AI
Accurate Scene Text Recognition with Efficient Model Scaling and Cloze Self-Distillation
|
The Conference on Computer Vision and Pattern Recognition (CVPR) is one of the most prestigious annual conferences in the field of computer vision and pattern recognition. It serves as a premier platform for researchers and practitioners to present cutting-edge advancements across a broad spectrum of topics, including object recognition, image segmentation, motion estimation, 3D reconstruction, and deep learning. As a cornerstone of the computer vision community, CVPR fosters innovation and collaboration, driving the field forward with groundbreaking research. In this blog series, we delve into the latest research contributions featured in CVPR 2025, offering insights into groundbreaking studies that are shaping the future of computer vision. Each post will explore key findings, methodologies, and implications of selected papers, providing readers with a comprehensive understanding of the innovations driving the field forward. Stay tuned as we uncover the transformative potential of these advancements in our series. Here is a list of them. #2. Augmenting Perceptual Super-Resolution via Image Quality Predictors (AI Center - Toronto) #3. VladVA: Discriminative Fine-tuning of LVLMs (AI Center - Cambridge) #4. Accurate Scene Text Recognition with Efficient Model Scaling and Cloze Self-Distillation (Samsung R&D Institute United Kingdom) #5. Edge-SD-SR: Low Latency and Parameter Efficient On-device Super-Resolution with Stable Diffusion via Bidirectional Conditioning (AI Center - Cambridge) #6. DreamCache: Finetuning-Free Lightweight Personalized Image Generation via Feature Caching (Samsung R&D Institute United Kingdom) |
Motivation
Scene Text Recognition (STR) aims to automatically transcribe text in natural scenes, enabling applications in autonomous driving, augmented reality, language translation, and assistive technologies.
Scaling architectures have been proven effective for improving Scene Text Recognition (STR), but the individual contribution of vision encoder and text decoder scaling remain under-explored.
We present an in-depth empirical analysis and demonstrate that, contrary to previous observations, scaling the decoder yields significant performance gains, always exceeding those achieved by encoder scaling alone. We also identify label noise as a key challenge in STR, particularly in real-world data, which can limit the effectiveness of STR models. To address this, we propose Cloze Self-Distillation (CSD), a method that mitigates label noise by distilling a student model from context-aware soft predictions and pseudo-labels generated by a teacher model. Also, we enhance the decoder architecture by introducing differential cross-attention for STR.
Our methodology achieves state-of-the-art performance on 10 out of 11 benchmarks using only real data, while significantly reducing the parameter size and computational costs.
Our Contributions
Unlike traditional Optical Character Recognition (OCR), which typically works with clean or scanned documents, STR faces unique challenges due to the diverse and uncontrolled nature of text in real-world environments. In particular, text in these settings can vary significantly in orientation, font style, shape, size, color, formatting, and aspect ratio. It often appears on complex backgrounds that may also include reflections, transparency, or occlusions.
Recent research has led to notable performance improvements in STR by enhancing training methods [1], deploying novel architectures [2], and exploring the effects of model scaling [3]. Despite these advancements, current STR models still face important challenges that limit their effectiveness. Our work is motivated by the following research question:
“What are the primary bottlenecks currently limiting STR, and what strategies can be employed to improve both accuracy and efficiency?”
Throughout our analysis, we identify three important limitations: 1) sub-optimal model scaling, 2) noisy labels in training data, and 3) architectural limitations within current model designs.
Sub-optimal model scaling: We provide an in-depth analysis of the effects of independently scaling the encoder and decoder components under different data volumes. Contrary to previous findings, we demonstrate that decoder scaling is indeed essential for achieving optimal STR performance. As illustrated in Fig. 1, increasing the decoder size provides substantial benefits for any visual encoder and results in more favourable scaling laws.

Figure 1. Average word accuracy (%) on 11 STR benchmarks for the models with ViT-T, ViT-S and ViT-B vision encoders and four different decoder sizes. Results are compared with the previous state-of-the-art model, CLIP4STR. Results using Real training dataset (3.3M images) are depicted with solid lines and circle markers, while results using RBU training dataset (6.5M images) are shown with dashed lines and diamond markers. The x-axis represents the total number of model parameters (in millions) on a logarithmic scale.
Noisy labels in training data: We observe that text annotations of STR datasets often suffer from inconsistencies, errors and noise, which can negatively impact STR performance as illustrated in Fig. 2. Therefore, we propose a novel Cloze Self-Distillation (CSD) technique. In CSD, a model serving as a teacher, is first trained and used to generate predictions on training data. These predictions are then refined using a cloze-filling approach: each character is re-predicted using all other characters as textual context, resulting in more accurate, informative and context-aware soft predictions. We then distill the teacher into an identical student model on the same training set by employing the teacher's hard predictions as ground truth and a knowledge distillation term that minimizes the divergence between the student's limited-context predictions (obtained through permuted language modelling) and the teacher's full-context cloze predictions.

Figure 2. Examples of label inconsistencies and errors in the training set. For each image, we show the ground truth label (L) and the teacher-generated pseudolabel (P). Subfigures (a-c) illustrate typical label errors, such as spelling mistakes or missing characters. Subfigures (d,e) highlight label inconsistencies, where punctuation or occluded parts are not annotated. Subfigure (f) demonstrates a labelling error caused by severe degradation in the image quality.
Architectural limitations: Inspired by Differential Transformer [4], we propose a novel Differential Permutation Language Decoder that employs Differential Cross-attention layers and SwiGLU activations [6], addressing the limitation of previous architecture in focusing on relevant context. Fig. 3 provides visual comparisons between the standard Cross-Attention and our Differential Cross-Attention. From the results, the majority of the noise and errors observed in the standard Cross-Attention are effectively reduced, when the Differential Cross-Attention is used.

Figure 3. Comparison of Attention Maps. Attention maps of the last Cross-Attention in the last block of the Permutation Language Decoder. On the left: the original input image. First row of each section: attention maps obtained with the standard Cross-Attention. Second row of each section: attention maps obtained with our Differential Cross-Attention.
Proposed Method
In this work, we consider a STR model pθ composed by an image encoder E and a text decoder D. Given an input image x, the encoder E computes a sequence of vision tokens that constitute the latent representations z∈Z. Later, for a random permutation π and given z, a sequence position πt and previous characters yπ<t, the decoder D estimates the logits over the character set C in order to predict the πtht character in the input image x In particular, our STR model can be formulated by:

where the subscript c is used to indicate the index of the probability vector computed with the softmax function σ(.) associated to character c. Furthermore, the parameters θ=(Eθ,Dθ) denote both the encoder and decoder parameter sets.
a) Scaling Analysis:
We analyze how increasing model size can affect the final performance in our STR model, by specifically showing the individual effects of encoder and decoder scaling. To achieve this goal, we consider three image encoders with the same transformer architecture (Vision Transformer) and pre-training scheme (on ImageNet21k), but different parameter capacities: ViT-Tiny, ViT-Small, and ViT-Base. Additionally, we employ Permutation Language Decoders with four different sizes: PLD-Tiny, PLD-Small, PLD-Base, and PLD-Large. The details of these architectures in terms of hyperparameters, number of parameters and GFLOPs are presented in Tab. 1.

Table 1. Details of ViT encoders and PLD decoders used in our scaling experiments. GFLOPs for the decoder refer to the average test sequence length L=5.5.
b) Cloze Self-Distillation:
Previous empirical evaluations [3, 5] have demonstrated that real datasets offer a better sample-efficiency for training STR models than synthetic datasets, as they are more closely aligned with the target distributions found in STR tasks. However, despite their importance, real datasets often contain a large number of label errors and inconsistencies, which can adversely impact the performance of STR models. We propose a novel technique, named Cloze Self-Distillation (CSD), to mitigate the impact of such errors and to improve the STR performance. In particular, CSD is motivated by two key observations:
Given a dataset with potential label noise, CSD involves three main steps: 1) a teacher STR model pθT is fully trained on the noisy dataset; 2) pθT is employed to compute pseudolabels and context aware-logits with the cloze-filling refinement for the noisy dataset; 3) a new student model pθS (with the same architecture and size of the initial model) is distilled from the teacher. Hence, teacher pseudolabels are used instead of the ground truth annotations to minimize the negative log likelihood (NLL) and an additional Knowledge Distillation (KD) loss term is introduced to minimize the divergence between the context-aware soft predictions of the teacher (obtained with cloze-filling) and the partial-context predictions of the student (obtained with PLM), as it is illustrated in Fig. 4.

Figure 4. Flow of Cloze Self-Distillation (CSD). Pseudolabels and soft predictions of a fixed teacher model, obtained with the cloze-filling approach, are distilled into a student model by minimizing the negative log likelihood (NLL) and the knowledge distillation (KD) objective.
We remark that the teacher soft-predictions are computed given the full context, yπ≠t, while the student outputs are computed with the standard context of PLM, yπ<t. This intuitively makes the task more challenging for the student, allowing it to effectively distill the knowledge from the teacher and to outperform its performance. The overall CSD objective is:

where the expectation Ε[.] is with respect to the data samples (x,y), the permutations π and the position t in the sequence. Furthermore, α is the hyperparameter to define the contribution of distillation term to the objective function.
c) Differential Decoder:
For the decoder D, we introduce a Differential Cross-Attention mechanism, inspired from the Differential Self-Attention proposed by [4] for NLP. Intuitively, Differential Cross-Attention computes two separate softmax cross-attention maps and subtracts them to cancel out common-noise mode. This enables the Cross-Attention mechanism to focus more on relevant context and vision tokens than noisy-representations.
Formally, let d be the inner dimension of the transformer, h be the number of heads, such that dh=d/h∈N is the dimension of each head. Given an input sequence of Lq tokens for the query stream sq and an input sequence of Lkv tokens for the key-value stream skv, for the attention head i=[1,...,h], the differential cross-attention operation is formulated by:

where the queries, keys and values in the attention operation can be represented as q=[q1,q2 ]=sqWiq, k=[k1,k2 ]=skvWik and v=skvWiv, where I indicates the head index and Wiq, Wik, Wivare the projection matrices and [.,.] indicates a concatenation operation. λ is a scalar parameter shared across heads of the same layer.

Figure 5. Differential Cross-Attention used in our PLD decoder. For simplicity, the diagram shows a single head.
In our Differential Decoder, we replace all traditional Multi-Head Cross-Attention layers with Multi-Head Differential Cross-Attention layers and utilize MLP with SwiGLU. A diagram of the Differential Cross-Attention is presented in Fig. 5.
Experimental Results
Test Benchmarks: We evaluate STR models on the six most widely used benchmarks in the literature: ICDAR13 (IC13), IIIT5K, and Street View Text (SVT) for Regular text recognition; and CUTE80 (C80), ICDAR15 (IC15) and Street View Text-Perspective (SVT-P) for Irregular text recognition. The IC13 benchmark includes subsets of 857 images (IC13-857) and a subset of 1015 images (IC13-1015), while IC15 include subsets of 1811 images (IC15-1811) and 2077 images (IC15-2077). Additionally, we report performance on two datasets designed to evaluate robustness for occlusions: Heavily Occluded Scene Text (HOST) and Weakly Occluded Scene Text (WOST). To further ensure comprehensive evaluation, we also include more recent and larger benchmarks, COCO-Text, ArT and Uber-Text.
Training protocol: Model parameters are optimized with a global batch size of 1024 using AdamW, 0.1 weight decay and gradients are clipped to 1.0. The learning rate follows a One-Cycle schedule with a maximum value of 0.01 and 3300 warm-up steps, both for encoder and decoder parameters. We train each STR model for 110K steps, corresponding to approximately 35 epochs for Real (R) dataset, 17.5 for RBU. To train the model with Permutation Language Modeling, we follow [5] and employ the causal and anti-causal permutations (left-to-right and right-to-left), together with four random permutations sampled differently for each batch. For CSD, the same training schedule is employed both for the teacher and the student and we use α=0.1 and τ=2.0.
Evaluation metrics: Following previous works, we evaluate our STR model using the word accuracy, where a predicted sequence is considered correct only if all characters match the ones of the ground truth label. To make a comparison with the results reported by previous works, we provide two separate aggregate scores: the average accuracy across all 11 benchmarks, considering the subsets IC13-1015 and IC15-1811 (it is referred as AVG11 and the weighted average of the 6 common benchmarks with the subsets IC13-857 and IC15-1811 (it is referred as AVG6).
a) Encoder-Decoder Scaling Results:
We analyze the impact of scaling both the vision encoder and the text decoder in our STR model. In Tab. 2, we present the average word accuracy AVG11 achieved with various encoder and decoder configurations.
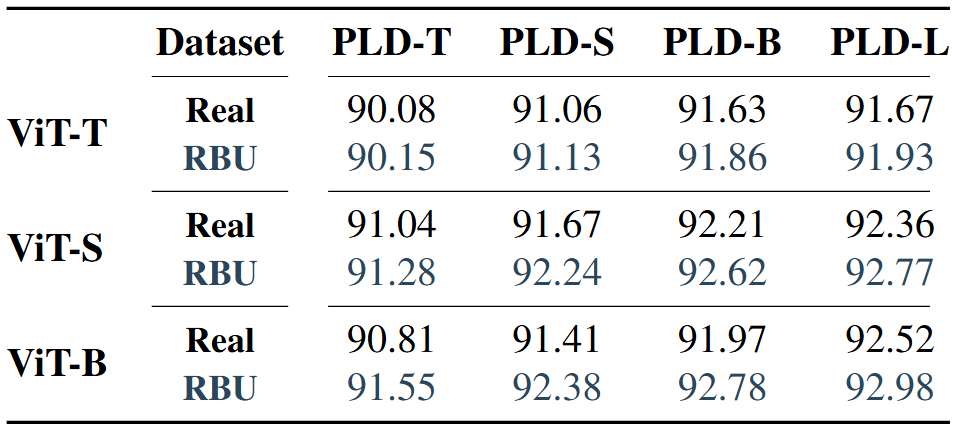
Table 2. Encoder-Decoder Scaling. Average word accuracy (%) on the 11 benchmarks (AVG11) for different encoder-decoder configurations trained on Real or RBU dataset.
Encoder Scaling: From the results, scaling the vision encoder from ViT-T to ViT-S significantly boosts the accuracy across both Real and RBU datasets, and for all decoder configurations. However, further scaling from ViT-S to ViT-B, shows a different effect: when data is abundant (on RBU), the larger encoder improves performance with all decoders, but on the Real dataset with smaller decoders, ViT-B decreses the performance compared to ViT-S.
Permutation Language Decoder Scaling: Our results demonstrate that scaling the decoder is more parameter and computational efficient than scaling the encoder only, leading to more favourable scaling laws than previous state-of-the-art approaches. Using the larger RBU dataset as a reference, increasing the encoder from ViT-T to ViT-B yields an average improvement (across decoders) of 1.16% AVG11 with an additional 80.3M parameters. In contrast, scaling the decoder from PLD-T to PLD-L results in an average improvement (across encoders) of 1.56% AVG11 with only 26.3M parameter increase.
b) Cloze Self-Distillation Results:
Tab. 3 presents the average word accuracy AVG11 obtained with different training procedures: standard supervised training, training on teacher pseudolabels (P) and CSD (pseudolabels and Knowledge Distillation (KD)). In this experiment, we utilize ViT of varying sizes (Tiny, Small, Base) as encoders, paired with the base-size decoder (PLD-B). Notably, incorporating teacher pseudolabels during training significantly enhances the performance, since it reduces the label errors and inconsistencies in real datasets.

Table 3. Effects of pseudolabels and KD. Average word accuracy (%) on 11 benchmarks (AVG11) using the Real dataset with standard supervised training, pseudolabels (P) and Knowledge Distillation (KD) with the cloze soft probabilities.
Moreover, integrating the Knowledge Distillation component based on context-aware probabilities (computed with the cloze-filling approach) further strengthens the regularization effects, resulting in an additional performance gain. The superiority of CSD is evident also in Tab. 4, which reports the average accuracy of ViT-Base with PLD-B when scaling the data from 10% to 100% of the Real dataset, as well as on RBU (which represents approximately 200% of the Real dataset). Compared to the baseline method of standard supervised training, CSD consistently provides notable improvements at all data scales. Our technique achieves appx. 0.5% accuracy gain both when the full Real dataset or RBU dataset are used (for comparison, doubling the training dataset, i.e., Real⟶RBU, yields a +0.8% performance increase).

Table 4. Benefits of CSD. Average word accuracy (%) on the 11 benchmarks (AVG11) of ViT-B and PLD-B scaling the data samples from 0.33M (10%) to 6.5M (200%). Standard supervised training (Sup.) is compared to our method (CSD).
c) Differential Decoder Results:
We evaluate its effectiveness in the base configuration with 2 layers, an inner dimension of 768 and 12 attention heads and with ViT-Base encoder. Tab. 5 shows that PLD-Diff consistently improves the performance using both Real and RBU datasets. In a traditional Cross-Attention mechanism, a small proportion of attention maps might focus on relevant context. Hence, this leads to poor predictions and decreases the performance. In contrast, Differential attention concentrates more on critical information, so that a performance increase can be observed.

Table 5. Benefits of Differential Decoder(PLD-D). AVG11 and AVG6 of ViT-B paired with the standard base decoder (PLD-B) and the differential decoder (PLD-D), trained on Real or RBU dataset.
d) Comparison with State-of-the-Art:
Tab. 6 shows that our models outperform previous state-of-the-art models in almost all benchmarks, whether they are trained on the Real or RBU dataset. Precisely, when they are trained solely on the Real dataset, our models outperform the previous state-of-the-art models on 10 out of 11 benchmarks, while requiring significantly less parameters and GFLOPs. Our best model, CSD-D, achieves an AVG11 accuracy of 92.73% and a AVG6 accuracy of 97.42%, compared to CLIP4STR-L whose respective scores are 91.69% and 97.04%. Note that our models use only 24.7% of the parameters and 23.9% of the GFLOPs achieved by CLIP4STR-L. By expanding the training dataset to RBU, our models continue to outperform previous models, with CSD-D achieving an AVG11 accuracy of 93.30% and a AVG6 accuracy of 97.62%, even outperforming the 97.42% AVG6 achieved by CLIP4STR-L when scaled to the larger RBU-Syn dataset whose size is 18M.

Table 6. Comparison with state-of-the-art methods. The word accuracy (%) of our models trained with CSD is compared with state-of-the-art approaches both for the Real and RBU training datasets.
e) Additional Results:
In Tab. 7, we show that our CSD model outperforms previous state-of-the-art even in the challenging Union14M benchmark.

Table 7. Comparison of CSD-D with CLIP4STR on Union14M benchmark.
Conclusion
We present a comprehensive analysis of encoder-decoder scaling for STR by demonstrating the significant benefits of scaling the decoder. Additionally, we introduce a novel training strategy to address label noise in real-world STR datasets. We leverage context-aware predictions generated from a teacher model through a cloze-filling approach, to distill a student model with improved performance. Moreover, we propose architectural updates, including Differential Cross-Attention, to improve the effectiveness of the decoder to focus on relevant context during inference. Empirical evaluations show the superiority of our model, achieving SOTA across multiple benchmarks while using fewer parameters and reducing the computational overhead (FLOPs) compared to previous models.
Link to the paper
Our paper “Scene Text Recognition with Efficient Model Scaling and Cloze Self-Distillation” will appear at the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025.
https://arxiv.org/abs/2503.16184
References
[1] Qing Jiang, Jiapeng Wang, Dezhi Peng, Chongyu Liu, and Lianwen Jin. Revisiting scene text recognition: A data per- spective. In Proceedings of the IEEE/CVF international con- ference on computer vision, pages 20543–20554, 2023.
[2] Shuai Zhao, Ruijie Quan, Linchao Zhu, and Yi Yang. Clip4str: A simple baseline for scene text recognition with pre-trained vision-language model. arXiv preprint arXiv:2305.14014, 2023.
[3] Miao Rang, Zhenni Bi, Chuanjian Liu, Yunhe Wang, and Kai Han. Large ocr model: An empirical study of scaling law for ocr. arXiv preprint arXiv:2401.00028, 2023.
[4] Tianzhu Ye, Li Dong, Yuqing Xia, Yutao Sun, Yi Zhu, Gao Huang, and Furu Wei. Differential transformer. arXiv preprint arXiv:2410.05258, 2024.
[5] Darwin Bautista and Rowel Atienza. Scene text recognition with permuted autoregressive sequence models. In European conference on computer vision, pages 178–196. Springer, 2022.
[6] Noam Shazeer. Glu variants improve transformer. arXiv preprint arXiv:2002.05202, 2020


