AI
LAFUFU: Latent Acoustic Features for Ultra-Fast Utterance Restoration
1. Introduction
Speech (utterance) restoration is the task of recreating high-fidelity speech from imperfect recordings degraded by noise, reverberation, and other distortions. Such problems have been addressed by classical and neural signal processing methods [21], but their reliance on fixed statistical assumptions limits generalization to varied acoustic conditions.
In recent years, generative diffusion models have been shown to be remarkably effective in this domain, demonstrating leading performance on various benchmarks [9]. By modelling the distribution of clean speech conditioned on corrupted inputs, they produce natural, intelligible reconstructions. However, while effective, these models typically operate on high-dimensional sound representations and require lengthy iterative sampling, resulting in high computational costs that hinder real-time or edge deployments [10]. This challenge is especially acute for high-definition 48kHz audio, where spectrograms are considerably larger and each denoising step becomes significantly more expensive.
In this blog post, we present LAFUFU — a novel approach to the utterance restoration problem leveraging latent-space acoustic representations. Rather than performing the diffusion process on raw audio spectrograms, LAFUFU operates on compact features extracted by a bespoke autoencoder. Utilizing those dedicated latent representations enables significant inference speedups without sacrificing output quality — a critical advantage for high-definition audio processing. We also show that, given equivalent time constraints, LAFUFU is capable of producing higher-quality restored utterances than the classical non-latent alternatives, as evidenced by its competitive performance on the EARS-WHAM and EARS-Reverb 48kHz frontier benchmarks.
The remainder of this post is structured as follows. We first provide the necessary background on score-based generative models and latent space diffusion. We then describe the LAFUFU methodology in detail, followed by a presentation of our experimental results. We discuss the implications of our findings, compare them with prior work, and conclude with a summary and outlook on future directions.
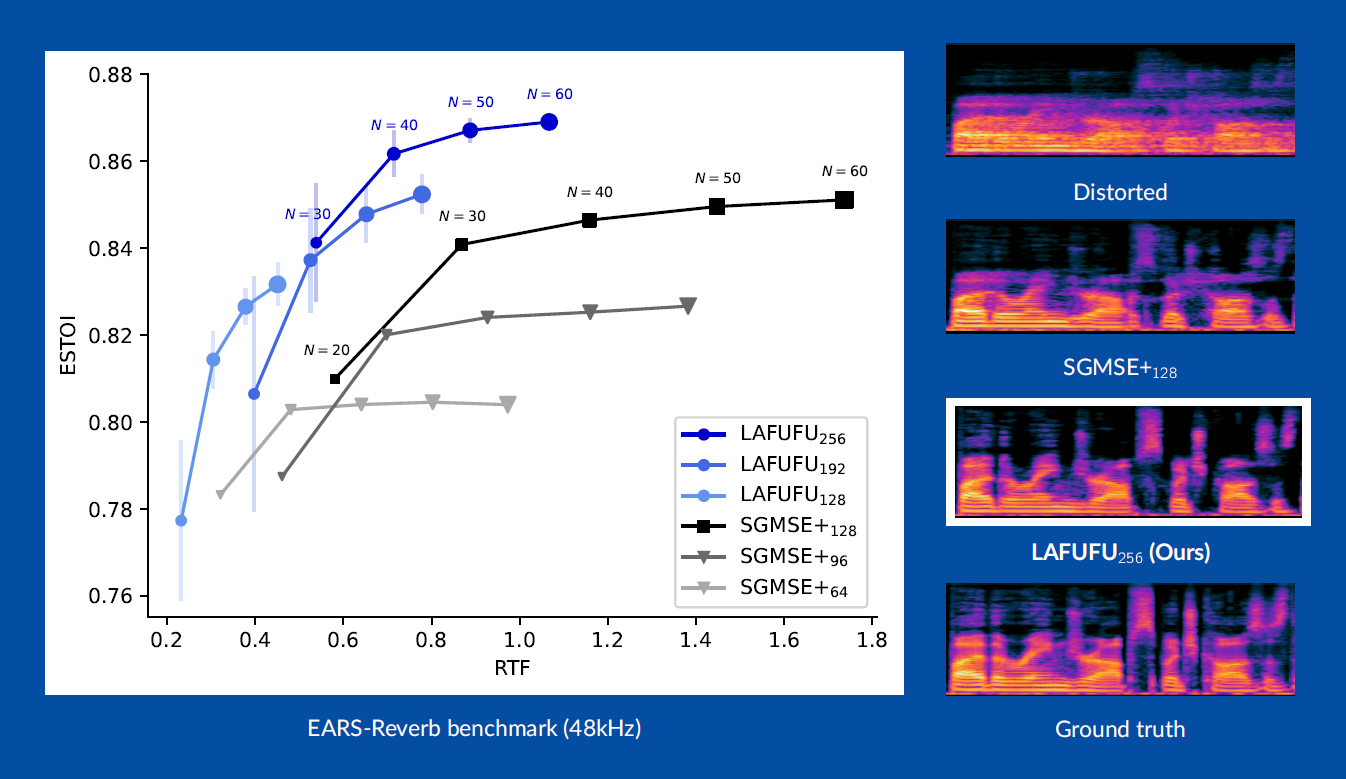
Figure 1. Results overview.
2. Background
Problem formulation
Let us define the distorted recording as the sum $Y= \cal{A}(X)+\cal{N}$, where $X$ denotes the original clean speech, while $\cal{A}$ and $\cal{N}$ represent degradations caused by the external environment. $\cal{A}$ could take the form of a convolution operator $X ∗ H$, where $H$ is e.g. a room impulse response. The additive term $\cal{N}$ is typically interpreted as background noise. The aim of the utterance restoration task is to recreate $X ′ ≈ X$ from said noisy $Y$. For the purpose of this work, all variables are represented as complex tensors storing the short-time Fourier transform (STFT) coefficients [2].
Score-based generative models
The restoration task can be effectively recast as a conditional generation problem, enabling adaptation of existing generative frameworks [4]. Given their strong benchmark performance, we focus on approaches employing mean-reverting stochastic differential equations (SDEs) [5]. For our baseline analysis, we selected SGMSE+ [11], a proven score-based model using noise-conditional score networks, as it represents a well-established solution in this methodological family.
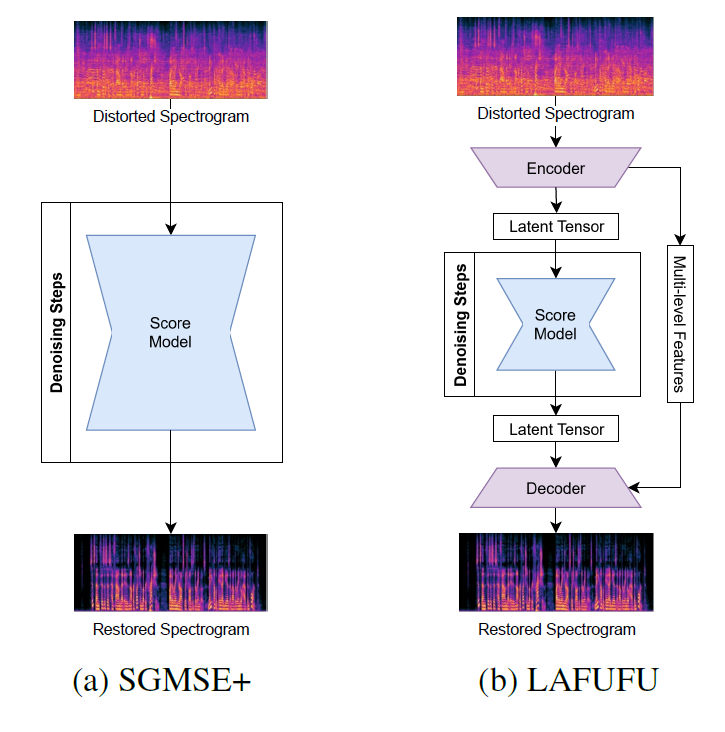
Figure 2. Denoising architectures.
SGMSE+ sees the result synthesis mechanism as the inverse complement of a certain diffusion process, defined by the following forward SDE:
$ dX_t=f(X_t,Y)dt+g(t)dw $
where $w$ is a standard Wiener process [7], $f$ is a drift function, $g$ is a diffusion coefficient, $t ∈ [0, T]$, and $X_t$ denotes the current state of the working variable (with $X_0= X$). In practice, this forward procedure gradually transforms the initial clean speech sample X into its distorted counterpart, while simultaneously perturbing it with Gaussian noise.
This process can be run backwards in time (therefore recreating the original audio) by utilizing the associated reverse SDE [1] (where w̄ is a reverse-time Wiener process):
$ dX_t=[-f(X_t,Y)+ g(t)^2 ∇_{X_t} log p_t (X_t|Y)]dt+g(t)dw̄ $
The $∇_{X_t} logp_t (X_t |Y)$ term, where $p_t$ denotes the conditional probability density, known as the score, cannot be calculated without prior knowledge of the target $X$. Fortunately, it can be replaced by a learnable parametrised approximation $ s_θ (X_t,Y,t)$ (e.g., in the form of a multi-resolution deep U-Net). Thus, the restoration workflow boils down to: initialising $X_t=Y+ N(μ,σ²)$ (with mean $μ$ and variance $σ²$), dividing the [0, T] interval into N discrete steps (not to be confused with the noise term $N$ above), employing a suitable numerical solver, and iterating back through the SDE. As a consequence, the operational core of SGMSE+ consists mainly of the looped denoising steps, which in turn rely heavily on repeated calls to the neural score model $s_θ$.
Latent space diffusion
The main disadvantage of previous mean-reverting SDEs is their iterative, multi-stage enhancement process, which requires significant computational resources. This limitation makes them impractical for real-time applications or resource-constrained environments. A common solution involves transferring the diffusion process from high-dimensional input space to a compact latent space using pretrained variational autoencoders (VAEs) [12]. However, while suitable VAEs exist for general tasks like image generation, they are often unavailable for specialized domains with scarce data. To address this, recent work in image restoration introduced Refusion [6], a simplified, task-specific autoencoder tailored for enhancement needs.
3. Methodology
LAFUFU is a unified lightweight technique that combines the expressive strength of the SGMSE+ model with the efficiency gains provided by the latent-space diffusion paradigm. Rather than running diffusion on full spectrograms, it operates on compact features produced by a bespoke autoencoder — designed and trained from scratch specifically for speech restoration.
Architecture
Our method adapts the Refusion autoencoder (AE) for STFT-based speech processing by treating time and frequency as spatial dimensions. To handle complex numbers, we encode real and imaginary components as separate image channels. Given the sparsity of STFT spectrograms and the varied scales of voice-related features, we replace the typical L1 loss with a multi-resolution STFT loss (MRSTFT) [13] for superior perceptual reconstruction quality. The AE architecture is simplified by using a U-Net with only two down/upsampling blocks — a reduction from the base Refusion's three — due to spectrograms having significantly lower resolution than high-definition images.
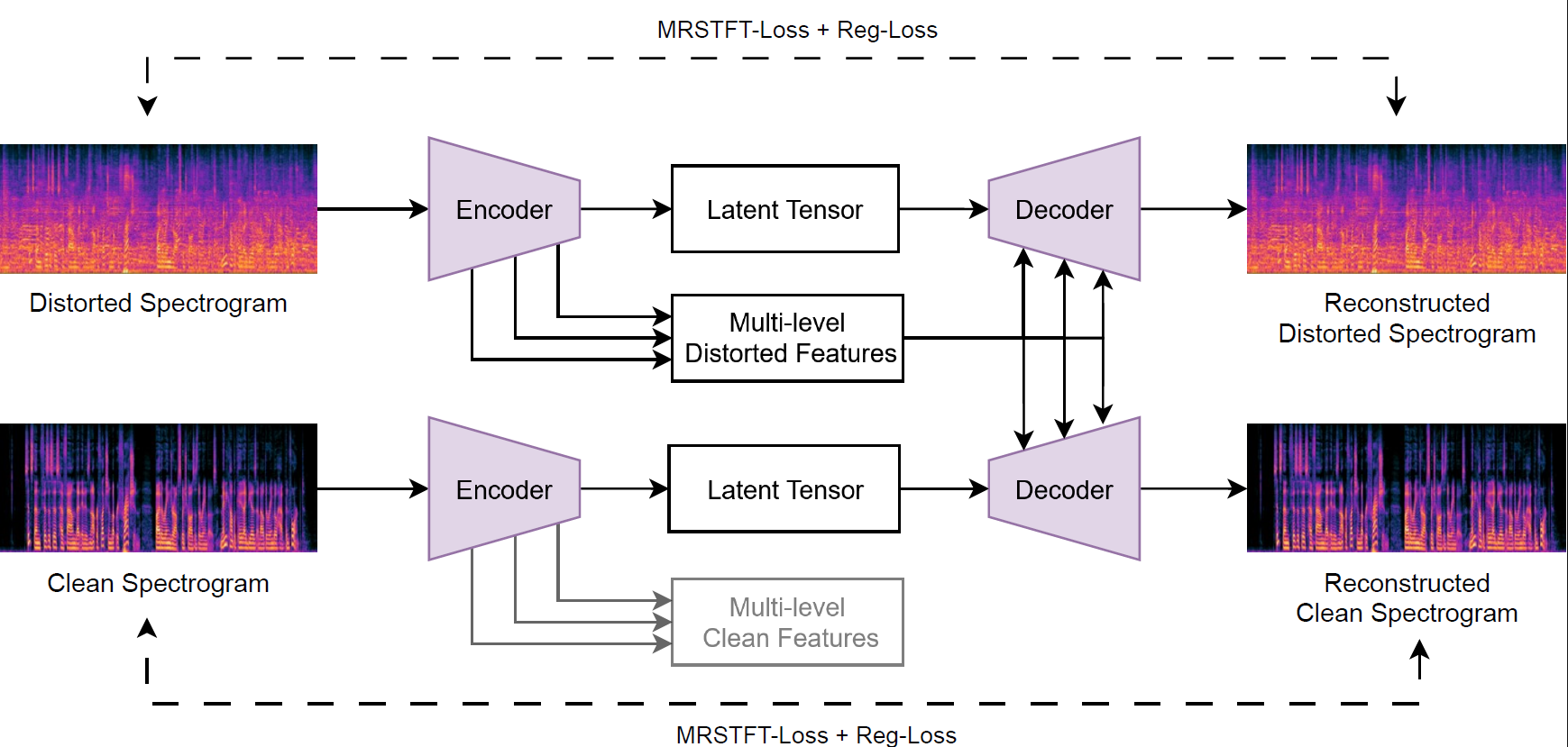
Figure 3.
We retain the original Reg-Loss mechanism, which penalizes embeddings that diverge significantly from the input's statistical properties, as it effectively prevents fragmentation of the latent space into discontinuous hash-like encodings. Formally, Reg-Loss is implemented as:
$ RegLoss(Z_Y,Y)=|μ_(Z_Y )-μ_Y |+|σ_{Z_Y}- \frac 12 σ_Y | $
where $Z_Y$ is the latent embedding of a distorted sample, while μ and σ denote the mean and standard deviation of the given tensor elements.
We follow Luo et al. [6] in employing their latent-replacement approach, where the decoder constructs the output using multi-level features from the distorted input (always available in restoration tasks). This allows the latent tensor to focus solely on encoding the necessary modifications rather than the complete target signal, avoiding the challenge of representing high-entropy components and resulting in a more efficient and robust AE architecture.
For the generative diffusion core, we closely follow the standard SGMSE+ architecture to ensure performance gains stem specifically from our latent-centric approach rather than score model modifications. We only remove its first and last layers, as their raw feature preprocessing is now handled by the autoencoder.
Experimental setup
Computational inefficiencies of diffusion methods become more evident when dealing with high-resolution audio, due to noticeably larger input resolutions. Thus, we decided to focus on audio recordings sampled in 48kHz and utilise EARS-WHAM and EARS-Reverb benchmark datasets [14] as the chief diagnostic tools.
For each sub-benchmark, we trained a matching pair consisting of an AE and a score model. Our primary objective was to evaluate whether latent domain diffusion could achieve performance parity with the original SGMSE-class models. To systematically assess this, we implemented latent score models with varying channel configurations (128×, 192×, and 256× per-block channel multiplier), naming them respectively LAFUFU₁₂₈, LAFUFU₁₉₂, and LAFUFU₂₅₆. These models were benchmarked against publicly available SGMSE+ checkpoints, with the smallest one used as a reference point for the ablation study. Additionally, to investigate the effect of model size reduction on output quality, we trained scaled-down SGMSE+ with 64× and 96× channel counts.
Our input preprocessing pipeline and score model training recipe were consistent with prior work [14]. The AE optimization employed MRSTFT loss weight of 1.0 combined with a 0.1-weighted Reg-Loss term. MRSTFT covered eight window lengths (32, 64, 128, 256, 512, 1024, 1534, and 2048 samples), each paired with a ¼ length hop size.
To rigorously evaluate model performance, we employed SI-SDR, PESQ, ESTOI, and DNSMOS for quality assessment alongside real-time factor (RTF) as a computational efficiency measure. Inference was performed utilising the predictor-corrector setup inherited from prior work [14]. To mitigate random initialization effects, we performed three independent training runs for each experimental condition on both EARS-WHAM and EARS-Reverb datasets. Results present mean values, mean standard deviations, and metric-wise standard deviations across all repetitions. All discussed procedures were conducted on a single NVIDIA A100 GPU.
4. Results
EARS-WHAM benchmark
The table and plots below present the results on the EARS-WHAM benchmark (speech denoising task):
Table 1. EARS-WHAM benchmark results.
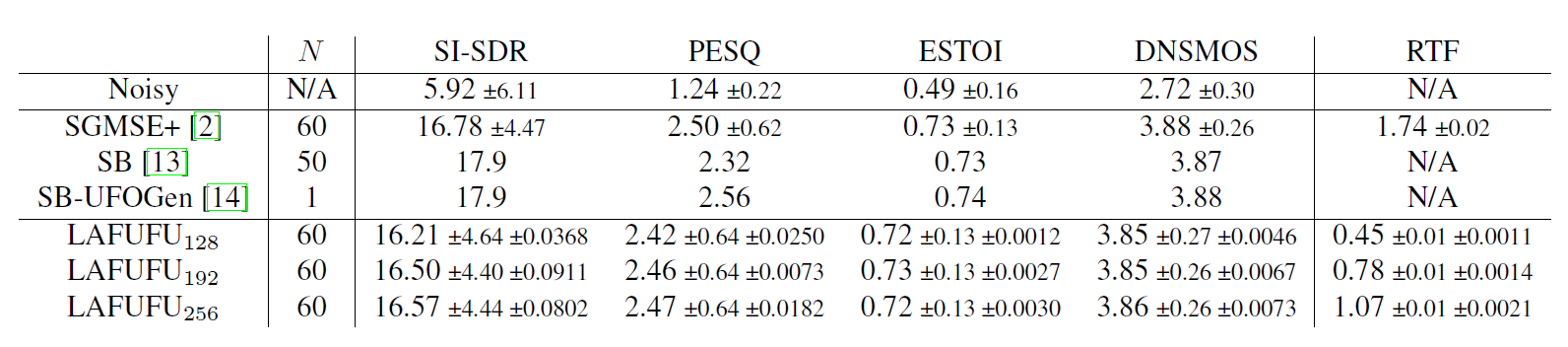
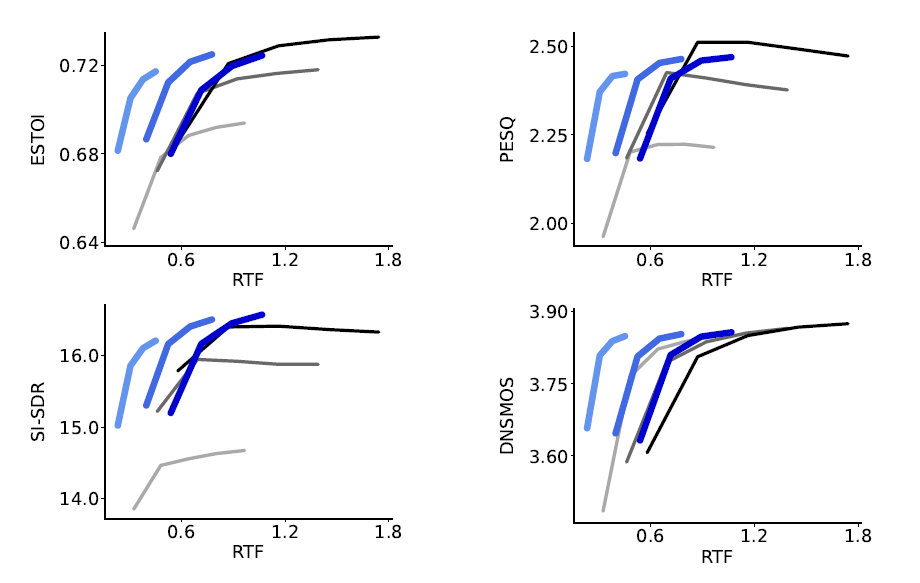
Figure 4. Relation between speech restoration quality and inference speed (EARS-WHAM benchmark).
EARS-Reverb benchmark
The table and plots below present the results on the EARS-Reverb benchmark (speech dereverberation task):
Table 2. EARS-Reverb benchmark results.
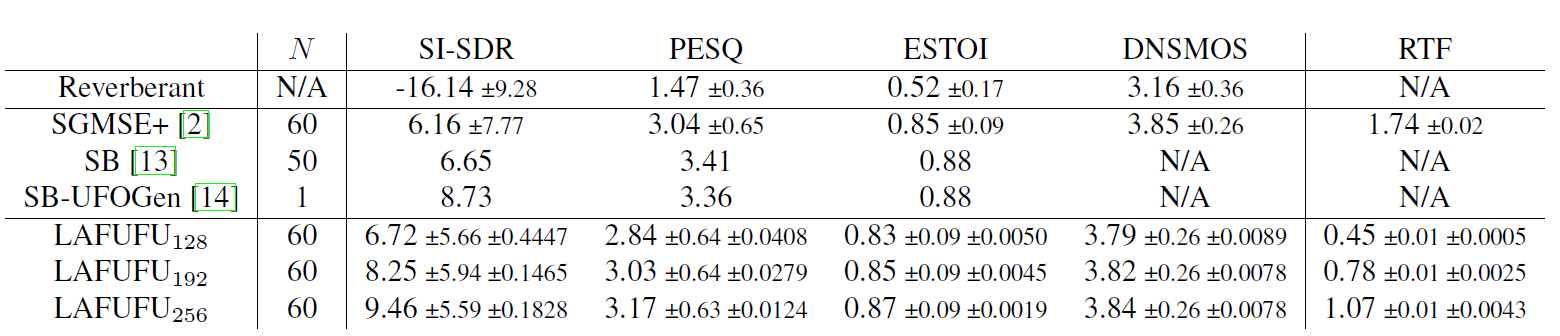
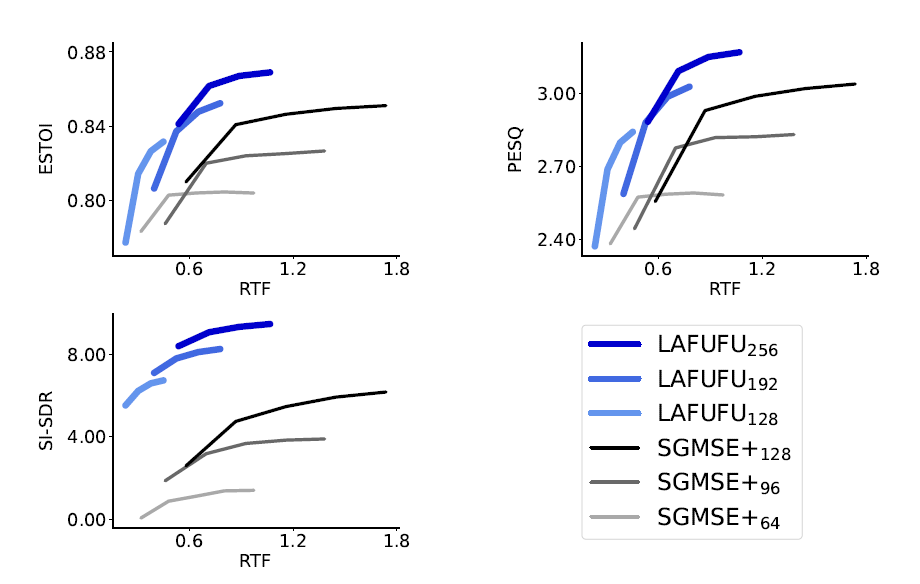
Figure 5. Relation between speech restoration quality and inference speed (EARS-Reverb benchmark).
5. Discussion
The gathered experiment outcomes confirmed that performing iterative denoising in the condensed latent space leads to multifold improvements in inference speed — a result of particular significance for high-definition 48kHz audio, where the computational burden of operating on full spectrograms is most acute. The enhanced performance enables scaling up score model sizes beyond previous architectural limits, yielding better output quality at lower real-time factor (RTF) targets. This is particularly evident on the EARS-Reverb benchmark, where LAFUFU not only surpasses its SGMSE+ foundation but also achieves state-of-the-art comparable evaluation scores.
These results highlight representation learning as a key enabler for unlocking generative diffusion potential in audio applications, suggesting further progress is achievable via this research avenue.
Ablation study
We conducted an ablation study on the EARS-Reverb benchmark to assess the contribution of individual architectural components:
Table 1. Ablation study results (EARS-Reverberant benchmark).

Removal of the encoder-decoder hidden connections resulted in marginal decrease across all evaluation metrics, but offered no tangible gains in inference RTF. Thus, while not critical, their influence was deemed as overall beneficial.
Attempts at suspending the Reg-Loss component revealed its crucial role in the AE framework, as all models trained without it exhibited substantial performance degradation. Our empirical evidence suggests that preserving the statistical properties of the original space in its latent representation is fundamental for maintaining robustness of the dependent score models.
Comparison with prior work
Score-based generative diffusion has already been applied to the complex STFT domain [16] and demonstrated effective for speech enhancement. Those successes inspired a plethora of follow-up studies [4], with contemporary ones exploring Schrödinger bridge formulation [9] or hybridising with an adversarial network [3]. Latent diffusion techniques, initially introduced for HD image synthesis [12], found adoption in multiple sound-adjacent scenarios, such as text-to-audio generation [8] or editing [17]. In the context of utterance restoration, latent space embeddings started gaining traction in the past year, seeing use as an auxiliary mechanism in multi-stage enhancement pipelines [18], a part of transformer-based solutions [19], or an enabler for a dual-context conditional diffusion model [20]. However, none of those studies focused on the latency tradeoffs critical for real-time use cases. LAFUFU fills this gap by demonstrating that a bespoke, task-specific latent space can achieve competitive quality with multifold improvements in inference speed.
Limitations and future work
The primary drawback of this approach stems from its dual-model architecture, which increases memory demands and parameter complexity. However, we argue that LAFUFU's advantages outweigh these limitations, establishing latent-driven methods as a viable direction for speech enhancement research.
Link to the paper
ICASSP 2026 Paper: LAFUFU: Latent Acoustic Features For Ultra-Fast Utterance Restoration | IEEE Conference Publication | IEEE Xplore
Demo page: https://samsunglabs.github.io/LAFUFU/
References
1. Anderson, B. D. O. (1982). Reverse-time diffusion equation models. *Stochastic Processes and their Applications*, 12(3), 313–326.
2. Fu, S.-W., Hu, T.-Y., Tsao, Y., & Lu, X. (2017). Complex spectrogram enhancement by convolutional neural network with multi-metrics learning. *2017 IEEE 27th International Workshop on Machine Learning for Signal Processing (MLSP)*, 1–6.
3. Han, S., Lee, S., Lee, J., & Lee, K. (2025). Few-step Adversarial Schrödinger Bridge for Generative Speech Enhancement. *Interspeech 2025*, 2380–2384.
4. Lemercier, J.-M., Richter, J., Welker, S., Moliner, E., Välimäki, V., & Gerkmann, T. (2025). Diffusion models for audio restoration: A review. *IEEE Signal Processing Magazine*, 41(6), 72–84.
5. Luo, Z., Gustafsson, F. K., Zhao, Z., Sjölund, J., & Schön, T. B. (2023a). Image restoration with mean-reverting stochastic differential equations. arXiv:2301.11699.
6. Luo, Z., Gustafsson, F. K., Zhao, Z., Sjölund, J., & Schön, T. B. (2023b). Refusion: Enabling large-size realistic image restoration with latent-space diffusion models. *Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition*, 1680–1691.
7. Malliaris, A. G. (1990). Wiener process. In *Time Series and Statistics* (pp. 316–318). Springer.
8. Liu, H., Chen, Z., Yuan, Y., Mei, X., Liu, X., Mandic, D., Wang, W., & Plumbley, M. D. (2023). AudioLDM: Text-to-Audio Generation with Latent Diffusion Models. arXiv:2301.12503.
9. Nasretdinov, R., Korostik, R., & Jukić, A. (2025). Robust Speech Recognition with Schrödinger Bridge-Based Speech Enhancement. *ICASSP 2025*, 1–5.
10. Richter, J., de Oliveira, D., & Gerkmann, T. (2025). Investigating Training Objectives for Generative Speech Enhancement. *ICASSP 2025*.
11. Richter, J., Welker, S., Lemercier, J.-M., Lay, B., & Gerkmann, T. (2023). Speech enhancement and dereverberation with diffusion-based generative models. *IEEE/ACM Transactions on Audio, Speech, and Language Processing*, 31, 2351–2364.
12. Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. *Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition*, 10684–10695.
13. Yamamoto, R., Song, E., & Kim, J.-M. (2020). Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram. *ICASSP 2020*, 6199–6203.
14. Richter, J., Wu, Y.-C., Krenn, S., Welker, S., Lay, B., Watanabe, S., Richard, A., & Gerkmann, T. (2024). EARS: An anechoic fullband speech dataset benchmarked for speech enhancement and dereverberation. arXiv:2406.06185.
15. Richter, J., & Gerkmann, T. (2024). Diffusion-based speech enhancement: Demonstration of performance and generalization. *Audio Imagination: NeurIPS 2024 Workshop AI-Driven Speech, Music, and Sound Generation*.
16. Welker, S., Richter, J., & Gerkmann, T. (2022). Speech enhancement with score-based generative models in the complex STFT domain. arXiv:2203.17004.
17. Wang, Y., Ju, Z., Tan, X., He, L., Wu, Z., Bian, J., & Zhao, S. (2023). AUDIT: Audio Editing by Following Instructions with Latent Diffusion Models. arXiv:2304.00830.
18. Dhyani, T., Lux, F., Mancusi, M., Fabbro, G., Hohl, F., & Vu, N. T. (2025). High-Resolution Speech Restoration with Latent Diffusion Model. arXiv:2409.11145.
19. Guimarães, H. R., Su, J., Kumar, R., Falk, T. H., & Jin, Z. (2025). DiTSE: High-Fidelity Generative Speech Enhancement via Latent Diffusion Transformers. arXiv:2504.09381.
20. Zhao, S., Pan, Z., Zhou, K., Ma, Y., Zhang, C., & Ma, B. (2025). Conditional Latent Diffusion-Based Speech Enhancement Via Dual Context Learning. arXiv:2501.10052.
21. Lu, X., Tsao, Y., Matsuda, S., & Hori, C. (2013). Speech enhancement based on deep denoising autoencoder. *Interspeech 2013*, 436-440.




