AI
[INTERSPEECH 2025 Series #1] Beyond Hard Sharing: Efficient Multi-Task Speech-to-Text Modeling with Supervised Mixture of Experts
|
Interspeech is one of the premier international conferences dedicated to advancing and disseminating research in the field of speech science and technology. It serves as a global platform where researchers, engineers, and industry professionals can share cutting-edge innovations, methodologies, and applications related to speech communication. In this blog series, we are introducing some of our research papers at INTERSPEECH 2025 and here is a list of them. #1. Beyond Hard Sharing: Efficient Multi-Task Speech-to-Text Modeling with Supervised Mixture of Experts (AI Center-Seoul) #2. Significance of Time-Frequency Preprocessing for Automatic Ultrasonic Vocalization Classification in Autism Spectrum Disorder Model Detection(Samsung R&D Institute Poland) #3. Adversarial Deep Metric Learning for Cross-Modal Audio-Text Alignment in Open-Vocabulary Keyword Spotting (AI Center-Seoul) #4. Low Complex IIR Adaptive Hear-Through Ambient Filtering for Overcoming Practical Constraints in Earbuds (Samsung R&D Institute India-Bangalore) #5. SPCODEC: Split and Prediction for Neural Speech Codec (Samsung R&D Institute China-Beijing) #6. Efficient Streaming TTS Acoustic Model with Depthwise RVQ Decoding Strategies in a Mamba Framework (AI Center-Seoul) #7. Robust Unsupervised Adaptation of a Speech Recogniser Using Entropy Minimisation and Speaker Codes (AI Center-Cambridge) #8. A Lightweight Hybrid Dual Channel Speech Enhancement System under Low-SNR Conditions (Samsung R&D Institute China-Nanjing) #9. Fairness in Dysarthric Speech Synthesis: Understanding Intrinsic Bias in Dysarthric Speech Cloning using F5-TTS (Samsung R&D Institute India-Bangalore) |
Introduction
Speech-to-text (STT) models are usually trained on wideband (WB) audio, but narrowband (NB) audio remains important for mobile and telephony use cases. Training separate models for WB/NB inputs and different tasks like ASR and speech translation (ST) is resource-intensive, especially on mobile devices. Multi-task learning (MTL) can help by sharing a single model across tasks, but traditional hard-parameter sharing often leads to task interference.
To address this, we propose Supervised Mixture of Experts (S-MoE) - a modular approach inspired by MoE but without the need for complex gating functions. Instead, it uses guiding tokens to route each task to its designated expert network, making the model efficient and scalable. (see Figure 1)
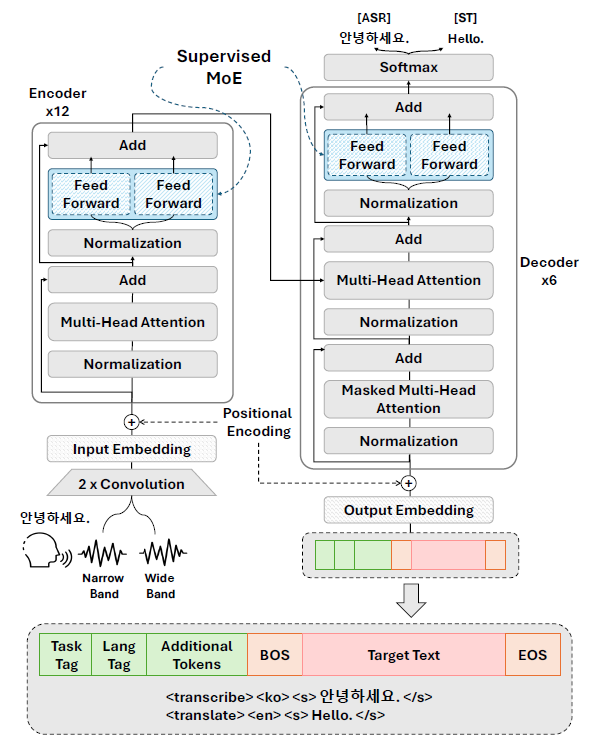
Figure 1. Two S-MoE layer embedded within a STT model. The S-MoE in the encoder directs inputs to expert networks based on the speech bandwidth (NB or WB), while the S-MoE in the decoder routes inputs according to the task (ASR or ST)
Key contributions:
Approach
We propose the Supervised Mixture of Experts (S-MoE) architecture, which modifies the traditional Mixture of Experts (MoE) by replacing the learnable gating network with a predefined gating function. This simplifies training by eliminating the need for gating network learning.
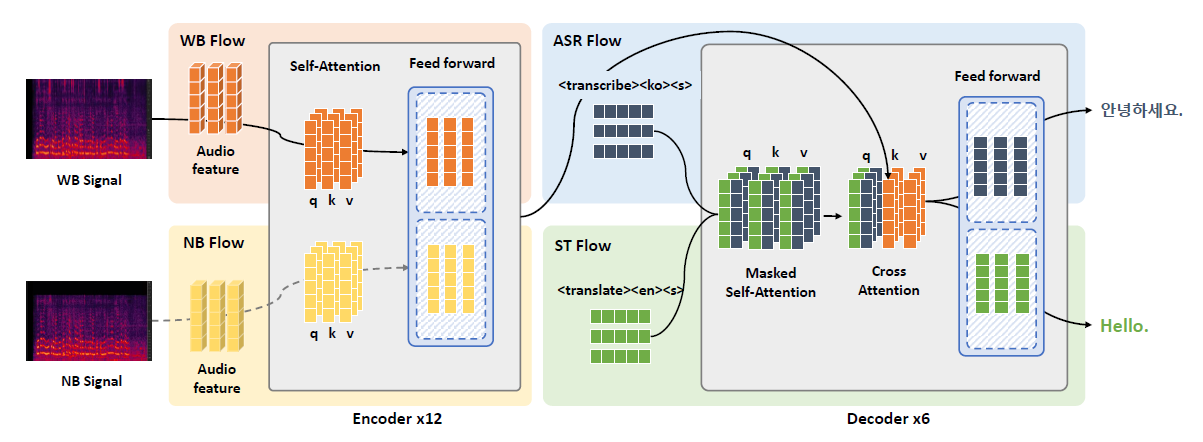
Figure 2. Embedding flow of S-MoE Transformer. During training/inference, a single feedforward block within the encoder is chosen, whereas both feedforward blocks within the decoder are utilized
Embedding Flow: Special tokens indicating the task (
Experimental setup
Datasets: Training uses 40,000 hours of Korean speech from the AIHub corpus. ASR targets are transcripts; ST targets are either provided English translations or generated via an internal machine translation model. Both narrowband (NB, 8 kHz) and wideband (WB, 16 kHz) audio variants are used. NB data is created by downsampling and codec-based conversions applied to 15% of the training data for fine-tuning.
Evaluation uses two in-house test sets (1,000 daily conversation samples each) and the public Fleurs dataset, with NB/WB variants generated similarly to training.
Model: Transformer-based sequence-to-sequence with 12-layer encoder and 6-layer decoder. We use sinusoidal positional embeddings, GLU activations, 8 attention heads, FFN dimension 2048, embedding size 512, and 0.15 dropout. Input features are 80-dim log Mel filterbanks extracted from 16 kHz resampled audio. Tokenization uses byte-level byte-pair encoding (BBPE) with 40,000 vocab size.
Training runs for 10 epochs with batch size 3,200, learning rate decayed by cosine annealing.
Encoder-Decoder S-MoE model is initialized from Decoder S-MoE and fine-tuned for 5 epochs with the NB/WB fine-tuning subset.
Metrics: ASR performance is evaluated by Word Error Rate (WER). ST quality is measured using BLEU score with the sacrebleu library.
Experimetal results
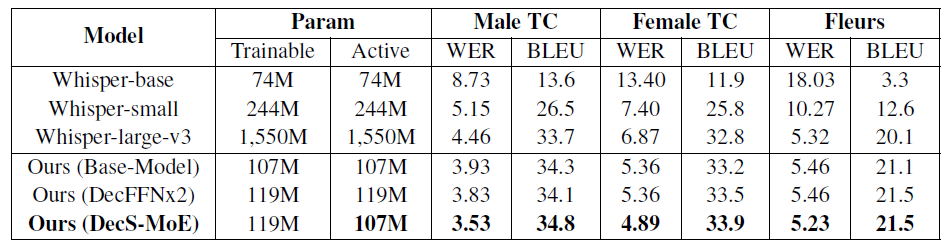
Table 1. Impact of Decoder S-MoE on ASR/ST
Decoder S-MoE (DecS-MoE) consistently outperformed the baseline, showing:
→ Average 8.06% relative improvement in WER and 1.77% increase in BLEU across test sets.
→ Better results than DecFFNx2, proving that task-specific experts outperform just increasing model size.
→ Outperformed Whisper-large (much bigger model) with 21.98% relative WER reduction and 3.99% BLEU improvement, despite having only 1/10th of the parameters.
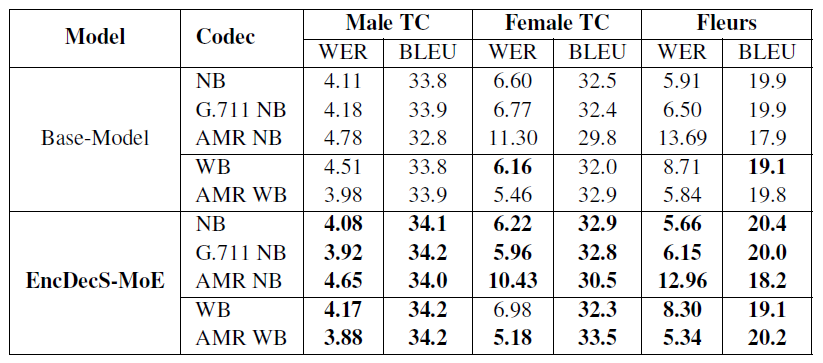
Table 2. Impact of Encoder-Decoder S-MoE on ASR/ST
Fine-tuned on mixed bandwidth data, EncDecS-MoE achieved:
→ 6.35% relative improvement in WER and 1.63% increase in BLEU on NB data.
→ 2.39% relative improvement in WER and 1.15% increase in BLEU on WB data.
→ Results show separate FFNs in the encoder effectively address challenges of mixed bandwidth data without increasing inference cost.
Extended S-MoE to both encoder and decoder to handle mixed bandwidth (NB/WB) inputs and multitask learning. Encoder uses two experts for NB and WB audio; decoder uses two for ASR and ST, totaling four experts. Although the total parameter count is larger, only relevant experts are activated during inference, keeping active parameters equal to the baseline.
Conclusion
This paper proposes the S-MoE architecture to reduce task interference in multi-task learning for speech-to-text applications. By replacing dynamic gating with guiding tokens, S-MoE improves training efficiency and performance while handling ASR and speech translation with mixed-bandwidth inputs. This makes it well-suited for resource-limited environments. Future work aims to extend S-MoE to more speech tasks and multilingual support for broader real-world use.
References
[1] M. Crawshaw, “Multi-task learning with deep neural networks: A survey,” arXiv preprint arXiv:2009.09796, 2020.
[2] S. Ruder, “An overview of multi-task learning in deep neural net-works,” arXiv preprint arXiv:1706.05098, 2017.
[3] Y. Zhang and Q. Yang, “A survey on multi-task learning ieee transactions on knowledge and data engineering,” 2021.
[4] S. Gupta, S. Mukherjee, K. Subudhi, E. Gonzalez, D. Jose, A. H. Awadallah, and J. Gao, “Sparsely activated mixture-of-experts are robust multi-task learners,” arXiv preprint arXiv:2204.07689, 2022.
[5] N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” arXiv preprint arXiv:1701.06538, 2017.
[6] P. J. Moreno and R. M. Stern, “Sources of degradation of speech recognition in the telephone network,” in Proceedings of ICASSP’94. IEEE International Conference on Acoustics, Speech and Signal Processing, vol. 1. IEEE, 1994, pp. I–109.
[7] M. L. Seltzer and A. Acero, “Training wideband acoustic mod-els using mixed-bandwidth training data for speech recognition,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 15, no. 1, pp. 235–245, 2006.
[8] (2022) Multilingual translation and translation reading data. [Online]. Available: https://aihub.or.kr, dataSetSn=71524
[9] (2021) Korean-english mixed recognition data. [Online]. Available: https://aihub.or.kr, dataSetSn=71260
[10] (2018) Korean voice data. [Online]. [Online]. Available: https://aihub.or.kr, data&dataSetSn=123
[11] (2021) Broadcast content dialogue voice recognition data. [Online]. Available: https://aihub.or.kr, dataSetSn=463
[12] (2022) Korean language college lecture data. [Online]. [Online]. Available: https://aihub.or.kr, dataSetSn=71627
[13] (2020) Conference voice data. [Online]. [Online]. Available: https://aihub.or.kr, dataSetSn=132
[14] (2022) Broadcasting contents korean-european interpretation and translation voice data. [Online]. [Online]. Available: https://aihub.or.kr, dataSetSn=71384
[15] (2022) Broadcasting contents korean-english interpretation and translation voice data. [Online]. [Online]. Available: https://aihub.or.kr, dataSetSn=71379
[16] (2021) Conference voice recognition data by major area. [Online]. [Online]. Available: https://aihub.or.kr, dataSetSn=464
[17] (2021) Noise environment voice recognition data. [Online]. [Online]. Available: https://aihub.or.kr, dataSetSn=568
[18] (2022) News script and anchor voice data. [Online]. [Online]. Available: https://aihub.or.kr, dataSetSn=71557
[19] B. Bessette, R. Salami, R. Lefebvre, M. Jelinek, J. Rotola-Pukkila, J. Vainio, H. Mikkola, and K. Jarvinen, “The adaptive multirate wideband speech codec (amr-wb),” IEEE transactions on speech and audio processing, vol. 10, no. 8, pp. 620–636, 2002.
[20] C. Recommendation, “Pulse code modulation (pcm) of voice frequencies,” in ITU, 1988.
[21] A. Conneau, M. Ma, S. Khanuja, Y. Zhang, V. Axelrod, S. Dalmia, J. Riesa, C. Rivera, and A. Bapna, “Fleurs: Few-shot learning evaluation of universal representations of speech,” in 2022 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2023, pp. 798–805.
[22] A. Vaswani, “Attention is all you need,” Advances in Neural Information Processing Systems, 2017.
[23] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318.
[24] A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” in International conference on machine learning. PMLR, 2023, pp. 28 492–28 518.



