AI
Robust neural codec language modeling with phoneme position prediction for zero-shot TTS
1. Introduction
Large language models (LLMs) have exhibited impressive in-context learning abilities [1]. Inspired by these successes, recent studies [2-5] have extended LLM applications to text-to-speech (TTS) systems by representing speech through discrete acoustic codes. These LLM-based models show remarkable progress in zero-shot TTS, successfully generating high-quality personalized speech for unseen speakers using a brief audio prompt. However, these models suffer from robustness issues, manifesting as word skipping, repetition, and mispronunciations in generated speech.
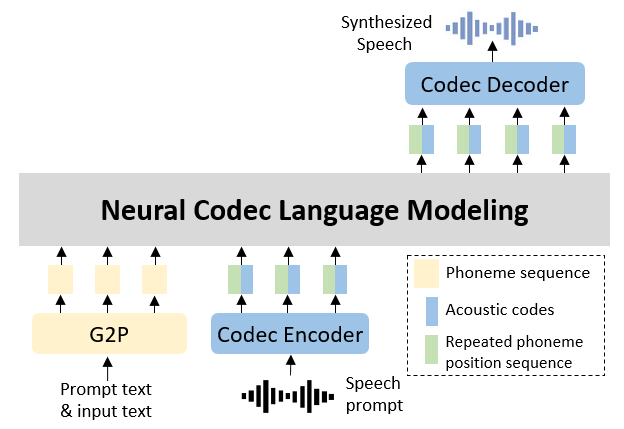
Figure 1. Overview of proposed method
To alleviate this challenge, we propose a simple yet effective method to enhance alignment between acoustic codes and phonemes. As illustrated in Figure 1, our approach synchronously predicts both acoustic codes and their corresponding phoneme positions within the input sequence. We then utilize this combined information as conditions for subsequent predictions. This approach enables each acoustic code to accurately attend to its target phoneme, and the enforced monotonic progression of positional indices ensures complete phoneme coverage within the attention framework.
2. Method
Notably, while implementing our method using VALL-E [2] as foundation, the design maintains compatibility with any decoder-only AR-TTS models.
Let the target text-speech pair be denoted as {x,y}, and the prompt text-speech pair from same speaker as { x̃ , ỹ }.
A pre-trained neural codec model encodes the speech y and ỹ into discrete acoustic codes, denoted as $c_T^N=Codec(y)$ and $c_{T'}^N$ , respectively.
Here, T and T' are the total number of time steps for each matrix, and N is the number of quantizers in the codec model. Concurrently, the text x and x̃ are converted into phoneme sequences
$p={p_1,p_2,…,p_L}$ and p̃ respectively. It should be noted that the text can also be represented as sequences of syllables or text tokens.
VALL-E is a decoder-only TTS system that regards zero-shot TTS as a codec language modeling task.
It incorporates two Transformers to hierarchically predict the acoustic codes.
One AR transformer takes p as input to sequentially predict the target acoustic codes of first quantizer $c_{1:T}^1$ and aims to maximize the following distribution:
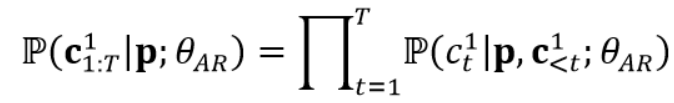
where $θ_{AR}$ is the trainable parameters of the AR model. In AR model training, there is no explicit acoustic prompt, instead, any prefix sequence $c_{< t}^1$ is treated as a prompt for the subsequent part $c_{≥t}^1$. To align with this training approach, during inference, p̃ is prepended to p to form the phoneme prompt and the enrollment acoustic codes from first quantizer $c̃^1$are used as acoustic prefix.
One non-autoregressive (NAR) transformer predicts the codes of the remaining quantizers. It simultaneously predicts all target acoustic codes $c_{1:T}^j$ from the j-th quantizer, using p, c ̃ , and all codes from previous quantizers $c_{1:T}^{ < j}$ as conditions and maximizes the following distribution:
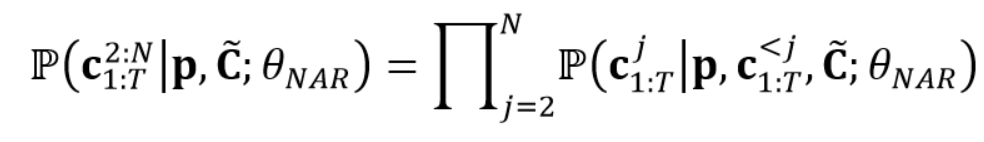
2.2 Enhancing alignment with phoneme position prediction
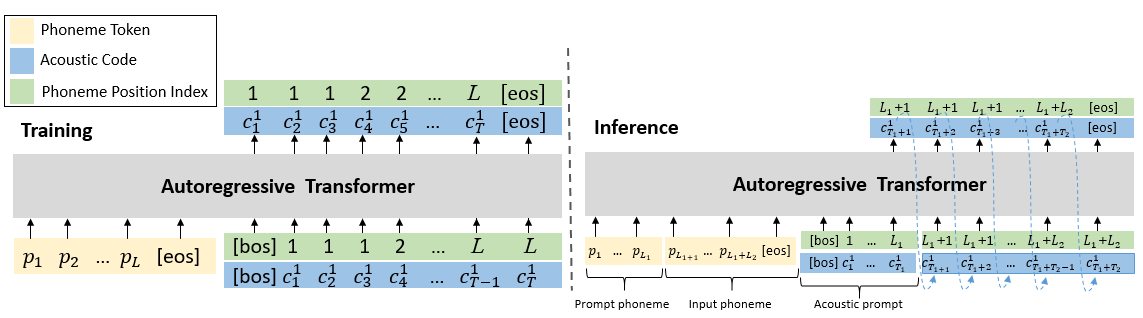
Figure 2. Training and inference process of our proposed AR model
In our proposed method, we primarily focus on enhancing the robustness of the AR transformer while leaving the NAR transformer unchanged. We propose incorporating phoneme position prediction into the AR model to strengthen the alignment between acoustic codes and phonemes. To achieve this, we first derive the alignment $d={d_1,…,d_L}$ between phonemes and acoustic codes, where $d_i$ represents the duration of i-th phoneme, and $∑_{i=1}^L d_i=T$. Subsequently, we construct the repeated phoneme position sequence pos by repeating each position i ∈ [1,L] $d_i$ times. As shown in the upper section of Figure 2, our model is then trained to synchronously predict both the acoustic codes $c_{1:T}^1$ and their corresponding phoneme positions $pos_{1:T}$ using teacher forcing, conditioned on the phoneme sequence p. The model is optimized by maximizing the following probability:
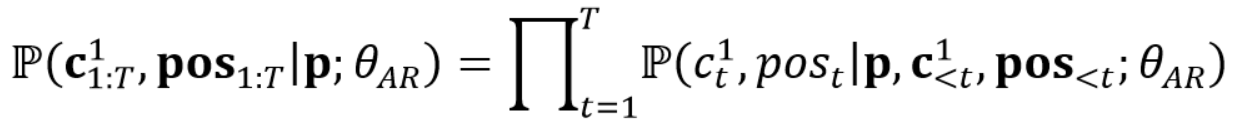
In practice, the model predicts $c_t^1$ and $pos_t$ with two separate heads, and their embeddings are summed up and fed to the model for the prediction of the next step.
2.3 Zero-shot TTS inference
We implement zero-shot TTS through prompting during inference, following VALL-E but differing in two key aspects to accommodate our AR model modifications, as depicted in the lower portion of Figure 2. First, given an enrollment speech sample from an unseen speaker as prompt, in addition to the phoneme sequence and acoustic code matrix, phoneme durations should also be included. Second, in the decoding process, we employ two distinct strategies corresponding to each prediction target. For phoneme positions, we use greedy decoding, while for acoustic codes, we apply nucleus sampling [6] with a predefined top-p value of 0.98.
3. Results
We evaluate the proposed method with several baselines on zero-shot TTS task.
3.1 Objective evaluations
We adopt Seed-TTS [7] test-zh for objective evaluation, and use Character Error Rate (CER) and Speaker Embedding Cosine Similarity (SECS) to evaluate the robustness and speaker similarity of synthesized samples respectively. The evaluation results are detailed in Table 1. For speaker similarity, all synthetic methods achieve comparable SECS scores that remain within 1% of the GT. In terms of robustness, our method exhibits substantial improvements across all subsets, especially reduces deletion (Del) and insertion (Ins) errors on hard subset.
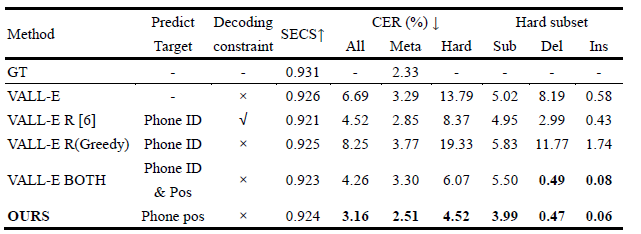
Table 1. Objective evaluation results for cross sentence zero-shot TTS on Seed-TTS test-zh testset
3.2 Subjective evaluations
For subjective evaluation, we conduct Comparative Mean Opinion Score (CMOS) and Speaker Similarity Mean Opinion Score (SMOS) tests to assess the naturalness and speaker similarity of the synthesized speech, respectively. The evaluation results, as detailed in Table 2, demonstrate that our system outperforms the other two VALL-E-based systems and validate the effectiveness of our approach.
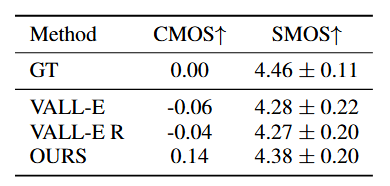
Table 2. Subjective evaluation results on cross sentence zero-shot TTS
3.3 Alignment analysis
To verify that the robustness improvement of our model is attributed to the enhanced alignment between phonemes and acoustic codes, we first visualized the attention weights of all attention heads across all layers and selected the head exhibiting the most distinct diagonal alignment patterns between phonemes and acoustic codes for detailed analysis on the Seed-TTS test-zh hard samples.
We quantified the occurrences of each alignment error, including phoneme skipping, repetition and one-to-many alignment, and presented the results in Table 3. We observed that our approach completely eliminates all three types of alignment errors, achieving zero error occurrences. This indicates that the proposed phoneme position prediction mechanism effectively addresses alignment issues, thereby enhancing the robustness and accuracy of the TTS system.
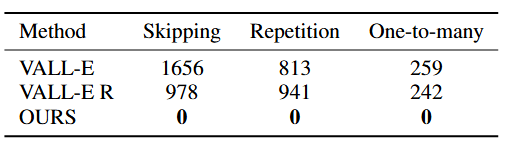
Table 3. Occurrence times of three alignment errors on Seed-TTS test-zh hard cases
4. Conclusion
In this paper, we introduce a robust zero-shot TTS model that integrates neural codec language modeling with phoneme position prediction. The position of phonemes corresponding to each acoustic code, along with the code itself, are predicted and then fed back into the model. This additional positional information guides the TTS model to accurately align the acoustic codes with the corresponding phonemes. Experimental results demonstrate that our system effectively eliminates alignment errors.
Link to the paper
References
[1] A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle et al., “The llama 3 herd of models,” arXiv preprint arXiv:2407.21783, 2024.
[2] C. Wang, S. Chen, Y. Wu, Z. Zhang, L. Zhou et al., “Neural codec language models are zero-shot text to speech synthesizers,” arXiv preprint arXiv:2301.02111, 2023.
[3] C. Du, Y. Guo, H. Wang et al., “VALL-T: Decoder-only generative transducer for robust and decoding controllable text-to-speech,” arXiv preprint arXiv:2401.14321, 2024.
[4] B. Han, L. Zhou, S. Liu, S. Chen et al., “VALL-E R: Robust and efficient zero-shot text-to-speech synthesis via monotonic alignment,” arXiv preprint arXiv:2406.07855, 2024.
[5] D. Xin, X. Tan, K. Shen et al., “RALL-E: Robust codec language modeling with chain-of-thought prompting for text-to-speech synthesis,” arXiv preprint arXiv:2404.03204, 2024.
[6] A. Holtzman, J. Buys, L. Du, M. Forbes, and Y. Choi, “The curious case of neural text degeneration,” in ICLR, 2020.
[7] P. Anastassiou, J. Chen, J. Chen, Y. Chen et al., “Seed-tts: A family of high-quality versatile speech generation models,” arXiv preprint arXiv:2406.02430, 2024.



