AI
Edge-SD-SR: Low Latency and Parameter Efficient On-device Super-Resolution with Stable Diffusion via Bidirectional Conditioning
|
The Conference on Computer Vision and Pattern Recognition (CVPR) is one of the most prestigious annual conferences in the field of computer vision and pattern recognition. It serves as a premier platform for researchers and practitioners to present cutting-edge advancements across a broad spectrum of topics, including object recognition, image segmentation, motion estimation, 3D reconstruction, and deep learning. As a cornerstone of the computer vision community, CVPR fosters innovation and collaboration, driving the field forward with groundbreaking research. In this blog series, we delve into the latest research contributions featured in CVPR 2025, offering insights into groundbreaking studies that are shaping the future of computer vision. Each post will explore key findings, methodologies, and implications of selected papers, providing readers with a comprehensive understanding of the innovations driving the field forward. Stay tuned as we uncover the transformative potential of these advancements in our series. Here is a list of them. #2. Augmenting Perceptual Super-Resolution via Image Quality Predictors (AI Center - Toronto) #3. VladVA: Discriminative Fine-tuning of LVLMs (AI Center - Cambridge) #5. Edge-SD-SR: Low Latency and Parameter Efficient On-device Super-Resolution with Stable Diffusion via Bidirectional Conditioning (AI Center - Cambridge) #6. DreamCache: Finetuning-Free Lightweight Personalized Image Generation via Feature Caching (Samsung R&D Institute United Kingdom) |
Introduction
Stable Diffusion [1] for Super Resolution (i.e. SD-SR), has been shown to produce steep improvements compared to previous SR approaches. However, deploying large diffusion models on computationally restricted devices such as mobile phones remains impractical due to the large model size and high latency. Considering that SR is most widely used on mobile phones, where the vast majority of photos are taken nowadays, in this work, we focus on the very challenging task of creating a SD-SR model that can run on Edge devices (i.e. Edge SD-SR).
Deploying SD-SR models on such computationally limited devices entails addressing several practical challenges due to the large model size and high latency. These issues are exacerbated for the SR task, as it operates on high-resolution and typically requires multiple model runs. For example, to generate a 4Kx3K image using state-of-the-art models such as StableSR [2] takes around 900 seconds on a high-end GPU (A100), making on-device deployment unfeasible. In this work, we aim to address both model size and latency while maintaining the model's visual quality.
In our work, we adopt prior art when possible, and focus on bridging the remaining gap. In particular, we 1) follow prior work [3] and adopt a pruning and re-training strategy for the UNet (although a more aggressive pruning level is required in our case), 2) use compact variants of the encoder and decoder, which do not boast a large proportion of the parameters, but account for a significant portion of the FLOPs and latency, 3) re-use our previous work [4] to train a 1-step model, which includes a decoder fine-tuning strategy. Despite all these efforts to leverage existing work, the resulting light (~169M parameter) and efficient (~142 GFLOPS) model suffers from a large drop in image quality, as illustrated in Figure 1 (b).
Our Solution: Edge-SD-SR
While it is tempting to attribute such performance drop to the extreme reduction of model capacity (e.g. 850M to 158M params for the UNet) and step count (down to 1 step), we show that in the case of super-resolution, such a drop can be largely mitigated through careful improvements to the optimization strategy. We hypothesize that SR requires less capacity than general text-to-image generation as it generates from an LR image instead of random noise.
To make the most out of the input LR image, we introduce a new conditioning mechanism that takes the low-resolution image into account during both the noising and denoising processes, which we coin bidirectional conditioning. This conditioning provides a better training signal, which allows us to train a very compact diffusion model to a high level of quality. In addition, we extend the training strategy to jointly train a lightweight encoder directly using the diffusion loss, thanks to an asymmetric encoder design and a modified noise sampling schedule. Finally, we combine our approach with the training strategy proposed in our previous work [4] targeting a 1-step SD-SR model, which also allows for directly training a diffusion-aware lightweight decoder tailored to the task of SR. Combined, these contributions yield our model, coined Edge-SD-SR, that can upscale a whole 512×512 image to 2048×2048 on-device (on a Samsung S24 DSP) in just ~1.1 sec while maintaining high quality, as illustrated in Figure 1 (c).

Figure 1. Results of 4× upsampling with (a) interpolation, (b) our architecture with the standard training approach (c) our architecture with our training approach. Samples taken from the DIV2K-RealESRGAN dataset.
Methods Details
Background: Stable Diffusion for Super Resolution
Before delving into the details of our method we begin by giving some background regarding how stable diffusion is used for the task of super resolution. Given pairs of high-res (HR) and low-res (LR) images, $(x_h,x_l)$~$p(x_h,x_l)$, SD first projects images to latent space using an encoder $z_{h/l}=Ɛ(x_{h/l})$. During the training of SD-SR models, the HR image is progressively perturbed in a Markovian process:
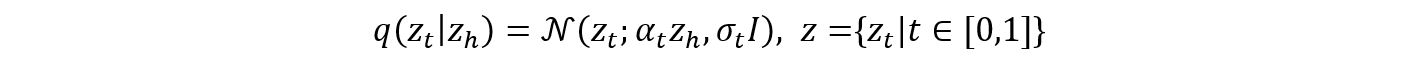
The LR image is passed to the backward denoising function as an additional input, typically through concatenation with the noisy input. We can estimate the backward denoising process $p(z_h│z_t,z_l )$ using a neural network $Z_θ$, via a weighted mean square error loss:

over uniformly sampled timesteps $t∈[0,1]$, and $z_t=α_t z_h+σ_t ϵ ; ϵ∈N(0,Ι)$. We call this mechanism unidirectional because the forward process is not conditioned on the LR image. We hypothesize that a direct conditioning on the low-res image of both the forward and backward steps would provide a better signal to the training process, making the problem simpler for the model and hence allow for reducing the model capacity.
Our Bidirectional Conditioning
To include the conditioning signal in the forward process, we modify the Markovian Gaussian forward process of the diffusion to:

where $z_l$=< $z_l^μ$,$z_l^σ$ >, $z_h$ are the embeddings of the LR and HR image, respectively, and $z_h$, $z_l^μ$ and $z_l^σ$ are of the same dimensions.
During training, the model learns to reverse this diffusion process progressively to generate the super-resolved image, without needing $z_l$ as an additional explicit input, given that it is now directly included in $z_t$. Specifically, we estimate the backward denoising process $p(z_t│z_h,z_l )$ using a network, $Z_θ$, via a weighted mean square error loss:

over uniformly sampled timesteps $t∈[0,1]$, and:

Encoder Training
The SR methods based on stable diffusion use the same encoder for the HR and LR images. This encoder is pre-trained on the HR images [1]. To cope with the domain shift between the LR and HR images, we propose to train the encoder jointly with the UNet for the SR task. This approach allows us to not only avoid computational overhead but also to reduce the encoder size drastically, where we need far fewer parameters to encode the LR image compared to the HR one. In particular, we use two encoders, $Ɛ$ and $Ɛ_{hr}$ for the LR and HR images respectively. We initialize Ɛ_hr with the SDv1.5 text-to-image encoder and freeze it, while we initialize $Ɛ$ randomly. We train $Ɛ$ jointly with the UNet. Notably, the HR image encoder is only needed at training time, and we only need the efficient LR encoder at inference.
Scale Distillation and Decoder Finetuning
The proposed approach can be readily combined with other techniques specifically targeting speeding up inference of the SD model. Here, we opt to use scale distillation [3] as it was specifically designed for the SR task and demonstrated superior performance with only 1-step.
The final step of our pipeline is to train an efficient decoder on top of the efficient 1-step model. To this end, we use the same VQ-VAE loss used to train the original auto-encoder in the original SD paper [1]. This step concludes the training of the proposed efficient Edge-SD-SR model.
Experimental Results and Comparisons
We compare our proposed lightweight model to the leading SD-SR methods on the established SR benchmarks. The quantitative results in Table 1 and qualitative results in Figure 2 speak decisively in favor of our model. Our approach offers overall superior performance across datasets yet, crucially, it has the lowest parameter and computational cost. The compute cost is an order of magnitude lower than ResShift, the next most efficient method.

Table 1. Comparison with State of the Art. #GFLOP indicate model compute, #Param indicates model parameters (millions). Refs: LDM [1], StableSR [2], DiffBir [5], SeeSR [6], ResShift [7].

Figure 2. Qualitative results on samples from the DIV2K-RealESRGAN, RealSR and DRealSR datasets. . ResShift and StableSR include 173M and 1043M parameters and both require > 2, 000 GFLOPs to process a 128 × 128 patch, resp. Ours includes only 169M parameters and requires 142 GFLOPs. Despite being hugely cost and parameter-efficient, our method works competitively with the larger baselines.
Summary
We presented Edge-SD-SR, the first SD-based SR solution that can readily run on device. To enable training this model, we introduce a new conditioning technique and training strategy that provides a better training signal for the diffusion model. The resulting model yields high quality HR images that surpass state-of-the-art while running on device.
Link to the paper
VladVA: Discriminative Fine-tuning of LVLMs. Yassine Ouali, Adrian Bulat, Alexandros Xenos, Anestis Zaganidis, Ioannis Maniadis Metaxas, Brais Martinez, Georgios Tzimiropoulos.
Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
References
[1] Rombach, R. et al., High-resolution image synthesis with latent diffusion models. IEEE Conference on Computer Vision and Pattern Recognition (2022).
[2] Wang, J. et al, Exploiting diffusion prior for real-world image super-resolution. arXiv: 2305.07015 (2023).
[3] Li, Y. et al., SnapFusion: Text-to-image diffusion model on mobile devices within two seconds. Neural Information Processing Systems (2023).
[4] Noroozi, M. et al., You only need one step: Fast super-resolution with stable diffusion via scale distillation. European Conference on Computer Vision (2024).
[5] Lin, X. et al., DiffBir: Towards blind image restoration with generative diffusion prior. European Conference on Computer Vision (2024).
[6] Wu, R. et al., SeeSR: Towards semantics-aware real-world image super-resolution. In IEEE Conference on Computer Vision and Pattern Recognition (2024).
[7] Yue, Z. et al., ResShift: Efficient diffusion model for image super-resolution by residual shifting. Neural Information Processing Systems (2023).



