AI
[INTERSPEECH 2022 Series #1] Human Sound Classification based on Feature Fusion Method with Air and Bone Conducted Signal
|
The 23rd Annual Conference of the International Speech Communication Association (INTERSPEECH 2022) is being held in Incheon, South Korea in this week. Hosted by the International Speech Communication Association (ISCA), INTERSPEECH is the world's largest conference on research and technology of spoken language understanding and processing. This year a total of 13 papers in Samsung Research’s R&D centers around the world were accepted at the INTERSPEECH 2022. In this relay series, we are introducing a summary of the 6 research papers. - Part 1 : Human Sound Classification based on Feature Fusion Method with Air and Bone Conducted Signal - Part 5: Prototypical Speaker-Interference Loss for Target Voice Separation Using Non-Parallel Audio Samples |
Background
Human sound classification is similar to Acoustic scene classification(ASC) and aims to distinguish the kinds of sounds that the human body makes. This technology can be used in scenes such as human health detection, but there are few related works on human sound classification. The CNN is widely used in extracting the characteristics of the time-frequency domain signal[1, 2]. In addition, the use of residual network also greatly improves the accuracy of the ASC task [1, 3]. The CRNN structure has been proved to be effective in sound event detection and classification tasks, such as gated CRNN[4], Conformer-DNC[5], CNN-LSTM parallel net[6], and CRNN with classification chain[7].
Different from others ASC, human sounds can be captured by human wearable devices to obtain signals of different modalities, such as bone conduction signal. The current ASC task related research mostly focuses on one stream signal which is mainly collected from the air-conducted (AC) microphone, and the event itself is extremely susceptible to external noise interference. For human sound classification, bone conducted (BC) signal could be used to reduce the noise interference. BC signals have strong anti-noise ability, but due to different propagation media from AC signal, mickle harmonics would be lost [8]. When a person makes a sound (such as speaking, coughing, exercising, etc.), it can be transmitted not only through the air, but also through the bone. The bone conduction microphone can collect such weak signals from the skull and the larynx to obtain BC signal [9]. Thus, we propose a network combing both BC signals and AC signals can possibly improve the classification ability.
In this blog, we present our related work which published at INTERSPEECH 2022. We combine both BC and AC signals as input to train a CNN based model, and demonstrate the improvement of using BC signals on the human sound classification task. An attentional feature fusion method is proposed based on the complementarity between two signals. Moreover, a feature enhancement method is used for BC signal to improve the high frequency band features. Experimental results show feature fusion method and BC signals feature enhancement method improve the effect of the model in the human sound classification task.
Proposed Method
As shown in Figure 1, our proposed methods are implemented on a CNN and fully connected (FC) based model. There are four continuous convolutional layers to extract features from the AC and BC signal respectively, and each layer follows a Batch Normalization (BN) and an Average Pooling (AP). The extracted BC and AC features are fused and the proposed BC_E module is applied to enhance the feature of BC signal. Finally, the FC layer is to estimate the probabilities of each classes.
The drop out is applied between the second and third CNN block to prevent overfitting and we extract acoustic features of two streams from the waveform. Data augmentation method SpecAugment is applied to the input layer space.

Figure 1. Illustrates of the classification network
Considering the differences and complementarities between BC signals and AC signals, it is significantly important to select the feature weights of the two signals. Hence a kind of attentional feature fusion method is used.
BC-AC fusion method: We believe that the complementarities exist in the two stream signal feature layer. We propose an attentional feature fusion method to select more useful features between AC and BC signals. We use the network as a two-signal fusion method instead of a multi-scale fusion method. The structural overview of the BC-AC fusion layer is shown in Figure 2, which is applied after signals feature extraction.
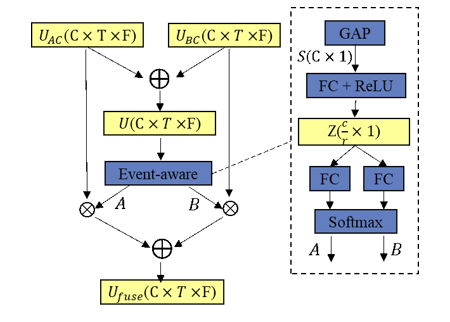
Figure 2. Structural overview of the BC-AC fusion method
Given two stream features, we firstly fuse them via an element-wise summation  to concentrate both features, where
to concentrate both features, where  ,
,  ,
,
 . Then, Global Average Pooling (GAP) is applied to squeeze the fused output
. Then, Global Average Pooling (GAP) is applied to squeeze the fused output  into one channel representation
into one channel representation  . A FC layer is used to reduce dimensionality for better efficiency, followed by an activation function ReLU. The degree of compression between the input
and the output
. A FC layer is used to reduce dimensionality for better efficiency, followed by an activation function ReLU. The degree of compression between the input
and the output 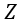 is determined by the reduction ratio
is determined by the reduction ratio
 . A soft attention across channels contains FC layers and a Softmax function is used to adaptively select different spatial scales of information, which is guided by the compact feature descriptor
. A soft attention across channels contains FC layers and a Softmax function is used to adaptively select different spatial scales of information, which is guided by the compact feature descriptor
 .
.  denote the output of FC with
as input. Specifically, the Softmax is applied on the channel-wise digits.
denote the output of FC with
as input. Specifically, the Softmax is applied on the channel-wise digits.

BC_E module : Inspired by frequency Band Width Extension (BWE), we propose a method for BC signals enhancement without neural network. The full-band enhancement of the BC signal can be performed with only low frequency band harmonics and the positions of all harmonics can be recovered. The method consists of three main steps in total, as shown in Figure 3.

Figure 3. BC_E module
The first step in processing the BC signal is to crop. In order to make the energy of harmonics account for a larger proportion of the overall signal energy, low pass filtering (LPF) is performed on the full-band signal, and only the signal below the cut-off frequency (CoF) is retained. Given an input
 ,
, 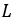 is the length of sequence. Here we use Butterworth filter. Then, the signal
is the length of sequence. Here we use Butterworth filter. Then, the signal
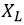 pass through a non-linear device (NLD) which shifts the frequencies to higher region. There are some NLDs such as half-wave rectification, square and cube law that perform well in BC_E module. Then a high pass filter (HPF) is used to select extensions frequency (>1KHz). After obtaining the low-frequency band and the recovered high-frequency band information separately, we combine the two parts into one enhanced BC signal Xen. The recovered signal
pass through a non-linear device (NLD) which shifts the frequencies to higher region. There are some NLDs such as half-wave rectification, square and cube law that perform well in BC_E module. Then a high pass filter (HPF) is used to select extensions frequency (>1KHz). After obtaining the low-frequency band and the recovered high-frequency band information separately, we combine the two parts into one enhanced BC signal Xen. The recovered signal
 has almost same energy as the signal ,
thus we adopt a gain factor
has almost same energy as the signal ,
thus we adopt a gain factor 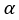 to balance the energy distribution of the whole band.
to balance the energy distribution of the whole band.
Experimental Results
Experiments show that the BC signals and proposed methods can improve the performance of the model in human sound classification task on the ‘human sound’ part in public dataset Audioset and our recorded dataset.

Table 1. The F1-score on the two datasets
Table 1 shows the comparison results of the five models on the human sound part in Audioset and the real recorded dataset. We count the F1-score on the two datasets, and in the comparison results, we can conclude that whether the model uses the simulated BC signal or the real BC signal, its classification effect is better than the model only uses AC signal. Compared to models using only AC signals, our proposed methods achieve 6.2% and 17.4% improvement in performance on the two datasets, respectively. Furthermore, the BC_E module and BC-AC fusion method can effectively improve the classification ability.

Table 2. The F1-score of each class on the Audioset
Table 2 shows the performance improvement of each human sound category on the Audioset. We separately count the F1-score of the proposed model with or without BC signal (and BC_E module). From the results, the model with BC signal and proposed methods has a significant improvement in the human voice and human group actions, which proves that the BC signal can effectively capture and expand features for sounds with obvious harmonics.
Finally, we explore the influence of different CoF and NLD in BC_E module, and the result shows in Table 3.
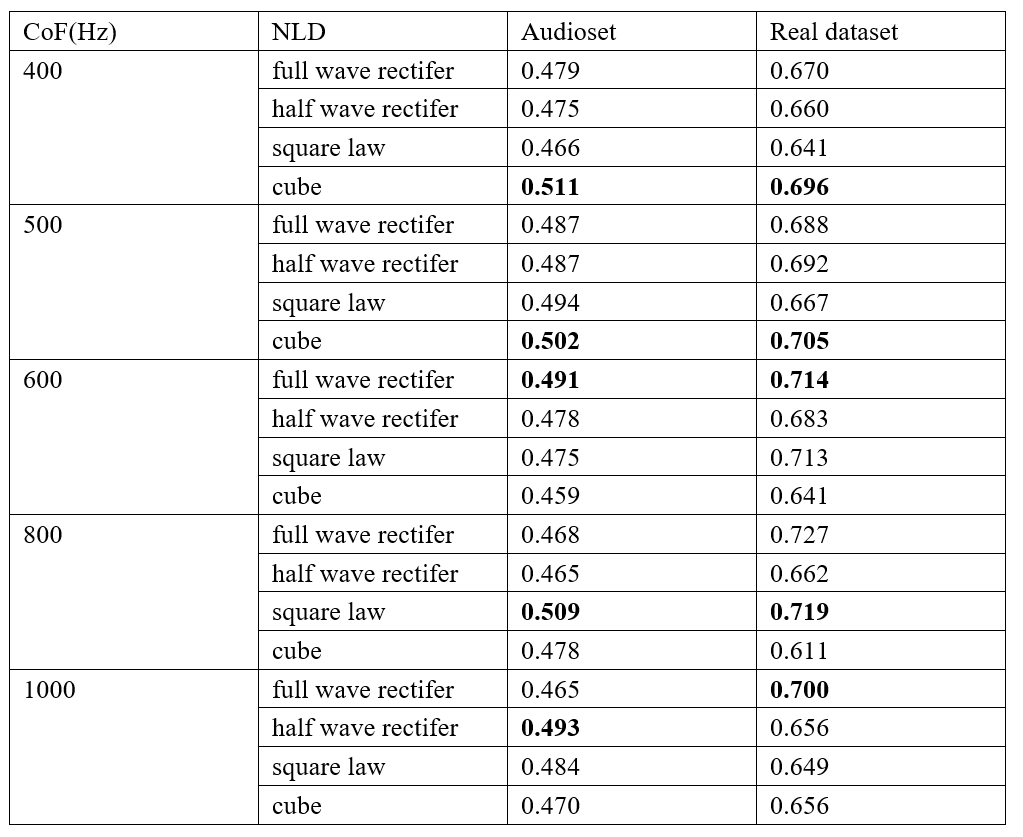
Table 3. Evaluation of the BC E module
From Table 3 we can obtain the following three conclusions about BC_E module. First of all, we find that the classification performance will decrease after a certain frequency band reaches the highest level. Secondly, the optimal gain effect brought by different NLD modules occurs at different cut-off frequencies. Finally, on the same CoF, both real and simulated BC signals basically obtain the best results on the same NLD. However, square law performs better on real BC signals, while cube law is more suitable for simulated BC signals.
Conclusion
In this blog, we combine both BC and AC signals in the human sound classification task. An attentional feature fusion method for AC and BC signals is proposed and a feature enhancement method based on frequency band extension is used on BC signal. Our work proves the complementarity between BC signal and AC signal, and the experimental results show the BC signal and proposed methods can effectively improve the model classification ability. In the future, we aim to explore other techniques to make use of the BC signal features in human sound classification.
References
[1]. L. Ford, H. Tang, F. Grondin, and J. Glass, “A Deep Residual Network for Large-Scale Acoustic Scene Analysis,” in Proc. Interspeech 2019, 2019, pp. 2568–2572.
[2]. S. Si, J. Wang, H. Sun, J. Wu, C. Zhang, X. Qu, N. Cheng, L. Chen, and J. Xiao, “Variational Information Bottleneck for Effective Low-Resource Audio Classification,” in Proc. Interspeech 2021, 2021, pp. 591–595.
[3]. J. Naranjo-Alcazar, S. Perez-Castanos, P. Zuccarello, and M. Cobos, “Acoustic scene classification with squeeze-excitation residual networks,” IEEE Access, vol. 8, pp. 112 287–112 296, 2020.
[4]. Y. Xu, Q. Kong, W. Wang, and M. D. Plumbley, “Large-scale weakly supervised audio classification using gated convolutional neural network,” in Proc. Interspeech 2021, 2021, pp. 576–580.
[5]. S. Seo, D. Lee, and J.-H. Kim, “Shallow Convolution-Augmented Transformer with Differentiable Neural Computer for LowComplexity Classification of Variable-Length Acoustic Scene,” in Brazilian Journal of Psychiatry 29 (2007): s13-s18.
[6]. S. H. Bae, I. Choi, and N. S. Kim, “Acoustic scene classification using parallel combination of lstm and cnn,” in Proceedings of the detection and classification of acoustic scenes and events 2016 workshop (DCASE2016), 2016, pp. 11–15.
[7]. T. Komatsu, S. Watanabe, K. Miyazaki, and T. Hayashi, “Acoustic Event Detection with Classifier Chains,” in Proc. Interspeech 2021, 2021, pp. 601–605.
[8]. C. Porschmann, “Influences of bone conduction and air conduction on the sound of one’s own voice,” Acta Acustica united with Acustica, vol. 86, no. 6, pp. 1038–1045, 2000.
[9]. Q. Pan, T. Gao, J. Zhou, H. Wang, L. Tao, and H. K. Kwan, “Cyclegan with dual adversarial loss for bone-conducted speech enhancement,” arXiv preprint arXiv:2111.01430, 2021.



