AI
Efficient Compositional Multi-tasking for On-device Large Language Models
Introduction
Adapter parameters [2] provide a mechanism to modify the behaviour of machine learning models and have gained significant popularity in the context of large language models (LLMs) and generative AI. These parameters can be merged to support multiple tasks via a process known as task merging. However, prior work on merging in LLMs, particularly in natural language processing, has been limited to scenarios where each test example addresses only a single task. In our work, we focus on on-device settings and study the problem of text-based compositional multi-tasking, where each test example involves the simultaneous execution of multiple tasks, as illustrated in Figure 1. For instance, generating a translated summary of a long text requires solving both translation and summarization tasks concurrently. To facilitate research in this setting, we propose a benchmark comprising four practically relevant compositional tasks. We also present an efficient method (Learnable Calibration) tailored for on-device applications, where computational resources are limited, emphasizing the need for solutions that are both resource-efficient and high-performing. Our contributions lay the groundwork for advancing the capabilities of LLMs in real-world multi-tasking scenarios, expanding their applicability to complex, resource-constrained use cases.
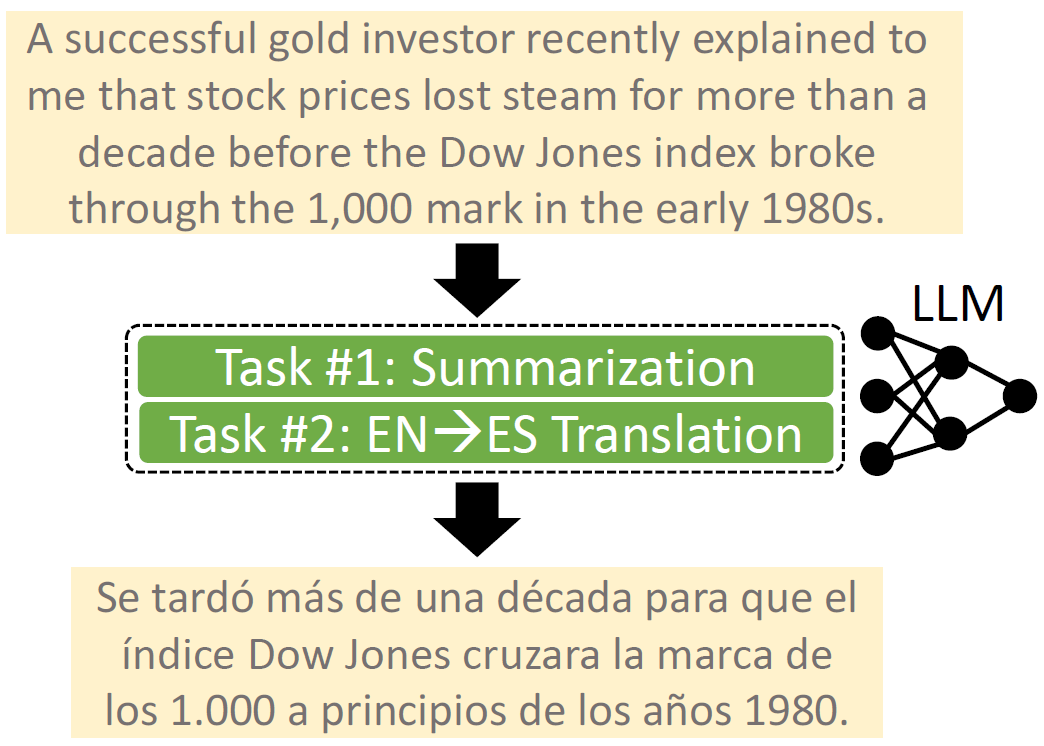
Figure 1. Compositional multi-tasking involves performing multiple tasks simultaneously, such as summarization and translation. The challenge lies in executing all tasks jointly within a single inference pass for optimal efficiency, rather than performing them separately through multiple inferences
Our Benchmark
We focus on the novel problem of enabling compositional multi-tasking in on-device LLMs, which requires a suitable benchmark that includes data for both training and evaluation. To facilitate research in this domain, we develop a benchmark targeting practically valuable compositional tasks. Specifically, our benchmark includes four task combinations: summarization and reply suggestion (often referred to as “smart reply”) as the main task $T_1$, combined with translation or tone adjustment (i.e., rewriting) as the auxiliary task $T_2$. We provide an overview of the benchmark in Figure 2. A generic task $T$ maps an input text x to an output text y; i.e., $T(⋅):x↦y$. For instance, $x$ may represent a long text or part of a conversation, with the goal of producing a summary or an appropriate reply in a specific language or tone. In general, $N$ tasks can be used, for which the compositional task would be defined as $T_{[N]}^C (x)=T_N (…T_2 (T_1 (x)))$, where
$T_N (…T_2 (T_1 (x))):x↦y_1↦y_2↦⋯↦y_N.$
Input $x$ is first processed by $T_1$ to produce $y_1$, $T_2$ subsequently transforms $y_1$ into $y_2$, etc. We primarily use $N=2$.

Figure 2. Overview of the four compositional tasks in our benchmark. The tasks include three translation settings (English to Spanish, French, and German) and four tone variations (professional, casual, witty, and neutral paraphrase), leading to fourteen sub-tasks overall
Our benchmark features three translation settings (English to Spanish, French, or German) and four tone adjustments (professional, casual, witty, and paraphrase), resulting in fourteen sub-tasks in total. Existing summarization and dialogue datasets were repurposed for compositional multi-tasking using specialized models. Evaluation is performed via ROUGE scores (text overlap) and LLM judge ratings (%, ↑).
Our Method: Learnable Calibration
Our setup assumes there is a shared compressed LLM (with e.g. 1B parameters) and one LoRA [3] adapter per each specific task on the device (with each LoRA containing e.g. 30M parameters and consuming e.g. 50MB of disk space). We would like to efficiently combine these adapters to achieve excellent performance on compositional tasks. Existing approaches that can be used for compositional multi-tasking in on-device LLMs are either inefficient or have low performance, as we show in our analysis. How can we achieve both efficiency and good performance so that we can target on-device applications where computational resources and storage are restricted? We propose a new method that addresses this challenge. In particular, we develop an efficient solution that achieves comparable or superior performance to inefficient baselines, such as the multi-step application of adapters or a new adapter trained specifically for each compositional task (referred to as a “joint-expert” adapter).
Our Learnable Calibration starts by computing an average of the relevant single-task LoRAs, which are then corrected via a few calibration parameters. In our basic version of Learnable Calibration, we use a vector of column-wise biases that are shared across all layers. This variation introduces relatively fewer parameters (e.g., 23K), but is less expressive. Learnable Calibration++ uses calibration low-rank matrices instead. It has more parameters (e.g., 166K) and is more expressive, leading to better performance. Our two variations of Learnable Calibration are illustrated in Figure 3. The Learnable Calibration parameters are trained on data from compositional tasks during server-side pre-training. The parameters are deployed to the device where they specify how to combine the single-task LoRAs already available on the device.
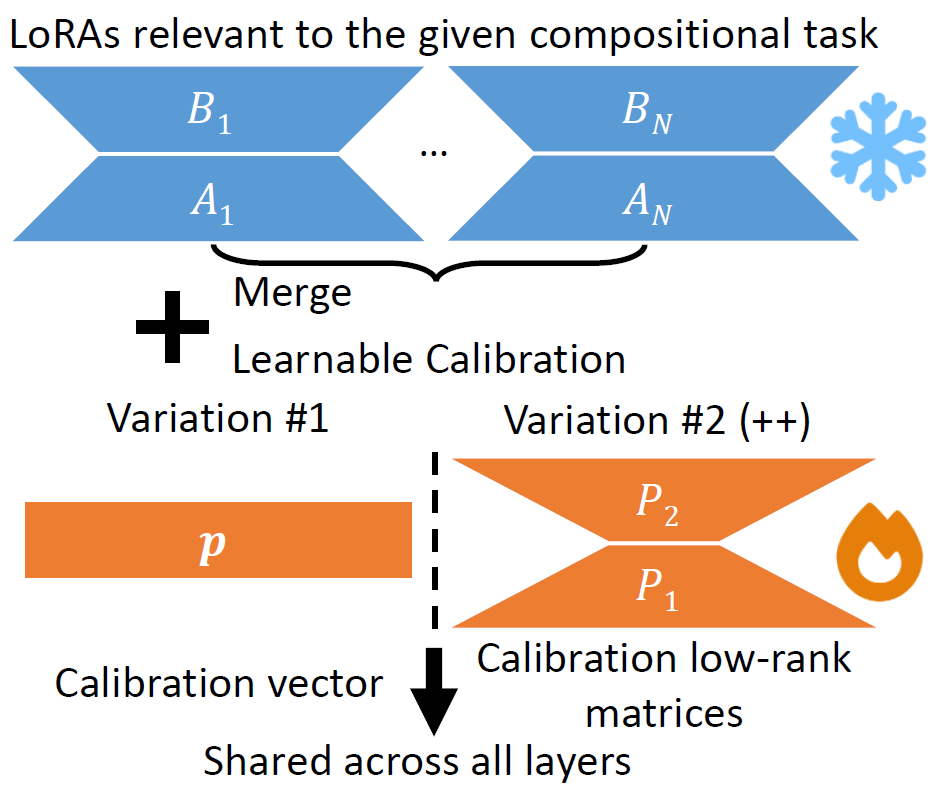
Figure 3. Our Learnable Calibration. We add a small number of calibration parameters to correct the initial merged LoRAs. Variation #1 uses a calibration vector of biases, while Variation #2 (++) uses two calibration low-rank matrices
Experimental Evaluation
We use models that are suitable for on-device settings and more specifically have between 1B and 1.6B parameters. We report the average scores across three models as well as all languages or tones in Table 1. We see our Learnable Calibration outperforms simple baselines and various merging strategies, both data-free (e.g. TIES [5]) and data-driven (e.g. LoraHub [4]). Its performance is similar to inefficient but strong baselines: multi-step LoRA usage and joint-expert LoRA. We also see the more expressive Learnable Calibration++ performs better than its more basic variation. LLM judge scores indicate our approach obtains strong performance on the compositional tasks in general. Further, our analysis shows calibration parameters can be shared across tasks but with worse performance.
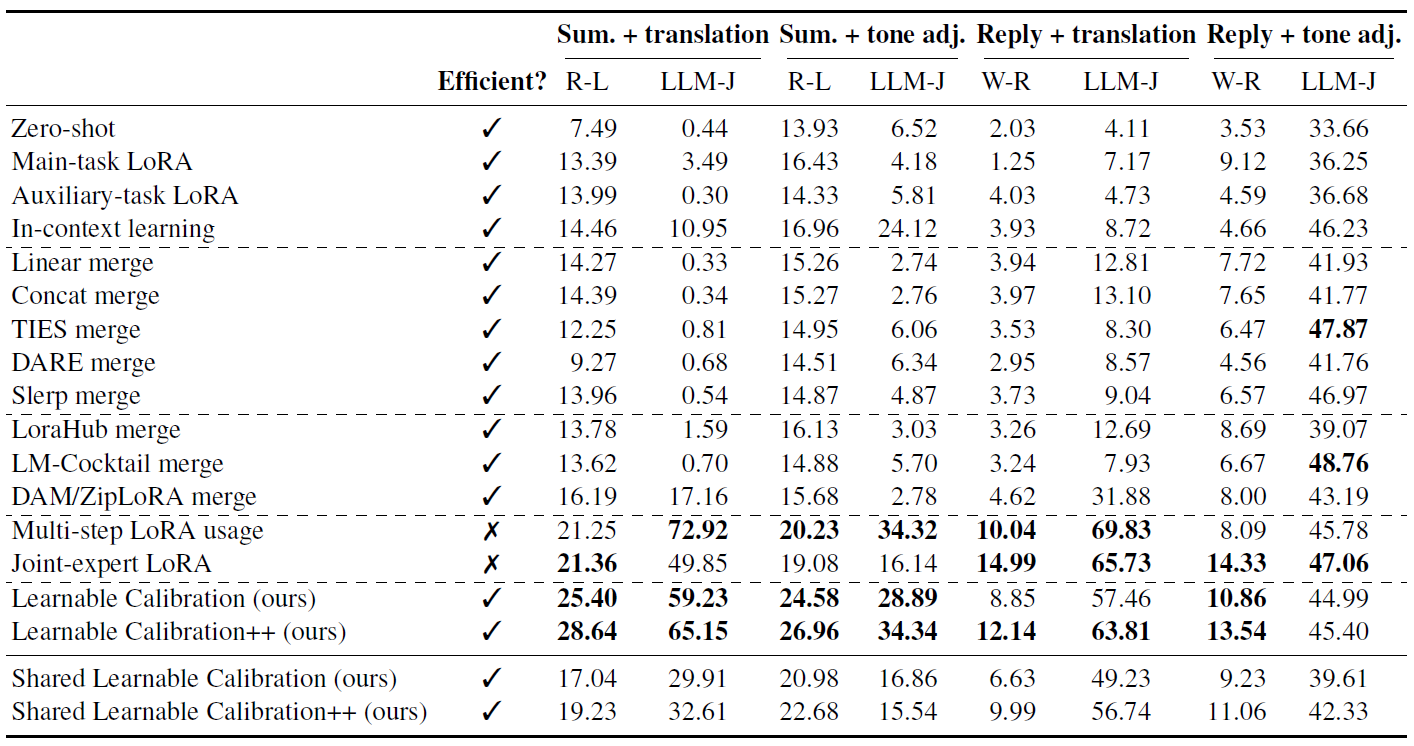
Table 1. Benchmark of compositional multi-tasking. Test results reported as % (↑) and averaged across models and languages or tones. Our Learnable Calibration methods achieve comparable performance to inefficient baselines while being significantly more efficient in terms of inferences and storage. Similarly, fast baselines, such as various merging strategies, typically fail in compositional multi-tasking. The metrics include ROUGE-L (R-L), Weighted ROUGE (W-R) and LLM judge (LLM-J) scores. The Efficient? column captures both runtime and storage efficiency. The bottom block includes results for a version of Learnable Calibration where additional parameters are shared across all four tasks. The best three methods from the main set of results are in bold
We compare the efficiency of our solutions against the two well-performing but inefficient baselines in Table 2. Our solutions require only a minimal number of additional parameters, amounting to approximately 0.08–0.56% of the parameters of a joint-expert LoRA. The resulting additional storage on disk is less than 0.5 MB, making our solutions suitable for on-device deployment.
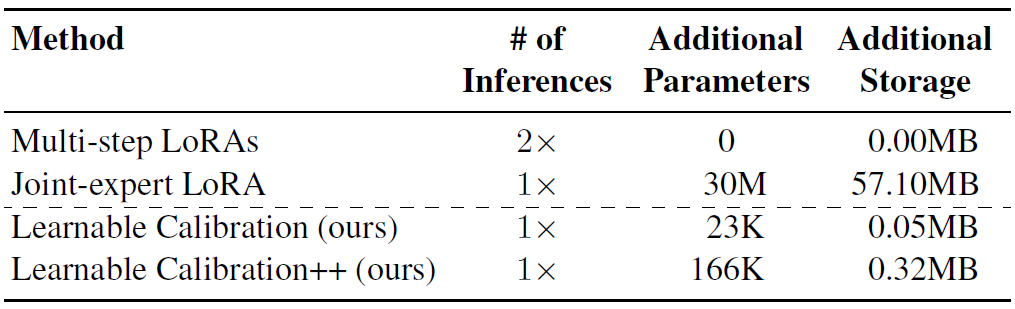
Table 2. Efficiency of well-performing approaches. Our methods require only 0.08–0.56% of additional parameters / storage, depending on the variation (averaged across models). Baselines not reported here, such as Main-task LoRA and Linear Merge, are efficient (i.e., single inference pass, zero additional parameters / storage) but have significantly lower performance
On-device Demonstration
To better showcase and investigate compositional multi-tasking for on-device use cases, we have developed an application that performs compositional multi-tasking fully on-device. We built the back-end in Rust and the front-end in React Native, utilizing mistral.rs [1] package for LLM and adapter management. The application focuses on summarization of conversations in another language, which is one of the multiple practical use cases of compositional multi-tasking. Screenshots of the application are included in Figure 4.
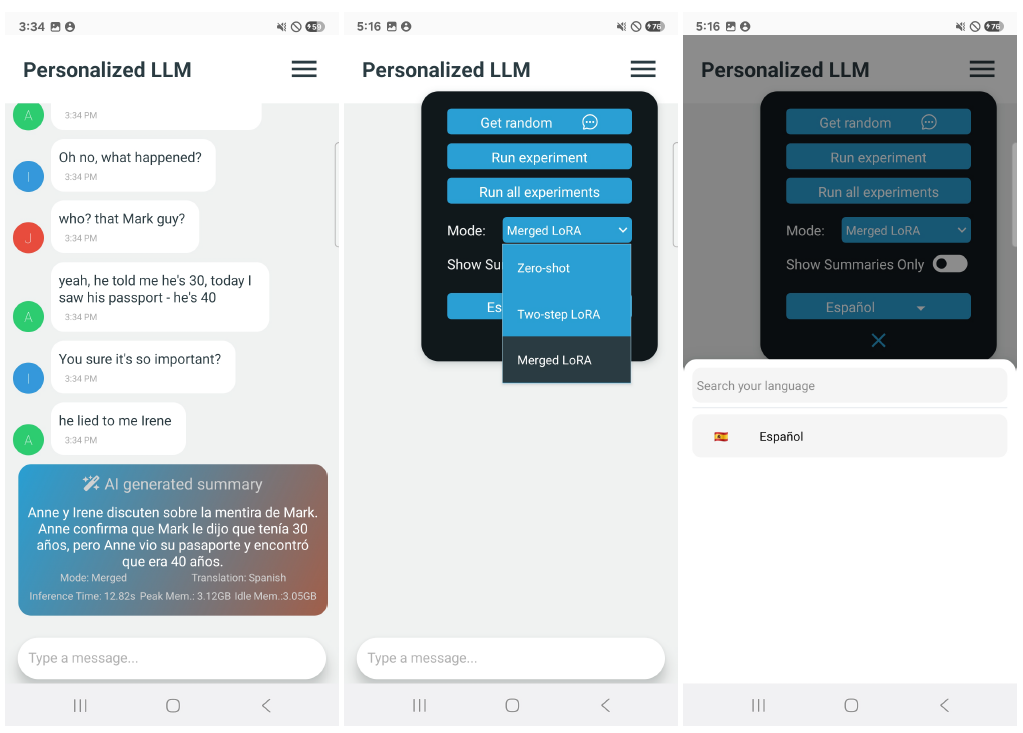
Figure 4. The application runs entirely on a Samsung Android device, without sending data to remote servers. The screenshots show (i) a generated summary in another language, (ii) configuration menu, (iii) language selection
Conclusion
We introduced the practically valuable problem of compositional multi-tasking for LLMs in on-device settings, where computational and storage resources are constrained. To facilitate research in this area, we developed a comprehensive benchmark comprising diverse practical compositional tasks. Our evaluation demonstrates that existing methods either lack efficiency or fail to achieve adequate performance, highlighting the need for new approaches. As a solution, we proposed Learnable Calibration, a family of methods that leverage pre-existing adapters on a device and calibrate them with a minimal number of additional parameters, achieving strong performance while being efficient in both storage and computation.
References
[1] Eric L. Buehler. mistral.rs: A rust implementation of mistral models. https://github.com/EricLBuehler/mistral.rs, 2025.
[2] Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-efficient fine-tuning for large models: A comprehensive survey. In TMLR, 2024.
[3] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In ICLR, 2022.
[4] Chengsong Huang, Qian Liu, Bill Yuchen Lin, Tianyu Pang, Chao Du, and Min Lin. Lorahub: Efficient cross-task generalization via dynamic lora composition. In COLM, 2024.
[5] Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. Ties-merging: Resolving interference when merging models. In NeurIPS, 2024.




