Communications
6G AI/ML for Physical-layer: Part II – Audio Traffic with JSCM
Introduction
For decades, wireless systems have been built around one central objective: deliver bits as accurately as possible. That design philosophy has served the industry well, but it also reflects a strong assumption that communication quality is determined mainly by bit accuracy.
For many human-facing services, that assumption is only partly true. In speech communication, for example, small bit errors do not always prevent a listener from understanding the message. What often matters more is whether the meaning survives, not whether every transmitted bit is perfectly preserved. This is the starting point of semantic communication.
Semantic communication shifts the design target from bit-perfect delivery to meaning-preserving delivery [1]. Instead of protecting every bit equally, the system tries to transmit the information that matters most for the task or perception at the receiver. This opens the door to a different kind of efficiency — especially for analog and perceptual sources such as speech, audio, video, and other signals generated from the physical world.
Recent progress in AI makes this idea far more practical than it once was. With end-to-end neural models, source compression, channel coding, and modulation no longer have to be treated as completely separate blocks. Instead, they can be jointly optimized in a unified architecture. In our work, we explore this direction through semantic audio communication, using a neural joint source-channel coding and modulation (JSCM) framework as a first step toward more meaning-aware wireless systems.
Why Start with Audio?
If semantic communication is about preserving what matters rather than every bit, audio is one of the most natural places to begin.
Speech is still the most fundamental mode of human communication. It is interactive, delay-sensitive, and deeply tied to human perception. At the same time, speech also reveals one of the core limitations of traditional communication design: the system often spends a large amount of resource protecting bit-level fidelity even when the listener only needs intelligible and perceptually acceptable audio [2].
That makes audio a particularly strong candidate for semantic communication. It sits at the intersection of human perception, resource efficiency, and practical deployment value. In other words, it is both technically meaningful and commercially relevant.
This becomes especially important in resource-scarce scenarios, where the communication system cannot afford to operate as if bandwidth, power, and coverage were abundant. In our view, semantic audio communication is especially compelling in four such settings:
These are exactly the cases where transmitting meaning more efficiently may matter more than preserving every bit perfectly.
From Separate Blocks to End-to-End Semantic Audio
Traditional audio communication follows a familiar layered pipeline: compress the source, apply channel coding, modulate the signal, and send it over the air. This architecture is robust and well understood, but it is not always the most efficient way to deliver perceptual information.
Our approach takes a different path as shown in Fig 1. Instead of separating source coding, channel coding, and modulation into independent stages, we use an end-to-end neural architecture that jointly learns all three functions. The transmitter-side network compresses the input audio and directly produces complex-valued symbols for transmission. The receiver-side network reconstructs the audio from the received noisy symbols. In this sense, the communication link is optimized as one system rather than as a chain of loosely connected blocks.
At a high level, this is the role of JSCM in semantic audio communication. The model is trained over noisy channel conditions so that it learns not only how to compress speech, but also how to make that representation resilient to transmission impairments. This is the key difference from conventional neural audio codecs: the communication channel is part of the learning process itself.
There are, of course, many practical details behind this architecture, from model structure to waveform constraints and protocol integration. But for the purpose of this blog, the central point is simple: semantic audio communication becomes possible when compression and transmission are designed together rather than separately.
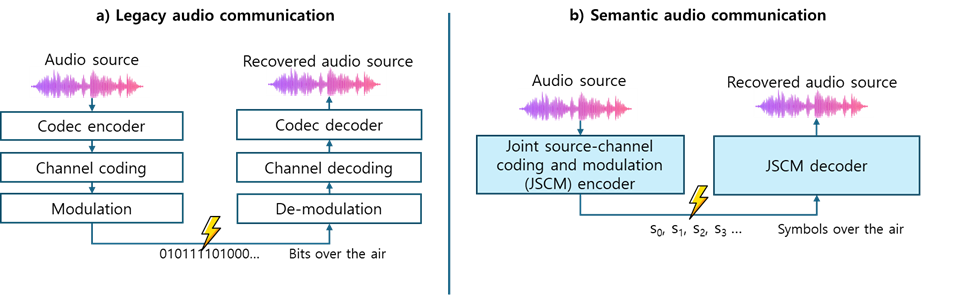
Figure 1. Communication architectures of: a) legacy audio communication, and b) semantic audio communication.
What Did We Test?
To evaluate whether this idea is just conceptually attractive or also practically useful, we validated it in two ways.
First, we built a 5G-based link-level simulator to study semantic audio communication under cellular conditions. This allowed us to compare our semantic JSCM system against conventional separation-based pipelines under controlled wireless impairments. Second, we built a hardware proof-of-concept (PoC) using Universal Software Radio Peripherals (USRPs), as shown in Fig 2, in a Bluetooth-band setup to test whether the same idea still works over a real air interface. Both evaluations were conducted using the LibriSpeech dataset [4], and benchmark systems were trained and tested under fair resource conditions.
This two-step validation matters. Simulation tells us whether the idea works under a realistic wireless model. Hardware testing tells us whether it survives contact with implementation constraint.
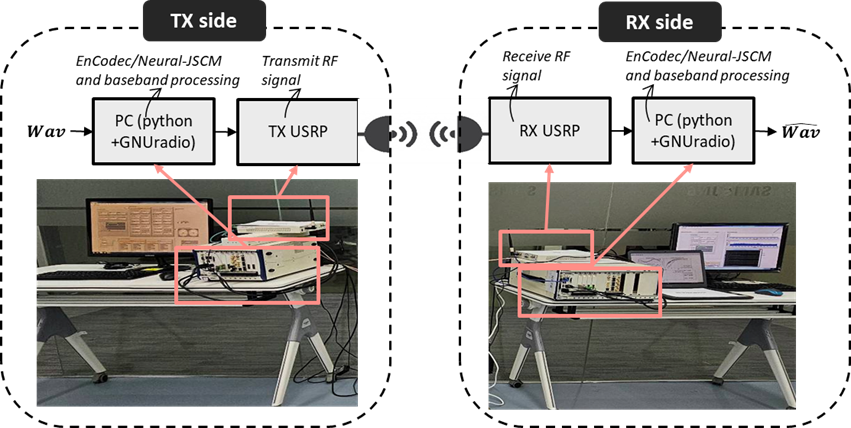
Figure 2. Architecture, signal processing procedure, and hardware illustration of the PoC testbed.
What We Observed
The most important result is straightforward: semantic audio communication can maintain similar perceptual quality at roughly 10 dB lower SNR or transmit power than conventional benchmark systems. This trend appears both in our 5G-based link-level simulations and in the hardware proof-of-concept.
In the simulation environment, the SAC-JSCM scheme (blue curve) consistently outperformed traditional source-channel separation across the tested SNR range, as illustrated in Fig 3. In practical terms, this kind of link budget gain could translate into meaningful improvements in coverage or transmit energy efficiency.
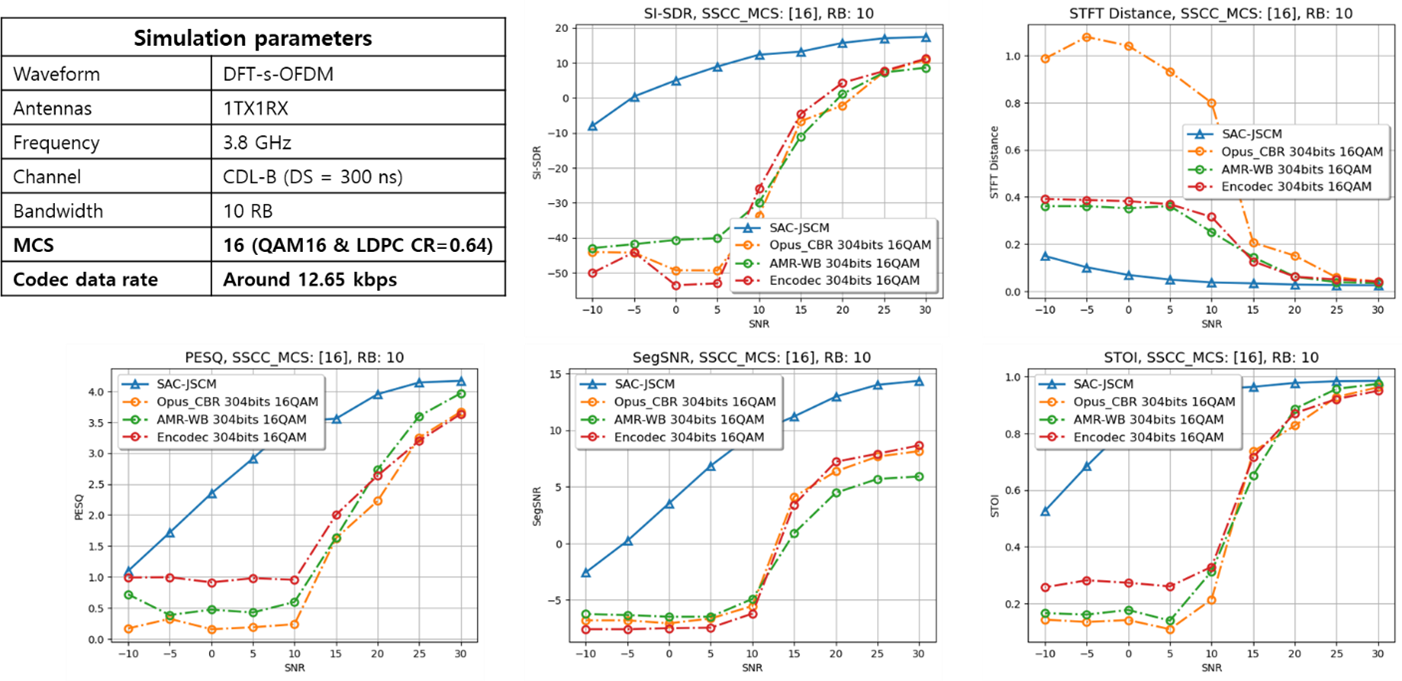
Figure 3. Simulation parameters and numerical results of LLS.
The hardware results were equally important. As shown in Fig 4, over the real wireless link, the PoC corroborates the trends observed in our LLS, where the SAC-JSCM scheme (blue curve) outperforms the benchmark across the entire range of transmission powers, delivering a gain of over 10 dB. Furthermore, the benchmark showed a much sharper cliff-effect as transmit conditions weakened, while the semantic approach degraded more gracefully and continued. That behavior is particularly attractive for real-world wireless systems, where performance under stress often matters more than peak performance in ideal settings.
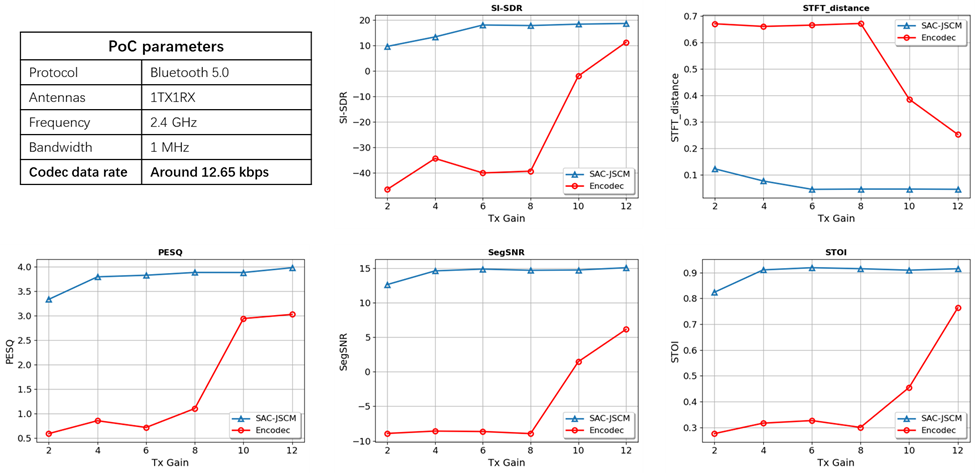
Figure 4. Parameters and numerical results of field test via hardware PoC.
Why This Matters
The broader implication is not just that speech transmission can be made more efficient. It is that the communication system itself can begin to optimize for what the user actually perceives, rather than only for what the bitstream dictates.
That shift matters most when resources are scarce. In a satellite link, it may enable native voice where only messaging is feasible today. In a wearable device, it may reduce transmission power enough to materially change battery life. In weak-coverage cellular conditions, it may extend the range over which speech remains usable. And in public safety situations, it may preserve critical coordination even when bandwidth is severely constrained.
Seen this way, semantic audio communication is not just a smarter codec or a new neural waveform trick. It is an early example of how future wireless systems may become more task-aware, perception-aware, and ultimately more efficient.
Conclusion
Semantic communication asks a simple but powerful question: what if wireless systems were designed to preserve meaning, not just bits?
Using audio as a starting point, we showed how an end-to-end semantic communication framework can outperform conventional designs in resource-constrained wireless settings. Our results from both 5G-based simulation and hardware prototyping suggest that semantic audio communication can deliver comparable perceptual quality with about 10 dB less signal power.
There is still work ahead in model robustness, generalization, and system integration. But the message is already clear: semantic communication is no longer only a theoretical idea. For audio, at least, it is becoming a practical direction for building more efficient wireless systems.
References
[1] Y. Shao, C. Qi, and D. Gündüz. "A theory of semantic communication." IEEE Transactions on Mobile Computing, 23.12 (2024): 12211-12228.
[2] Z. Weng and Z. Qin. "Semantic communication systems for speech transmission." IEEE Journal on Selected Areas in Communications, 39.8 (2021): 2434-2444.
[3] P. Vassil, et al. "Librispeech: an ASR corpus based on public domain audio books." IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015.