AI
[INTERSPEECH 2025 Series #3] Adversarial Deep Metric Learning for Cross-Modal Audio-Text Alignment in Open-Vocabulary Keyword Spotting
|
Interspeech is one of the premier international conferences dedicated to advancing and disseminating research in the field of speech science and technology. It serves as a global platform where researchers, engineers, and industry professionals can share cutting-edge innovations, methodologies, and applications related to speech communication. In this blog series, we are introducing some of our research papers at INTERSPEECH 2025 and here is a list of them. #3. Adversarial Deep Metric Learning for Cross-Modal Audio-Text Alignment in Open-Vocabulary Keyword Spotting (AI Center-Seoul) #4. Low Complex IIR Adaptive Hear-Through Ambient Filtering for Overcoming Practical Constraints in Earbuds (Samsung R&D Institute India-Bangalore) #5. SPCODEC: Split and Prediction for Neural Speech Codec (Samsung R&D Institute China-Beijing) #6. Efficient Streaming TTS Acoustic Model with Depthwise RVQ Decoding Strategies in a Mamba Framework (AI Center-Seoul) #7. Robust Unsupervised Adaptation of a Speech Recogniser Using Entropy Minimisation and Speaker Codes (AI Center-Cambridge) #8. A Lightweight Hybrid Dual Channel Speech Enhancement System under Low-SNR Conditions (Samsung R&D Institute China-Nanjing) #9. Fairness in Dysarthric Speech Synthesis: Understanding Intrinsic Bias in Dysarthric Speech Cloning using F5-TTS (Samsung R&D Institute India-Bangalore) |
Introduction
Keyword Spotting (KWS) refers to the task of detecting whether a target keyword or phrase appears in a spoken utterance. KWS systems are commonly deployed in voice assistants and low-power on-device ASR systems, where the goal is to detect specific trigger words such as "Hi Bixby" or "OK Google."
There are two broad types of KWS:
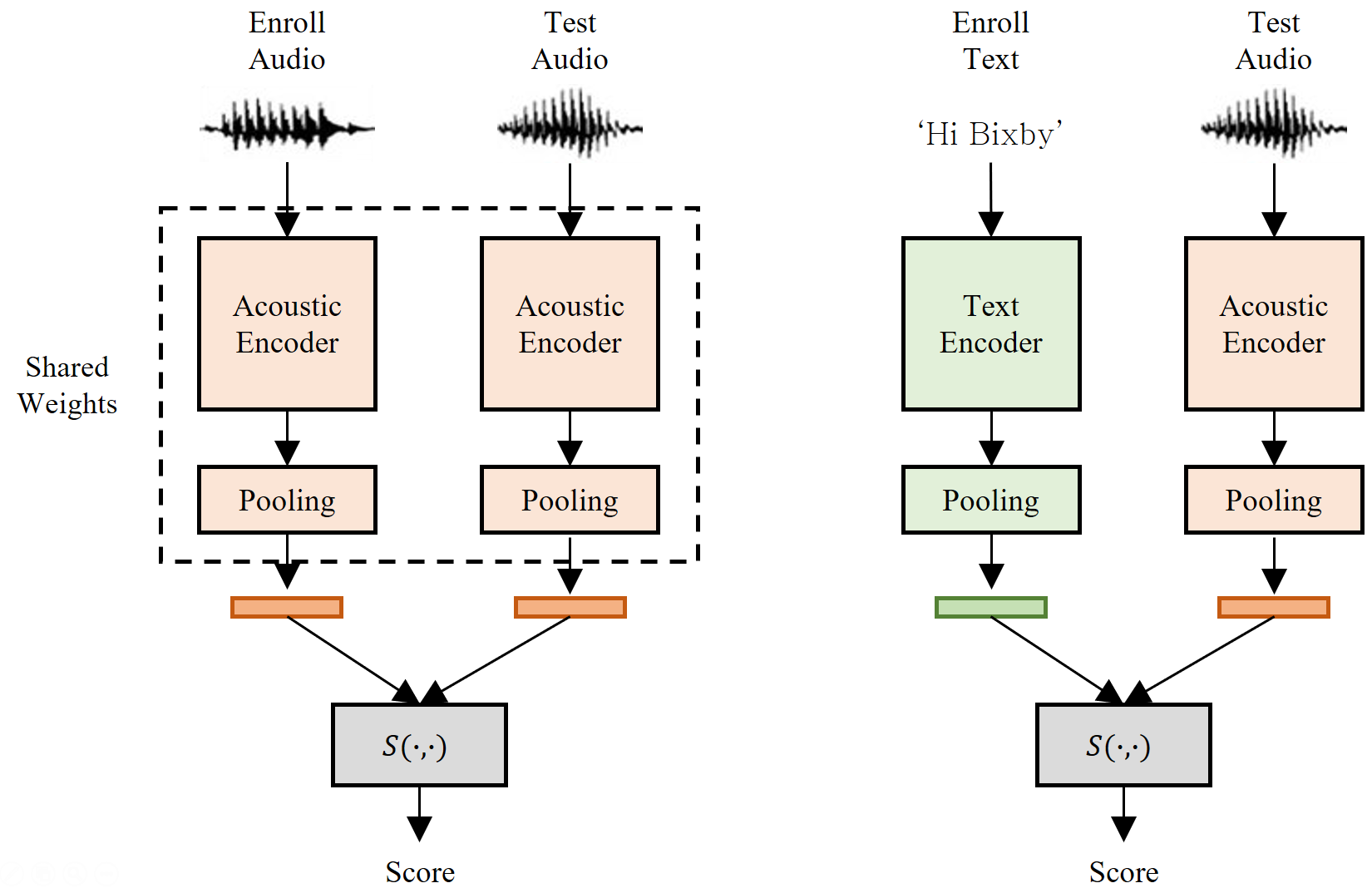
Figure 1. Two enrollment strategies in open-vocabulary KWS (audio-enrollment and text-enrollment)
Open-vocabulary KWS systems are further divided into two categories based on how users enroll keywords (see Figure 1):
This blog focuses on the text-enrolled open-vocabulary KWS problem, where a system must determine whether an utterance contains a keyword given only its text form. This requires comparing inputs from two inherently different modalities: audio signals and phoneme sequences.
Our approach tackles the alignment of these modalities using a unified embedding space trained with deep metric learning (DML) [15], supported by modality adversarial learning (MAL) and auxiliary classification objectives. In developing this system, we encountered several practical challenges worth sharing:
In the following sections, we describe the proposed model architecture, training objectives, and experimental results that demonstrate the effectiveness of our framework for text-enrolled open-vocabulary keyword spotting.
Proposed method
Architecture Overview
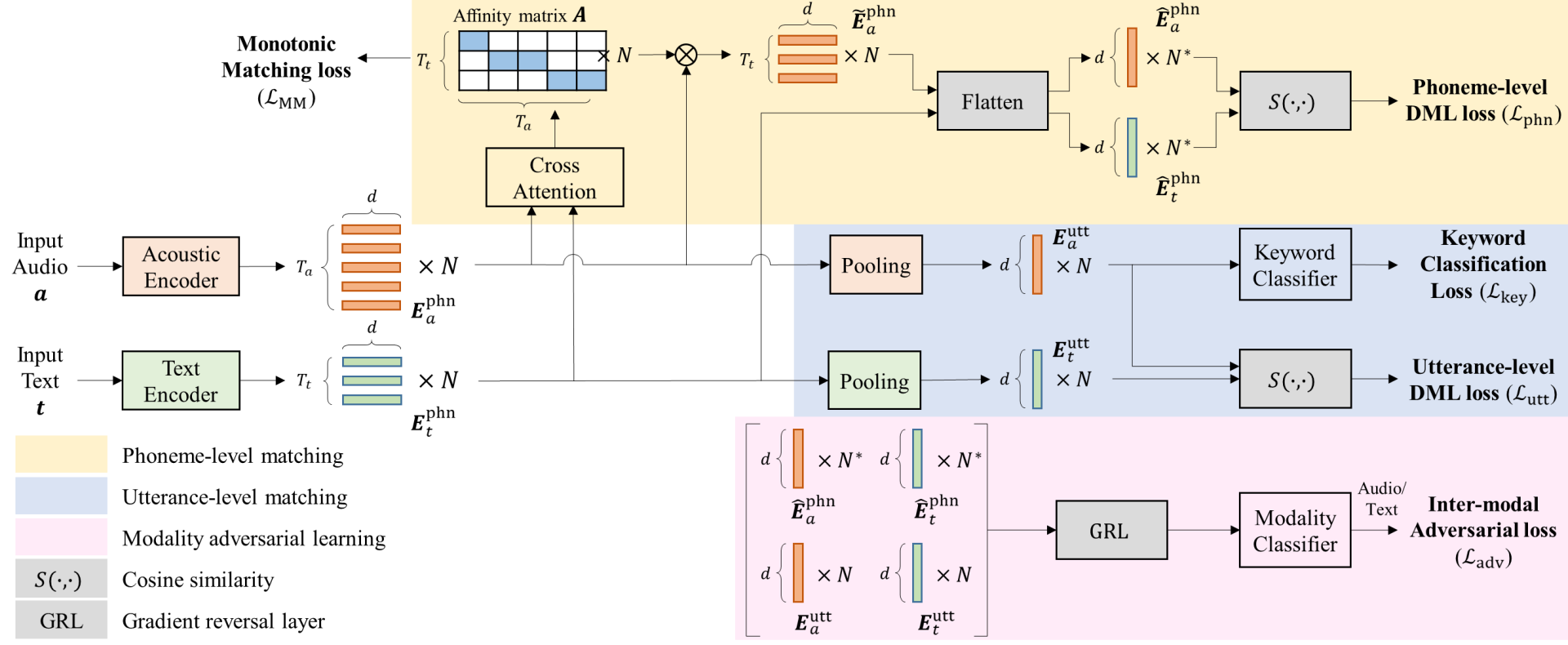
Figure 2. Overall architecture of Adversarial Deep Metric Learning (ADML)
The proposed system consists of two modality-specific encoders:
Each encoder outputs:
A cross-attention mechanism computes an affinity matrix between the acoustic and textual sequences, enabling direct alignment at the phoneme level.
Deep Metric Learning Losses
The AsyP loss treats the text phoneme embeddings as fixed proxies, and minimizes the distances between each audio frame and its most similar proxy. This structure allows the model to learn cross-modal alignment without requiring explicit alignment supervision.
To further improve convergence, the Adaptive Margin and Scale (AdaMS) [20] strategy is applied on top of the AsyP loss, dynamically adjusting the decision boundary during training.
Modality Adversarial Learning (MAL)
To reduce the representational gap between speech and text, the model incorporates modality adversarial learning (MAL) using a gradient reversal layer (GRL). This framework encourages both encoders to generate modality-invariant embeddings, which is essential for effective cross-modal similarity computation.
Concretely, a lightweight modality classifier (a two-layer MLP) is attached to both the utterance-level and phoneme-level embeddings. The classifier is trained to predict the modality (audio vs. text) of the input embedding. However, through the GRL, the gradient signals back-propagated to the encoders are reversed (multiplied by -1), forcing them to produce embeddings that confuse the classifier. This setup effectively acts as a minimax game: while the classifier improves at distinguishing modalities, the encoders improve at hiding modality-specific features.
Importantly, MAL is applied at two levels of granularity:
This multi-scale MAL formulation ensures that both local (phoneme-wise) and global (utterance-wise) representations are aligned across modalities, which is crucial for effective cross-modal matching in the KWS task.
One important implementation detail is that the adversarial loss is scaled down relative to the main embedding losses. Specifically, the loss weights for both phoneme- and utterance-level MAL are set to 0.1, so that the adversarial objective influences—but does not dominate—the training process. This weighting proved crucial for stabilizing training and preventing the modality classifier from overwhelming the encoders during early optimization.
Auxiliary Keyword Classification
To enhance intra-class compactness and inter-class separation in the utterance-level acoustic embedding space, the model employs SphereFace2 [21] as an auxiliary classification head.
Unlike traditional softmax-based loss functions that are designed for multi-class classification, SphereFace2 is formulated as a binary classification loss, which is more appropriate in the KWS setting where each example is labeled as “contains keyword” or “does not contain keyword.” This aligns well with text-enrolled open-vocabulary KWS, where each test involves a binary decision for a particular keyword query.
In ablation studies, SphereFace2 outperformed both triplet loss and additive angular margin softmax (AAM-Softmax), achieving the highest average precision on WSJ.
Experiments
1. Experimental setup
Training data. The model is trained on the King-ASR-066 dataset [27], which comprises 4.6k hours of English read speech. To improve generalization, we apply data augmentation with additive noise and reverberation using samples from MUSAN [30] and simulated room impulse responses (RIRs) [29].
Evaluation sets.
Acoustic features. We use 40-dimensional log Mel-filterbank coefficients extracted with a 25 ms window and 10 ms hop. Features are mean-normalized at the utterance level.
Optimization. All models are trained for 100 epochs using the AdamW optimizer. The learning rate starts at and is halved every 20 epochs. Training is done with a batch size of 500 utterances (250 keywords × 2 utterances) on 2 × A100 GPUs.
Loss weighting:
2. Results
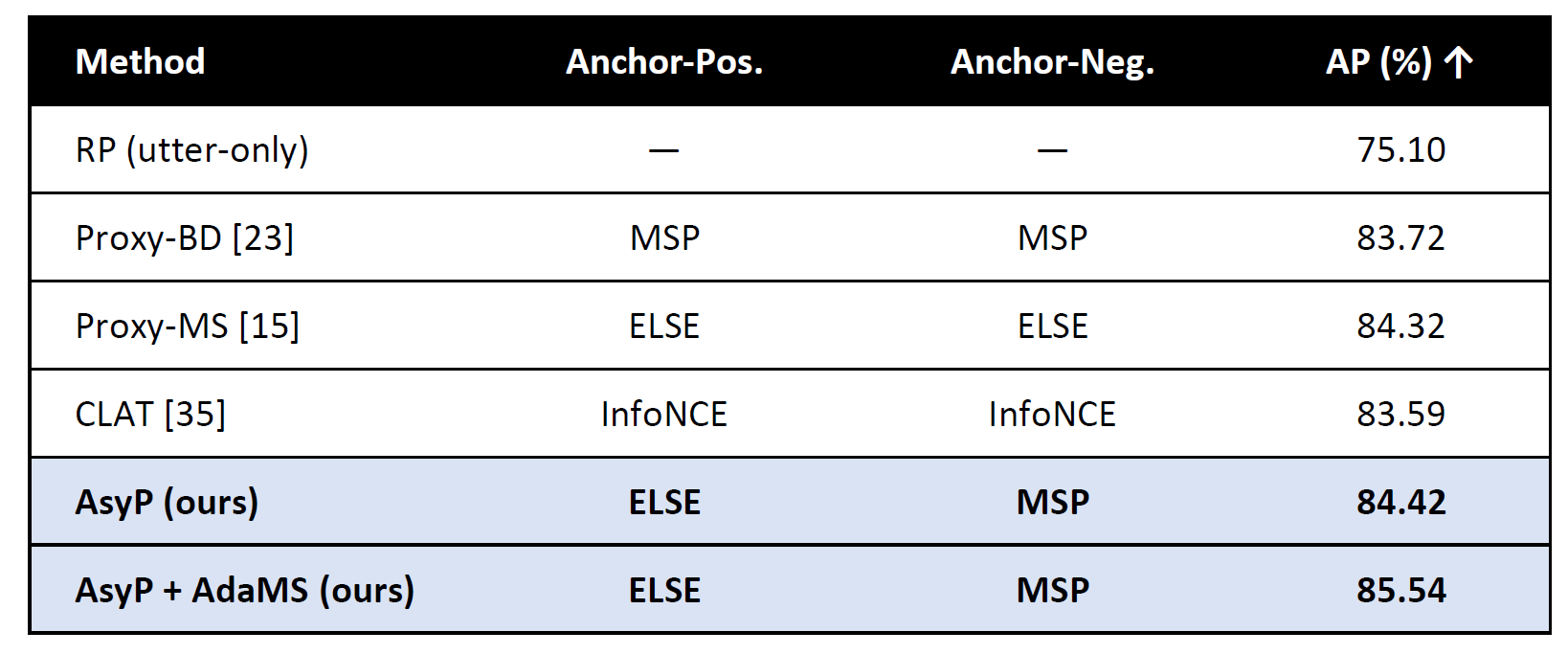
Table 1. Phoneme-level matching loss comparison (WSJ AP %)
→ AsyP with AdaMS yields the best phoneme alignment, adding +10 AP over the utterance only baseline.
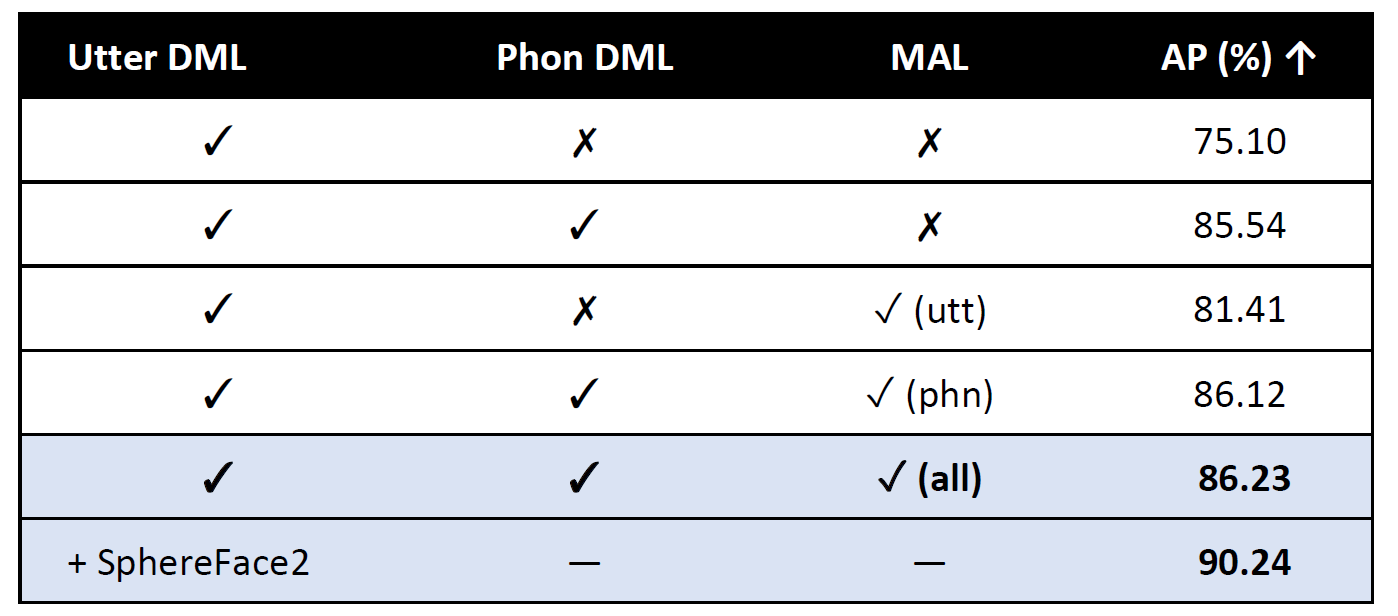
Table 2. Ablation MAL & Phoneme DML (WSJ AP %)
→ Both phoneme DML and MAL are essential; together they deliver a +14 % relative gain, and SphereFace2 brings us to 90% AP.
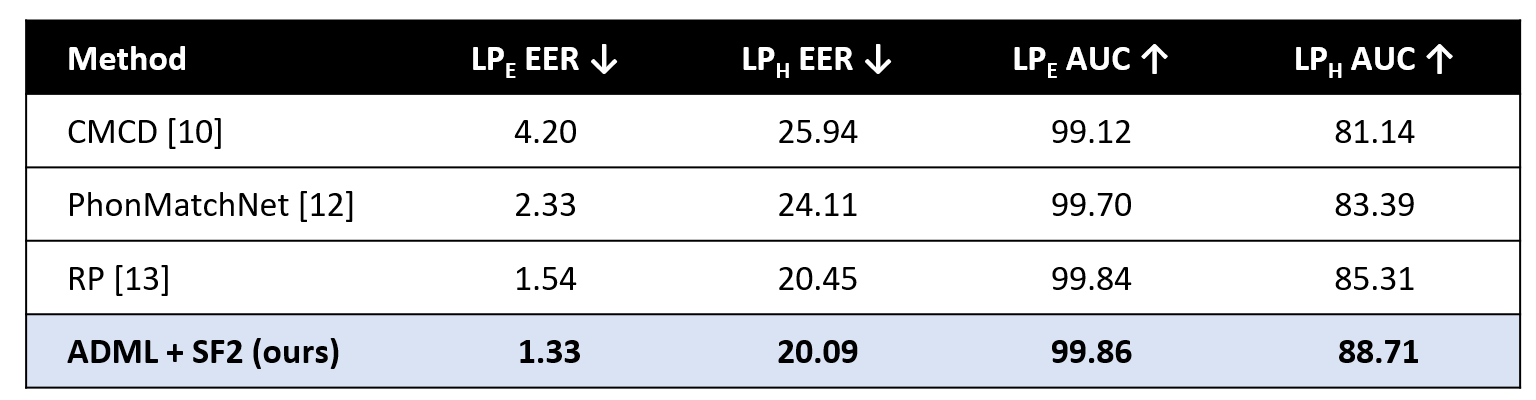
Table 3. Evaluation on LibriPhrase (EER %)
→ ADML achieves the lowest EER and the highest AUC, surpassing prior phoneme based baselines.
Conclusion
This blog introduced a unified framework for text-enrolled open-vocabulary keyword spotting that leverages multi-granularity deep metric learning (DML) and modality adversarial learning (MAL) to bridge the gap between speech and text representations.
The proposed system demonstrates several key contributions:
Comprehensive experiments show that each component contributes significantly to the final performance. The system achieves 90.24% average precision on WSJ and 1.33% EER on LibriPhrase (LPE), establishing new benchmarks for the text-enrolled KWS task.
From an engineering perspective, we found that training stability required careful loss weighting across granularities and objectives. In particular, scaling the adversarial loss relative to the main embedding losses was critical to convergence.
Future work will explore more expressive modality discriminators (e.g., transformer-based classifiers), curriculum learning for dynamic loss weighting, and extending the framework to multilingual or code-switched keyword spotting.
References
[1] G. Chen, C. Parada, and G. Heigold, “Small-footprint keyword spotting using deep neural networks,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2014, pp. 4087–4091.
[2] T. N. Sainath and C. Parada, “Convolutional neural networks for small-footprint keyword spotting,” in Proc. Interspeech, 2015, pp. 1478–1482.
[3] R. Tang and J. J. Lin, “Deep residual learning for small-footprint keyword spotting,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 5484–5488.
[4] G. Chen, C. Parada, and T. N. Sainath, “Query-by-example keyword spotting using long short-term memory networks,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5236–5240.
[5] J. Huang, W. Gharbieh, H. S. Shim, and E. Kim, “Query-by-example keyword spotting system using multi-head attention and soft-triple loss,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 6858–6862.
[6] K. R, V. K. Kurmi, V. Namboodiri, and C. V. Jawahar, “Generalized keyword spotting using ASR embeddings,” in Proc. Interspeech, 2022, pp. 126–130.
[7] H. Lim, Y. Kim, Y. Jung, M. Jung, and H. Kim, “Learning acoustic word embeddings with phonetically associated triplet network,” arXiv:1811.02736, 2018.
[8] W. He, W. Wang, and K. Livescu, “Multi-view recurrent neural acoustic word embeddings,” in Proc. International Conference on Learning Representations (ICLR), 2017.
[9] M. Jung and H. Kim, “Asymmetric proxy loss for multi-view acoustic word embeddings,” in Proc. Interspeech, 2022, pp. 5170–5174.
[10] H.-K. Shin, H. Han, D. Kim, S.-W. Chung, and H.-G. Kang, “Learning audio-text agreement for open-vocabulary keyword spotting,” in Proc. Interspeech, 2022, pp. 1871–1875.
[11] K. Nishu, M. Cho, and D. Naik, “Matching latent encoding for audio-text based keyword spotting,” in Proc. Interspeech, 2023, pp. 1613–1617.
[12] Y.-H. Lee and N. Cho, “PhonMatchNet: Phoneme-guided zero-shot keyword spotting for user-defined keywords,” in Proc. Interspeech, 2023, pp. 3964–3968.
[13] Y. Jung, S. Lee, J.-Y. Yang, J. Roh, C. W. Han, and H.-Y. Cho, “Relational proxy loss for audio-text based keyword spotting,” in Proc. Interspeech, 2024, pp. 327–331.
[14] S. Jin, Y. Jung, S. Lee, J. Roh, C. Han, and H. Cho, “CTC-aligned audio-text embedding for streaming open-vocabulary keyword spotting,” in Proc. Interspeech, 2024, pp. 332–336.
[15] X. Wang, X. Han, W. Huang, D. Dong, and M. R. Scott, “Multi-similarity loss with general pair weighting for deep metric learning,” in Proc. the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 5022–5030.
[16] Z. Ai, Z. Chen, and S. Xu, “MM-KWS: Multi-modal prompts for multilingual user-defined keyword spotting,” in Proc. Interspeech, 2024, pp. 2415–2419.
[17] Y. Kim, J. Jung, J. Park, B.-Y. Kim, and J. S. Chung, “Bridging the gap between audio and text using parallel-attention for user-defined keyword spotting,” IEEE Signal Processing Letters, vol. 31, pp. 2100–2104, 2024.
[18] K. Nishu, M. Cho, P. Dixon, and D. Naik, “Flexible keyword spotting based on homogeneous audio-text embedding,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 5050–5054.
[19] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Proc. Advances in Neural Information Processing Systems (NeurIPS), 2014.
[20] M. Jung and H. Kim, “AdaMS: Deep metric learning with adaptive margin and adaptive scale for acoustic word discrimination,” in Proc. Interspeech, 2023, pp. 3924–3928.
[21] Y. Wen, W. Liu, A. Weller, B. Raj, and R. Singh, “SphereFace2: Binary classification is all you need for deep face recognition,” in Proc. International Conference on Learning Representations (ICLR), 2022.
[22] K. Park and J. Kim, “g2pe,” 2019. [Online]. Available: https://github.com/Kyubyong/g2p
[23] D. Yi, Z. Lei, S. Liao, and S. Z. Li, “Deep metric learning for person re-identification,” in Proc. International Conference on Pattern Recognition, 2014, pp. 34–39.
[24] B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification,” arXiv:2005.07143, 2020.
[25] B. Han, Z. Chen, and Y. Qian, “Exploring binary classification loss for speaker verification,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5.
[26] Y. Ganin and V. Lempitsky, “Unsupervised domain adaptation by backpropagation,” in Proc. the International Conference on Machine Learning (ICML), 2015, pp. 1180–1189.
[27] DataOceanAI, “King-ASR-066,” 2015. [Online]. Available: https://en.speechocean.com/datacenter/details/1446.html
[28] D. B. Paul and J. M. Baker, “The design for the wall street journal-based CSR corpus,” in Proc. the Workshop on Speech and Natural Language, 1992, pp. 357–362.
[29] T. Ko, V. Peddinti, D. Povey, M. L. Seltzer, and S. Khudanpur, “A study on data augmentation of reverberant speech for robust speech recognition,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 5220–5224.
[30] D. Snyder, G. Chen, and D. Povey, “Musan: A music, speech, and noise corpus,” arXiv:1510.08484v1, 2015.
[31] Y. Hu, S. Settle, and K. Livescu, “Multilingual jointly trained acoustic and written word embeddings,” in Proc. Interspeech, 2020, pp. 1052–1056.
[32] M. Jung, H. Lim, J. Goo, Y. Jung, and H. Kim, “Additional shared decoder on siamese multi-view encoders for learning acoustic word embeddings,” in Proc. IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), 2019, pp. 629–636.
[33] H. Li, B. Yang, Y. Xi, L. Yu, T. Tan, H. Li, and K. Yu, “Text-aware speech separation for multi-talker keyword spotting,” in Proc. Interspeech, 2024, pp. 337–341.
[34] Y. Jung, J. Lee, S. Lee, M. Jung, Y.-H. Lee, and H.-Y. Cho, “Text-aware adapter for few-shot keyword spotting,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025.
[35] L. Kewei, Z. Hengshun, S. Kai, D. Yusheng, and D. Jun, “Phoneme-level contrastive learning for user-defined keyword spotting with flexible enrollment,” arXiv:2412.20805, 2024.
[36] W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song, “SphereFace: Deep hypersphere embedding for face recognition,” in Proc. The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 3967–3976.



