AI
[INTERSPEECH 2025 Series #8] A Lightweight Hybrid Dual Channel Speech Enhancement System under Low-SNR Conditions
|
Interspeech is one of the premier international conferences dedicated to advancing and disseminating research in the field of speech science and technology. It serves as a global platform where researchers, engineers, and industry professionals can share cutting-edge innovations, methodologies, and applications related to speech communication. In this blog series, we are introducing some of our research papers at INTERSPEECH 2025 and here is a list of them. #5. SPCODEC: Split and Prediction for Neural Speech Codec (Samsung R&D Institute China-Beijing) #8. A Lightweight Hybrid Dual Channel Speech Enhancement System under Low-SNR Conditions (Samsung R&D Institute China-Nanjing) #9. Fairness in Dysarthric Speech Synthesis: Understanding Intrinsic Bias in Dysarthric Speech Cloning using F5-TTS (Samsung R&D Institute India-Bangalore) |
Introduction
Speech enhancement aims to extract desired speech signals degraded by noise and interference. It serves as a crucial frontend module in applications, including human-machine interaction, including human-machine interaction, video conferencing, and hearing aids.With the rapid advancement of deep neural networks (DNNs), data driven speech enhancement systems have demonstrated remarkable performance, surpassing traditional rule-based signal processing methods.
In low-SNR conditions, speech enhancement techniques often fail to retain speech components. One approach to address this issue is the two-stage strategy. However, the high computational demands of neural networks make them unsuitable for deployment on edge devices for real-time applications.
DNN-based multi-channel speech enhancement approaches have made great progress in recent years, but the number of microphones required for these methods is often too large to enable practical deployment.
Recent works have focused on developing lightweight models that maintain competitive performance with reduced computational resources. For example, RNNoise, GTCRN, DPCRN. However, their speech enhancement performance in high noise level scenarios remains questionable.
Independent vector analysis (IVA) is a traditional blind source separation method, While DNN-based methods often outperform IVA, the latter remains effective in separating speech and noise even in low-SNR conditions
In this blog, we propose a lightweight hybrid dual-channel speech enhancement system that combines IVA with a modified dual-channel GTCRN to achieve effective speech enhancement in low-SNR conditions. IVA is employed as a coarse estimator to obtain preliminary separated speech and noise signals, subsequently, our modified GTCRN refines these estimates, effectively integrating both the original noisy mixture and the separated source information provided by IVA to further enhance speech quality.
Proposed Method
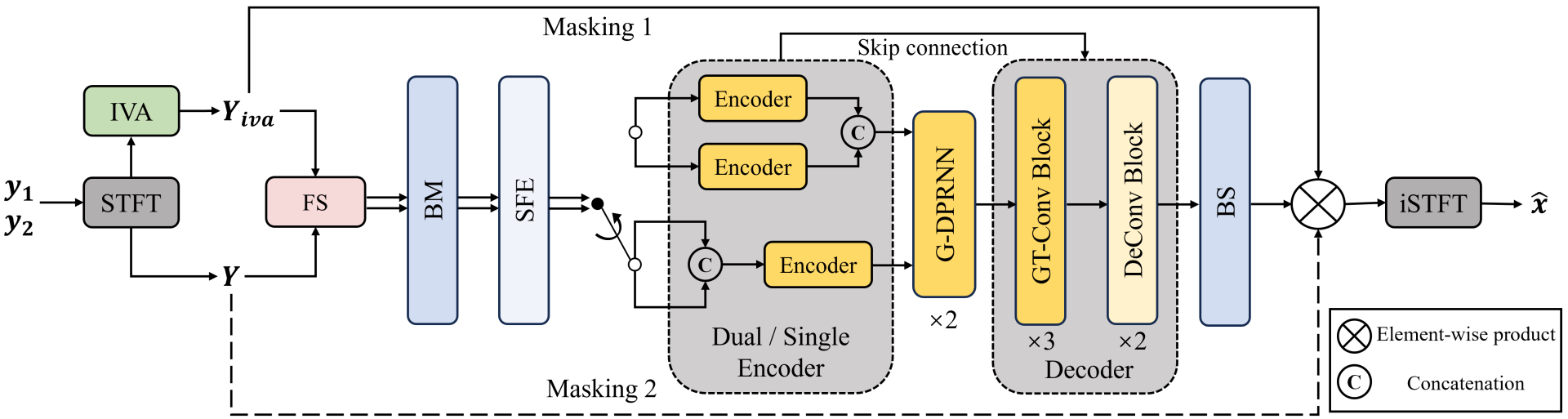
Figure 1. The framework of our proposed system
As depicted in Figure 1, our proposed system is built upon the GTCRN architecture. We introduce the dual-channel version of the model and incorporate several modifications to ensure the comprehensive utilization of diverse information. These modifications include feature selection, auxiliary information selection, masking approach selection, and the adoption of a dual encoder structure.
The system consists of several key components:
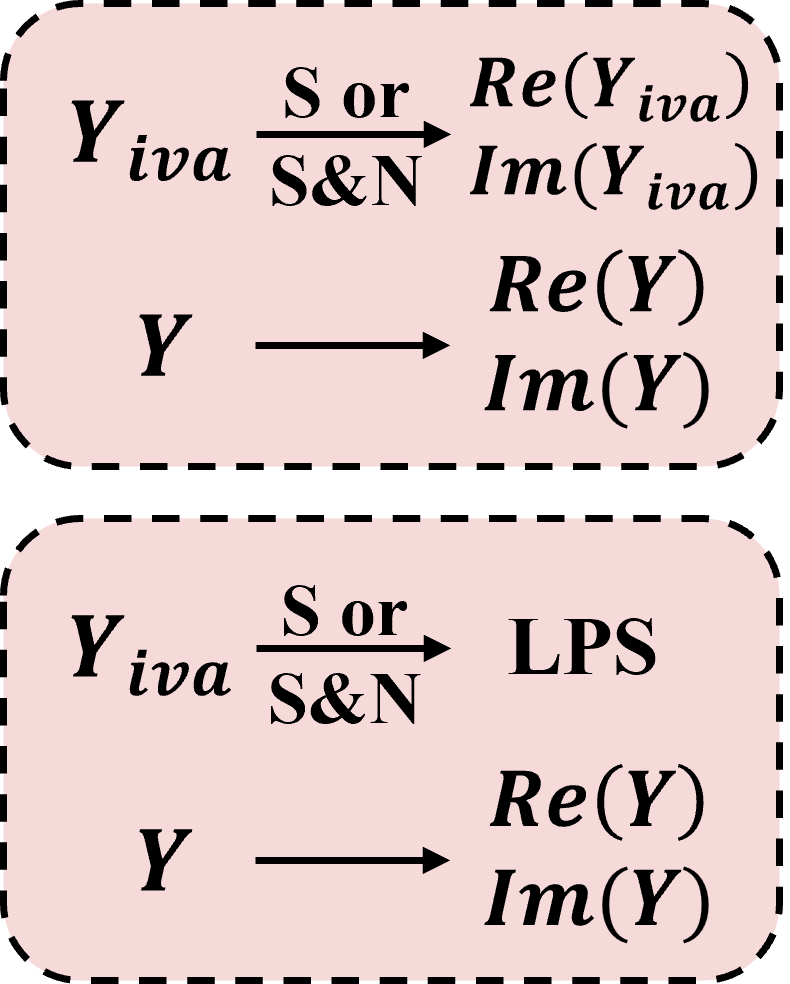
Figure 2. Feature selection module
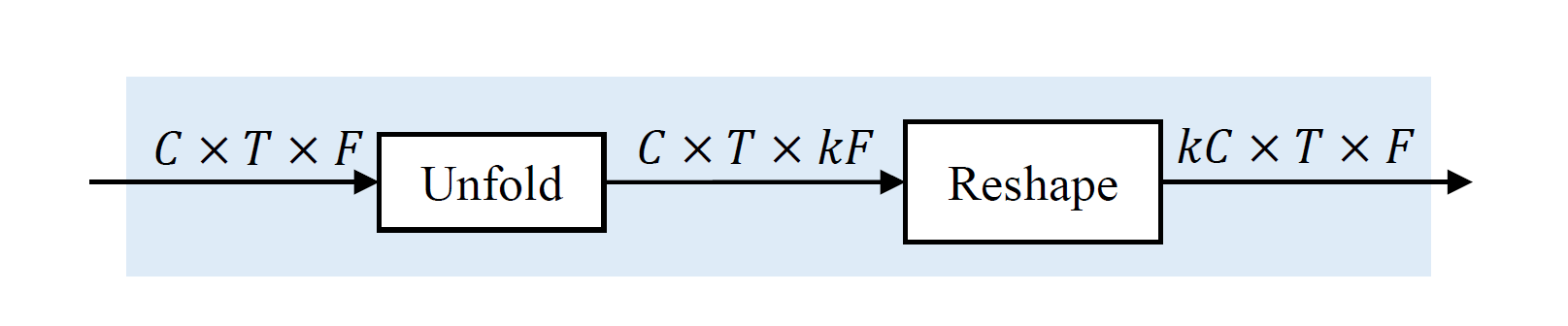
Figure 3. Subband feature extraction module
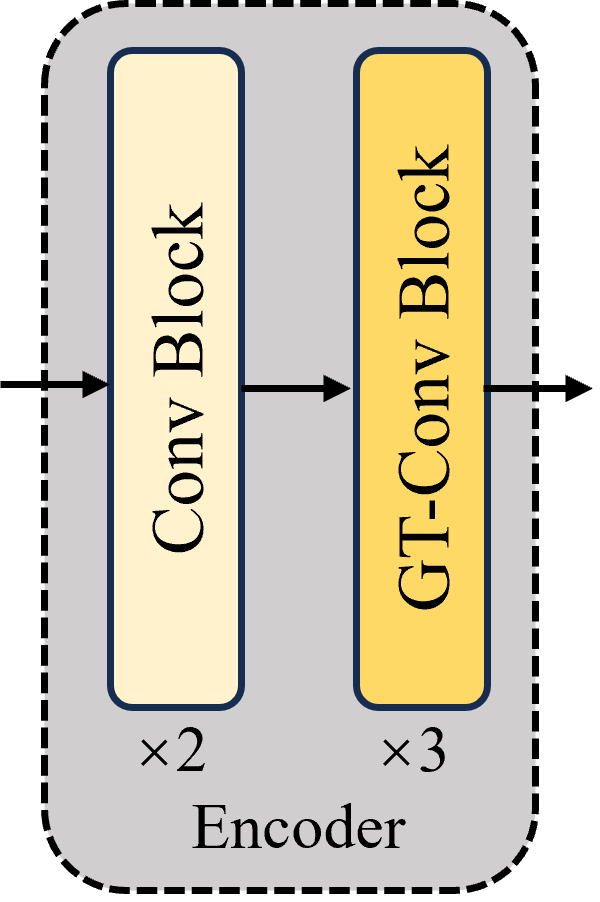
Figure 4. Encoder module
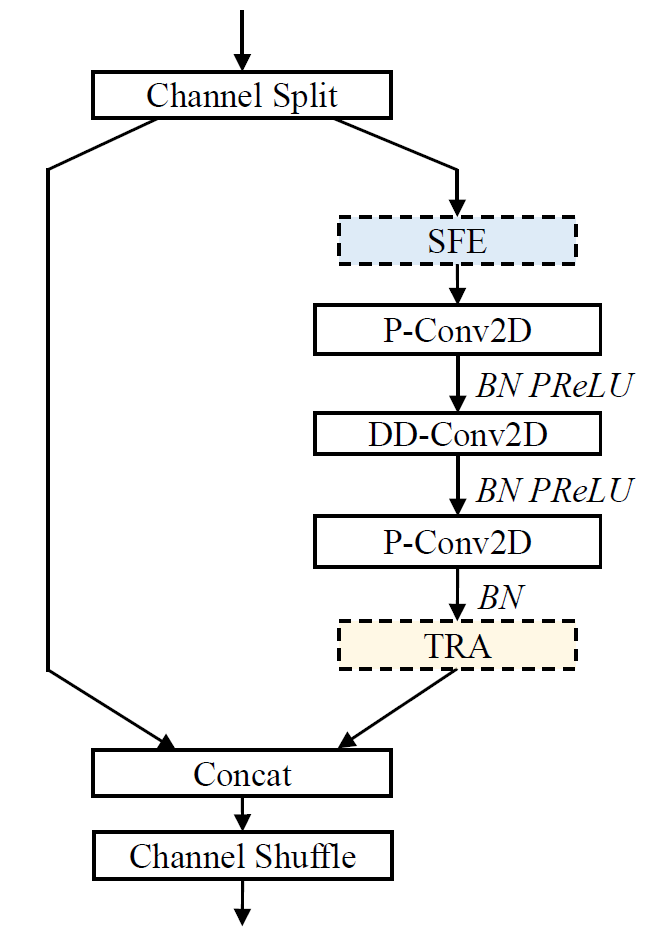
Figure 5. Grouped temporal convolution block
Loss Function: Our model is trained on the hybrid loss function, which consists of scale-invariant signal-to-noise ratio (SISNR) loss and complex compressed mean-squared error (ccMSE) loss.
Experiments
Dataset: We generate the simulated dataset with the image method ,with dual-channel RIRs based on a linear array with two microphones placed 4 cm apart. The room size ranges from 3m×3m×2.5m to 10m×10m×3 m, and the reverberation time (RT60) ranges from 0.1 s to 0.4 s. The distance from the source to the array is randomly selected from {0.5 m, 1 m, 2 m, 3m}, with the direction of arrival (DOA) difference between the target speech and interference noise being greater than 5 °. We convolve the speech dataset from the DNS-3 challenge with these dual-channel RIRs to generate the simulated speech signals. The early reflection (50 ms) of the first channel is preserved as the training target. For the noise signals, we select data from the DNS-3 and DCASE datasets. During training, the SNR ranges from −10 dB to 0 dB. The validation set maintains this range of SNR, with 500 noisy-clean pairs in each case. For the test set, we set three SNR levels: −12.5 dB,−7.5 dB, and −2.5 dB, each with 500 noisy-clean pairs. All utterances are sampled at 16 kHz.
Evaluation metrics:
The evaluation is conducted using the objective metrics, including perceptual evaluation of speech quality (PESQ) and short-time objective intelligibility (STOI). Additionally, DNN-based non-intrusive subjective metrics DNSMOS P.808 and DNSMOS P.835 are also employed.
Ablation study:
We conduct an ablation study on our modified GTCRN to evaluate the impact of various factors, including the use of speech and noise information from IVA, the type of feature, the type
of masking approach, and the adoption of the dual-encoder, as shown in Table 1.
As seen in IDs 1 and 2, IDs 3 and 5, and IDs 4 and 6. It is clear that Masking 2 (IDs 2, 5, 6) outperforms Masking 1 (IDs 1, 3, 4), which can be attributed to the coarse estimation and speech preservation provided by IVA.
A comparison between ID-1 and ID-3 highlights the effectiveness of the LPS feature, which improves all metrics, indicating that phase information is not as crucial.
Compared to ID-5, the inclusion of the noise information provided by IVA (ID-6) leads to substantial improvements in nearly all metrics, despite a slight degradation in SIG is observed. This is because the two separated signals allow for a more comprehensive capture of the noisy
mixture, while the speech channel focuses solely on the speech component.
Finally, the results for ID-7 exhibit noticeable declines across most metrics, despite a marginal improvement in STOI over ID-6. We attribute this to the computational limitations of our lightweight network, which restrict the ability to fully leverage the potential benefits of the dual-encoder framework.
Consequently, we select the best-performing method in the table (ID-6) for comparison with the baseline models.
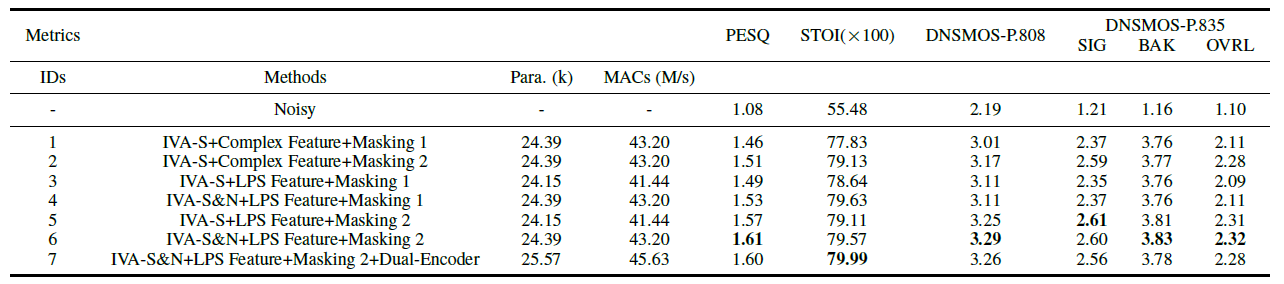
Table 1. Results of the ablation study on the simulated validation set. BOLD indicates the best score in each metric
Results comparison with baselines:
Four methods are selected as baselines: (a) Aux-IVA, (b)GTCRN, (c) DC-GTCRN, a dual-channel version of GTCRN,and (d) DC-GTCRN-L, a larger-scale version of DC-GTCRN.
The results of the simulated test set are presented in Table 2. By integrating Aux-IVA, our proposed method attains the highest scores, further validating the efficacy of auxiliary information and underscoring the superiority of our hybrid approach. The parameters and computational loads reported in the table include the Aux-IVA module, which contributes a negligible increase in parameters and only 0.20 MMACs per second per iteration.

Table 2. Results comparison with baselines on the simulated test set. BOLD indicates the best score in each metric
A set of typical audio samples is presented in Figure 6, clearly demonstrating that our proposed method excels in both speech preservation and noise suppression. Audio samples are available: https://github.com/Max1Wz/H-GTCRN.
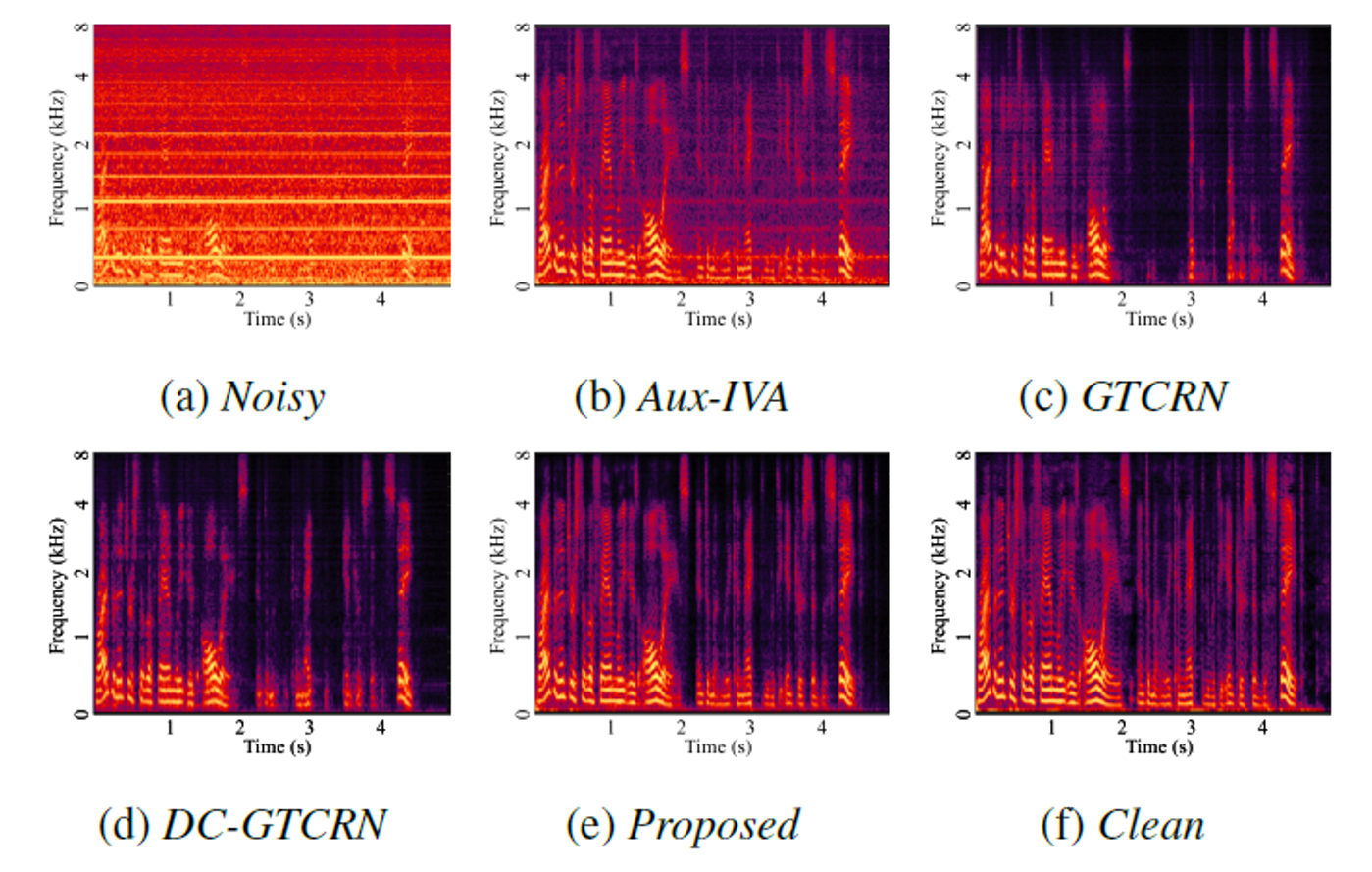
Figure 6. Typical spectrograms
Conclusion
We propose a hybrid dual-channel speech enhancement system designed for low-SNR conditions, integrating IVA and a modified GTCRN. Aux-IVA acts as a coarse estimator, providing auxiliary information, while the GTCRN further refines the speech quality. Through various architecture modifications, both the original and auxiliary information are fully leveraged. With only a minimal increase in parameters and computational complexity, the proposed system effectively enhances speech. Experimental results validate its effectiveness.
References
[1] K. Tan, X. Zhang, and D. Wang, “Real-time speech enhancement using an efficient convolutional recurrent network for dualmicrophone mobile phones in close-talk scenarios,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 5751–5755.
[2] Y. Li, F. Chen, Z. Sun, J. Ji,W. Jia, and Z.Wang, “A smart binaural hearing aid architecture leveraging a smartphone app with deeplearning speech enhancement,” IEEE Access, vol. 8, pp. 56 798–56 810, 2020.
[3] N. Modhave, Y. Karuna, and S. Tonde, “Design of matrix wiener filter for noise reduction and speech enhancement in hearing aids,” in 2016 IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT). IEEE, 2016, pp. 843–847.
[4] X. Hao, X. Su, Z. Wang, H. Zhang, and Batushiren, “Unetgan: A robust speech enhancement approach in time domain for extremely low signal-to-noise ratio condition,” in Interspeech 2019,2019, pp. 1786–1790.
[5] X. Hao, X. Su, S. Wen, Z. Wang, Y. Pan, F. Bao, and W. Chen,“Masking and inpainting: A two-stage speech enhancement approach for low snr and non-stationary noise,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6959–6963.
[6] Z. Hou, T. Lei, Q. Hu, Z. Cao, M. Tang, and J. Lu, “Snrprogressive model with harmonic compensation for low-snr speech enhancement,” IEEE Signal Processing Letters, 2024.
[7] X. Le, T. Lei, L. Chen, Y. Guo, C. He, C. Chen, X. Xia, H. Gao, Y. Xiao, P. Ding, S. Song, and J. Lu, “Harmonic enhancement using learnable comb filter for light-weight full-band speech enhancement model,” in Interspeech 2023, 2023, pp. 3894–3898.
[8] Z. Zhang, Y. Xu, M. Yu, S.-X. Zhang, L. Chen, and D. Yu, “Adlmvdr: All deep learning mvdr beamformer for target speech separation,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021,pp. 6089–6093.
[9] J.-M. Valin, “A hybrid dsp/deep learning approach to real-time full-band speech enhancement,” in 2018 IEEE 20th international workshop on multimedia signal processing (MMSP). IEEE, 2018, pp. 1–5.
[10] X. Rong, T. Sun, X. Zhang, Y. Hu, C. Zhu, and J. Lu, “Gtcrn: A speech enhancement model requiring ultralow computational resources,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 971–975.
[11] X. Le, H. Chen, K. Chen, and J. Lu, “DPCRN: Dual-Path Convolution Recurrent Network for Single Channel Speech Enhancement,” in Interspeech 2021, 2021, pp. 2811–2815.
[12] N. Ma, X. Zhang, H.-T. Zheng, and J. Sun, “Shufflenet v2: Practical guidelines for efficient cnn architecture design,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 116–131.
[13] F. Gao, L. Wu, L. Zhao, T. Qin, X. Cheng, and T.-Y. Liu, “Efficient sequence learning with group recurrent networks,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 2018, pp. 799–808.
[14] T. Kim, T. Eltoft, and T.-W. Lee, “Independent vector analysis: An extension of ica to multivariate components,” in International conference on independent component analysis and signal separation. Springer, 2006, pp. 165–172.
[15] T. Kim, H. T. Attias, S.-Y. Lee, and T.-W. Lee, “Blind source separation exploiting higher-order frequency dependencies,” IEEE transactions on audio, speech, and language processing, vol. 15, no. 1, pp. 70–79, 2006.
[16] H. Ruan, L. Liao, K. Chen, and J. Lu, “Speech extraction under extremely low snr conditions,” Applied Acoustics, vol. 224, p.110149, 2024.
[17] D. S. Williamson, Y. Wang, and D. Wang, “Complex ratio masking for monaural speech separation,” IEEE/ACM transactions on audio, speech, and language processing, vol. 24, no. 3, pp. 483–492, 2015.
[18] N. Ono, “Stable and fast update rules for independent vector analysis based on auxiliary function technique,” in 2011 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics(WASPAA). IEEE, 2011, pp. 189–192.
[19] T. Taniguchi, N. Ono, A. Kawamura, and S. Sagayama, “An auxiliary-function approach to online independent vector analysis for real-time blind source separation,” in 2014 4th Joint Workshop on Hands-free Speech Communication and Microphone Arrays(HSCMA). IEEE, 2014, pp. 107–111.
[20] M. Chidambaram, Y. Yang, D. Cer, S. Yuan, Y. Sung, B. Strope, and R. Kurzweil, “Learning cross-lingual sentence representations via a multi-task dual-encoder model,” in Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019). Association for Computational Linguistics, 2019, pp.250–259.
[21] Y. Luo, Z. Chen, and T. Yoshioka, “Dual-path rnn: efficient long sequence modeling for time-domain single-channel speech separation,”in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020,pp. 46–50.
[22] S. Braun and I. Tashev, “A consolidated view of loss functions for supervised deep learning-based speech enhancement,” in 2021 44th International Conference on Telecommunications and Signal Processing (TSP). IEEE, 2021, pp. 72–76.
[23] J. B. Allen and D. A. Berkley, “Image method for efficiently simulating small-room acoustics,” The Journal of the Acoustical Society of America, vol. 65, no. 4, pp. 943–950, 1979.
[24] C. K. Reddy, H. Dubey, V. Gopal, R. Cutler, S. Braun, H. Gamper, R. Aichner, and S. Srinivasan, “Icassp 2021 deep noise suppression challenge,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6623–6627.
[25] K. Dohi, K. Imoto, N. Harada, D. Niizumi, Y. Koizumi, T. Nishida, H. Purohit, T. Endo, M. Yamamoto, and Y. Kawaguchi, “Description and discussion on dcase 2022 challenge task 2: Unsupervised anomalous sound detection for machine condition monitoring applying domain generalization techniques,”arXiv preprint arXiv:2206.05876, 2022.
[26] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in ICLR 2015, 2015.
[27] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra,“Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,” in 2001 IEEE international conference on acoustics, speech, and signal processing. Proceedings (Cat. No. 01CH37221), vol. 2. IEEE, 2001, pp. 749–752.
[28] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “A shorttime objective intelligibility measure for time-frequency weighted noisy speech,” in 2010 IEEE international conference on acoustics, speech and signal processing. IEEE, 2010, pp. 4214–4217.
[29] C. K. Reddy, V. Gopal, and R. Cutler, “Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6493–6497.
[30] ——, “Dnsmos p. 835: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 886–890.




