AI
VladVA: Discriminative Fine-tuning of LVLMs
|
The Conference on Computer Vision and Pattern Recognition (CVPR) is one of the most prestigious annual conferences in the field of computer vision and pattern recognition. It serves as a premier platform for researchers and practitioners to present cutting-edge advancements across a broad spectrum of topics, including object recognition, image segmentation, motion estimation, 3D reconstruction, and deep learning. As a cornerstone of the computer vision community, CVPR fosters innovation and collaboration, driving the field forward with groundbreaking research. In this blog series, we delve into the latest research contributions featured in CVPR 2025, offering insights into groundbreaking studies that are shaping the future of computer vision. Each post will explore key findings, methodologies, and implications of selected papers, providing readers with a comprehensive understanding of the innovations driving the field forward. Stay tuned as we uncover the transformative potential of these advancements in our series. Here is a list of them. #2. Augmenting Perceptual Super-Resolution via Image Quality Predictors (AI Center - Toronto) #3. VladVA: Discriminative Fine-tuning of LVLMs (AI Center - Cambridge) #4. Accurate Scene Text Recognition with Efficient Model Scaling and Cloze Self-Distillation (Samsung R&D Institute United Kingdom) #5. Edge-SD-SR: Low Latency and Parameter Efficient On-device Super-Resolution with Stable Diffusion via Bidirectional Conditioning (AI Center - Cambridge) #6. DreamCache: Finetuning-Free Lightweight Personalized Image Generation via Feature Caching (Samsung R&D Institute United Kingdom) |
Introduction
Large-scale contrastive image-text pre-training has become the foundation for training Vision-Language Models (VLMs), with models such as CLIP [1] serving as the gold standard for discriminative vision-language tasks like image-text retrieval. These models demonstrate remarkable zero-shot capabilities across various classification benchmarks. However, they suffer from a critical limitation: contrastively-trained models have limited language understanding capabilities and exhibit a bag of words behavior. This bag of words behavior means that models treat text as an unordered collection of words, failing to understand word order, spatial relationships, and compositional meaning. For example, a model might consider "a red car next to a blue house" and "a blue car next to a red house" as nearly identical, ignoring the crucial positional and color-object relationships. This problem persists even when scaling up model and dataset sizes, revealing fundamental compositional understanding deficits.
On the other hand, Large Vision-Language Models (LVLMs) that combine vision encoders with powerful large language models (LLMs) have emerged as capable multimodal assistants. These models excel at detailed vision-language reasoning and provide fine-grained responses, demonstrating strong understanding of spatial relationships and compositional concepts. However, their autoregressive training makes them unsuitable for direct use in discriminative tasks like image-text retrieval. This creates a fundamental trade-off: discriminative models like CLIP are efficient for retrieval but lack compositional understanding, while LVLMs have strong vision-language understanding and reasoning capabilities but aren't designed for discriminative tasks.
In our paper published at the Conference on Computer Vision and Pattern Recognition (CVPR), we propose VladVA, a method that solves this by developing a novel training framework that adapts generative LVLMs into discriminative models, combining the efficiency of two-tower architectures with the compositional understanding of large language models
Zero-Shot Discriminative LVLMs
Before diving into our training approach, it's crucial to understand if and how a LVLM can function as a discriminative model. Previous works [2] showed that through careful prompting, LVLMs can indeed act as zero-shot discriminative models despite being trained only with autoregressive next-token prediction.
For a model to function as a discriminative model, we need to extract summary tokens, which are the representations that compress image or text information into a single embedding vector that can then be used downstream. For images, this involves passing the image through the entire LVLM with a prompt like "summarize the provided image in one word" and taking the output representation of the last token. Similarly, for text, we pass the text through the LLM component with prompts like "summarize the provided text in one word" and extract the final token representation.

Figure 1. Analysis of the image-text embeddings.
To understand what makes effective prompts for this zero-shot adaptation, we first start with a simple analysis. Using 1000 image-caption pairs from Flickr30k and testing 50 different prompt pairs with LLaVA-1.5-7B, and as shown in Figure 1 above, we observed that prompts containing keywords like "in a few words" or "in one word" push the model to condense information into the next token, resulting in 1) high entropy output distributions and 2) high-ranks embedding, indicating the model produces image/text representation that encode rich and diverse information about the inputs, which is necessary for discriminative tasks.
Based on the above analysis that indicates that LVLMs can indeed function as discriminative models with careful prompting. Next, we present our training approach for adapting LVLMs to discriminative tasks with the appropriate training setup and objective, so that we can both maintain their strong compositional abilities while unlocking their discriminative capabilities.
Our Solution: VladVA
VladVA (Vision-Language Adaptation for Discriminative Visual Assistant) converts generative LVLMs into powerful discriminative models through a carefully designed optimization framework. The VladVA training framework addresses a fundamental challenge in adapting LVLMs for discriminative tasks: how to effectively adapt LVLMs for discriminative tasks without losing their original strong vision-language understanding and compositional abilities. With VladVA, we achieve this by training on diverse set of captions across different lengths and granularity to both adapt the model to discriminative tasks and preserve its compositional understanding and avoid training collapse.
Specifically, the core innovation of VladVA lies in recognizing that different caption types require different training strategies:
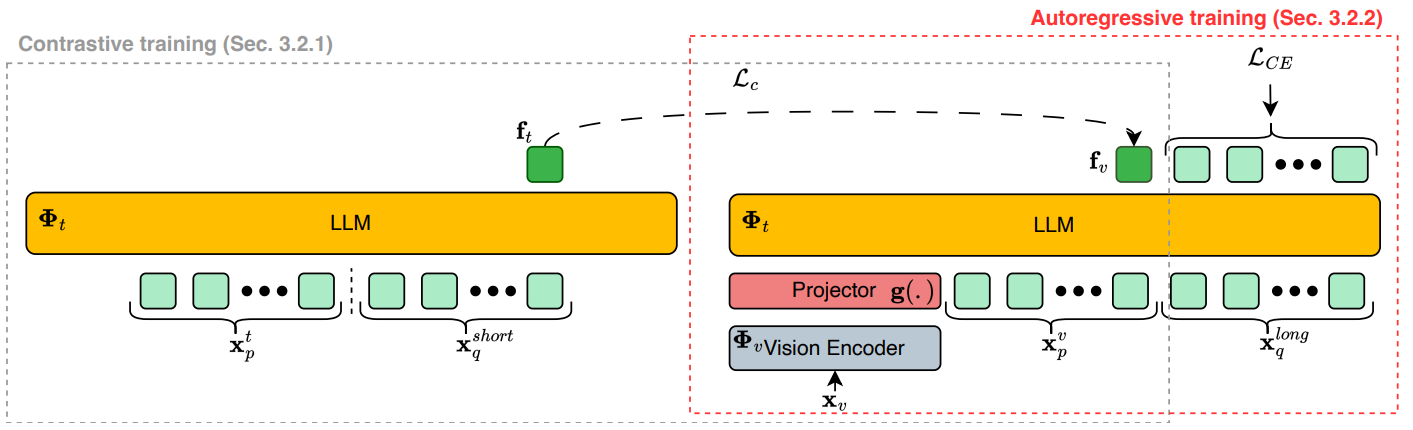
Figure 2. VladVA framework: a LVLM is adapted into a discriminative model with the help of (1) a contrastive training loss, and (2) an autoregressive loss. The first loss one is applied on image-text pairs with short(er) captions, encouraging the last token produced by both modalities to be discriminative. The second loss one, jointly optimized with the first one, is applied only on longer captions and allows the model to learn fine-grained details.
As such, we design our VladVA hybrid training framework consisting of the following key contributions:
Method Details
VladVA addresses a key challenge: how to adapt LVLMs for discriminative tasks while keeping their original vision-language understanding and compositional abilities. We achieve this by training on both short and long captions using different strategies for each type.
Our approach uses short captions with contrastive learning to teach the model discrimination, while long captions are used for autoregressive training to preserve the model's generative capabilities. This hybrid strategy is necessary because we found that contrastive loss works well for short captions but causes training collapse when applied to longer descriptions. The high specificity of long captions makes the contrastive task too easy, causing the loss to drop to zero within a few hundred iterations. By matching each caption type with its appropriate training objective, VladVA successfully adapts LVLMs for discrimination without losing their compositional understanding.
Training data
As previously mentioned, to both adapt the model for discriminative tasks and preserve its compositional abilities, our training data is composed of two types of captions:
Thus, our training will consist of LLaVA [3,8] training data that provides long captions, plus CC3M data that provides short captions. For the portion of our training data that lacks long captions, we use BLIP2 to generate short captions for images that lack them. As for the portion of our training data that lacks short captions, we use ShareGPT-4V to generate detailed them.
Training loss
After data pre-processing and annotations (i.e., generation of either a short caption or a long caption if one is missing), each input image from the training data is associated with two corresponding captions: one short caption and one long caption. As such, for each training iteration and a given batch of image-text pairs, the model is trained on a combination of two loss functions:
Model adaptation
Given the computational expense of full model fine-tuning, particularly when maintaining reasonably large batch sizes for effective contrastive learning, we adopt a parameter-efficient training strategy that combines two complementary techniques:
While soft prompting alone shows surprising effectiveness, the combination with LoRA adapters provides optimal performance by offering greater representational capacity.
Implementation Details
Training template: Our training implementation uses carefully designed multi-turn conversation templates that integrates both captions and to be able to compute both loss functions with a single forward pass. Specifically, the templates presented to the LVLM take the following form:
ASSISTANT: <out_token>
USER: Describe the image in detail.
ASSISTANT: <long_caption>
The contrastive loss is applied on the output representations <out_token> for both image and text modalities. Concomitantly, the next-token prediction loss is applied on the tokens of the <long_caption>. This template design allows the contrastive loss to operate on the summary token <out_token> representations while the autoregressive loss applies to the detailed caption tokens.
Training hyperparameters: We use LLaVA-1.5 (7B) [3] as our base model. For LoRA adapters, we set the rank and alpha to 16. The number of soft prompts is aligned to the length of the tokenized hand-crafted prompt. We train the models for 7 epochs using a batch size of 1024, a learning rate of 1e-4, no weight decay, and AdamW optimizer with default values for β₁ and β₂. The learning rate is decayed according to a cosine scheduler. Depending on the data configuration, we use up to 32 A100 GPUs.
Experimental Results and Comparisons
Zero-Shot Image-Text Retrieval

We evaluate on standard benchmarks: Flickr30k [4] (1,000 test samples), MS-COCO [5] (5,000 test samples), and nocaps [6] (15,100 test samples). Figure above shows recall at 1 (R@1) results, which demonstrate that VladVA provides significant improvements across all datasets:
Compositionality Understanding
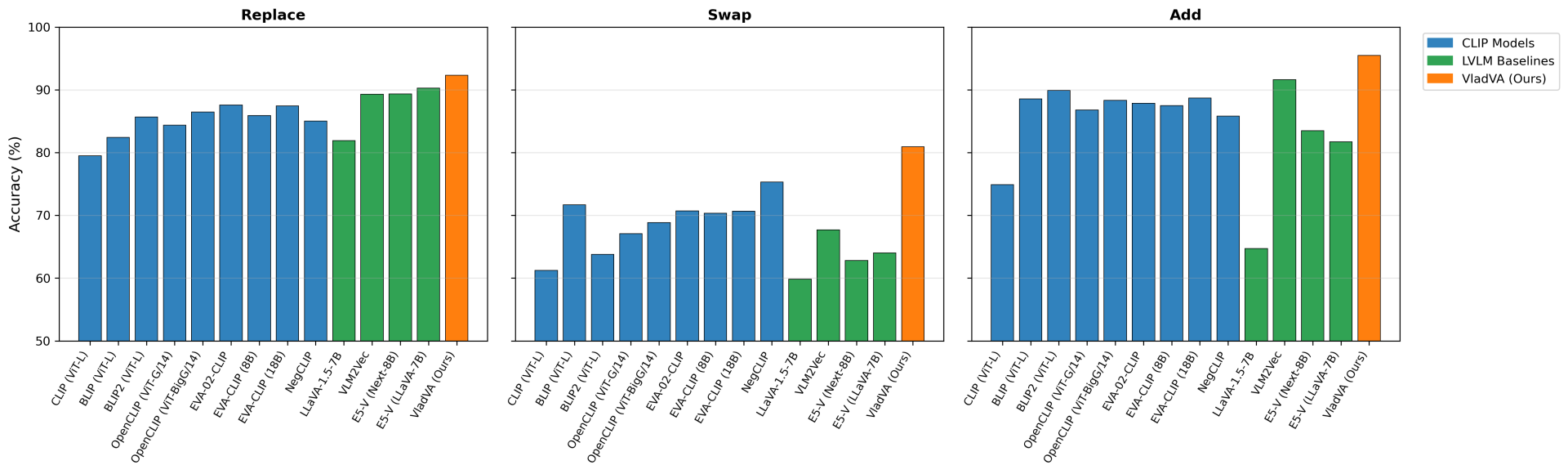
We evaluate on challenging compositionality SugarCrepe benchmark. This dataset specifically measures the understanding of spatial relationships, object-attribute bindings, and word order, which are areas where traditional contrastive models struggle. The results shown in the figure above shows that our method excels in these tasks by leveraging the compositional understanding of large language models, specifically:
Qualitative Analyses

Attention patterns evolution: As show figure above, post-training attention maps between summary tokens and vision tokens become significantly denser compared to the original LVLM. This densification reflects the model's adaptation to discriminative tasks. While generative models can selectively attend to relevant image regions at each generation step, discriminative models must compress all relevant visual information into the summary token, necessitating attention to all potentially relevant image regions.
Representation quality enhancement: As shown in Figure 1, our training produces models with output distributions exhibiting higher entropy and embeddings with more spread-out cumulative variance. This translates to richer, better-aligned representations that capture fine-grained details while maintaining the diversity necessary for effective discrimination.
Summary
VladVA represents a paradigm shift in vision-language model training, successfully converting generative LVLMs into powerful discriminative models. By recognizing that different caption types require different training strategies, we developed a hybrid approach that leverages both contrastive and autoregressive objectives. Combined with parameter-efficient adaptation techniques, this approach achieves substantial improvements over state-of-the-art models while using significantly fewer parameters. Importantly, our results demonstrate that it's possible to have the best of both worlds: the efficiency and discriminative power of two-tower architectures combined with the compositional understanding and reasoning capabilities of large language models. This opens new directions for building more capable and efficient vision-language models that excel at both discriminative tasks and complex reasoning.
Link to the paper
VladVA: Discriminative Fine-tuning of LVLMs. Yassine Ouali, Adrian Bulat, Alexandros Xenos, Anestis Zaganidis, Ioannis Maniadis Metaxas, Brais Martinez, Georgios Tzimiropoulos. Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
References
[1] Radford, A. et al. (2021). Learning transferable visual models from natural language supervision. International conference on machine learning.
[2] Jiang, T. et al. (2024). E5-v: Universal embeddings with multimodal large language models. arXiv preprint arXiv:2407.12580.
[3] Liu, H. et al. (2024). Improved baselines with visual instruction tuning. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
[4] Young, P. et al. (2014). From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics.
[5] Lin, T. Y. et al. (2014). Microsoft coco: Common objects in context. Computer Vision--ECCV 2014.
[6] Agrawal, H. et al. (2019). Nocaps: Novel object captioning at scale. Proceedings of the IEEE/CVF international conference on computer vision.
[7] Hsieh, C. Y. et al. (2024). Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality. Advances in neural information processing systems.
[8] Sun, Q. et al. (2023) Visual Instruction Tuning. Advances in neural information processing systems.
[9] Sun, Q. et al. (2024). Eva-clip-18b: Scaling clip to 18 billion parameters. arXiv preprint arXiv:2402.04252.



