AI
DreamCache: Finetuning-Free Lightweight Personalized Image Generation via Feature Caching
|
The Conference on Computer Vision and Pattern Recognition (CVPR) is one of the most prestigious annual conferences in the field of computer vision and pattern recognition. It serves as a premier platform for researchers and practitioners to present cutting-edge advancements across a broad spectrum of topics, including object recognition, image segmentation, motion estimation, 3D reconstruction, and deep learning. As a cornerstone of the computer vision community, CVPR fosters innovation and collaboration, driving the field forward with groundbreaking research. In this blog series, we delve into the latest research contributions featured in CVPR 2025, offering insights into groundbreaking studies that are shaping the future of computer vision. Each post will explore key findings, methodologies, and implications of selected papers, providing readers with a comprehensive understanding of the innovations driving the field forward. Stay tuned as we uncover the transformative potential of these advancements in our series. Here is a list of them. #2. Augmenting Perceptual Super-Resolution via Image Quality Predictors (AI Center - Toronto) #3. VladVA: Discriminative Fine-tuning of LVLMs (AI Center - Cambridge) #6. DreamCache: Finetuning-Free Lightweight Personalized Image Generation via Feature Caching (Samsung R&D Institute United Kingdom) |
Introduction
In the rapidly evolving landscape of artificial intelligence, personalized image generation has emerged as a transformative field, enabling the creation of tailored visual content across diverse applications. At the heart of this innovation lies the challenge of developing text-to-image generative models capable of capturing and replicating the core features of a reference subject, allowing for controlled generation in varied contexts. However, existing methodologies often grapple with significant hurdles, including intricate training processes, exorbitant inference costs, limited adaptability, or a combination of these constraints, which impede their practical deployment.
In this blog post, we unveil DreamCache [1], a pioneering solution designed to address these challenges head-on. DreamCache introduces a scalable and efficient approach to personalized image generation, leveraging a novel caching mechanism that stores a select subset of reference image features from specific layers and a single timestep of the pretrained diffusion denoiser. This innovative technique empowers dynamic modulation of generated image features through lightweight, trained conditioning adapters, ensuring both precision and flexibility.
DreamCache distinguishes itself by achieving state-of-the-art image and text alignment while utilizing significantly fewer additional parameters compared to conventional models. Its computational efficiency and versatility make it an unparalleled choice for applications ranging from creative design to scientific visualization. By overcoming the limitations of traditional methods, DreamCache sets a new benchmark for personalized image generation, offering a pathway to more accessible and scalable solutions.
As we delve deeper into the technical intricacies of DreamCache in subsequent sections, we invite you to explore how this groundbreaking approach is reshaping the future of generative AI and unlocking new possibilities for creators, researchers, and industries alike. Example generations are shown in Figure 1.

Figure 1. Personalized generations by DreamCache. The proposed method is able to adapt to different text prompts and leverage diffusion prior to perform appearance and style editing of the personalized content.
Our Method: DreamCache
DreamCache is a novel and scalable approach designed to address the challenges of personalized image generation. Given a pretrained text-to-image generative model and an image containing a reference subject, the goal of DreamCache is to generate novel images featuring the reference subject in various contexts while maintaining textual control. This is achieved through a combination of a pretrained diffusion model, conditioning adapters, and a feature cache derived from the reference image.
DreamCache achieves state-of-the-art image and text alignment while utilizing significantly fewer additional parameters compared to existing models. Its computational efficiency and versatility make it an ideal solution for applications ranging from creative design to scientific visualization. By enabling zero-shot personalized generation with any new reference image—without requiring further fine-tuning—DreamCache sets a new standard for scalability and accessibility in personalized image generation. The optimal performance-efficiency trade-off of DreamCache is shown in Figure 2 and Table 1.

Figure 2. DreamCache is a finetuning-free personalized image generation method that achieves an optimal balance between subject fidelity, memory efficiency, and adherence to text prompts.
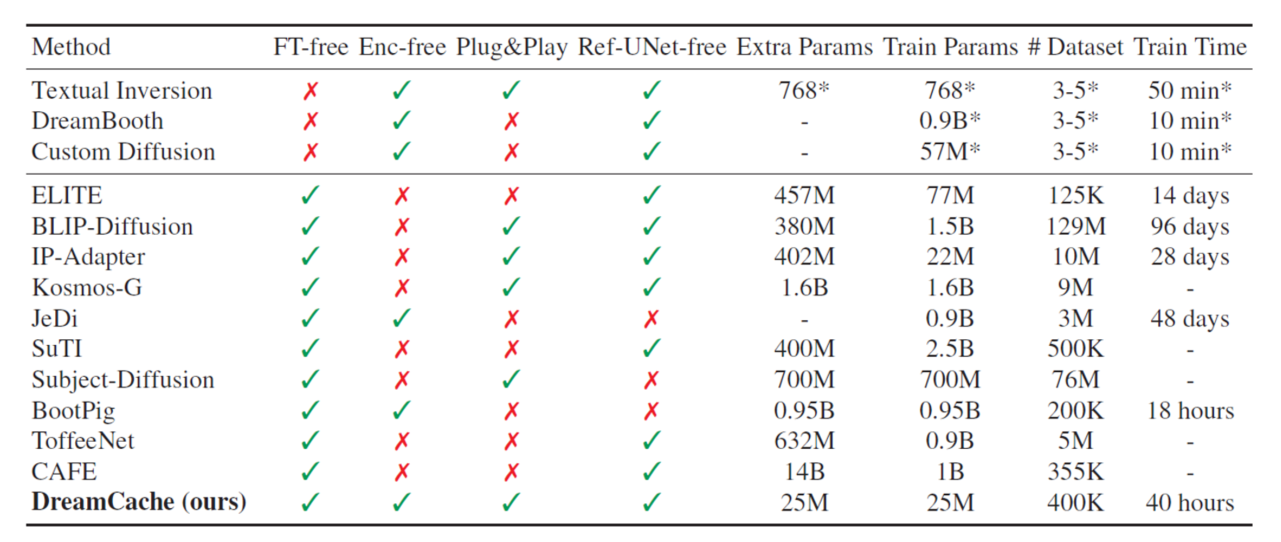
Table 1. Methods overview: our DreamCache achieves state-of-the-art generation quality at reduced computational costs. *: value refers to the personalization stage for each personal subject.
The core components of DreamCache are described next and illustrated in Figure 3.

Figure 3. Overview of DreamCache. Original U-Net layers are shown in violet, while the novel components introduced by DreamCache are highlighted in green. During personalization, features from selected layers of the diffusion denoiser are cached from a single timestep, using a null text prompt. These cached features serve as reference-specific information. During generation, conditioning adapters inject the cached features into the denoiser, modulating the features of the generated image to create a personalized output.
1. Caching Reference Features
At the heart of DreamCache lies a caching mechanism that extracts multi-resolution features from the reference image. This is accomplished by performing a forward pass through the denoiser of the pretrained diffusion model at a single timestep, the least noisy timestep, ensuring clean and optimal features for conditioning. To decouple the visual content of the reference image from its text caption, we remove text conditioning, eliminating the need for user-provided captions. This contrasts with methods like JeDi [2], which are sensitive to caption content.
During this process, activations are computed for all layers of the denoiser, but only a subset is cached. Based on experiments with the Stable Diffusion U-Net [3], caching features from a middle bottleneck layer and every second layer in the decoder strikes the best balance between generation quality and caching efficiency. The cached features, with varying spatial resolutions, enable both global semantic guidance and fine-grained detail preservation.
We foreground-segment the reference image to isolate the subject from the background before caching its features.
2. Conditioning on Cached Reference Features
DreamCache introduces a novel conditioning adapter mechanism to modulate the image generation process dynamically. This mechanism consists of:
The conditioning adapter mechanism works by projecting the current features of the image under generation and the cached reference features into a shared space. It then computes attention scores between these features to blend them effectively. The resulting combined features are projected back to their original dimensionality, ensuring seamless integration with the denoising process.
3. Training the Conditioning Adapters
To ensure generalization across diverse reference subjects, the conditioning adapters are trained on a synthetic dataset generated using open-source models. Inspired by BootPIG [4], we employ a large language model to generate captions for target images, which are then synthesized using Stable Diffusion [3]. The Segment Anything Model (SAM) [5] and Grounding DINO [6] are used to segment the reference subject and generate foreground masks. This pipeline produces a dataset where the Stable Diffusion-generated image serves as the target, the foreground object pasted on a white background as the reference, and the LLM-generated caption as the textual prompt.
The adapters are trained using a standard loss function that measures how well the model predicts noise from noisy images. This training process ensures that the adapters can effectively leverage both primary and conditioning-based contextual information, enabling zero-shot personalized generation with any new reference image without requiring further fine-tuning.
Experimental Results
We compare DreamCache against state-of-the-art methods for finetuning-based and zero-shot personalization. Table 2 presents quantitative results. Our approach achieves competitive or superior performance compared to other computationally-intensive state-of-the-art methods, which are trained on larger datasets and with significantly more parameters. We refer the reader to Table 1 for the data requirements, training time, and parameter count of the various methods. We remark that generally DINO is a preferred metric for image similarity with respect to CLIP-I, as it is more sensitive to the appearance and fine-grained details of the subjects.

Table 2. Quantitative results on DreamBooth. DreamCache obtains a better balance between DINO score and CLIP-T compared to all baselines, while also offering a more efficient computational tradeoff (see Table 1).
We also present qualitative comparisons with Kosmos-G [7] and BLIP-Diffusion [8]. As seen in Fig. 4, our method excels in subject preservation and textual alignment, producing visually superior results. We also notice that Kosmos-G reports a high CLIP-I score, but after inspecting the generated images, it is clear that the score does not entirely reflect the preservation of the reference subject in generated images. In fact, Kosmos-G presents a high degree of background interference, where the partial replication of the reference background boosts the alignment score.

Figure 4. Visual comparison. Personalized generations on sample concepts. DreamCache preserves reference concept appearance and does not suffer from background interference. BLIP-D [8] and Kosmos-G [7] cannot faithfully preserve visual details from the reference.
The computational efficiency of our method is compared to the reference-based method BootPIG [4] and encoder-based approaches such as Kosmos-G [7] and Subject- Diffusion [9]. Table 3 provides a detailed comparison of inference time, accounting for both personalization time (e.g., the time to generate the cache for DreamCache) and the time to sample the personalized image. We also report the increase in model size, i.e., the storage (in FP16 precision) required for the extra parameters to allow for personalization, showing that DreamCache is one order of magnitude more compact than the state of the art. Overall, DreamCache offers a lightweight solution that achieves state-of-the-art performance with faster inference and reduced computational overhead.

Table 3. Computational comparison. *: time to generate an image with 100 timesteps, evaluated on a single NVIDIA A100 GPU.
Conclusions
In this blog, we introduced DreamCache, a novel approach to personalized text-to-image generation that uses feature caching to overcome the limitations of existing methods. By caching reference features from a small subset of layers of the U-Net only once, our method significantly reduces both computational and memory demands, enabling efficient, real-time personalized image generation. Unlike previous approaches, DreamCache avoids the need for costly finetuning, external image encoders, or parallel reference processing, making it lightweight and suitable for plug-and-play deployment. Our experiments demonstrate that DreamCache achieves state-of-the-art zero-shot personalization with only 25M additional parameters and a fast training process. While DreamCache is a promising direction towards more efficient personalized generation, it has some limitations. Although effective for single-subject personalization, our approach may require adaptation for complex multi-subject generation where feature interference can occur. Additionally, certain edge cases, such as highly abstract or stylistic images, may challenge the caching mechanism’s capacity to accurately preserve subject details. To address these challenges, future work may explore adaptive caching techniques or multi-reference feature integration.
Link to the paper
References
[1] Emanuele Aiello, Umberto Michieli, Diego Valsesia, Mete Ozay, Enrico Magli. DreamCache: Finetuning-Free Lightweight Personalized Image Generation via Feature Caching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12480–12489, 2025.
[2] Yu Zeng, Vishal M Patel, Haochen Wang, Xun Huang, Ting-Chun Wang, Ming-Yu Liu, and Yogesh Balaji. Jedi: Joint-image diffusion models for finetuning-free personalized text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6786–6795, 2024.
[3] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
[4] Senthil Purushwalkam, Akash Gokul, Shafiq Joty, and Nikhil Naik. Bootpig: Bootstrapping zero-shot personalized image generation capabilities in pretrained diffusion models. arXiv preprint arXiv:2401.13974, 2024.
[5] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. arXiv preprint arXiv:2304.02643, 2023.
[6] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023.
[7] Xichen Pan, Li Dong, Shaohan Huang, Zhiliang Peng,Wenhum Chen, and Furu Wei. Kosmos-G: Generating images in context with multimodal large language models. arXiv preprint arXiv:2310.02992, 2023.
[8] Dongxu Li, Junnan Li, and Steven CH Hoi. BLIP-diffusion: Pre-trained subject representation for controllable text-to-image generation and editing. arXiv preprint arXiv:2305.14720, 2023.
[9] Jian Ma, Junhao Liang, Chen Chen, and Haonan Lu. Subject-diffusion: Open domain personalized text-to-image generation without test-time fine-tuning. arXiv preprint arXiv:2307.11410, 2023



