AI
Real-Time Multilingual Video Subtitle Spotting on Resource-Constrained Devices
Introduction
Accurate real-time on-device video subtitles spotting is essential for many applications such as subtitle translation, text-to-speech conversion, video content comprehension. However, most video content providers encrypt or embed subtitles in ways that prevent direct text extraction, necessitating the use of Optical Character Recognition (OCR) for detection and recognition. Current state-of-the-art video text spotting methods are not optimized for real-time operation on edge devices. To address this challenge, we introduce the specialized neural network architectures designed for on-device video content classification, subtitle tracking, detection and recognition. To enhance efficiency, the proposed neural network architectures employs advanced optimization techniques, significantly reducing memory and computational demands while maintaining high real-time performance on TV devices. Through rigorous testing and on-device end-to-end (E2E) evaluation, we achieved an impressive novel state-of-the-art E2E word accuracy of over 97% across seven languages, with a low latency of under 200 ms. The results of this work were commercialized in Audio Subtitles and Live Translate services for Samsung TV devices. The findings hold great potential for extending this technology to other platforms, including IoT devices and digital appliances.
Motivation
The rapid advancement of consumer devices, communication technologies, and video services has led to a significant transformation in how information is consumed by users [1]. Video traffic has become increasingly dominant, having had the strongest growth at 50 percent over the period from 2020 to 2024 [2], as on average, consumers spend about 3.7 hours daily watching online video content. Another global trend is the implementation of video subtitling for content localization, making it accessible to global audiences, and captioning for better accessibility to the media content [3]. According to a recent poll, over half of Americans keep subtitles or closed captions turned on some (21%) or all (34%) of the time, especially younger people [4].
Over the last few decades, the task of text-on-video spotting has gained considerable attention in the fields of computer vision and multimedia processing [5-8] with applications ranging from content indexing to accessibility services. Text spotting from videos involves detection, tracking, and recognizing text that appears naturally within video frames (scene text) as well as overlaid text like subtitles. While substantial progress has been made in video text spotting [9] , the challenge of achieving real-time, high-accuracy on resource-constrained devices remains an open issue. Current solutions generally rely on server-based cloud computing systems, where video data is uploaded to a remote server for processing. These solutions, while effective, are hindered by several drawbacks, including latency, privacy concerns, and dependency on internet connectivity. To overcome these limitations, there is a growing push towards on-device text spotting, where extraction occurs directly on edge computing devices or embedded systems [7, 10]. This approach promises real-time performance, enhanced privacy, reduced latency, and better energy efficiency. The need for on-device text spotting solutions has become particularly critical with the increasing usage of smartphones and other edge devices. These devices are increasingly tasked with real-time video processing, but their limited computational power, storage capacity, and energy constraints present significant challenges for implementing deep learning models capable of robust text detection. While cloud-based systems can leverage large computational resources to process video content with higher accuracy, on-device systems need to strike a balance between efficiency and accuracy. Optimizing these systems for edge devices requires a deep understanding of model compression techniques, hardware-aware algorithms, and efficient resource management.
Despite the essential benefits of text extraction from video content, it is an increasingly challenging task due to the dynamic nature of video streams, varying lighting conditions, complex backgrounds, and text styles. In addition, the implementation of real-time text spotting on a device requires solving several problems caused by limited resources and architectural constraints.
Subtitle text represents a specialized case within text video spotting, characterized by several unique properties: temporal persistence with dynamic changes, high contrast visibility, and often consistent positioning within the video frame. In addition to standard on-device deployment challenges, subtitle text video spotting presents specific difficulties, including: distinguishing subtitles from other textual elements within the video stream, dynamic content handling (managing subtitle text that changes over time while maintaining recognition accuracy), dealing with complex backgrounds, handling artistic or stylized subtitle fonts that deviate from standard text formats, supporting multilingual content. The specialized nature of subtitle video text spotting requires a tailored approach that accounts for these unique characteristics while maintaining robust performance across diverse video content and taking into account the on-device deployment scenario.
This paper presents an in-depth exploration of on-device text spotting solutions, focusing on the methodologies and algorithms that enable real-time subtitle extraction from video content on resource-constrained devices.
Solution Overview
We present here a lightweight on-device real-time solution for subtitle recognition and reading aloud on the fly. It consists of five main components: content classifier, subtitle tracker, text line detector, text recognition engine, and TTS (Fig.1). All components’ architectures are based on the experiments and chosen from the point of the trade-off between accuracy and latency. In addition, we considered their applicability to on-device implementation. The details and structure of all modules are described in the next subsections.
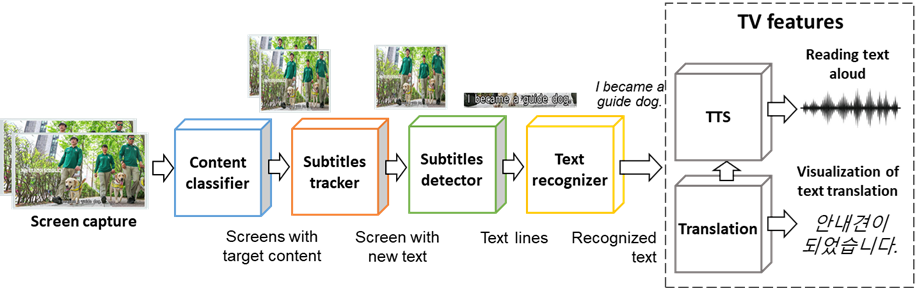
Figure 1. The overview of the proposed video subtitles spotting pipeline
A. Content Classifier
The content classifier module is aimed at the filtration of input video frames. It selects only frames with target content: movies and other entertainment videos with subtitles. The screens with non-target content are skipped. Under non-target content, we consider cases when the screen contains non-subtitle text elements. It corresponds to news, sports, economics, advertisements, and other TV programs. Implementation of this module allows for prevention detection, recognition and sounding of non-subtitle text elements, that very important for correct user experience. This module is based on a lightweight CNN model, which takes as input resized to 300×300 pixels video frame (Fig. 2). This ML model was trained using a specially collected dataset, which contains various examples of screenshots with target (movie, cartoon, entertainment) and non-target (news, sports, advertisements, etc.) content.
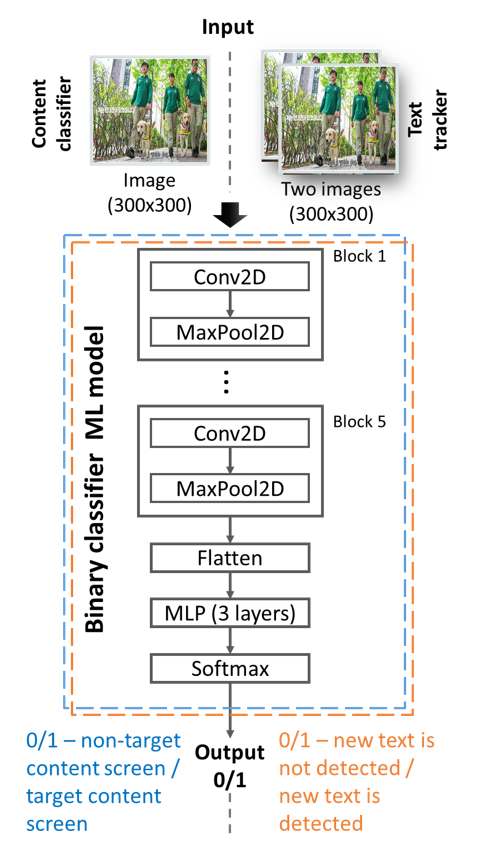
Figure 2. Architecture of Content classifier and Subtitle tracker
B. Subtitle Tracker
The tracking module provides information about the appearance of subtitles of interest in the video. The core of the module is a CNN-based classification model (Fig. 2).
For the subtitle tracking module, it is supposed that the concatenation along the channel axis of the closely sampled time frames is sufficient for the efficient detection of new subtitles. After that, the two consecutive frames are concatenated and fed to the CNN-based classifier. It has a similar architecture as Content Classifier. Tracker was trained on the synthetically generated dataset, which was formed by the following principles:
class 1 (new subtitle detected) corresponds to the case when the first frame does not contain a new subtitle, and a new subtitle is present in the second frame;
class 0 (no new subtitle): all other cases.
C. Subtitle Detector
The text detection module is implemented based on the Single Shot MultiBox Detector (SSD) architecture [11]. The text detector network takes the captured frame image as an input and produces the list of text candidate boxes with the corresponding class confidences (Fig. 3).
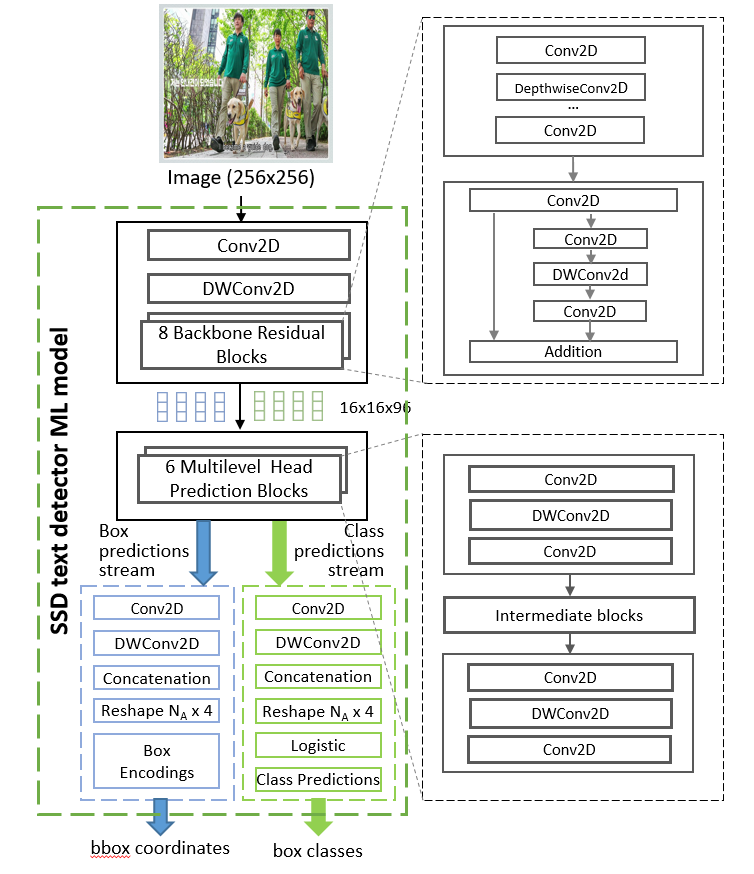
Figure 3. Architecture of text detector
For subtitle text line localization, we employ the SSD (head and predictor) with MobileNetV3 backbone architecture similar to the TextBoxes++ model [12]. This architecture provides one of the most flexible compromises in terms of accuracy and latency. The implementation is based upon works [11] and was trained with quantization-aware training (QAT), which preserves high-quality location results despite rounding errors. Adjusted text line boxes are normalized by a height of 48 pixels, and then are handled by the recognition model.
D. Subtitle Recognition
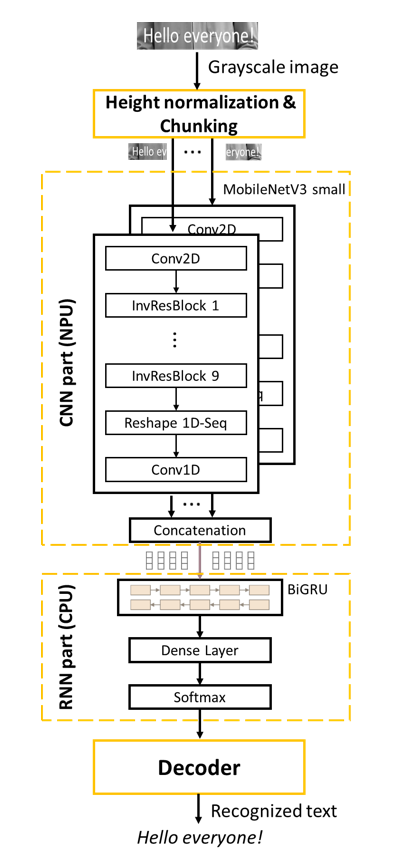
Figure 4. CRNN recognition architecture
There are a great number of DL approaches for image text recognition. Popular encoder models that use attention, such as TransformerOCR [9] are heavily dependent on a resource-exhaustive global attention mechanism, which in the current state of hardware technology, makes them inapplicable for wide use on Edge and mobile devices. CTC-based recurrent models [13] such as CRNN [14] are far more flexible and are especially lightweight, which presents them as primary candidates for effective on-device usage. It is important to note that due to the regular rectangular form of the subtitle text. In our proposed solution, we use CRNN-CTC architecture (Fig. 4) with inference using a probabilistic Language Model and a token-passing algorithm [15].
For grammar correction, the class-based trigram language model is applied. The dictionary of the language model is about 100k words. Both results of the recognition neural network and the language model are linearly weighted in order to produce balanced output results. For the CNN we use MobileNetV3-small architecture without five last layers and modified strides reducing the length of the sequence by eight times along the X-axis.
The input image for our CNN-BiGRU architecture [7] is firstly divided into equal non-overlapping chunks of 48×192 pixels. The feature extraction is performed per chunk and concatenated before it is fed to the BiGRU. It is important to note that in comparison with other sliding window convolutional approaches, our method proposes to use non-overlapping extracted patches, thus forcing the model to use non-repetitive context information from different chunks with zero shared information. It also benefits the execution time by skipping the already-seen part of the input image.
Datasets
To acquire the training data for the DL models in our solution, we utilized synthetic datasets generated using our custom-built data generator. By incorporating open-source video footage and reference information about subtitles (such as text, style, and layout parameters), the generator produces videos and/or images with embedded subtitles along with corresponding annotations. The annotations contain information about the generated subtitles: time, placement, text, and style. This approach was used for dataset formation for training ML models for subtitle tracking, detection and recognition. We use 90/10 division of datasets for training and validation data. For independent testing purposes, we utilized specifically designed videos, which will be discussed in the subsequent section. The datasets are described below:
Experiments and Results
The evaluation of the proposed system was performed on TV sets using specifically designed independent video test sets for six supported languages. Every test set contains 64 videos (five minutes each) with burned-in subtitles in eight different styles. We have selected the most common styles which differ in text color (white/yellow), font (Arial-bold/Courier-bold) and background (black/transparent). Examples of the subtitles with these styles are shown in Fig. 5.
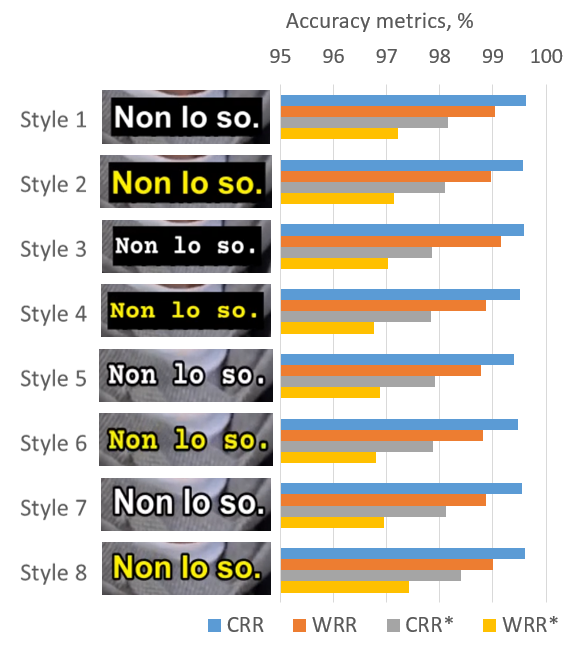
Figure 5. Evaluating subtitle recognition accuracy across diverse styles of subtitle
For the evaluation of subtitle recognition quality, common character and word recognition rate metrics (CRR, WRR) were applied. The punctuation and case information were discarded due to their minimal effect on end-user experience. Also, corresponding E2E metrics (CRR*, WRR*) were estimated. The E2E metrics take into account the performance of all solution modules and fully correspond with the user’s perception and reflect their expectations for the overall performance.
Test results for seven supported languages are presented in Tab. 1. The average WRR* metric for all target languages is 96.17%. This value is consistent with state-of-the-art OCR solution [8]. In addition, we have investigated the influence of different subtitle styles on recognition accuracy (Fig. 5).
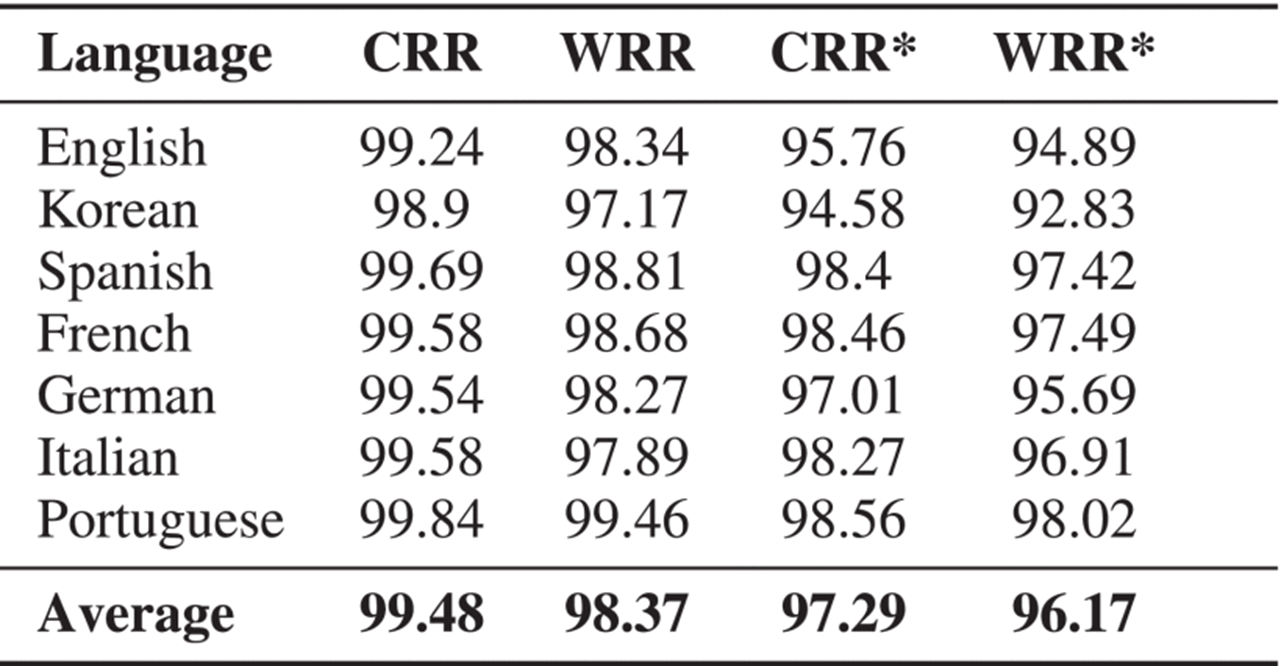
Table 1. On-Device Subtitle Recognition Accuracy Metrics, %
For a comparison of text recognition results, several benchmark on-device solutions were selected: the mobile version of PaddleOCR [16] and EasyOCR [17]. Both chosen OCR solutions are adapted for the edge computing. Using the test set from benchmark dataset [18], we report the recognition results in Tab. 2. Our text recognition model demonstrates the highest recognition accuracy while the model size is five times smaller than that of the competing OCR systems. In addition to the benefit of the proposed approach, this advantage stems from training it specifically on subtitle data, while the other OCR solutions are designed for generic text recognition.
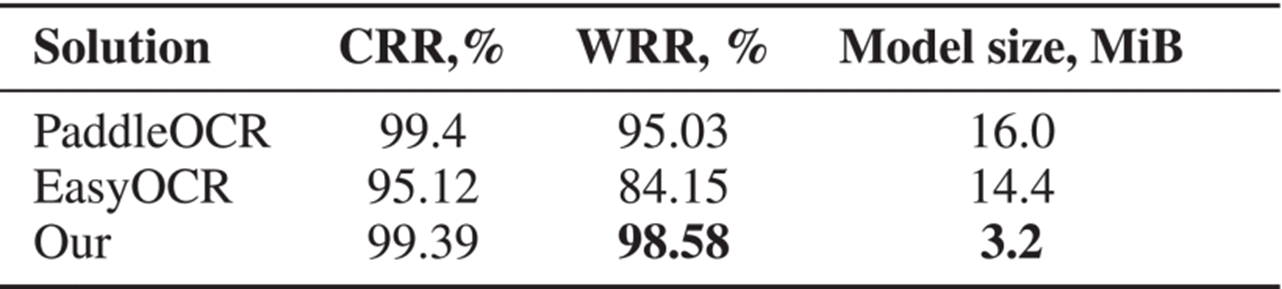
Table 2. Benchmarking of On-Device Text Recognition
E2E latency alongside the corresponding metrics from each module of our solution for the English language are presented in Fig. 6. E2E latency was estimated as a delay between the screen capturing start moment and the moment of obtaining the results of subtitle
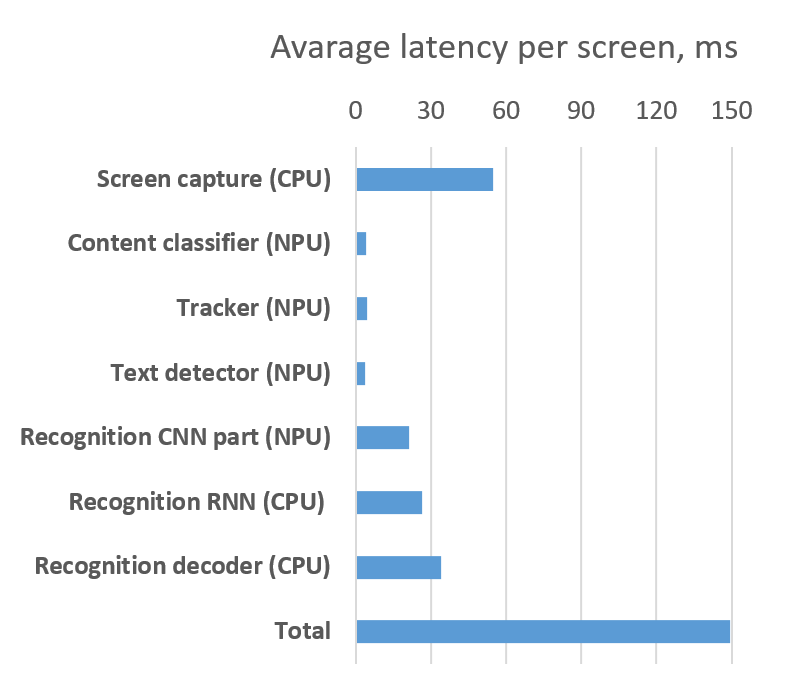
Figure 6. Latency of solution components per screen
For on-device implementation, the computational constraints pose a significant importance regarding CPU usage and memory consumption. The aggregate CPU consumption for all main components (except screen capture) of the solution is less than 0.7%. The average memory consumption does not exceed 24 MB and the peak value is less than 36.5 MB.
Conclusions
In this work, we have presented a computationally efficient approach to on-device subtitles spotting, thus enabling the real-time reading and/or translation of burned-in subtitles. The proposed solution is specifically aimed at alternative audio track synthesis in multiple languages and demonstrates high performance. It is particularly valuable for visually impaired individuals or others who cannot read subtitles displayed on the screen.
The proposed architecture includes several innovative solutions: content classification, subtitle tracking, text line detection and classification, and an optimized recognition engine for on-device deployment. The solution currently supports seven languages: English, Korean, Spanish, Italian, French, German and Portuguese.
E2E on-device performance evaluation demonstrated an average latency of 150 ms, which satisfies the requirements for mouth-to-ear delay for real-time services. At the same time, the achieved average E2E word recognition accuracy of 96.17% in average across all six supported languages establishes a novel state-of-the-art for on-device implementation.
The future directions of video subtitle spotting include the support of new languages, implementing automatic subtitle language classification to provide different scenarios for multilingual content processing, and building the unified framework for both scene text and subtitle processing.
The visual cues derived from the proposed lightweight text detection and content classification modules, combined with consistent tracking history, can serve as a foundation for integration of additional features (facial expressions, scene and speaker content, etc.). It may enable richer semantic understanding and benefit visual and linguistic cohesion during real-time processing for multiple downstream tasks, e.g. content summarization, question answering. etc.
One more point for future development is a multi-modal (OCR + audio) approach for speaker-adaptive subtitles reading. It supposes changing the TTS voice parameters based on information about language, current active speaker, speech tempo and emotions. This will allow to make reading subtitles aloud more natural and informative.
The proposed approach presents promising opportunities for extension to other edge platforms, such as IoT devices and digital appliances. The results delivers new possibilities for video content localization and distribute accessibility for visually impaired users.
References
1. J. K. Chalaby, “The streaming industry and the platform economy: An analysis,” Media, Culture Soc., vol. 46, no. 3, pp. 552–571, Apr. 2024.
2. Ericsson. ( 2025 ). Ericsson Mobility Report Jun. 2025. [Online]. Available: https://www.ericsson.com/en/reports-and-papers/mobility-report/reports/june-2025
3. A. Desai, R. Alharbi, S. Hsueh, R. E. Ladner, and J. Mankoff, “Toward language justice: Exploring multilingual captioning for accessibility,” in Proc. CHI Conf. Human Factors Comput. Syst., 2025, pp. 1–18.
4. E. J. McDonnell, T. Eagle, P. Sinlapanuntakul, S. H. Moon, K. E. Ringland, J. E. Froehlich, and L. Findlater, “Caption it in an accessible way that is also enjoyable,” in Proc. CHI Conf. Human Factors Comput. Syst., 2024, pp. 1–16.
5. C. Y. Lokkondra, D. Ramegowda, G. M. Thimmaiah, A. P. B. Vijaya, and M. H. Shivananjappa, “ETDR: An exploratory view of text detection and recognition in images and videos,” Revue d’Intell. Artificielle, vol. 35, no. 5, pp. 383–393, Oct. 2021.
6. W. Wu, Y. Cai, C. Shen, D. Zhang, Y. Fu, H. Zhou, and P. Luo, “End-to-end video text spotting with transformer,” Int. J. Comput. Vis., vol. 132, no. 9, pp. 4019–4035, Sep. 2024
7. I. Degtyarenko, N. Tkach, O. Radyvonenko, I. Deriuga, K. Seliuk, O. Ivanov, V. Sielikhov, S. Y. Lee, Y.-H. Choi, and C.-H. Hahm, “SDRV: Real-time on-device subtitles detection, recognition and voicing,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. Workshops (ICASSPW), Jun. 2023, pp. 1–5.
8. H. Yan and X. Xu, “End-to-end video subtitle recognition via a deep residual neural network,” Pattern Recognit. Lett., vol. 131, pp. 368–375, Mar. 2020.
9. M. Li, T. Lv, J. Chen, L. Cui, Y. Lu, D. Florencio, C. Zhang, Z. Li, and F. Wei, “TrOCR: Transformer-based optical character recognition with pre-trained models,” in Proc. AAAI Conf. Artif. Intell., Jun. 2023, pp. 13094–13102.
10. I. Degtyarenko, N. Tkach, K. Seliuk, O. Ivanov, and V. Sielikhov, “Electronic device and audio track obtaining method therefor,” U.S. 20 250 166 608 A1, May 22, 2025.
11. W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “SSD: Single shot MultiBox detector,” in Proc. ECCV, 2016, pp. 21–37.
12. M. Liao, B. Shi, and X. Bai, “TextBoxes++: A single-shot oriented scene text detector,” IEEE Trans. Image Process., vol. 27, no. 8, pp. 3676–3690, Aug. 2018.
13. A. Graves, S. Fernandez, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks,” in Proc. ICML, 2006, pp. 369–376.
14. B. Suvarnam and V. S. Ch, “Combination of CNN-GRU model to recognize characters of a license plate number without segmentation,” in Proc. 5th Int. Conf. Adv. Comput. Commun. Syst. (ICACCS), Mar. 2019, pp. 317–322.
15. Z. Chen, M. Jain, Y. Wang, M. L. Seltzer, and C. Fuegen, “End-to-end contextual speech recognition using class language models and a token passing decoder,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), May 2019, pp. 6186–6190
16. C. Cui, T. Sun, M. Lin, T. Gao, Y. Zhang, J. Liu, X. Wang, Z. Zhang, C. Zhou, H. Liu, Y. Zhang, W. Lv, K. Huang, Y. Zhang, J. Zhang, J. Zhang, Y. Liu, D. Yu, and Y. Ma, “PaddleOCR 3.0 technical report,” 2025, arXiv:2507.05595.
17. M. A. M. Salehudin, S. N. Basah, H. Yazid, K. S. Basaruddin, M. J. A. Safar, M. H. M. Som, and K. A. Sidek, “Analysis of optical character recognition using EasyOCR under image degradation,” J. Phys., Conf. Ser., vol. 2641, no. 1, Nov. 2023, Art. no. 012001
18. W. Wu, Y. Cai, D. Zhang, S. Wang, Z. Li, J. Li, Y. Tang, and H. Zhou, “A bilingual, OpenWorld video text dataset and end-to-end video text spotter with transformer,” 2021, arXiv:2112.04888.





