AI
[INTERSPEECH 2022 Series #2]FedNST: Federated Noisy Student Training for Automatic Speech Recognition
|
The 23rd Annual Conference of the International Speech Communication Association (INTERSPEECH 2022) was held in Incheon, South Korea. Hosted by the International Speech Communication Association (ISCA), INTERSPEECH is the world's largest conference on research and technology of spoken language understanding and processing. This year a total of 13 papers in Samsung Research’s R&D centers around the world were accepted at the INTERSPEECH 2022. In this relay series, we are introducing a summary of the 6 research papers. - Part 1 : Human Sound Classification based on Feature Fusion Method with Air and Bone Conducted Signal - Part 2: FedNST: Federated Noisy Student Training for Automatic Speech Recognition (by Samsung R&D Institute UK) - Part 5: Prototypical Speaker-Interference Loss for Target Voice Separation Using Non-Parallel Audio Samples |
Voice assistants have seen an ever-increasing uptake by consumers’ worldwide leading to the availability of vast amounts of real-world speech data. Research efforts around the world focus on effectively leveraging this data to improve the accuracy and robustness of state-of-the-art automatic speech recognition (ASR) models.
Acquiring such data for training (see Figure 1. Centralized ASR training) can lead to privacy compromises since sensitive information such as age, gender and personality can be inferred from speech [1] [2]. Advancements towards on-device AI have made it possible for voice assistant queries to be resolved entirely on user devices. These queries, which are not uploaded to the cloud, are not available for model improvements.

Figure 1. Centralized ASR training
An active area of research that promises to improve model accuracy while preserving privacy is Federated Learning (FL) [3] [4]. Briefly, an FL algorithm involves: (1) selecting a group of clients, (2) transmitting a global model to clients, (3) training the global model on local user data, (4) transmitting gradients/weights back to the server, (5) aggregating gradients/weights, and (6) repeating steps 1-5 until convergence.
By training on-device and only sharing gradients to the server, this method improves user privacy as compared to uploading raw audio to the server. Recently, various federated ASR methods have been proposed to train ASR models in FL systems [5] [6] [7] [8].

Figure 2. Federated ASR training
All such approaches assume availability of labelled data on clients participating in FL (Figure 2. Federated ASR Training). This requires users to manually transcribe their spoken sentences on their devices which may not be desirable. In order to help overcome this limitation we explore the field of self and semi-supervised learning.
In this blog post we present our research work [9] where we adopt Noisy Student Training (NST) [10] [11], a semi-supervised learning method, to leverage unlabelled user data for federated training of ASR models.
The contributions of our work are as follows:
1. To our best knowledge, this is the first work which aims to leverage private unlabelled speech data distributed amongst thousands of clients to improve accuracy of end-to-end ASR models in FL systems.
2. For this purpose, we propose a new method called FedNST, employing noisy student training for federated ASR models, which achieves 22.5% word error rate reduction (WERR) over training with only labelled data.
3. We elucidate the change in word error rate (WER) of ASR models from central training to cross-device Federated Learning regimes with FedNST, achieving a marginal 2.2% relative difference from fully-centralized NST in a comparable setup.
Our Approach: FedNST
Our work explores a challenging and realistic scenario: each client holds and trains a model exclusively on its own unlabelled speech data, leading to a heterogeneous data distribution, and, more than a thousand clients participate in FL, resulting in a cross-device scenario.
Federated Noisy Student Training (FedNST) considers a scenario where a corpus of labelled data  with paired audio samples and transcripts is available on a central server. Each client
with paired audio samples and transcripts is available on a central server. Each client  , where
, where  is the set of all clients, has an unlabelled speech dataset
is the set of all clients, has an unlabelled speech dataset  . The aim of FedNST is then to leverage the unlabelled datasets
. The aim of FedNST is then to leverage the unlabelled datasets  to improve accuracy of an ASR model trained on while preserving user privacy, i.e., without sending user data to the server.
to improve accuracy of an ASR model trained on while preserving user privacy, i.e., without sending user data to the server.
Following high-level steps describes FedNST (illustrated in Figure 3. FedNST - High-level overview):
1. We train a baseline model using the supervised data – this is the Gen-0 model ( )
)
2. This model is sent to a selection of users devices, the users perform noisy student training on the device – so pseudo-label their data and then train for N epochs.
3. The models are then sent to the server, aggregated and a new global model emerges – this becomes the model for the next round.
4. Steps 2-3 are repeated for a certain number of rounds, at every round a new set of users are sampled and pseudo-labelling can either be done based on the round 0 model () or the current round model ( , where t is the round index).
, where t is the round index).
5. Once the global model converges or the desired number of rounds are reached, the final model produced is denoted as the Gen-1 model adapting NST nomenclature (aka  , after training for
, after training for  rounds) which is then sent to all user devices for an improved on-device ASR performance.
rounds) which is then sent to all user devices for an improved on-device ASR performance.

Figure 3. FedNST - High-level overview
We refer the reader to our paper [9] for the full FedNST algorithm and federated optimization procedure.
Experimental setup
We empirically evaluate our proposed method on the LibriSpeech (LS) dataset [12]. Following the setup described in [5], we divide the dataset into two equal subsets,  and
and  , each comprising of 480 hours of audio. The two sets are disjoint, such that all data arising from a single speaker is assigned to only one set.
, each comprising of 480 hours of audio. The two sets are disjoint, such that all data arising from a single speaker is assigned to only one set.
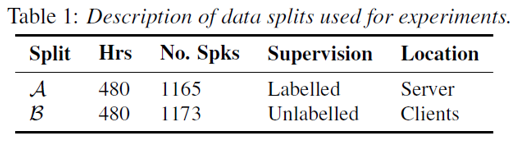
Table 1. Experimental setup
We use an end-to-end ASR model architecture [13] with a Conformer (S) encoder [14], a transformer decoder and a joint CTC+Seq2Seq objective [15]. We evaluate all models using WER which measures the discrepancy between predicted and actual transcript in terms of edit distance.
Results reported on the dev-clean, test-clean and test-other sets of LS [12] are obtained by fusing the ASR model with an off-the-shelf language model (LM) [13] and using a beam search of size 10. This approach of LM fusion is typical for evaluation in ASR literature. For the federated experiments, we use a FL simulation platform with design characteristics similar to those described in [5].
We explore design choices for FedNST which balance model performance and training cost on two fronts: when to pseudo-label and whether to re-use labelled server data during FL.
First, instead of sending the model to all clients at the beginning to perform pseudo-labelling, we propose an alternative strategy: at every round  , the participating clients (selected for training) perform pseudo-labelling using the latest global model, .
, the participating clients (selected for training) perform pseudo-labelling using the latest global model, .
Secondly, the standard NST [16] procedure involves mixing samples from the labelled and pseudo-labelled datasets for each training step. However, in supervised FL, it is common to start with a model pre-trained on the server with some labelled data, and during the FL process to only use client data for model updates [5] [6]. In this work, we perform an empirical study to determine the optimal strategies for data mixing with FedNST – only aggregating client updates, or also incorporating the supervised data on the server, which was used for pre-training .
We refer the reader to our paper [9] for full experimental setup details.
Results
Comparison with SotA Methods
We compare our method against several baselines. We first evaluate a model that is only trained on the first set of LibriSpeech (, 480h, labelled) and denote it as SLseed. Second, we evaluate a model trained on the entire LibriSpeech data ( , 960h, labelled) centrally referred as SL. Next, we evaluate the centralized semi-supervised learning technique NST by further training the SLseed model with pseudo-labelled .
, 960h, labelled) centrally referred as SL. Next, we evaluate the centralized semi-supervised learning technique NST by further training the SLseed model with pseudo-labelled .
Finally, we evaluate labelled federated ASR training (denoted as SFL) and our proposed approach FedNST. For both approaches, we start with SLseed and train the model further with distributed amongst clients in a non-iid fashion. This implies that every FL client holds data of one LibriSpeech user only. is labelled or pseudo-labelled for SFL or FedNST respectively.

Table 2. Main results
Our results (presented in Table 2: Main Results) are summarized as follows:
1. We achieve a 22.5% WERR over a model trained with only labelled data using additional data that is pseudo-labelled (FedNST vs SLseed).
2. We achieve a marginal 2.2% relative difference in terms of WER from fully-centralized NST in a comparable setup (3.31 vs 3.24).
Exploring Different Pseudo-Labelled Regimes

Figure 4. Using A and B vs only B for FedNST
We analyse the hypothetical gain in performance if all of the data on clients was labelled; as well as the usefulness of initial labelled data for FedNST in Figure 4. Using A and B vs only B for FedNST.
Figure 4 (i) varies the percentage of clients with entirely labelled data against clients which pseudo-label their data. Figure 4 (ii) varies percentage of labelled samples per client, i.e., ratio of samples with ground-truth against samples that are pseudo-labelled for each client. Within each set, graphs representing (blue) and (red) show the impact of dataset mixing in FL.
We find that in the low-labelled data regime (0-50%), re-using (i.e., data-mixing) produces a noticeable WER improvement. However, this improvement significantly diminishes in the high-labelled data regime (50-100%).
We hypothesize that the benefits seen with using both and () for the low-labelled data regime come from acting as a form of regularisation when most of the client data is pseudo-labelled.
Comparison of Pseudo-Labelling Strategies

Table 3. Comparison of pseudo-labelling strategies
We also ran an experiment to test our alternative pseudo-labelling strategy in which pseudo-labelling is performed every round t for clients selected for training (see Table 3. Comparison of pseudo-labelling strategies). Although this strategy performs very similarly to our original approach in terms of WER, the pseudo-labelling step is highly computationally expensive, increasing the overall FL experiment time by 10x. We leave optimizing on this front as future work.
Conclusion and Future Work
We have proposed a new method called FedNST for semi-supervised training of ASR models in FL systems. FedNST performs noisy student training to leverage private unlabelled user data and improves the accuracy of models in low-labelled data regimes using FL. Evaluating FedNST on real-world ASR use-cases using the LibriSpeech dataset with over 1000 simulated FL clients showed 22.5% relative WERR over a supervised baseline trained only with labelled data available at the server. Our analyses showed that FedNST achieves a WER comparable to fully centralized NST and to supervised training while incurring no extra communication overhead compared to FedAvg [4].
In the future, we plan to employ FedNST on more challenging datasets with a larger set of clients and data distributions that mimic real-world scenarios e.g. short duration utterances. We plan to also extend FedNST by incorporating other self- and semi-supervised learning methods such as Wav2Vec2.0 [17].
Link to the paper
https://www.isca-speech.org/archive/pdfs/interspeech_2022/mehmood22_interspeech.pdfReferences
[1]. S. Galgali, S. S. Priyanka, B. R. Shashank and A. P. Patil, "Speaker profiling by extracting paralinguistic parameters using mel frequency cepstral coefficients," in International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), 2015.
[2]. B. W. Schuller, S. Steidl, A. Batliner, E. Nöth, A. Vinciarelli, F. Burkhardt, R. van Son, F. Weninger, F. Eyben, T. Bocklet, G. Mohammadi and B. Weiss, “A Survey on perceived speaker traits: Personality, likability, pathology, and the first challenge,” Computer Speech and Language, vol. 29, p. 100–131, 2015.
[3]. J. Konečný, H. B. McMahan, F. X. Yu, P. Richtárik, A. T. Suresh and D. Bacon, “Federated Learning: Strategies for Improving Communication Efficiency,” arXiv, vol. abs/1610.05492, 2016.
[4]. B. McMahan, E. Moore, D. Ramage, S. Hampson and B. A. y Arcas, “Communication-Efficient Learning of Deep Networks from Decentralized Data,” in AISTATS, 2017.
[5]. D. Dimitriadis, K. Kumatani, R. Gmyr, Y. Gaur and S. E. Eskimez, “A Federated Approach in Training Acoustic Models,” in Interspeech, 2020.
[6]. Y. Gao, T. Parcollet, S. Zaiem, J. Fernández-Marqués, P. P. B. de Gusmao, D. J. Beutel and N. D. Lane, “End-to-End Speech Recognition from Federated Acoustic Models,” in ICASSP, 2022.
[7]. D. Guliani, F. Beaufays and G. Motta, “Training Speech Recognition Models with Federated Learning: A Quality/Cost Framework,” in ICASSP, 2021.
[8]. X. Cui, S. Lu and B. Kingsbury, “Federated Acoustic Modeling for Automatic Speech Recognition,” in ICASSP, 2021.
[9]. H. Mehmood, A. Dobrowolska, K. Saravanan and M. Ozay, “FedNST: Federated Noisy Student Training for Automatic Speech Recognition,” in Interspeech, 2022.
[10]. Y. Zhang, J. Qin, D. S. Park, W. Han, C.-C. Chiu, R. Pang, Q. V. Le and Y. Wu, “Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition,” arXiv, vol. abs/2010.10504, 2020.
[11]. Q. Xie, M.-T. Luong, E. H. Hovy and Q. V. Le, “Self-Training With Noisy Student Improves ImageNet Classification,” in CVPR, 2020.
[12]. V. Panayotov, G. Chen, D. Povey and S. Khudanpur, “Librispeech: an ASR corpus based on public domain audio books,” in ICASSP, 2015.
[13]. M. Ravanelli, T. Parcollet, P. Plantinga, A. Rouhe, S. Cornell, L. Lugosch, C. Subakan, N. Dawalatabad, A. Heba, J. Zhong, J.-C. Chou, S.-L. Yeh, S.-W. Fu, C.-F. Liao, E. Rastorgueva, F. Grondin, W. Aris, H. Na, Y. Gao, R. D. Mori and Y. Bengio, “SpeechBrain: A General-Purpose Speech Toolkit,” arXiv, vol. abs/2106.04624, 2021.
[14]. A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu and R. Pang, “Conformer: Convolution-augmented Transformer for Speech Recognition,” in Interspeech, 2020.
[15]. S. Kim, T. Hori and S. Watanabe, “Joint CTC-attention based end-to-end speech recognition using multi-task learning,” in ICASSP, 2017.
[16]. D. S. Park, Y. Zhang, Y. Jia, W. Han, C.-C. Chiu, B. Li, Y. Wu and Q. V. Le, “Improved Noisy Student Training for Automatic Speech Recognition,” in Interspeech, 2020.
[17]. Y.-A. Chung, Y. Zhang, W. Han, C.-C. Chiu, J. Qin, R. Pang and Y. Wu, “w2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training,” in ASRU, 2021.
[18]. A. Baevski, Y. Zhou, A. Mohamed and M. Auli, “wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations,” in NeurIPS, 2020.
[19]. R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Henretty, R. Morais, L. Saunders, F. M. Tyers and G. Weber, “Common Voice: A Massively-Multilingual Speech Corpus,” in LREC, 2020.
[20]. M. Kotti and C. Kotropoulos, “Gender classification in two Emotional Speech databases,” in ICPR, 2008.



