AI
LoRA.rar: Learning to Merge LoRAs via Hypernetworks for Subject-Style Conditioned Image Generation
Introduction
Recently, there has been growing interest in personalized image generation [4, 5], where users can generate images that depict particular subjects or styles by providing just a few reference images. A key enabler of this personalization breakthrough is LoRA (Low-Rank Adapter), a parameter-efficient adaptation module introduced in [2], which enables high-quality, efficient personalization using only a small number of training samples. This innovation has spurred extensive model sharing on open-source platforms, such as Civitai and HuggingFace, making pre-trained LoRA parameters (LoRAs) readily available. The accessibility of these models has fuelled interest in combining them to create images of personal subjects in various styles. For instance, users might apply a concept (i.e., subject) LoRA trained on a few photos of their pet, and combine it with a downloaded style LoRA to render their pet in an artistic style of their choice.
Averaging LoRAs can work acceptably when subject and style share significant visual characteristics, but the fine-tuning of merging coefficients (i.e., coefficients used to combine LoRAs) is typically required for more distinct subjects and styles. ZipLoRA [5] introduces an approach that directly optimizes merging coefficients through a customized objective function tailored to each subject-style LoRA combination. However, ZipLoRA’s reliance on optimization for each new combination incurs a substantial computational cost, typically taking minutes to complete. This limitation restricts its practicality for real-time applications on resource-constrained devices like smartphones. Achieving comparable or superior quality with respect to ZipLoRA while enabling real-time merging (i.e., in under a second) would make such technology far more accessible for deployment on resource-constrained devices.
In this paper, we introduce a method named LoRA.rar for training a hypernetwork to learn merging coefficients for arbitrary subject and style LoRAs. Our hypernetwork is pre-trained on a curated dataset of LoRAs. During deployment, it generalizes to unseen subject-style pairs, generating merging coefficients instantly via a single forward pass, removing the need for retraining. An overview of our approach, along with examples of generated images, is shown in Figure 1.
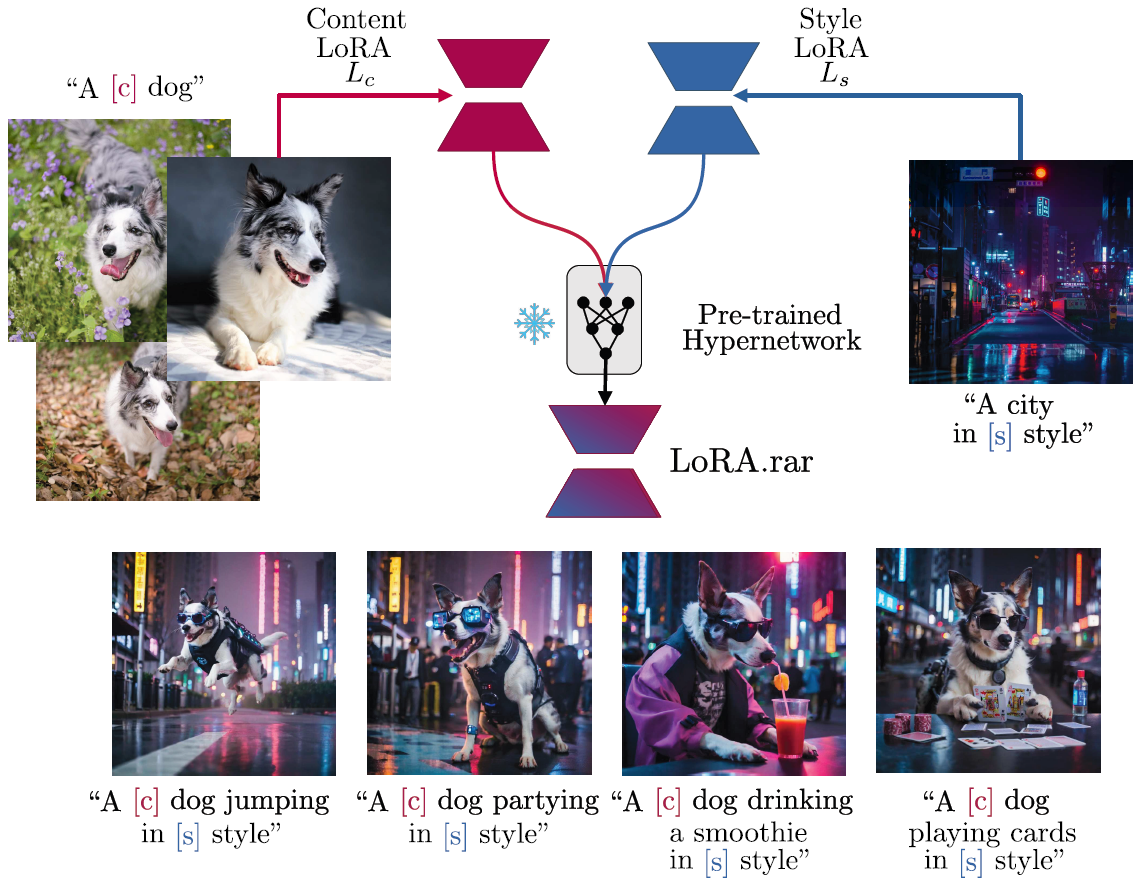
Figure 1. We address the problem of joint content-style image generation by combining content and style LoRAs. LoRA.rar uses a hypernetwork to dynamically predict the merging coefficients needed to combine content and style LoRAs. This enables high-quality, real-time LoRA merging, suitable for mobile devices
Our Method: LoRA.rar
Our objective is to design and train a hypernetwork that predicts weighting coefficients to merge content and style LoRAs. Using a set of LoRAs, we train this hypernetwork to produce suitable merging coefficients for unseen content and style LoRAs at the deployment stage (e.g. on edge devices).
Problem Formulation
We use a pre-trained image generation diffusion model $D$ with weights $W_0$ and LoRA $L$ with weight update matrix $ΔW$. For simplicity, we consider one layer at a time. A model $D$ that uses a LoRA L is denoted as $D_L=D⊕L$ with weights $W_0+ΔW$, where operation ⊕ means we apply LoRA $L$ to the base model $D$. To specify content and style, we use LoRAs $L_c$ (content) and $L_s$ (style) with respective weight update matrices $ΔW_c$ and $ΔW_s$. Our objective is to merge $L_c$ and $L_s$ into $L_m$, producing a matrix $ΔW_m$ that combines content and style coherently in generated images. The merging operation can vary, from simple averaging to advanced techniques like ZipLoRA's and ours.
ZipLoRA takes a gradient-based approach, learning column-wise merging coefficients $m_c$ and $m_s$ for $ΔW_c$ and $ΔW_s$, respectively, as: $ΔW_m=m_c⊗ΔW_c+m_s⊗ΔW_s$, where ⊗ represents element-by-column multiplication. Although ZipLoRA achieves high-quality results, it requires training these coefficients from scratch for each content-style pair. With ZipLoRA performing 100 gradient updates per pair, real-time performance is unfeasible, particularly on resource-constrained devices.
Our goal is to improve image quality while at the same time accelerating merging coefficient generation time by orders of magnitude for unseen content-style pairs. To accomplish this, we pre-train a hypernetwork that predicts adaptive merging coefficients on the fly, enabling fast, high-quality merging in a single feed-forward pass. An overview is shown in Figure 2.
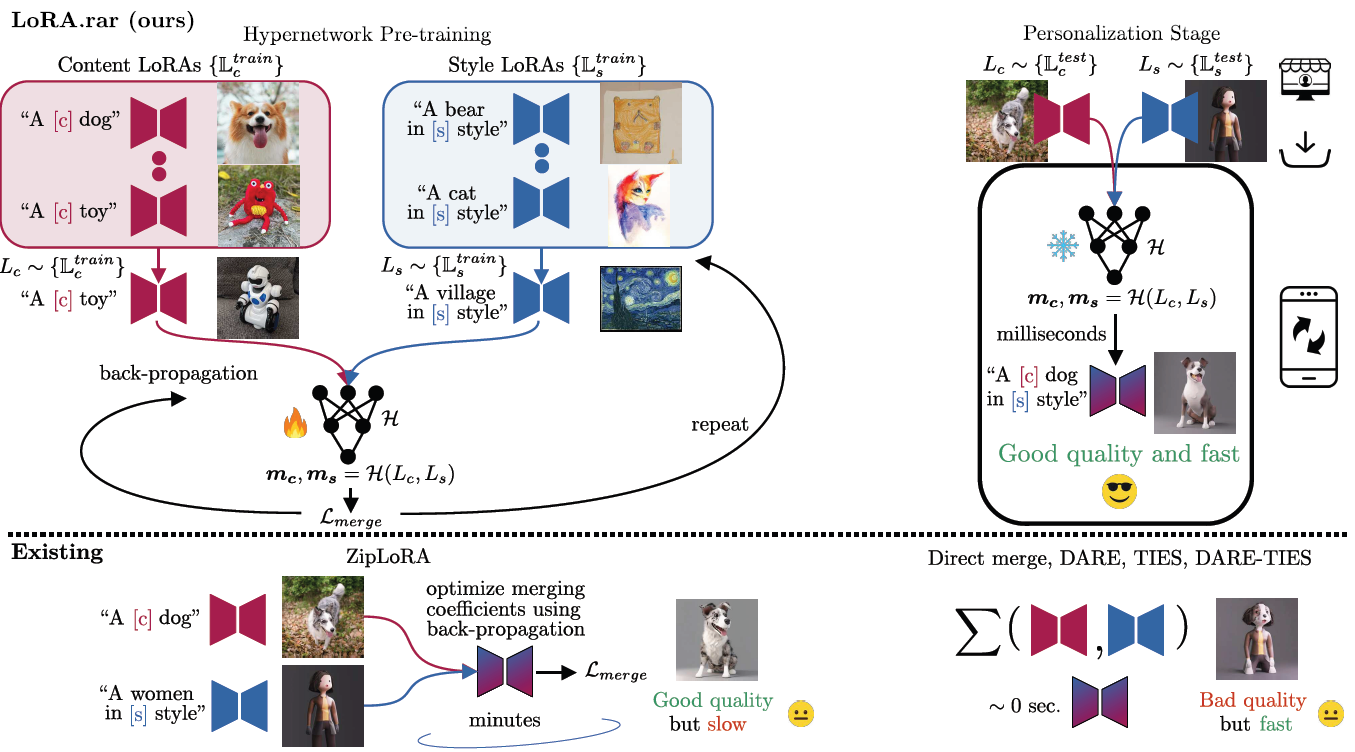
Figure 2. Method Overview. LoRA.rar pre-trains a hypernetwork that dynamically generates merging coefficients for new, unseen content-style LoRA pairs at deployment. In contrast, existing solutions are limited by either costly test-time training, as with ZipLoRA, or produce lower-quality outputs, as with conventional merging strategies
LoRA Dataset Generation
To train our hypernetwork, we first build a dataset of LoRAs. Content LoRAs are trained on individual subjects from the DreamBooth dataset [4], and style LoRAs are trained on various styles from the StyleDrop / ZipLoRA datasets [5, 6]. Each LoRA is generated via the DreamBooth protocol. We split the LoRA dataset into training {$L_c^{train}$},{$L_s^{train}$}, validation{$L_c^{val}$},{$L_s^{val}$}, and test {$L_c^{test}$},{$L_s^{test}$} sets.
Hypernetwork Structure
Our hypernetwork, $H$, takes two LoRA update matrices as inputs: $ΔW_c$ for content and $ΔW_s$ for style, and predicts column-wise merging coefficients $m_c$,$m_s$. Given the high dimensionality of each update matrix, flattening them directly as input would be impractical. To address this, we assume that the merging coefficient for each column can be predicted independently. Our hypernetwork uses two input layers (to handle inputs of different sizes) with ReLU non-linearities and a shared output layer to predict merging coefficients for each column.
Hypernetwork Training
We train the hypernetwork $H$ by sampling content-style LoRA pairs from the training set {$L_c^{train}$},{$L_s^{train}$}. The hypernetwork generates merging coefficients, which are then used to compute a merging loss $L_{merge}$ that updates the weights of $H$. We discover that the merging loss $L_{merge}$ of [5], which was originally proposed to optimize the merging coefficients for a specific subject-style LoRA pair at test time, could be repurposed more effectively to optimize the weights of the hypernetwork $H$ instead. This novel application produces better merging coefficients and promotes generalization to any new subject-style LoRA pair. The merging loss includes terms that ensure both content and style fidelity, while also encouraging orthogonality between content and style merging coefficients.
Experiments
Setup
Baselines. We compare our approach to several established methods, including: joint training of both content and style via Dreambooth [4]; direct merging of LoRA weights [7]; general model merging techniques such as DARE [9], TIES [8], and DARE-TIES [1]; and ZipLoRA [5], which is specifically designed for merging subject and style LoRAs. In all cases, we use the SDXL v1 [3] model, following the setup in [5].
Datasets. Our hypernetwork is trained on a set of LoRAs rather than images. The datasets used to train the LoRAs include 30 subjects and 26 styles. We split the subjects and styles into training, validation, and testing splits, yielding a total of 360 subject-style LoRA combinations for hypernetwork training, a quantity shown to be sufficient for robust performance.
Evaluation. We evaluate performance via 1) Multimodal Large Language Models (MLLMs); 2) Human evaluation. The MLLM judge assesses if each generated image meets the specified style and content independently, and we only give a score of 1 if both criteria are met (otherwise 0). Human evaluation is performed on a subset of generated images, comparing LoRA.rar with ZipLoRA, the primary competitor. We consider two cases: 1) randomly select one generated sample from each approach for every test content-style LoRA pair; 2) take a best sample, i.e. accepted by the MLLM model.
Quantitative Analysis
MLLM evaluation results are presented in Table 1. Our solution consistently outperforms all methods, including ZipLoRA, in both content and style accuracy. For the best sample (selected by MLLM from 10 generated images as one with correct style and content if available), both our solution and ZipLoRA achieve perfect accuracy, indicating users can reliably choose preferred outputs when multiple samples are available. Across all generated images, on average, our solution performs better than ZipLoRA, likely benefitting from its capacity to leverage knowledge learned from diverse content-style LoRA combinations. The human evaluation results in Figure 3 also indicate our solution compares favorably with ZipLoRA, confirming our generated images are typically either better or comparable in quality. Furthermore, our solution can operate in real-time for new subject-style combinations, unlike ZipLoRA.
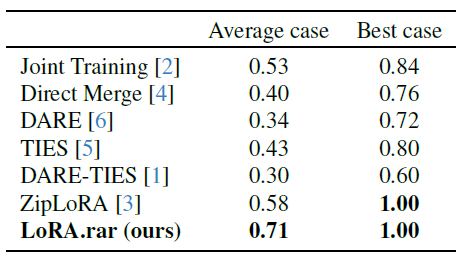
Table 1. MLLM Evaluation on SDXL. Ratio of generated images with the correct content and style on the combinations of test subjects and styles. Our solution leads to better images compared to existing approaches

Figure 3. Human Evaluation for generated images sampled randomly or according to the MLLM judge. More than 75% respondents consider LoRA.rar comparable or better than ZipLoRA
Qualitative Analysis
Qualitative comparison against the state of the art is shown in Figure 4. The results demonstrate that LoRA.rar excels in capturing fine details across various styles, consistently producing high-quality images. While ZipLoRA also generates high-quality images, LoRA.rar outperforms it in terms of overall fidelity to both content and style. A limitation of ZipLoRA is in too realistic generation, e.g., the teapot in 3D rendering style is immersed in a photorealistic scene, and the wolf plushie in oil painting does not resemble a painting. Other approaches show less consistent results, typically either the style or the concept is incorrect, or both.

Figure 4. Qualitative Comparison. LoRA.rar generates better images than other merging strategies, including ZipLoRA
Additional Analyses
Resource Usage is analysed in Table 2. Our findings highlight the efficiency and scalability of LoRA.rar in comparison to ZipLoRA: (1) Runtime Efficiency: our solution generates the merging coefficients over 4000× faster than ZipLoRA on a GPU, achieving real-time performance, making it suitable to run on resource-constrained devices. While ZipLoRA requires 100 training steps for each concept-style pair, LoRA.rar generates merging coefficients in a single forward pass (per layer) using a pre-trained hypernetwork. (2) Parameter Storage: ZipLoRA needs to store the learned coefficients for every combination of concept and style for later use. LoRA.rar only needs to store the hypernetwork, which has 3× fewer parameters than a single ZipLoRA combination. (3) Sample Efficiency: on average, LoRA.rar requires fewer attempts than ZipLoRA to produce a high-quality image that aligns with both content and style—2.28 attempts for LoRA.rar versus 2.55 for ZipLoRA. This improvement reflects LoRA.rar’s enhanced accuracy in generating visually coherent outputs without extensive retries, further optimizing resource usage and user experience. (4) Memory Consumption at Test Time: LoRA.rar is efficient in terms of memory, which is dominated by the generative model (∼15GB), with negligible overhead for our approach, while ZipLoRA requires additional 4GB (∼19GB in total).
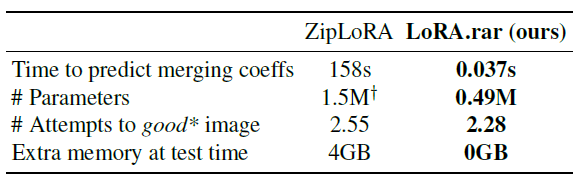
Table 2. Footprint Analysis. LoRA.rar is more than 4000× faster and uses 3× fewer parameters than ZipLoRA, despite using a hypernetwork. *: a good image is accepted by MLLM judge. †: value for one subject-style pair only
Analysis of Merging Coefficients learned by LoRA.rar is shown in Figure 5. LoRA.rar learns a non-trivial adaptive merging strategy, with diverse coefficients. This adaptability allows LoRA.rar to flexibly combine content and style representations, likely contributing to its superior performance.
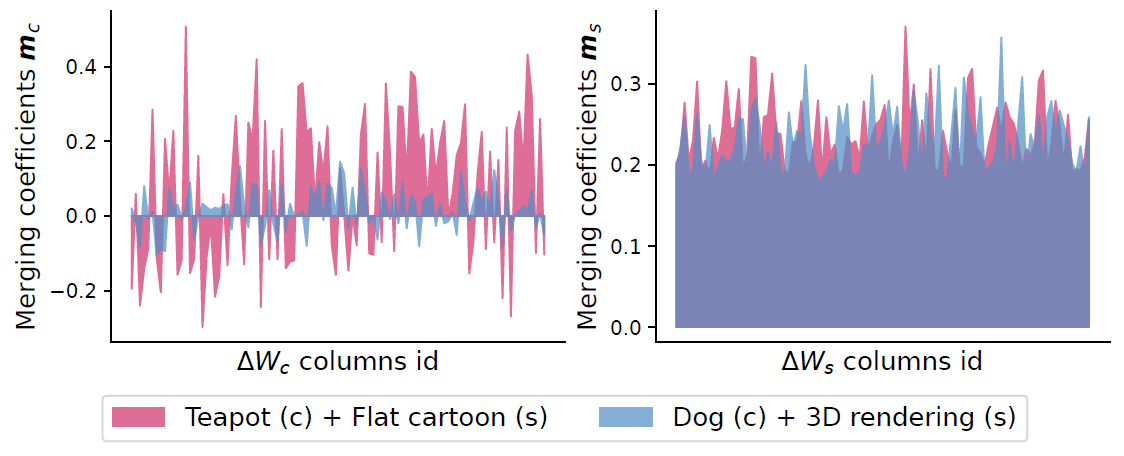
Figure 5. LoRA.rar’s Merging Coefficients for randomly selected columns of the LoRA weight update matrices. LoRA.rar learns a non-trivial strategy with superior performance
Conclusion
In this work, we introduced LoRA.rar, a novel method for joint subject-style personalized image generation. LoRA.rar leverages a hypernetwork to generate coefficients for merging content and style LoRAs. By training on diverse content-style LoRA pairs, our method can generalize to new, unseen pairs. Our experiments show LoRA.rar consistently outperforms existing methods in image quality. Crucially, LoRA.rar generates the merging coefficients in real time, bypassing the need for test-time optimization used by state-of-the-art methods. As a result, LoRA.rar is a method that is highly suitable for deployment on resource-constrained devices such as smartphones.
References
[1] Charles Goddard, Shamane Siriwardhana, Malikeh Ehghaghi, Luke Meyers, Vladimir Karpukhin, Brian Benedict, Mark McQuade, and Jacob Solawetz. Arcee’s mergekit: A toolkit for merging large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, 2024.
[2] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2021.
[3] Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M¨uller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. In International Conference on Learning Representations, 2024.
[4] Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023.
[5] Viraj Shah, Nataniel Ruiz, Forrester Cole, Erika Lu, Svetlana Lazebnik, Yuanzhen Li, and Varun Jampani. Ziplora: Any subject in any style by effectively merging loras. In European Conference on Computer Vision, 2024.
[6] Kihyuk Sohn, Lu Jiang, Jarred Barber, Kimin Lee, Nataniel Ruiz, Dilip Krishnan, Huiwen Chang, Yuanzhen Li, Irfan Essa, Michael Rubinstein, Yuan Hao, Glenn Entis, Irina Blok, and Daniel Castro Chin. Styledrop: Text-to-image synthesis of any style. In Advances in Neural Information Processing Systems, 2023.
[7] Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, et al. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In International Conference on Machine Learning, 2022.
[8] Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. Ties-merging: Resolving interference when merging models. In Advances in Neural Information Processing Systems, 2024.
[9] Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. Language models are Super Mario: Absorbing abilities from homologous models as a free lunch. In International Conference on Machine Learning, 2024.





