AI
LittleBit: Ultra Low-Bit Quantization via Latent Factorization
1. Introduction
Large Language Models (LLMs) have transformed technology, but their massive size presents a significant barrier to deployment. The huge memory and computational costs, especially GPU VRAM, make it difficult to run these powerful models on consumer-grade or edge devices.
Quantization, the process of reducing the numerical precision of model weights, is a popular solution. While methods like 4-bit quantization (e.g., GPTQ [3], AWQ [4]) have become standard, the "sub-1-bit" regime (where each weight is represented by less than one bit on average) has remained a critical challenge. This area often suffers from unacceptable performance degradation.
This post explores LittleBit, a novel method introduced in a NeurIPS 2025 paper that shatters this barrier. LittleBit enables extreme LLM compression down to levels like 0.1 bits per weight (BPW). This achieves a nearly 31x memory reduction, capable of shrinking a model like Llama2-13B to under 0.9 GB.
We will dive into the core methodology of LittleBit, examine its impressive results, and discuss the profound implications for deploying powerful LLMs in resource-constrained environments.
2. Background: The Wall of Sub-1-Bit Quantization
To understand LittleBit's innovation, we first need to understand the current landscape.
-
PTQ vs. QAT: Most quantization methods fall into two categories. Post-Training Quantization (PTQ) methods like GPTQ [3] and AWQ [4] adapt a pre-trained model and work well for ~4-bit precision. Quantization-Aware Training (QAT) integrates quantization into the training loop, allowing the model to adapt to the low-precision format, which is essential for 1-bit models [5].
-
The Sub-1-Bit Challenge: Even 1-bit models can be too large for some devices (e.g., a 70B 1-bit model is ~15.4GB [2]). Pushing below 1.0 BPW, however, causes severe information loss. Prior work like STBLLM [8] has ventured into this area, but maintaining performance and efficiency remains a critical challenge.
LittleBit's design is founded on two key observations:
1.
LLMs are Low-Rank: LLM weight matrices inherently have a significant low-rank structure [10, 11]. This suggests that factorization methods, like Singular Value Decomposition (SVD) [12], are a more stable compression path than pruning [13], especially at extreme ratios.
2.
Scaling is Crucial: Binarization (reducing weights to just ±1) causes massive information loss. High-performing 1-bit methods [7, 9] show that mitigating this loss requires sophisticated, learnable scaling factors over multiple dimensions.
LittleBit unifies these two ideas into a single, novel architecture.
3. Methodology: How LittleBit Works
LittleBit replaces standard linear layers with a new architecture designed from the ground up for extreme compression. This architecture has three core components.
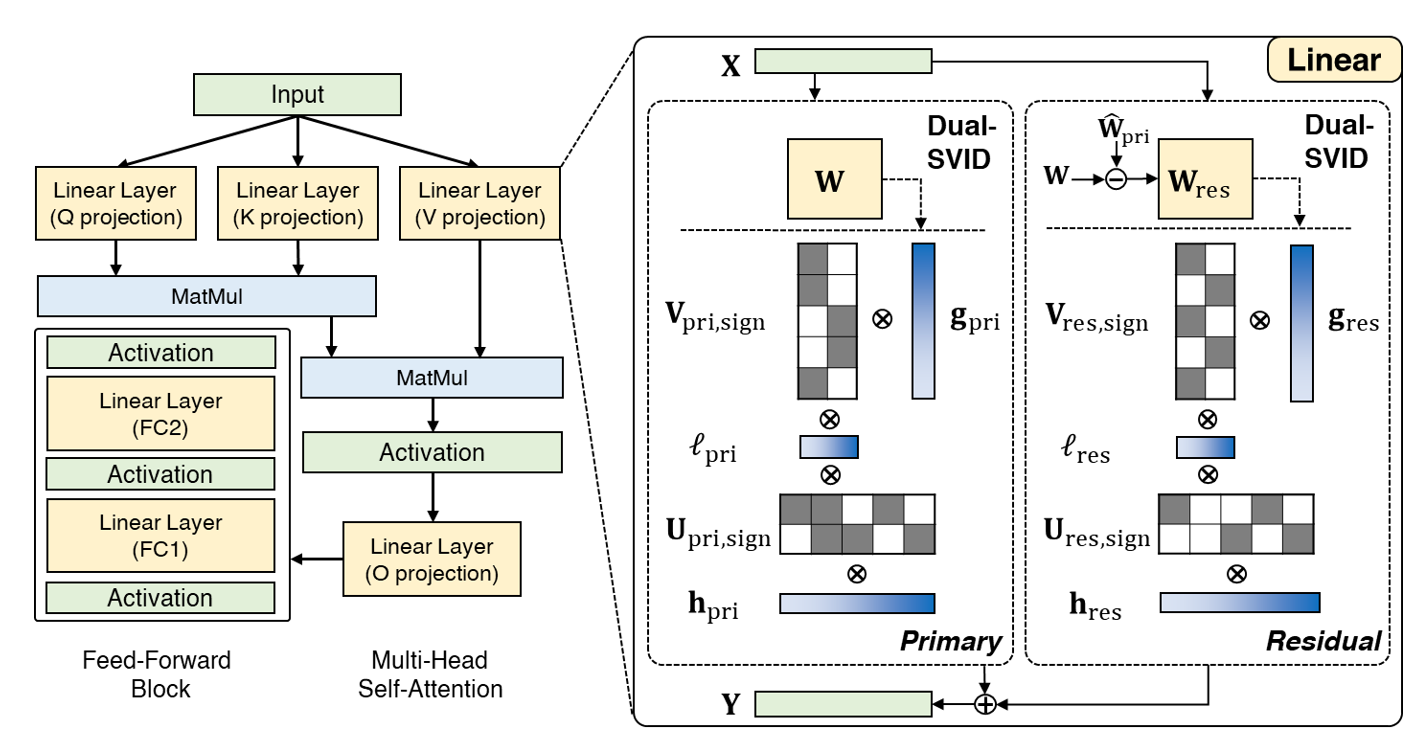
Figure 1. Comparing a standard Transformer layer (left) with the LittleBit architecture (right). The LittleBit layer shows the parallel Primary and Residual pathways
3.1. Latent Factorization with Multi-Scale Compensation
Instead of quantizing the full-size weight matrix $W$, LittleBit first approximates it in a low-rank form: $W≅UV^⊤$. These smaller latent factors, $U$, and $V$, are then binarized to $U_{sign}$ and $V_{sign}$ (containing only ±1).
To compensate for the massive information loss from this binarization, LittleBit introduces three separate FP16 learnable scaling factors:
- Row scale ($h∈R^{d_{out}}$): A standard per-row scaling vector.
- Column scale ($g∈R^{d_{in}}$): A standard per-column scaling vector.
- Latent scale ($l∈R^{d_r}$): This is a key innovation. This vector learns the relative importance of each of the $r$ latent dimensions (ranks), applying a unique scale to each one.
The final effective weight for the primary path, $\widehat W_{pri}$, is implicitly constructed from these binarized factors and multi-scale compensation factors:
$\widehat W_{pri}$ = diag($h$) $U_{sign}$ diag($l$) $V_{sign}^⊤$ diag($g$)
This factorized form is highly efficient, replacing one large matrix multiplication with two smaller binary matrix multiplications and element-wise scaling operations.
3.2. Dual-SVID Initialization
This highly constrained architecture can be unstable to train with QAT from a naive initialization. To solve this, LittleBit introduces Dual-SVID (Dual Sign-Value-Independent Decomposition), an SVD-based initialization method.
Dual-SVID provides a stable starting point for QAT by preserving the original weight's core information. It works by:
1. Performing a truncated SVD on $W$ to get optimal low-rank factors $U$' and $V$'.
2. Initializing the binary factors directly from their signs $U_{sign,0}$=sign($U$') and $V_{sign,0}$=sign($V$').
3. Decomposing the magnitudes (|$U$'| and |$V$'|) using a separate rank-1 SVD approximation to estimate the initial scales for $h_0$, $g_0$, and the latent scale $l_0=l_{u,0}⊙l_{v,0}$.
3.3. Residual Compensation
To further boost fidelity, LittleBit employs a Residual Compensation mechanism. This technique doesn't increase the total bit budget; instead, it strategically reallocates it from a single, higher-rank approximation into two lower-rank paths: a primary path and a residual path.
The residual path has an identical LittleBit structure ($W_{res}$) and is specifically initialized using Dual-SVID on the error of the primary path's initial approximation ($W_{res,0}=W- \widehat W_{pri,0}$).
During QAT, both paths are optimized jointly, and their outputs are summed: $\widehat W=\widehat W_{pri}+\widehat W_{res}$. This two-stage correction captures information missed by the primary path, significantly enhancing the model's final performance.
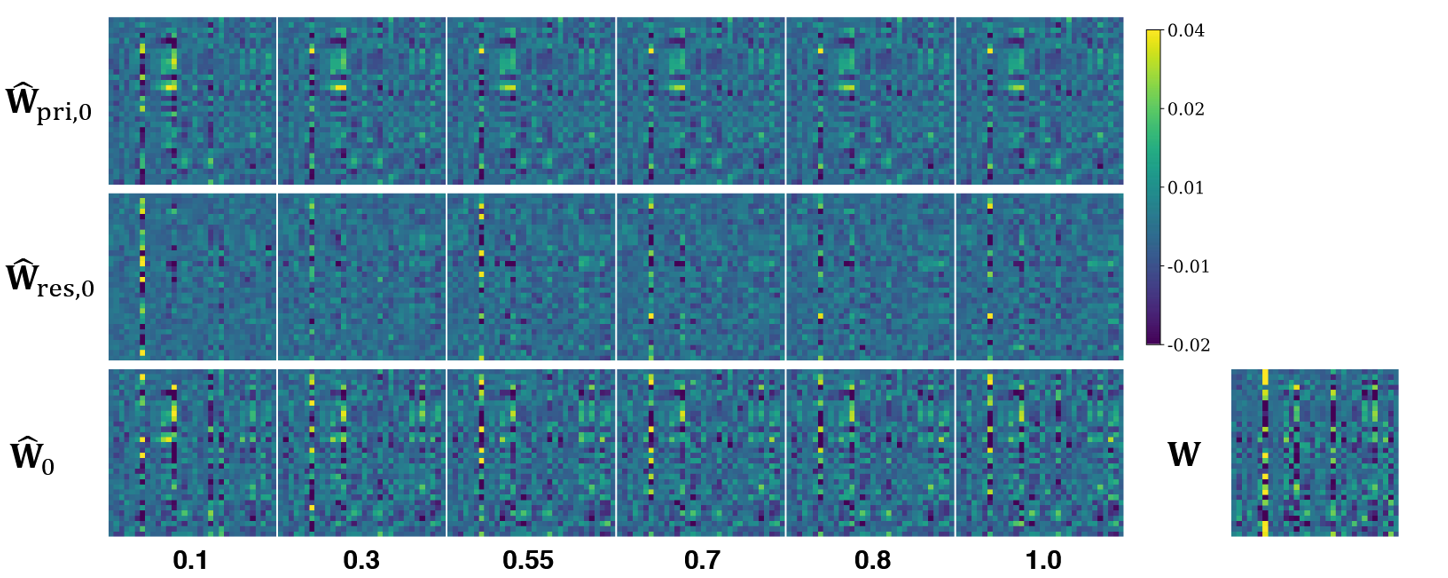
Figure 2. This visualization shows how the initialized primary path ($\widehat W_{pri,0}$), residual path ($\widehat W_{res,0}$), and their sum ($\widehat W_0$) effectively reconstruct the original weight $W$, even at very low BPWs
4. Results: Unprecedented Performance at Extreme Compression
LittleBit was extensively evaluated on a wide range of LLMs (from 1.3B to 32B), including the Llama, Llama2, Llama3, OPT, and Phi-4 families. The results demonstrate a new state-of-the-art in model compression.
4.1. Superior Perplexity (PPL) in the Sub-1-Bit Regime
Perplexity (PPL) is a standard metric for language modeling (lower is better). The results are striking.
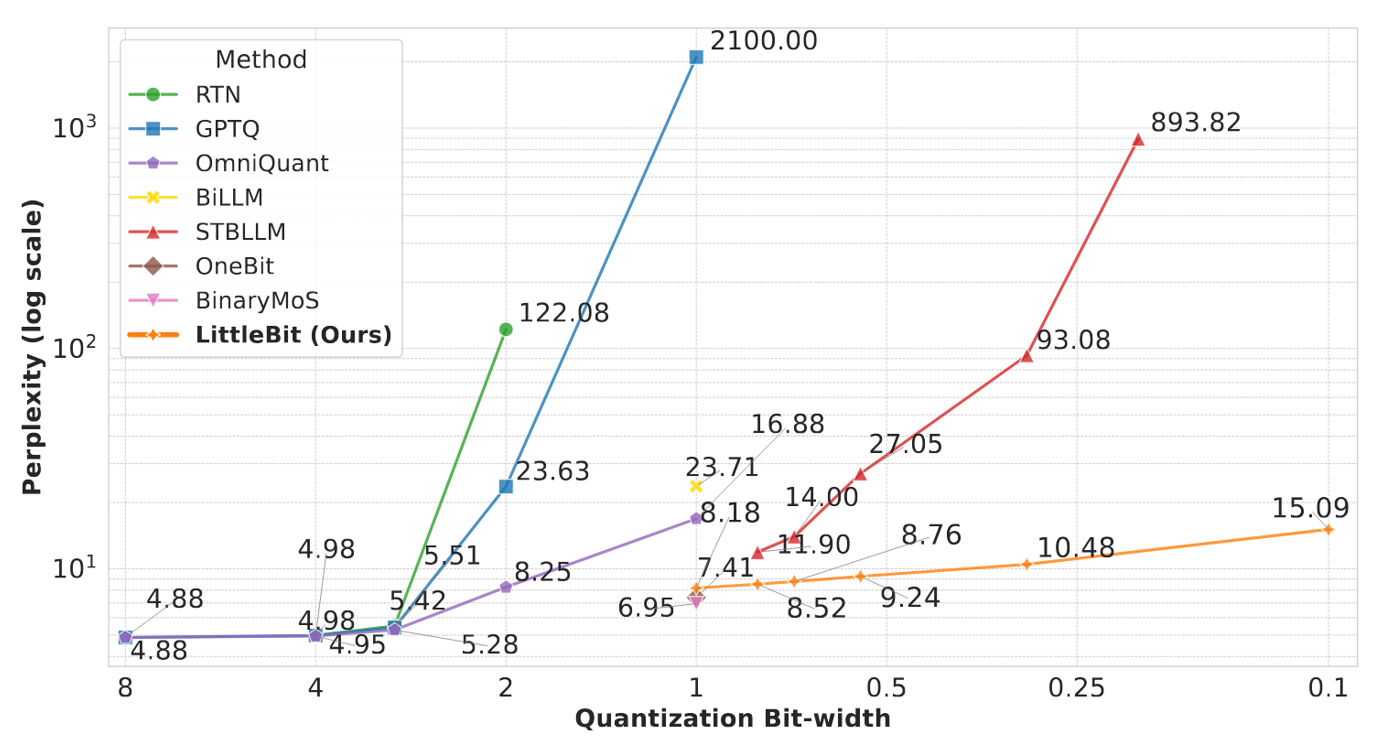
Figure 3. Perplexity vs. Quantization Bit-width for Llama2-13B on WikiText-2. Notice how the LittleBit (orange dashed line) remains low and stable, while the leading prior method (STBLLM, in gray) degrades sharply below 0.5 BPW
The chart shows that while most methods collapse, LittleBit remains robust. This is confirmed by the detailed numbers in Table 1.
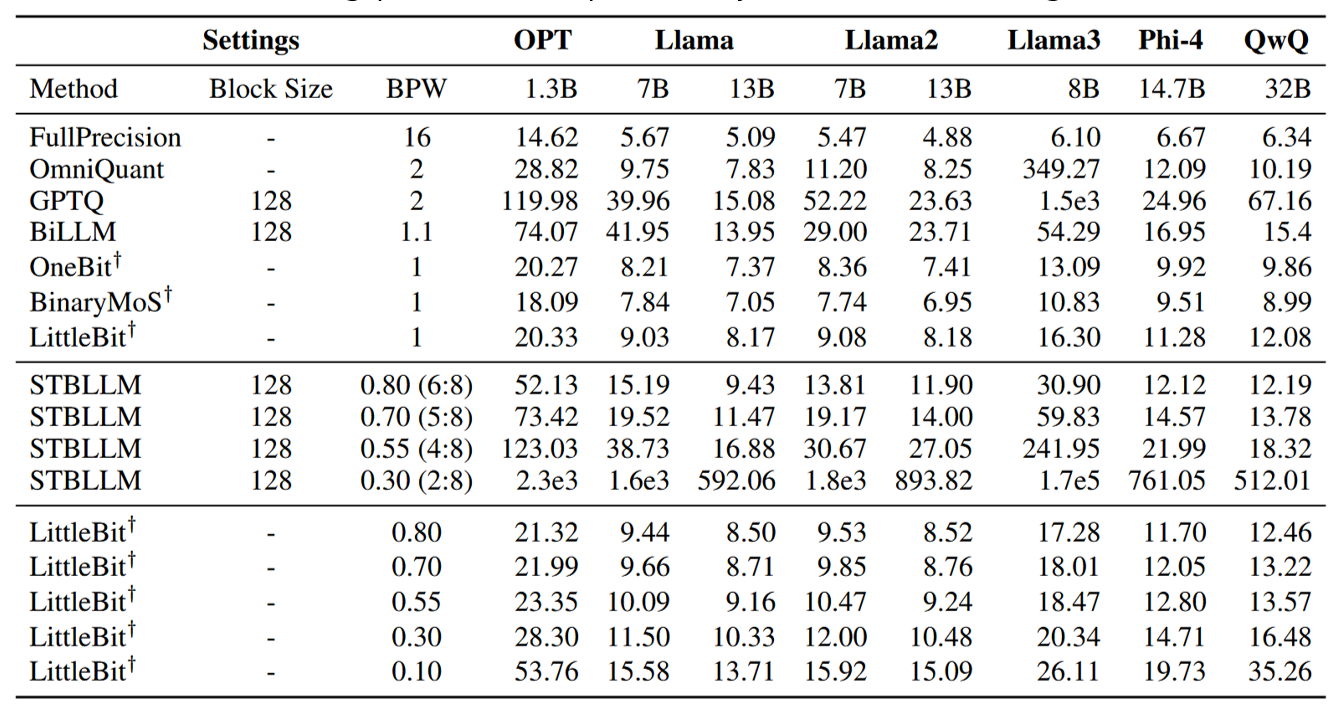
Table 1. Perplexity (PPL) comparison on WikiText-2 across various LLMs and quantization methods. LittleBit demonstrates strong performance, particularly in the sub-1-bit regime
Key performance highlights from Table 1 include:
- Llama2-7B @ 0.55 BPW: LittleBit achieves a PPL of 10.47, a massive improvement over STBLLM's 30.67.
- Extreme Stability: At 0.3 BPW, STBLLM's performance collapses (PPL of 1.8e3 for Llama2-7B). In contrast, LittleBit maintains a strong PPL of 12.00.
- Unprecedented 0.1 BPW: LittleBit remains viable even at an extreme 0.1 BPW, scoring 15.92 PPL on Llama2-7B. This is better than STBLLM at 0.7 BPW (19.17 PPL for Llama2-7B).
4.2. Preserving Reasoning Capabilities
LittleBit doesn't just produce coherent text; it preserves the model's core reasoning abilities.
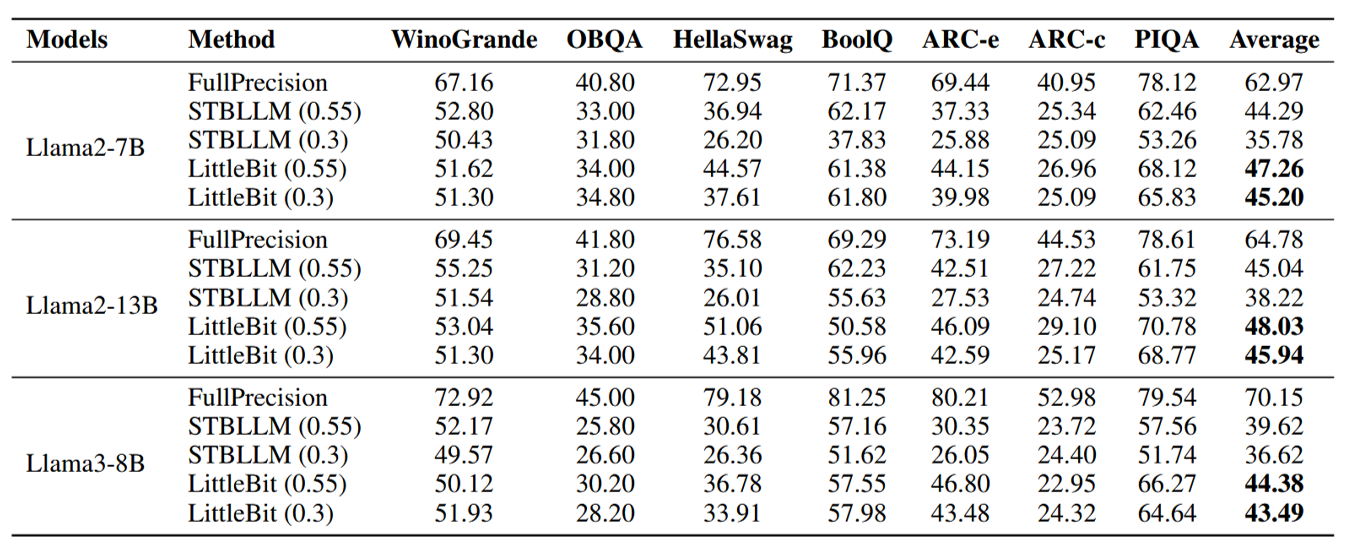
Table 2. Zero-shot accuracy (\%) comparison on common sense reasoning benchmarks
On benchmarks like WinoGrande, HellaSwag, and ARC, LittleBit consistently outperforms the previous state-of-the-art:
- Llama2-7B @ 0.55 BPW: LittleBit achieves a 47.26% average accuracy, surpassing STBLLM (44.29%).
- Llama2-7B @ 0.3 BPW: LittleBit maintains a 45.20% average, which is still higher than STBLLM at 0.55 BPW, demonstrating exceptional knowledge preservation even under extreme compression.
5. Discussion: The Practical Impact of LittleBit
These results are not just academic; they have profound, practical implications for LLM deployment.
5.1. Massive Memory Footprint Reduction
LittleBit enables fitting powerful models into tiny memory budgets.

Table 3. Memory footprint comparison (GB) for Llama2 models under different quantization methods
The memory savings are staggering:
- Llama2-7B (FP16 13.49 GB): Compresses to 0.79 GB at 0.3 BPW (>17x reduction) and 0.63 GB at 0.1 BPW (>21x reduction).
- Llama2-13B (FP16 26.06 GB): Compresses to just 0.84 GB at 0.1 BPW (a 31.02x reduction).
- Llama2-70B (FP16 138.04 GB): Compresses to 1.98 GB at 0.1 BPW (a 69.72x reduction), making it feasible to run on devices with limited VRAM.
5.2. Inherent KV Cache Compression (A "Free" Bonus)
A significant bottleneck in LLM inference, especially with long contexts, is the KV cache. LittleBit's architecture provides an inherent solution without any extra overhead.
Because the key/value projection matrices are factorized, the model only needs to cache the intermediate latent state (of dimension $r$) instead of the full model dimension ($d_{model}$).
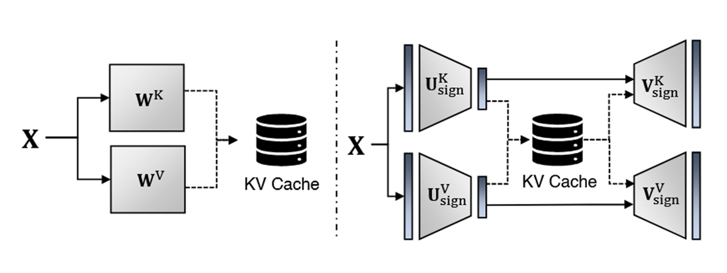
Figure 4. Conceptual view of KV Cache storage: the standard method (left) stores the full hidden dimension ($d_{model}$), whereas LittleBit (right) caches a reduced latent dimension ($r$)
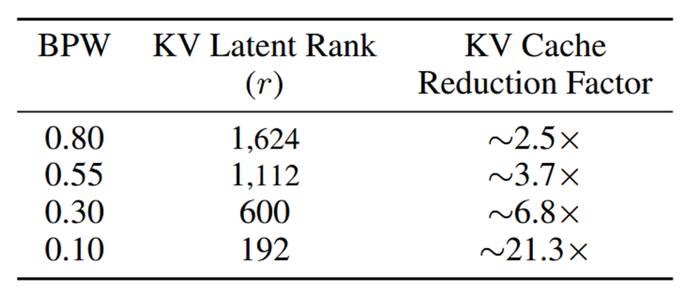
Table 4. Estimated KV cache memory reduction for Llama2-7B using LittleBit, with reduction factor $∼d_{model}/r$
This reduces KV cache memory by a factor of $∼d_{model}/r$. For Llama2-7B at 0.1 BPW, this translates to a ~21.3x reduction in KV cache size.
5.3. Significant Inference Speedup
LittleBit is designed for speed. By replacing most expensive FP16 operations with highly efficient low-rank binary operations, it promises substantial latency reductions.
A custom 1-bit GEMV CUDA kernel was benchmarked to measure this potential.
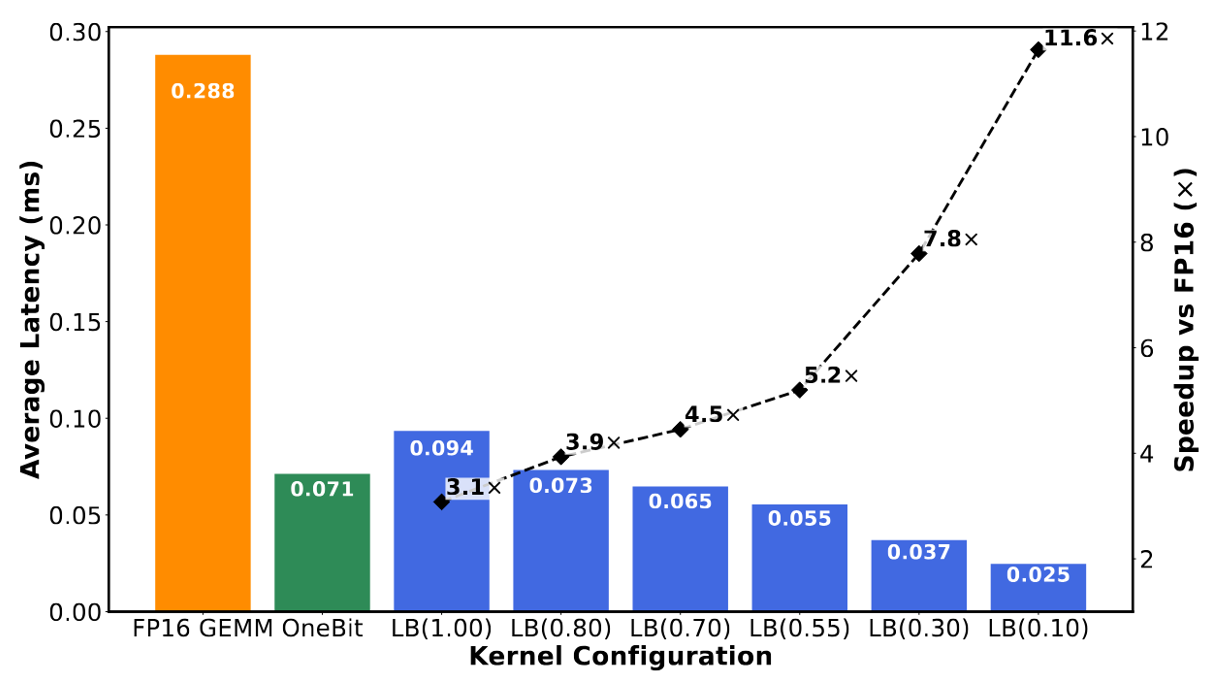
Figure 5. kernel-level latency and speedup on an NVIDIA A100. The dashed line (right axis) shows the speedup over an FP16 baseline.
The results are impressive:
- Kernel-Level: For a Llama2-70B MLP layer, the LittleBit kernel at 0.1 BPW achieves a staggering 11.6x speedup over the optimized FP16 baseline.
- End-to-End Throughput: This kernel-level speed translates to real-world gains. A Llama2-7B model using LittleBit (0.1 BPW) achieved 203.20 tokens/second, a 2.46x speedup over the FP16 baseline (82.56 tok/s) in end-to-end decoding.
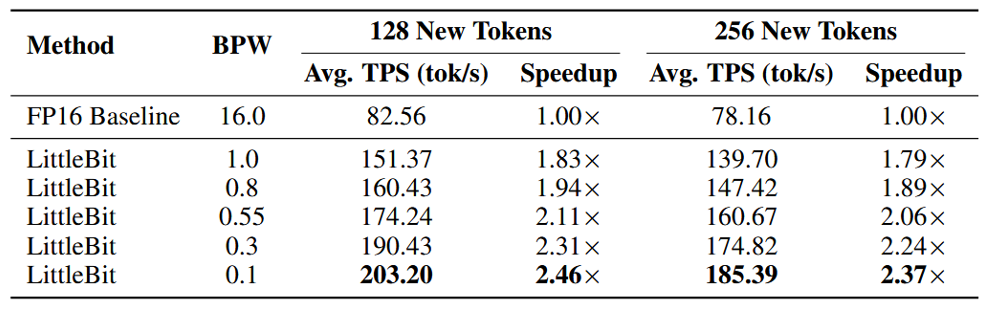
Table 5. End-to-end decoding throughput (tokens/sec) for Llama2-7B
6. Conclusion
LittleBit marks a significant advancement in LLM compression, pushing performance into the extreme sub-0.5 BPW regime and demonstrating viability even at 0.1 BPW.
By unifying SVD-inspired latent matrix factorization with a novel multi-scale compensation mechanism (row, column, and latent), it overcomes the information loss that plagues other ultra low-bit methods. The introduction of Dual-SVID initialization and Residual Compensation provides a stable and effective training pathway for this highly constrained architecture.
LittleBit establishes a new state-of-the-art in the size-performance trade-off, offering a practical path to deploy powerful, large-scale language models in highly resource-constrained environments.
References
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in Neural Information Processing System (NeurIPS), 30, 2017.
[2] Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, and Xiaojuan Qi. BiLLM: pushing the limit of post-training quantization for LLMs. In Proceedings of International Conference on Machine Learning (ICML), 2024.
[3] Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post-training quantization for generative pre-trained transformers. In Advances in Neural Information Processing Systems, volume 36, 2023.
[4] Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration. Proceedings of Machine Learning and Systems (MLSys), 6, 2024.
[5] Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[6] Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, and Furu Wei. BitNet: Scaling 1-bit transformers for large language models. arXiv preprint arXiv: 2310.11453, 2023.
[7] Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, and Wanxiang Che. OneBit: Towards extremely low-bit large language models. Advances in Neural Information Processing System (NeurIPS), 37, 2024.
[8] Peijie Dong, Lujun Li, Yuedong Zhong, Dayou Du, Ruibo Fan, Yuhan Chen, Zhenheng Tang, Qiang Wang, Wei Xue, Yike Guo, et al. STBLLM: Breaking the 1-bit barrier with structured binary LLMs. In Proceedings of International Conference on Learning Representations (ICLR), 2025.
[9] Dongwon Jo, Taesu Kim, Yulhwa Kim, and Jae-Joon Kim. Mixture of Scales: Memory-efficient token-adaptive binarization for large language models. Advances in Neural Information Processing System (NeurIPS), 37, 2024.
[10] Ajay Jaiswal, Lu Yin, Zhenyu Zhang, Shiwei Liu, Jiawei Zhao, Yuandong Tian, and Zhangyang Wang. From galore to welore: How low-rank weights non-uniformly emerge from low-rank gradients. arXiv preprint arXiv:2407.11239, 2024.
[11] Qinsi Wang, Jinghan Ke, Masayoshi Tomizuka, Yiran Chen, Kurt Keutzer, and Chenfeng Xu. Dobi-SVD: Differentiable SVD for LLM compression and some new perspectives. In Proceedings of International Conference on Learning Representations (ICLR), 2025.
[12] Gene H. Golub and Christian Reinsch. Singular value decomposition and least squares solutions. Numerische Mathematik, 14(5):403–420, 1970.
[13] Song Han, Huizi Mao, and William J. Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. In Proceedings of International Conference on Learning Representations (ICLR), 2016.
[14] Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv: 1308.3432, 2013.
[15] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.