Communications
Unified CSI Reconstruction and Prediction with Channel Attention Mechanism
1 Introduction
The study of Artificial Intelligence (AI)-based Channel State Information (CSI) feedback enhancement has shown great potential in reducing feedback overhead, and overcoming channel aging issues in massive multiple-input multiple-output systems. However, there remain several challenges in real-world deployments, including error propagation in reconstruction, prediction accuracy, and model generalization.
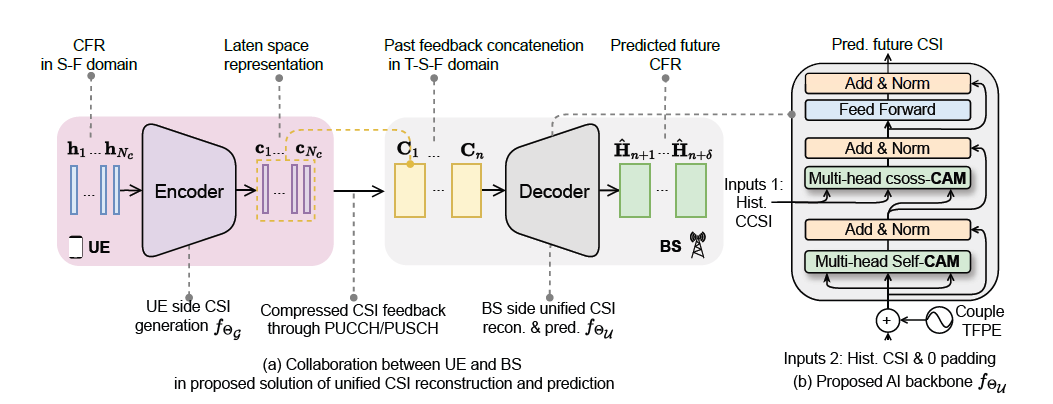
Figure 1. Overview of proposed method CAMUniCSI
In this work, we propose a novel Channel Attention Mechanism based Unified CSI reconstruction and prediction scheme (CAM-UniCSI). Our approach features a unified architecture that resolves the issue of error propagation in the traditional two-phased approach. Moreover, we develop a multipath channel model (MPC)-based channel attention mechanism to enhance the interpretability of the model and boost prediction performance. Additionally, we utilize UE-specific information instead of fixed parameters for position embedding, thereby improving the model’s generalization capability.
2 Method
A unified architecture is designed to perform CSI reconstruction and prediction simultaneously at BS side. The CSI generation process at UE side can adopt a regular encoder approach, which is, compress channel information in spatial-frequency domain of a single slot. Through this CSI generation model, UE can get a latent space representation of channel. After proper quantization process, the compressed CSI will then be feedback to BS through physical up-link control channel (PUCCH) or the physical uplink shared channel (PUSCH). At BS side, the received compressed CSI reported from UE is firstly de-quantized. Then instead of reconstruct single slot CSI, we use multi-moments of past feedback concatenation to directly predict channel frequency response (CFR) of future slots.
And for the AI backbone, we use a Transformer decoder based one for its powerful domain transformation capacity. With two different kinds of CSI information (accumulated historical compressed CSI and previously predicted CFR and 0 paddings for prediction) as the inputs of our AI backbone, and two kinds of channel attention mechanism (Self-CAM and Cross-CAM) in our decoder layer, the model can firstly extract correlation between historical CFR and future CFR, and then predict future CFR results by further introducing more compressed CSI.
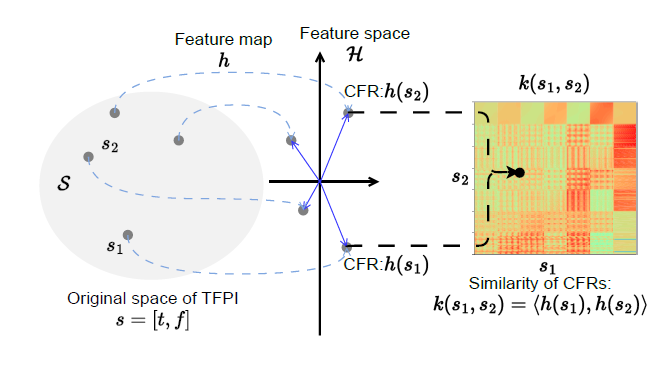
Figure 2. Kernel map from TFPI to similarity of corresponding CFR
2.1 Theoretical foundation - Complex-valued MPC kernel
Inspired by the perspective of attention under the kernel len in [3], where attention mechanism is regarded as a weighted linear combination process, with the combined weight being normalized kernel function, i.e., attention score, we develop a complex-valued MPC continuous kernel and discrete it to get a matrix-multiplication form as the basis of our CAM, and then through coupled time-frequency positional embedding (TFPE) and UE-specific spectral density extraction, we finally obtain the attention score by the fused MPC kernel and exponential kernel.
2.2 Implementation of CAM
Step 1 - Discrete division of space
Since AI model can only process discrete values, it’s necessary to divide the value space of variation rate reasonably.
Step 2 - Coupled TF Position Embedding
The purpose of Coupled TF Position Embedding (c-TFPE) is to get the exponential part of Kernel function.
Step 3 - UE-specific power distribution extraction
We use the UE-specific CFR input to extract multipath power feature D in Doppler-delay domain. That means for different UEs, we’ll have different power distributions. Thus we need a UE specific power distribution matrix to enable the model with ability to distinguish different channels for different UEs.
2.3 Implementation of CAM-UniCSI
To perform CSI reconstruction and prediction at BS side, we use a Transformer decoder based AI backbone for its powerful domain transformation capacity. With two different kinds of CSI information (accumulated historic compressed CSI and previously predicted CFR and 0 padding for prediction) as the inputs of our AI backbone, and two kinds of channel attention mechanism (Self-CAM and Cross-CAM, same function as the self-attention and cross attention in traditional Transformer) in our decoder layer, the model can firstly extract correlation between historic CFR and future CFR, and then predict future CFR results by further introducing more compressed CSI.
3 Results
3.1 Prediction Performance
The GCS results of ground-truth with delay indicates the channel aging problem and necessity of channel prediction. With 2-phased prediction, channel similarity can be improved, but still not acceptable due to reconstruction error. In our model, by synchronously reconstructing multiple time slots, we can reduce reconstruction errors to a significant degree. Also benefiting the powerful feature extraction of our interpretable channel attention mechanism, the prediction accuracy is further improved in all scenarios.

Table 1. Prediction accuracy (\%)
3.2 Model generalization
The generalization performance is presented below, including model generalization over different types of training and testing data. Figure 3 show that compared to current 2-phased transformer based prediction approach, the GCS performance of our model decline less when use different UE velocity of train/test data.
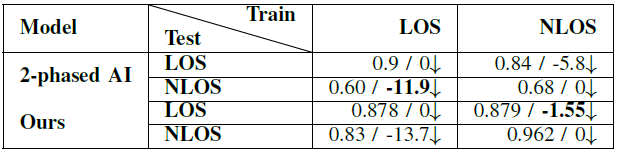
Table 2. Model generalization over LOS scenario (GCS results / relative gain compared to same train and test data type in %)
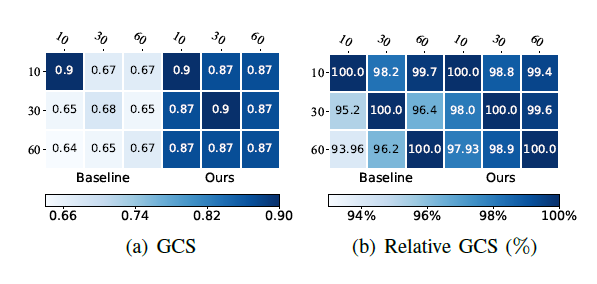
Figure 3. GCS and relative GCS (different train and testing data/same train and test data * 100% ) : each row corresponding to a type of training data of certain UE velocity in km/s, each column corresponding to a testing one
3.3 Model generalization
Moreover, Table III demonstrates that our solution exhibits significantly lower parameter size, computational complexity, and inference time for 100 samples (on GPU A6000) compared to the current 2-phased AI approach.

Table 3. Model complexity comparison with AI baseline
3.4 Model generalization
Through analysis of visible model parameters and simulations of effective input formats, the attention scores of self-CAM and cross-CAM under varying UE velocities (10 km/h, 30 km/h, 60 km/h) are illustrated in Figure 4. It is evident that the similarity of CFRs evolves simultaneously with time and frequency, with the rate of change increasing as the UE velocity rises.
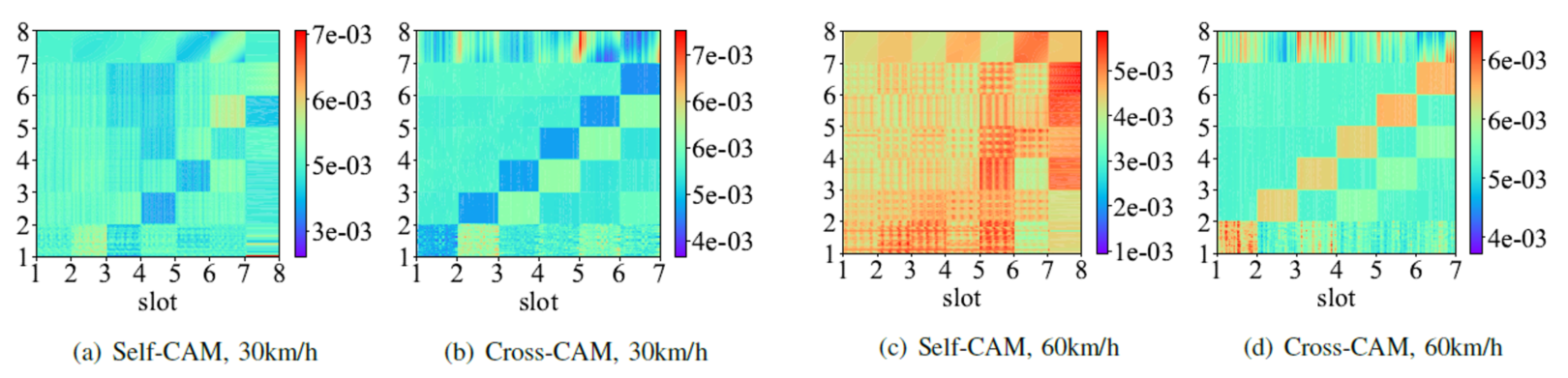
Figure 4. Attention score of self-CAM and cross-CAM under different UE velocities
4 Conclusion
This work proposed CAM-UniCSI, a novel unified CSI feedback enhancement architecture designed for improved commercial deployment feasibility. By incorporating a channel attention mechanism (CAM), we achieved highly accurate CSI prediction while enhancing the interpretability of our AI backbone. Additionally, our model extracted UE-specific power distributions, resulting in superior generalization performance. Furthermore, simulation results demonstrated the low complexity and compatibility of our approach with Rel-16 Type II cookbook-based PMI, facilitating its practical application. Also, it provided a solid basis for the standardization of CSI feedback enhancement process.
References
[1] M. K. Shehzad, L. Rose, and M. Assaad, “Dealing with csi compression to reduce losses and overhead: An artificial intelligence approach,” in IEEE ICC Wkshps, 2021.
[2] H. Jiang, M. Cui, D. W. K. Ng, and L. Dai, “Accurate channel prediction based on transformer: Making mobility negligible,” IEEE J. Sel. Area Commun., vol. 40, no. 9, pp. 2717–2732, 2022.
[3] Y. H. Tsai, S. Bai, M. Yamada, L. P. Morency, and R. Salakhutdinov, “Transformer dissection: a unified understanding of transformer’s attention via the lens of kernel,” arXiv preprint arXiv:1908.11775, 2019.