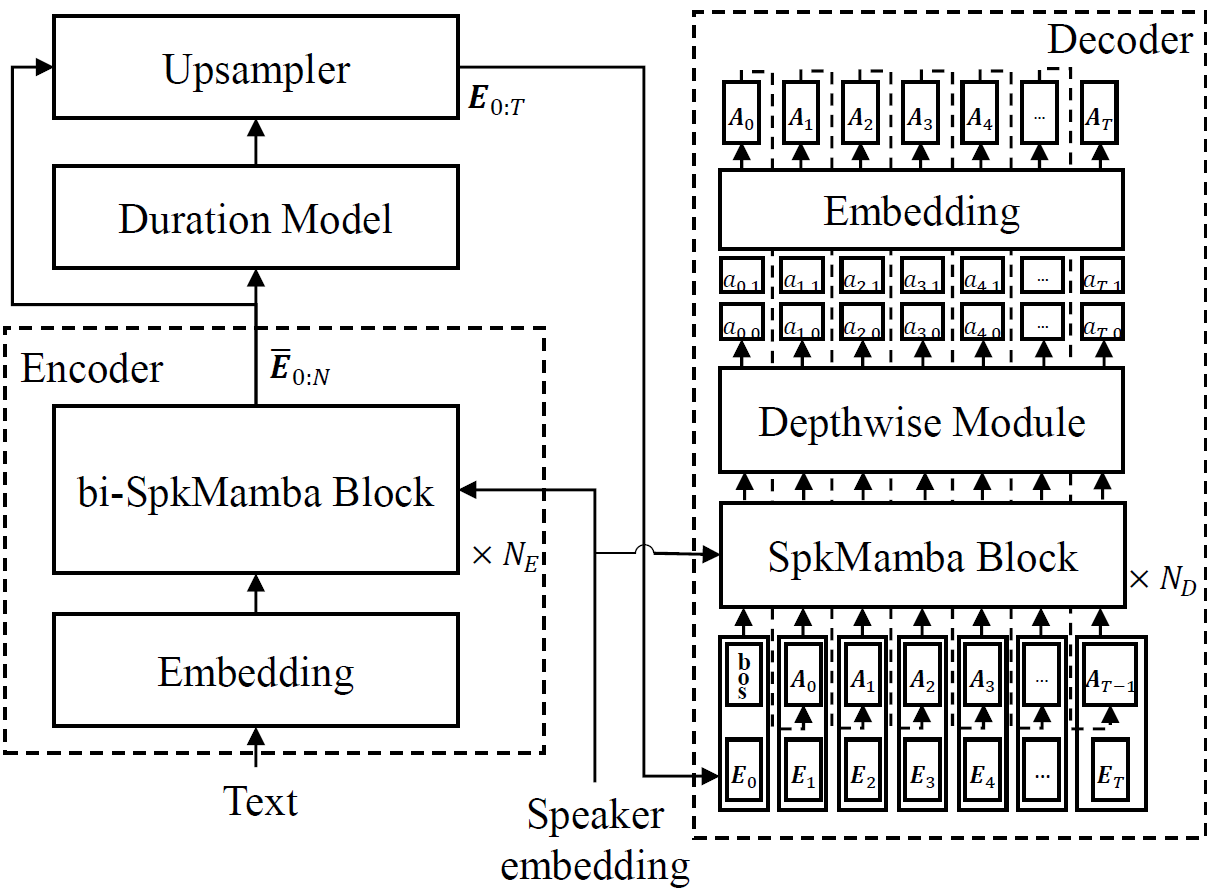
Figure 1. The overall architecture of our proposed acoustic model
We present a comprehensive solution built on three key innovations:
1. Mamba-Based Streaming Architecture
Unlike Transformer-based models that require global self-attention across entire sequences, Mamba [5] processes inputs incrementally, making it inherently suitable for streaming applications. Our architecture features:
- SpkMamba: Extends Mamba with speaker conditioning to enable zero-shot speaker conditioning. The speaker embedding is injected into the input projection layers of the Mamba block.
- Bidirectional Encoder: Processes the complete input text phoneme sequence using bidirectional SpkMamba blocks.
- Streaming Decoder: Operates autoregressively frame-by-frame, generating acoustic tokens in real-time as in the typical streaming TTS systems.
- Zero-shot Speaker Adaptation: Incorporates ECAPA-TDNN [15] based speaker embeddings for robust performance on unseen speakers
2. Two Novel Depthwise Decoding Strategies
To use RVQ codec in TTS, we should predict multiple depth levels of tokens at each acoustic frame. Thus, accurate and efficient decoding of RVQ tokens is critical for high-quality TTS synthesis. The core innovation lies in our two specialized approaches for handling RVQ token prediction:
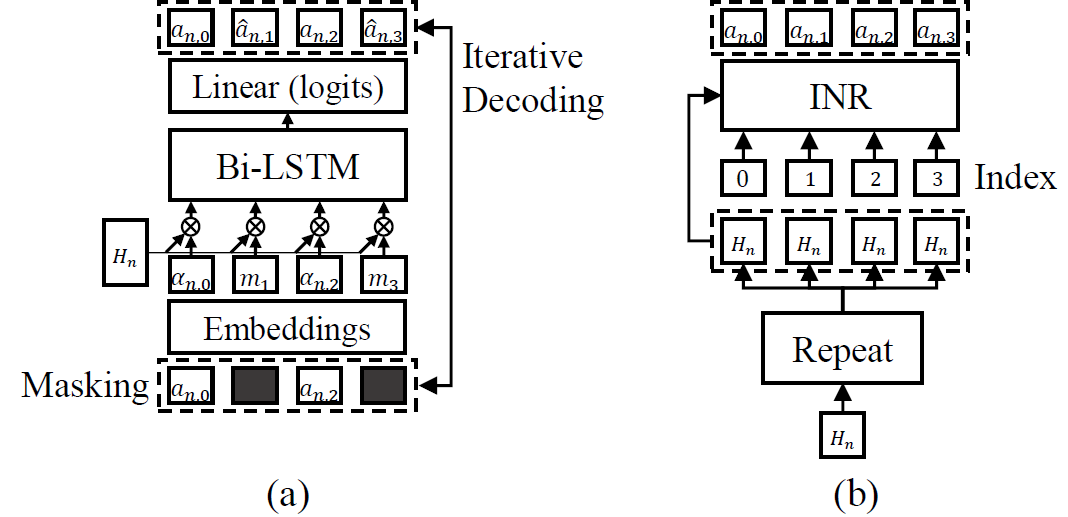
Figure 2. Architectures of MLM-based and INR-based decoding methods
2.1 Masked Language Model (MLM) Decoding
The MLM [13] decoding strategy repurposes the concept of masking from natural language processing. Unlike previous works [11] that mask tokens over the time axis, we focus solely on the depth dimension of RVQ. This strategy captures inter-level dependencies through iterative prediction, enhancing synthesis quality. At inference time, we apply a predetermined masking schedule with top-k sampling to maintain diversity
2.2. Implicit Neural Representation (INR) Decoding
In contrast to the iterative MLM strategy, the INR [14] -based approach leverages depth indices to predict all RVQ quantization levels in parallel. We modify the SegINR model [12], to take input the sequence of depth indices along with a repeated hidden representation of the last SpkMamba block. By treating the depth indices as continuous coordinates, the INR model generates the complete set of depthwise tokens in a single forward pass, eliminating the need for iterative refinement and explicit blank tokens.
3. Strategic Trade-offs for Flexible Deployment
Our framework offers deployment flexibility through a clear trade-off mechanism:
- MLM Approach: Prioritizes speech quality through iterative refinement
- INR Approach: Optimizes for speed and computational efficiency
- Configurable Selection: Enables system designers to choose based on specific hardware constraints and quality requirements
Experimental Validation
We conducted comprehensive evaluations on the LibriTTS dataset [16] under strict zero-shot conditions, comparing against state-of-the-art baselines including VALLE-X [20], VITS [19], the model proposed by Lee et al. (2024) [3], and Small-E [10]. Three configurations of the proposed streaming Mamba acoustic model (SMAM) were evaluated: SMAM with MLM decoding (SMAM+MLM), SMAM with INR decoding (SMAM+INR), and SMAM without advanced decoding strategies (SMAM+noMLM). The SMAM+noMLM, utilized for the ablation study, employs a single-step decoding process without any masking during both the training and inference phases.
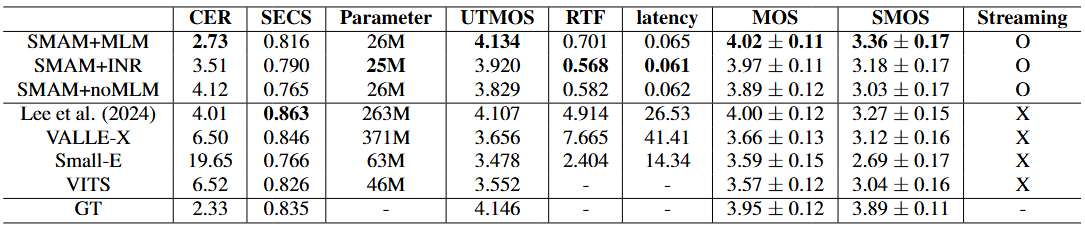
Table 1. Comparison of Experimental Results
1. Objective Performance:
- Superior Intelligibility: Our SMAM+MLM achieved a character error rate (CER, using Whisper large model [17]) of 2.73%,
outperforming all baselines despite having significantly fewer parameters (26M vs. 46M-371M).
- Better Speaker Similarity: Although the proposed models did not surpass other baselines speaker embedding cosine
similarity (SECS, using Resemblyzer) scores close to ground truth, demonstrating effective speaker preservation.
- High Perceptual Quality: UTMOS [18] score of 4.134(SMAM+MLM), indicating excellent perceived naturalness
2. Computational Efficiency on CPU
- Preeminent Real-time Performance: Real-time factor (RTF) of 0.701 (SMAM+MLM) and 0.568 (SMAM+INR) compared to
2.404-7.665 for non-streaming baselines.
- Remarkable Low Latency: By supporting streaming decoder, out models maintain latencies below 0.07 second for first token
generation versus 14+ seconds for baseline models.
- Objective results highlight a clear trade-off as mentioned before: while the SMAM+MLM offered the highest synthesis
quality, SMAM+INR provided advantages in computational speed and model compactness.
3. Subjective Evaluation
- Better perceptual quality: mean opinion score (MOS) of 4.02 for SMAM+MLM, surpassing larger baseline models.
- Outstanding Speaker Similarity: similarity MOS (SMOS) of 3.36, indicating superior perceptual speaker matching.
4. Ablation Study Insights
Our ablation study comparing SMAM+MLM with SMAM+noMLM (single-step decoding without masking) revealed the critical importance of depthwise iterative refinement. The removal of MLM resulted in significant degradation across all quality metrics, confirming that capturing inter-level dependencies is essential for high-fidelity synthesis.
Conclusion
In this post, we introduced a zero-shot streaming TTS system based on the Mamba framework (SMAM), incorporating two novel depthwise decoding strategies for RVQ: Masked Language Model (MLM) and Implicit Neural Representation (INR). Our experiments demonstrated that SMAM achieves high computational efficiency while maintaining superior performance compared to larger baseline models, with a clear trade-off between quality (MLM) and speed (INR). These findings enable flexible deployment across diverse hardware constraints, making SMAM a strong candidate for real-time streaming TTS on CPU.
Audio Samples
References
[1]E. Kharitonov, D. Vincent, Z. Borsos, R. Marinier, S. Girgin, O. Pietquin, M. Sharifi, M. Tagliasacchi, and N. Zeghidour, “Speak, read and prompt: High-fidelity text-to-speech with minimal supervision,” Transactions of the Association for Computational Linguistics, vol. 11, pp. 1703–1718, 2023.
[2] C. Wang, S. Chen, Y. Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y. Liu, H. Wang, J. Li et al., “Neural codec language models are zero-shot text to speech synthesizers,” arXiv preprint arXiv:2301.02111, 2023.
[3] J. Y. Lee, M. Jeong, M. Kim, J.-H. Lee, H.-Y. Cho, and N. S. Kim, “High fidelity text-to-speech via discrete tokens using token transducer and group masked language model,” in Interspeech 2024, 2024, pp. 3445–3449.
[4] M. Łajszczak, G. C´ambara, Y. Li, F. Beyhan, A. van Korlaar, F. Yang, A. Joly, ´Alvaro Mart´ın-Cortinas, A. Abbas, A. Michalski, A. Moinet, S. Karlapati, E. Muszy´nska, H. Guo, B. Putrycz, S. L. Gambino, K. Yoo, E. Sokolova, and T. Drugman, “Basetts: Lessons from building a billion-parameter text-to-speech model on 100k hours of data,” 2024. [Online]. Available: https://arxiv.org/abs/2402.08093
[5] A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” 2024. [Online]. Available: https://arxiv.org/abs/2312.00752
[6] D. Yang, S. Liu, R. Huang, J. Tian, C. Weng, and Y. Zou, “Hifi-codec: Group-residual vector quantization for high fidelity audio codec,” arXiv preprint arXiv:2305.02765, 2023.
[7] N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 495–507, 2021.
[8] A. D´efossez, J. Copet, G. Synnaeve, and Y. Adi, “High fidelity neural audio compression,” Transactions on Machine Learning Research, 2023, featured Certification, Reproducibility Certification.
[9] Z. Ye, P. Sun, J. Lei, H. Lin, X. Tan, Z. Dai, Q. Kong, J. Chen, J. Pan, Q. Liu, Y. Guo, and W. Xue, “Codec does matter: Exploring the semantic shortcoming of codec for audio language model,” arXiv preprint arXiv:2408.17175, 2024.
[10] T. Lemerle, N. Obin, and A. Roebel, “Small-e: Small language model with linear attention for efficient speech synthesis,” in Interspeech 2024, 2024, pp. 3420–3424.
[11] M. Jeong, M. Kim, J. Y. Lee, and N. S. Kim, “Efficient parallel audio generation using group masked language modeling,” arXiv preprint arXiv:2401.01099, 2024.
[12] M. Kim, M. Jeong, J. Y. Lee, and N. S. Kim, “Seginr: Segment-wise implicit neural representation for sequence alignment in neural text-to-speech,” IEEE Signal Processing Letters, vol. 32, pp.646–650, 2025.
[13] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT:Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), J. Burstein, C. Doran, and T. Solorio, Eds. Minneapolis, Minnesota: Association for Computational Linguistics, Jun. 2019, pp. 4171–4186. [Online]. Available: https://aclanthology.org/N19-1423/
[14] V. Sitzmann, J. Martel, A. Bergman, D. Lindell, and G. Wetzstein, “Implicit neural representations with periodic activation functions,” in Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 7462–7473. [Online]. Available: https://proceedings.neurips.cc/paper files/ paper/2020/file/53c04118df112c13a8c34b38343b9c10-Paper.pdf
[15] B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification,” in Proc. Interspeech 2020, 2020, pp. 3830–3834.
[16] H. Zen, V. Dang, R. Clark, Y. Zhang, R. J. Weiss, Y. Jia, Z. Chen, and Y. Wu, “Libritts: A corpus derived from librispeech for text-to-speech,” Interspeech 2019, 2019.
[17] A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” in International Conference on Machine Learning. PMLR, 2023, pp. 28 492–28 518.
[18] T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “Utmos: Utokyo-sarulab system for voicemos challenge 2022,” in Interspeech 2022, 2022, pp. 4521–4525.
[19] J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” in International Conference on Machine Learning. PMLR, 2021, pp. 5530–5540.
[20] Z. Zhang, L. Zhou, C. Wang, S. Chen, Y. Wu, S. Liu, Z. Chen, Y. Liu, H. Wang, J. Li et al., “Speak foreign languages with your own voice: Cross-lingual neural codec language modeling,” arXiv preprint arXiv:2303.03926, 2023.



