AI
DIFFSSR: Stereo Image Super-resolution Using Differential Transformer
1 Introduction
SwinIR established a robust baseline for image super-resolution using Swin Transformers. SwinFIR enhanced it via Fast Fourier Convolution (FFC), achieving SOTA. SwinFIRSSR adapted SwinFIR for StereoSR by fusing left/right features with a Stereo Cross-Attention Module (SCAM). However, Transformers inherently suffer from attention noise, assigning weight to irrelevant context. While the Differential Transformer (DIFF Transformer) mitigates this noise in language tasks, directly substituting it into SwinFIRSSR degraded performance in visual tasks, as shown in Figure. 1. This study proposes DIFFSSR, redesigning the DIFF Transformer for StereoSR by introducing a Differential Cross Attention Block (DCAB). DCAB successfully adapts the DIFF mechanism to vision and enhances cross-view information exchange compared to SwinFIRSSR. Furthermore, recognizing SCAM's limitation to strictly horizontal epipolar lines (as shown in Figure. 2)—which causes performance drops under misalignment—we propose Sliding SCAM (SSCAM). SSCAM addresses this vulnerability. Collectively, DIFFSSR with DCAB and SSCAM achieves new SOTA results across StereoSR benchmarks, significantly outperforming SwinFIRSSR. This represents the first successful adaptation of the DIFF Transformer to visual tasks.
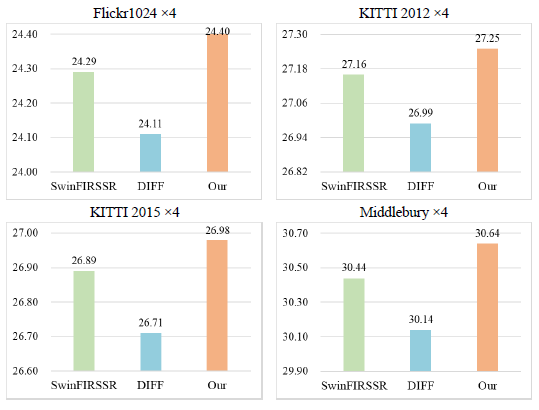
Figure 1. The comparison results with SwinFIRSSR. DIFF denotes replacing its Transformer with the DIFF Transformer.

Figure 2. On the horizontal epipolar line, the left and right views are not strictly aligned. Therefore, the performance of SCAM will be hindered.
2 Method
2.1 Overall Architecture
The DIFFSSR architecture, as depicted in Figure.3 (a), is composed of multiple Diff Cross Attention Blocks (DCAB) and Sliding Stereo Cross-Attention Module (SSCAM).
Initially, we extract shallow features $F_S^L∈\mathbb{R}^{H×W×C}$ and $F_S^R∈\mathbb{R}^{H×W×C}$ from the input low-resolution stereo images $X^L∈\mathbb{R}^{H×W×3}$ and $X^R∈\mathbb{R}^{H×W×3}$, where $H$, $W$, and $C$ denote the width, height, and number of channels of the input images or features, respectively. The feature extraction is performed as follows:
$F_S^L=H_S(X^L),F_S^R=H_S(X^R)$
where $H_S(∙)$ represents the shallow feature extraction network, which employs a convolutional layer with 3×3 kernels in this paper.
Subsequently, the extracted shallow features $F_S^L$ and $F_S^R$ are fed into a deep feature extraction module to recover the details lost in the low-resolution images. This process can be represented as:
$F_D^L=H_D(F_S^L),F_D^R=H_D(F_S^R)$
where $H_D(∙)$ denotes the deep feature extraction network, $F_D^L$ and $F_D^R$ represent the extracted deep features. The deep feature extraction module composed of a series of Diff Cross Attention Blocks (DCAB), and the intermediate features are obtained by:
$F_i^L=H_{DCAB}^i(F_{i-1}^L),F_i^R=H_{DCAB}^i(F_{i-1}^R ),i=1,2,⋯,L$
where $H_{DCAB}^i(∙)$ denotes the Diff Cross Attention Blocks, $F_i^L$ and $F_i^R$ represent the intermediate features of deep feature extraction network from each DCAB. Finally, the extracted deep features $F_D^L$ and $F_D^R$ are passed through a reconstruction module to upscale the images to the desired resolution:
$I_{SR}^L=H_{REC}(F_D^L+F_S^L),I_{SR}^R=H_{REC}(F_D^R+F_S^R)$
where $H_{REC}(∙)$ represents the reconstruction neural network, which consists of a convolutional layer followed by a pixel shuffle upsampling operation. By fusing the shallow features as residual information directly with the deep features, the network can focus more effectively on the recovery of high-frequency details. $I_{SR}^L$ and $I_{SR}^R$ denote the super-resolved left-view and right-view images, respectively.

Figure 3. The overall network architecture of DIFFSSR.
2.2 Diff Cross Attention Block (DCAB)
DCAB is a structure consisting of multiple Diff Cross Attention Layer (DCAL) and a single convolutional layer with 1×1 kernel. Specifically, the DCAL, as illustrated in Figure. 3 (b), is designed to address the issue of attention noise in traditional Transformer, which can lead to suboptimal reconstruction issues and loss of detail in super-resolved images. And the covolutional layer with spatially invariant filters can enhance the translational equivariance of DCAB. The outputs $(F_{i,j}^L$ and $F_{i,j}^R$) of $\$$j$\$$-th DCAL of i-th DCAB can be formulated as:
$F_{i,j}^L=H_{DCAL}^j(F_{i,j-1}^L ),F_{i,j}^R=H_{DCAL}^j(F_{i,j-1}^R ),j=1,2,⋯,N$
where $H_{DCAL}^j(∙)$ represents the j-th Diff Cross Attention Layer. Then, we use a convolutional layer to extract spatial features:
$F_{i,out}^L=H_{conv}^j(F_{i,N}^L),F_{i,out}^R=H_{conv}^j(F_{i,N}^R )$
where $H_{conv}^j(∙)$ represents the last convolutional layer with 1×1 kernels of i-th DCAB, $F_{i,out}^L$ and $F_{i,out}^R$ are the output of $\$$i$\$$-th DCAB, respectively.
DCAL is a cornerstone of our method. The formula for the differential attention is given by:
$[Q_1,Q_2]=xW_Q,[K_1,K_2]=xW_K,V=xW_V$
$F_{Att}=(S(\frac{Q_1K_1^T}{\sqrt{C}}+P)-λS(\frac{Q_2K_2^T}{\sqrt{C}}+P))V$
where x is the feature of left or right views, $Q_1,Q_2,K_1,K_2∈\mathbb{R}^{HW×\frac{C}{2}}$ and $V∈\mathbb{R}^{HW×C}$ denote the query, key and value. $W_Q,W_K,W_V∈\mathbb{R}^{C×C}$ are the weight of linear projection model. $F_{Att}$ denotes the output of the DIFF Attention, $S(∙)$ is the $softmax(∙)$ function and $P$ denotes the Relative Positional Encoding. $\$$\lambda$\$$ is a learnable scalar:
$λ=exp(sum(λ_{q1}*λ_{k1}))-exp(sum(λ_{q2}*λ_{k2}))+λ_{init}$
where $λ_q1,λ_q2,λ_k1,λ_k2∈\mathbb{R}^{\frac{C}{2}}$ are learnable parameters, and $λ_{init}=0.8$ in this paper.
2.3 Sliding Stereo Cross-Attention Module
The Sliding Stereo Cross-Attention Module (SSCAM), as shown in Figure.3 (c), is another critical component of our method. It is designed to integrate features from both left and right stereo images, leveraging the disparity between the two views to enhance the super-resolution process. In addition, our SSCAM is also used to addresses the performance degradation due to misalignment of horizontal epipolar lines in stereo images by employing a sliding window mechanism.
3 Results
3.1 Quantitative Evaluations
DIFFSSR demonstrates superior stereo image super-resolution (StereoSR) performance compared to leading methods SwinFIRSSR and NAFSSR-L across major benchmarks (KITTI 2012, KITTI 2015, Middlebury, Flickr1024) at both ×2 and ×4 scales, measured by PSNR and SSIM. On Flickr1024 at ×2 scale, DIFFSSR achieved 30.27dB PSNR and 0.9301 SSIM, surpassing SwinFIRSSR (30.14dB, 0.9286). At ×4 scale, DIFFSSR scored 24.40dB and 0.7722, exceeding SwinFIRSSR (24.29dB, 0.7681). This outperformance extends to KITTI 2012 and Middlebury. For example, on Middlebury at ×4 scale, DIFFSSR scored 30.55dB PSNR and 0.8723 SSIM, significantly higher than NAFSSR-L's 30.11dB and 0.8601. Crucially, DIFFSSR achieves this state-of-the-art performance with greater parameter efficiency. DIFFSSR uses only 19.86M (×2) and 20.01M (×4) parameters, considerably fewer than SwinFIRSSR's 23.94M and 24.09M. This reduction enhances rather than compromises performance, underscoring DIFFSSR's effectiveness in reconstructing high-quality images from degraded stereo pairs.
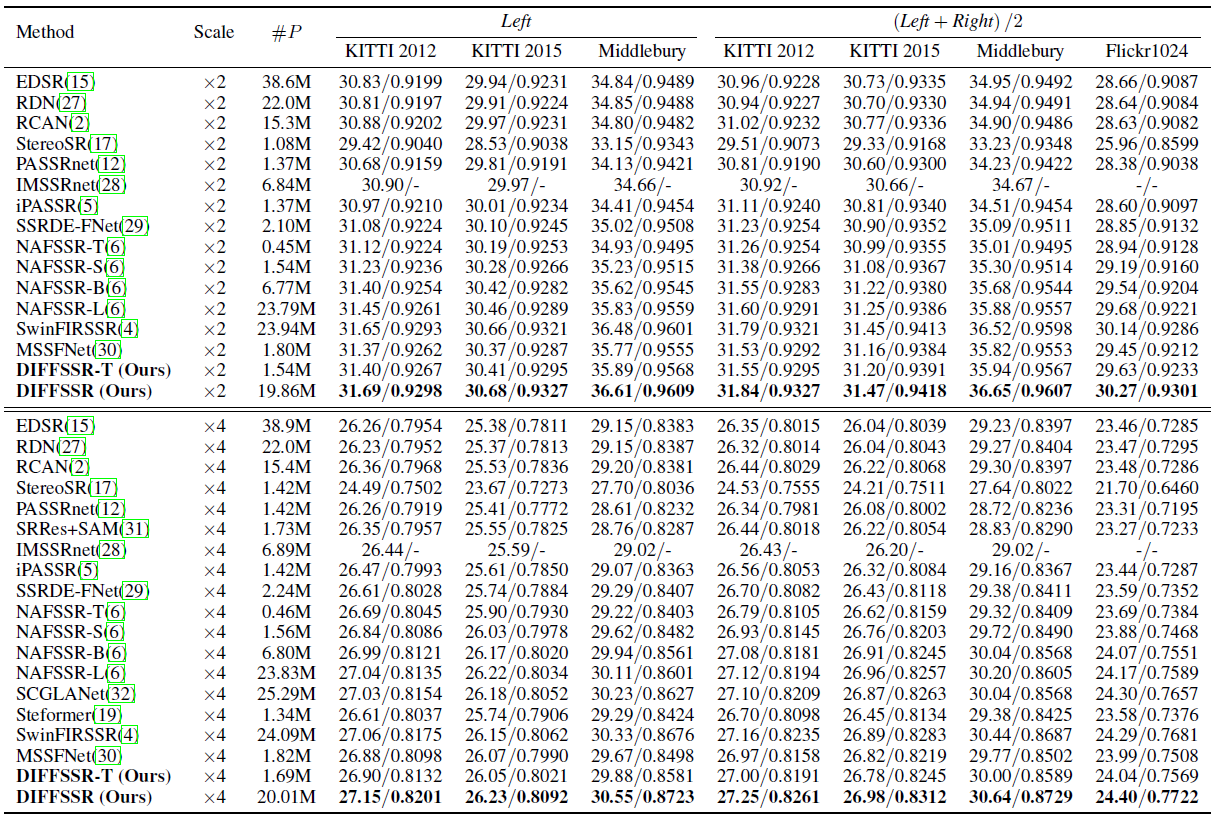
Table 1. Quantitative results achieved by different methods on the KITTI 2012, KITTI 2015, Middlebury, and Flickr1024 datasets on the RGB space for stereo image SR.
4 Conclusion
In this paper, we introduced DIFFSSR, a novel approach to stereo image super-resolution that leverages the strengths of the Differential Transformer to address the limitations of traditional Transformer models. Through the innovative design of the Diff Cross Attention Block (DCAB) and the Sliding Stereo Cross-Attention Module (SSCAM), DIFFSSR effectively reduces attention noise and improves the integration of cross-view information, leading to superior performance in recovering fine texture details and preventing over-reconstruction. Our method achieved state-of-the-art results across multiple benchmark datasets, outperforming existing methods such as NAFSSR and SwinFIRSSR. The visual comparison clearly demonstrates DIFFSSR's ability to restore low-resolution images with greater accuracy and detail, while also avoiding the over-smoothing artifact that plague traditional Transformer-based models. The success of DIFFSSR highlights the importance of tailored neural network architectures for specific visual tasks and the potential of Differential Transformer in improving the performance of super-resolution models.