AI
PIX-TAB: Efficient PIXel-Precise TABle Structure Recognition Approach with Speculative Decoding and Region-Based Image Segmentation
Introduction
Tables serve as a fundamental means of organizing and presenting structured information in various documents, including scientific papers, financial reports, web pages. Automatic recognition of table structures, including rows, columns, and cell relationships, is crucial for information extraction, data analysis, and document understanding [1, 2]. In this paper, we introduce an efficient PIXel-precise TABle structure recognition (PIX-TAB) approach with speculative decoding and region-based image segmentation (Fig. 1) inspired by MTL-TabNet architecture. A key advantage of our approach is that it gives precise, pixel-level structure using a small and fast neural network capable of on-device execution, while staying flexible: adding support for new language simply requires replacing the Optical Character Recognition (OCR) model without any modifications to the core structure recognition model.
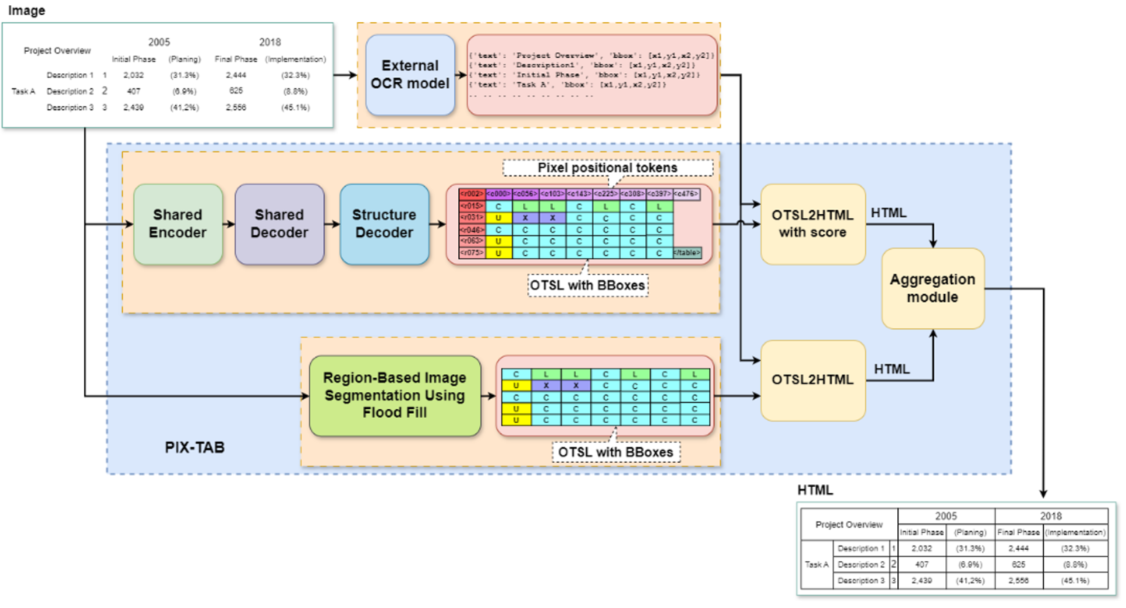
Figure 1. The overview of the proposed approach.
Our contributions are summarized as follows:
Overview
The proposed PIX-TAB approach consists of four parts:
Position-Aware Pixel-Precise Tokens
To enable deterministic reconstruction of table cells, we extended the structured OTSL representation [4] by adding explicit row- and column-position tokens. Thus, for a normalized table image of size X×Y, the position aware pixel-precise (PAPP) tokens are constructed as follows:
These PAPP tokens are mixed with four structural OTSL tokens: ''C'' (cell), ''L'' (left-looking), ''U'' (up-looking), ''X'' (cross).
We did not employ ''NL'' token from the original OTSL because the start of a new row is already indicated by <rYYY> token. In addition to that, we terminate the sequence with the </table> token to mark the end of the table. As it can be seen from Fig.2, the proposed table representation is considerably more compact than the equivalent HTML markup. It is only marginally larger than a pure OTSL representation due to the inclusion of the first row tokens.
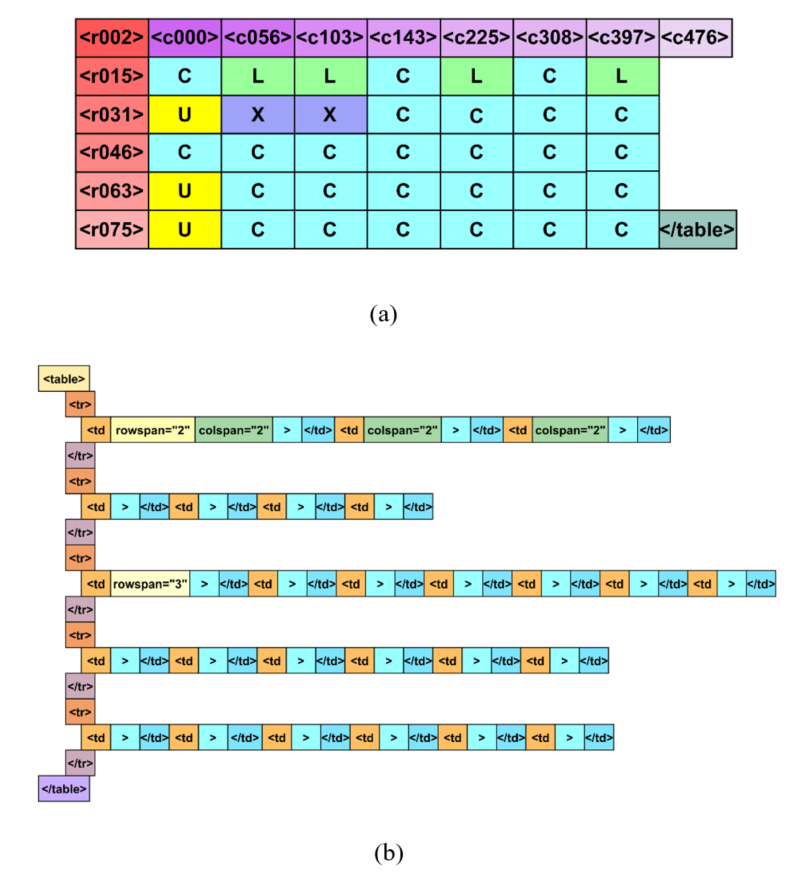
Figure 2. Comparison of table representation in (a) our proposed PAPP and OTSL tokens; (b) HTML tokens for the same table.
Model Architecture
The detailed architecture of the encoder-decoder model is presented in Fig. 3.
The encoder-decoder model consists of four main components:
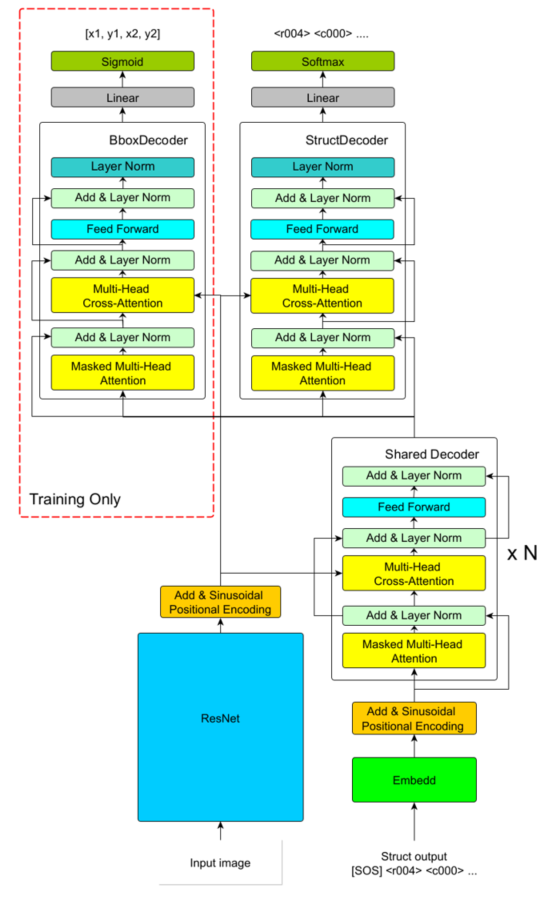
Figure 3. Encoder-decoder model architecture
Speculative Decoding
Due to the specifics of the TSR and use of the PAPP-OTSL tokens instead of bounding boxes during inference, we can generate hypotheses for speculative decoding [5] with an analytical algorithm instead of using another decoding model. The PAPP-OTSL sequences are highly regular across rows. We exploit this regularity to suggest a sequence of future tokens and reduce the number of decoder steps. Our decoder fills the table row by row. After the first row there are no <cXXX> tokens. Each next row starts with <rYYY>, following by the sequence of the OTSL tokens. Together, this makes it possible to suggest a sequence of future tokens with simple rules, without running any extra neural network. Fewer decoder steps means lower latency.
The speculation itself is pure token-level manipulation with a computational cost of O(K×Ncols) per trigger without extra model calls. In practice this operation is negligible compared with a single decoder step, yet it often removes a lot of decoder steps for regular tables.
Region-Based Image Segmentation
While the encoder-decoder model (EDM) serves as the primary method for TSR in our system, it often struggles with large tables that have complex layouts – a scenario that is very common in real enterprise documents. To address this limitation we introduced a region-based image segmentation (RBIS), which handles such tables more effectively. Our approach employs the EDM as the primary method and runs the RBIS in parallel for tables that have complete borders. Both methods output detected cells in HTML format; the final result is chosen by comparing the two outputs.
The algorithm exhibits time complexity of O(n×m) where n and m are the image dimensions, as each pixel is visited exactly once. Space complexity is also O(n×m) due to the visited matrix and worst-case breadth-first search queue.
Experiments and Results
Metrics
The table recognition performance of a method on a test set is defined as the mean of the TEDS scores between the recognition result and ground truth of each sample. While TEDSstruct provides a reliable measure of structural similarity, its high average score can mask the fact that many individual tables still contain one or more structural errors. To address these shortcomings we introduce an additional metric TEDSstruct100 that report the proportion of tables where the entire structure is recognized perfectly (100% recognition of the table structure) on the test dataset. The idea of calculating TEDS100 is the same, except that OCR accuracy is taken into account.
Experimental Results
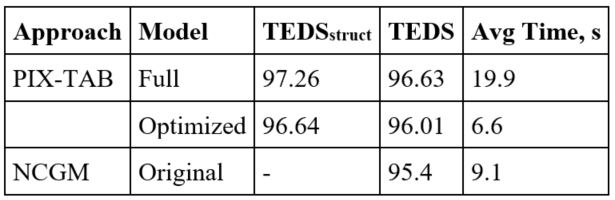
The evaluation of the proposed approach was performed on two benchmark test datasets FinTabNet and PubTabNet. We conducted experiments with addition of SynthTabNet dataset to compare results with our proposed method of data generation (referred as Synth). As we can see from Tab. 1, our approach yields performance improvements, confirming that any synthetic data enrichment effectively mitigates the inherent limitations of the original dataset, and the proposed metric TEDS100 demonstrates its consistency and relevance. Also, as part of the experiments, a comparison between the full and optimized for mobile device versions of the models was conducted. The comparison was performed on a Galaxy Z Fold 5 with a Qualcomm Snapdragon 8 Gen 2 chipset running the Android operating system. The results definitively demonstrate that the optimized version of the model, despite a slight decrease in accuracy, operates significantly faster than the full model. We also performed the comparison with the NCGM [4]. PIX-TAB model shows improved accuracy and recognition time (Tab. 2).
Table 1. PIX-TAB evaluation results.

Table 2. PIX-TAB performance evaluation on mobile device (PubTabNet).
Conclusions
In conclusion, this paper introduces an efficient PIX-TAB approach that combines position-aware pixel-precise tokens, an encoder-decoder model, speculative decoding, region-based image segmentation, and a hybrid selection strategy to achieve accurate and fast TSR. Our method stands out for its ability to deliver precise, pixel-level structure using a compact and fast neural network suitable for on-device deployment, while remaining language-agnostic – support for new languages is achieved by simply swapping the OCR model. Experimental results validate each component. The research strongly confirms the efficiency of the region-based image segmentation approach. Specifically, for the MarketingStyle part of the SynthTabNet, TEDSstruct100 increases from 56.14 % to 57.59 %, and TEDS100 rises significantly from 35.08 % to 45.61 %. Incorporating synthetically generated tables to the training data further enhances performance, increasing TEDSstruct from 95.2 % to 95.5 % and TEDS from 89.3 % to 89.6 % for PubTabNet. Furthermore, the model optimized for mobile devices demonstrated remarkable speed gains, achieving 3.66x and 3.01x faster performance for FinTabNet and PubTabNet, respectively, with only a marginal loss in accuracy.
References
[1] Nam Ly and Atsuhiro Takasu. An end-to-end multi-task learning model for image-based table recognition. In Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, page 626–634. SCITEPRESS - Science and Technology Publications, 2023.
[2] Lei Hu and Shuangping Huang. Enhancing table structure recognition via bounding box guidance. In Pattern Recognition, pages 209–225, Cham, 2025. Springer Nature Switzerland.
[3] Weihong Lin, Zheng Sun, Chixiang Ma, Mingze Li, Jiawei Wang, Lei Sun, and Qiang Huo. TSRFormer: Table structure recognition with transformers. In Proceedings of the 30th ACM International Conference on Multimedia, page 6473–6482, New York, NY, USA, 2022. Association for Computing Machinery.
[4] Maksym Lysak, Ahmed Nassar, Nikolaos Livathinos, Christoph Auer, and Peter Staar. Optimized table tokenization for table structure recognition. In Document Analysis and Recognition - ICDAR 2023, pages 37–50, 2023.
[5] Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. In Proceedings of the 40 th International Conference on Machine Learning, Honolulu, Hawaii, USA, 2023. Association for Computational Linguistics.