Communications
From Modules to Agents: An Automatic AI Inference Optimization Compiler for 5G RAN
1. Introduction
The 5G Radio Access Network (RAN) has rapidly become a fertile ground for artificial intelligence. Across both the physical layer (L1, PHY) and the data link layer (L2), AI models are increasingly being deployed to handle tasks once reserved for hand-engineered signal processing algorithms [1]. 3GPP has approved work items for AI/ML over the air interface, with AI-native transceiver technologies positioned as a key differentiator for 6G systems [2].
Yet running AI models inside a 5G base station is fundamentally different from running them in a cloud or edge inference server. The pipeline of a 5G gNodeB (gNB) operates under hard real-time constraints, and any AI module embedded in the receive or transmit chain must complete its inference within that budget while sharing the CPU with the rest of the signal processing stack.
General-purpose inference compilers such as TVM [3] or OpenVINO [4] are designed for very different deployment profiles; their overheads and code generation strategies rarely align with the tight latency budgets of an in-line RAN component. Closing this gap typically requires hand-written, AVX-512 [5] Single Instruction Multiple Data (SIMD) - tuned C++ kernels — a process that is slow, expert-intensive, and brittle as both AI architectures and target hardware evolve.
This post documents our effort to automate that gap. We have been developing a hardware-aware AI inference compiler that translates trained AI models into AVX-512 SIMD-optimized C++ kernels for direct integration into 5G RAN signal processing pipelines. The work has progressed in two stages: first a module-based compiler with a deterministic pipeline of analysis, optimization, and code generation modules; then a multi-agent compiler in which LLM-driven agents take over the roles previously hard-coded into modules.
The remainder of this post is organized as follows: Section 2 motivates inference optimization in the 5G RAN context; Section 3 describes the module-based compiler; Section 4 reflects on its achievements and limitations; Section 5 introduces the multi-agent compiler and presents results; and Section 6 concludes.
2. The Case for Automatic AI Inference Optimization Compiler
A modern 5G gNB processes radio signals through a layered protocol stack. The physical layer and the data link layer handle the most computationally intensive tasks — channel estimation, equalization, modulation, and scheduling — all of which must execute within the time boundary of a single transmission slot. AI models inserted into this pipeline inherit the same deadline. There is no grace period: a model that computes its output 50 microseconds late does not degrade gracefully — it breaks the pipeline entirely.
Modern server-class CPUs, including those used in commercial 5G Distributed Units (DUs), expose a powerful class of instructions called SIMD. Intel’s AVX-512 can process 512 bits of data in a single instruction cycle, enabling simultaneous computation on sixteen 32-bit floating-point values at once. For AI workloads dominated by matrix multiplications and convolutions, this translates to throughput gains of an order of magnitude over scalar code. However, exploiting AVX-512 effectively is not automatic: data must be aligned to 64-byte boundaries, computation tiles must fit inside L1 or L2 cache to avoid costly main-memory accesses, and instruction sequences must be carefully ordered to keep all execution units occupied. Hardware-aware optimization, therefore, means knowing exactly which registers and cache levels a given layer’s tensors occupy, and tiling the computation accordingly.
Given these requirements, a natural question is whether existing approaches can fill the gap. Historically, the highest-performing AI inference code in latency-critical environments has been written entirely by hand: optimization experts study the target hardware, translate the model into C++, and iterate experimentally until the fastest implementation emerges. This was the path we ourselves took initially, and it produces excellent code, but it scales poorly with the diversity of 5G RAN AI models and the pace at which target hardware evolves.
The alternative is a general-purpose AI compiler such as TVM or OpenVINO. However, these are designed around a fundamentally different set of assumptions: the inference runtime operates as an isolated process, the latency target is loose rather than 5G RAN slot-bound.
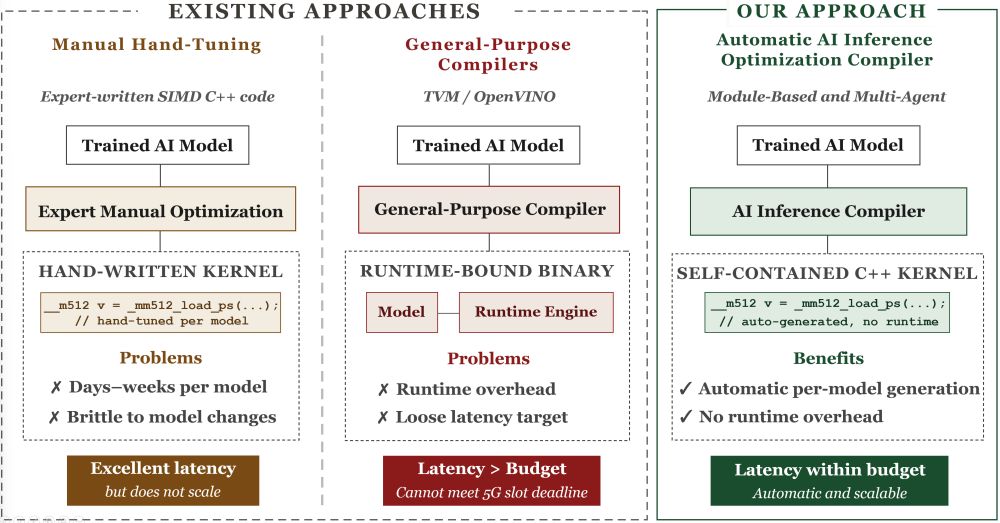
Figure 1. Existing approaches to AI inference optimization either fail to scale (manual hand-tuning) or fail to meet the latency budget of 5G RAN (general-purpose compilers), motivating our automatic AI inference optimization compiler.
This gap — between what general-purpose AI compilers provide and what a real-time 5G RAN pipeline demands — is what motivated us to build our own hardware-aware AI inference compiler from the ground up. As Fig. 1 illustrates, existing approaches either fail to scale (manual hand-tuning) or fail to meet the slot-level latency budget (general-purpose compilers), leaving an unmet need that our compiler is designed to fill. Rather than adapting an existing compiler to a new deployment target, we chose to generate AVX-512 SIMD C++ kernels tailored to the exact microarchitecture and cache topology of the target DU platform.
3. First Generation: A Module-Based Compiler
Our first attempt at automating the kernel generation process took the form of a deterministic, module-based compiler structured as a clean three-stage pipeline — parse, optimize, generate — that mirrored the established design pattern of classical AI compilers, adapted to the demands of 5G RAN deployment. The objective was twofold: to capture the manual optimization workflow in a reproducible software form, and to do so without introducing any runtime dependency. Every model that entered the compiler had to leave as a self-contained C++ source and object file that could be linked by a standard toolchain and dropped directly into the DU codebase.
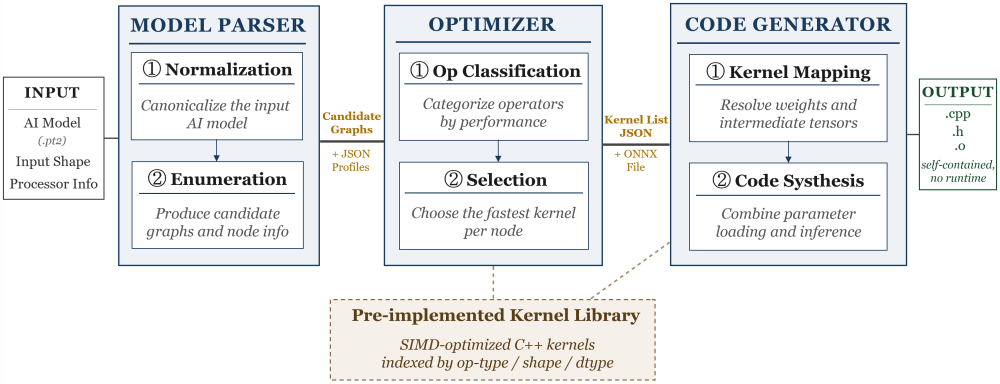
Figure 2. The module-based compiler operates as a deterministic three-stage pipeline. Each module hands off a structured artifact (Candidate Graphs, Kernel List) to the next, with all final choices grounded in measurement.
Fig. 2 illustrates the overall architecture. The Model Parser normalizes the input model and prepares a structured representation that exposes optimization opportunities for downstream stages. The Optimizer then evaluates candidate kernel implementations on the target hardware and selects the fastest realization for each operator. Finally, the Code Generator materializes the resulting design as complete C++ code. The design makes a deliberate trade-off — empirical evaluation over heuristic search — in exchange for output that is reproducible, inspectable, and free of runtime surprises.
3.1 Model Parser
The Model Parser is the entry point of the compiler. It accepts a trained model — supplied in a common deep learning framework format — together with the input tensor shape and a description of the target processor, and converts this into a structured representation that downstream stages can consume deterministically. Internally, the Parser performs this work in two phases.
The first phase normalizes the input model into a canonical graph representation, eliminating framework-specific code paths and stripping away artifacts left over from training or export so that every remaining node corresponds to a real, performance-relevant computation. The second phase enumerates candidate graph variants by applying a predefined set of operator fusion rules in different combinations, and annotates each candidate with the per-node metadata that downstream stages will need. Rather than committing to a single fused graph through a heuristic, the Model Parser produces the full set of candidates so that the final choice can be settled by measurement later in the pipeline.
3.2 Optimizer
The Optimizer acts as the empirical core of the compiler. Its objective is to map every operator in a candidate graph to the kernel implementation that runs fastest on the target hardware. Unlike traditional frameworks that rely on analytical cost models to estimate performance, our Optimizer is designed around a “hardware-in-the-loop” philosophy: mapping decisions are grounded in actual behavior on the target 5G RAN hardware.
Internally, the Optimizer first classifies operators by their performance characteristics and routes each through the evaluation strategy best suited to it — some operators benefit from empirical measurement against multiple kernel variants, while others can be resolved through lightweight static rules without incurring measurement overhead. The Optimizer then selects and validates the chosen kernels: any candidate graph whose kernels fail to execute correctly is discarded immediately, and the surviving mappings are serialized as the primary input for the Code Generator.
3.3 Code Generator
The Code Generator takes the optimization decisions produced by the Optimizer and turns them into deployable C++ code. The overall flow proceeds in two phases.
In the first phase, the generator traverses the graph and maps each operator to its assigned kernel implementation, resolving the necessary context for code emission — model weights, intermediate tensor declarations, and the connective logic between successive kernels. In the second phase, it synthesizes the final source, combining parameter loading code with the inference pipeline into a single, self-contained C++ file. By automating these phases end to end, the Code Generator delivers optimized inference code immediately whenever the input model or kernel set changes, eliminating any need for manual code modification.
4. Achievements and Limitations of the Module-Based Compiler
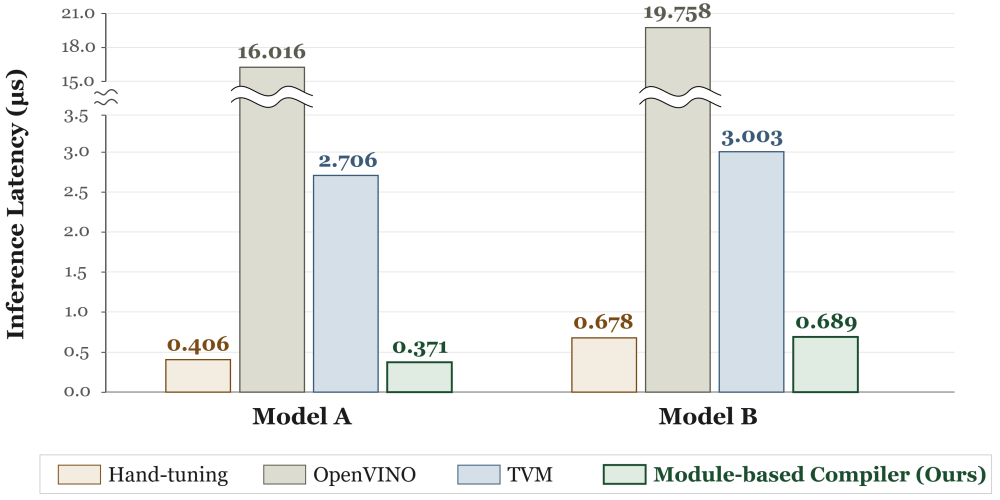
Figure 3. The module-based compiler reaches latency parity with expert hand-tuned implementations, far outperforming general-purpose compilers (TVM, OpenVINO) while reducing the time to product a deployable C++ kernel from days of manual work to a single invocation.
Before turning to its limitations, it is worth taking stock of what the module-based compiler actually delivered. The most immediate gain was development velocity. Where the previous workflow — analyzing target hardware by hand, drafting an optimization strategy, and writing AVX-512 C++ kernels line by line — could occupy a senior engineer for days or weeks per model, the compiler reduced that turnaround to a single automated invocation. A new model checkpoint could be passed in, and a deployable C++ source bundle would emerge with no human intervention in between.
Equally important, the quality of the output held up. We measured the average inference latency on the single core of server-class Intel CPU with fixed frequency. As shown in Fig. 3, the module-based compiler reaches latency parity with carefully hand-tuned baselines on small DNN-based 5G RAN AI models. The contrast with general-purpose AI compilers was even sharper: when the same models were executed under TVM or OpenVINO, neither could reach the latency envelope demanded by an in-line RAN component, falling short by more than an order of magnitude. Their generated code, optimized under assumptions of a standalone inference process and loose latency targets, simply did not fit the tight budget of a 5G slot. Our module-based compiler — by emitting self-contained AVX-512 kernels with no runtime, no scheduler, and no engine to coexist with — was the only configuration in our evaluation that produced AI inference fast enough to be deployable inside a real-time RAN signal processing pipeline.
These gains, however, came with a structural ceiling that became increasingly visible as we attempted to scale the compiler to more models and more hardware variants. The most pressing limitation was the dependence on the pre-implemented kernel library. Although the compiler chose between candidate kernels intelligently, every kernel still had to be written by hand. Adding support for a new operator type — a layer normalization variant, an attention primitive, an unfamiliar activation — required an expert engineer to design, implement, vectorize, and validate a new SIMD kernel before the compiler could even consider the operator. If a model arrived containing an operator for which no implementation existed, the compiler simply could not produce output. The automation we had achieved was conditional on a manually maintained library, and that library scaled linearly with engineering effort.
A second limitation lay in the rule-based graph optimization itself. The fusion rules captured the optimization patterns we had already understood, but they captured nothing else. Modern AI architectures, particularly those customized for specific 5G RAN tasks, frequently introduce structural patterns that fall outside any pre-enumerated rule: unconventional skip connections, operator orderings that hint at fusable subgraphs without matching a known template, or layer compositions where the optimal SIMD strategy is not a fusion at all but a re-tiling or a memory-layout transformation. For such graphs the compiler would still produce correct, deployable code, but the resulting inference latency was almost certainly suboptimal — the compiler had no way to recognize the optimization opportunity, let alone act on it.
Taken together, these limitations pointed in a single direction. What the compiler lacked was not more rules or more kernels, but the ability to reason about novel operators and unfamiliar graph structures the way a human expert does — by drawing on broad knowledge, recognizing patterns by analogy, and proposing optimization strategies that no rule had been written for. This is precisely the kind of open-ended inference that recent advances in large language models have begun to make tractable as a software component. Section 5 describes the multi-agent compiler that emerged from this question.
5. Second Generation: The Multi-Agent AI Inference Optimization Compiler
Closing the gap identified in Section 4 is not a matter of building a larger rule table or a richer kernel library — both approaches simply postpone the same scaling problem. What is needed is a different decision-making substrate, one that can interpret an unfamiliar operator from context, propose an optimization strategy by analogy with prior cases, and write the corresponding SIMD C++ code on the spot. These are the capabilities that modern large language models have begun to exhibit in software-engineering domains [9].
Even within the rule space the module-based compiler did cover, its decisions were locally optimal but globally rigid; an LLM-based reasoning component, by contrast, can weigh the broader graph context and recognize when a particular sequence would benefit from being split rather than fused given its tensor shapes and the target cache layout. Combining these two needs — open-ended operator handling and context-sensitive optimization — into a single monolithic LLM call is impractical. The natural design response is to decompose the task across multiple cooperating agents [10], orchestrated as a pipeline that mirrors the compilation flow.
5.1 A Feasibility Study: Can an LLM Write Production-Quality SIMD Kernels?
Before committing engineering effort to a full multi-agent architecture, we needed to answer a more fundamental question: could an LLM, given an appropriate description of the task, actually produce SIMD C++ kernel code competitive with that written by an expert by hand? Low-level intrinsic programming has long been considered one of the last domains where human expertise was indispensable. If the answer were no, no amount of orchestration logic could compensate, and the multi-agent direction would be a dead end.
The experiment compared LLM-generated SIMD kernels against the hand-written kernels already used by the module-based compiler, on two operators that exercise very different optimization patterns: Conv2D, which is dominated by structured data reuse, and Fully Connected, whose performance hinges on dense matrix-multiplication efficiency. We varied the amount of context supplied to the model across four prompt levels. Level 1 provided only the operator name and SIMD support. Level 2 added input/output shape, data type, and AI model architecture. Level 3 further included optimization strategy hints such as preferred loop tiling dimensions, register blocking, and memory alignment requirements. Level 4 supplied the full set of hardware information available to a human expert, including expected register assignment strategy, FMA pipeline utilization, and cache hierarchy details. We measured all performances on the isolated same single core of server-class Intel CPU with fixed frequency.
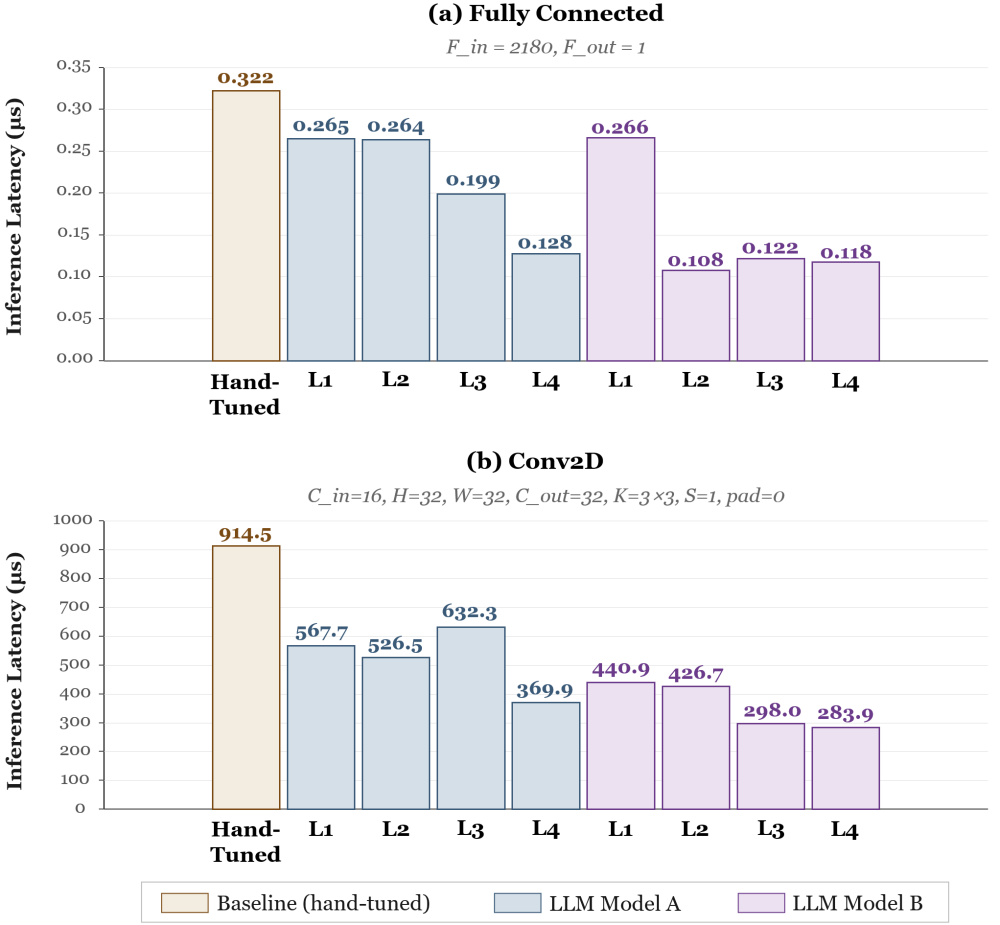
Figure 4. Across both operators, kernels generated at higher prompt levels approach or surpass the hand-tuned baseline, confirming that an LLM supplied with structured hardware and shape context can produce expert-quality SIMD code.
Fig. 4 summarizes the results. Across both operators and across the LLM models we tested, kernels generated at the higher prompt levels consistently surpassed the hand-written baselines. The improvement curve from Level 1 to Level 4 was almost monotonic, confirming that LLM-generated low-level code is highly sensitive to the precision of the contextual information it is given — a result with direct implications for how a multi-agent compiler should structure information flow into its codegen agents. The Level 4 kernels in particular, which received the same kind of structured hardware context that an expert engineer would assemble before writing SIMD code, demonstrated that the LLM was applying the supplied constraints to produce kernels tuned to the specific deployment scenario rather than merely pattern-matching against memorized snippets.
5.2 Architecture and Methodology of the Multi-Agent Compiler
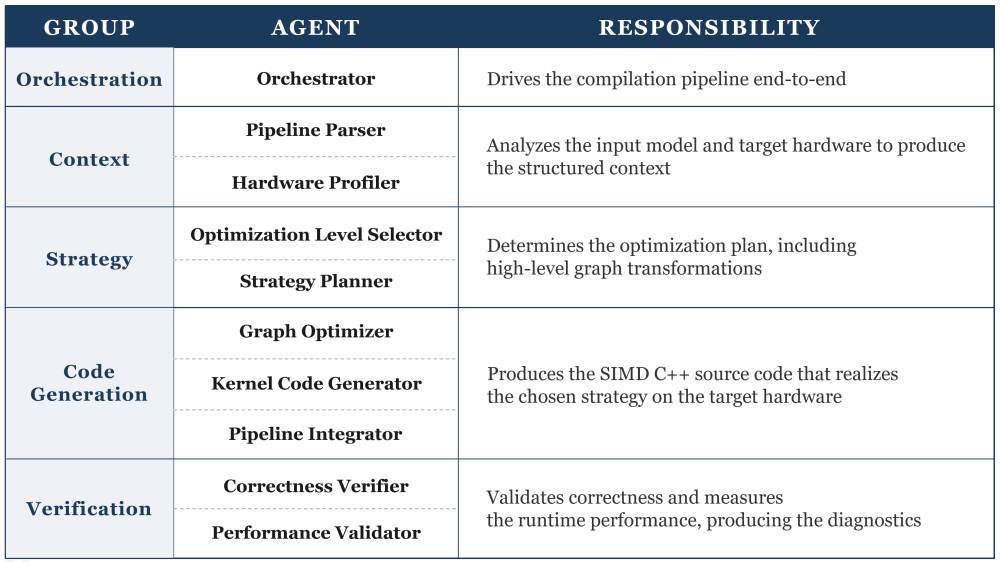
The multi-agent compiler reconstitutes the work that the module-based system performed inside fixed Python modules into a collaboration of specialized reasoning agents, organized into functional groups and coordinated by a single Orchestrator. Each agent inherits a narrow responsibility within its group, but executes it through LLM reasoning grounded in structured context. To our knowledge, no prior AI compiler has been built around this design: not as a wrapper over an LLM that emits code, but as an end-to-end compilation pipeline whose every analysis, optimization, and code-generation decision is delegated to a reasoning agent. Table 1 summarizes the agent organization, and Fig. 5 shows the corresponding pipeline structure with its feedback loop.
Table 1. Functional Groups of the Multi-Agent AI Inference Optimization Compiler
Three methodological principles govern how AI is used inside this system, and together they distinguish it from a naive “compiler-as-prompt” approach. The first principle is strict task scoping. Each agent is given a tightly-bounded prompt template that defines what it may decide, what it must output, and — equally importantly — what it must not attempt. This containment prevents the cascade of silent re-interpretations that occurs when an LLM is given latitude beyond its station, and makes each agent’s behavior independently testable.
The second principle is the delegation of deterministic work to Python tooling. A surprising amount of what looks like reasoning in a compiler is, on inspection, mechanical: parsing ONNX graphs, extracting tensor shapes, comparing numerical outputs, measuring elapsed time. Tasking an LLM with these operations introduces randomness with no upside. We therefore identified every deterministic sub-task and implemented it as a Python script that the relevant agent invokes as a tool. The LLM is invoked only where genuine judgment is required: choosing a fusion strategy, drafting a kernel, diagnosing a bottleneck. This separation of judgment from computation is the single most important factor in keeping a multi-agent system reliable enough for production use.
The third principle is a retrieval-augmented memory of past compilations [11], complemented by a feedback loop that lets the system recover from suboptimal first attempts. Successful kernels and end-to-end compilations are written to a repository indexed along the dimensions that characterize a compilation request. When a new compilation begins, the corresponding script retrieves matching entries and supplies them as in-context examples to the strategy and code-generation groups. Retrieval is only one half of the story. Once the Verification group detects that the latency budget has been missed, the Orchestrator routes a structured diagnostic back to the Strategy group, which re-plans the optimization strategy with this new information in hand. Together, the repository and the feedback loop turn the compiler into a system that improves both across invocations (through accumulated experience) and within a single invocation (through measurement-driven re-planning) — a property that no rule-based or auto-tuning compiler can claim.
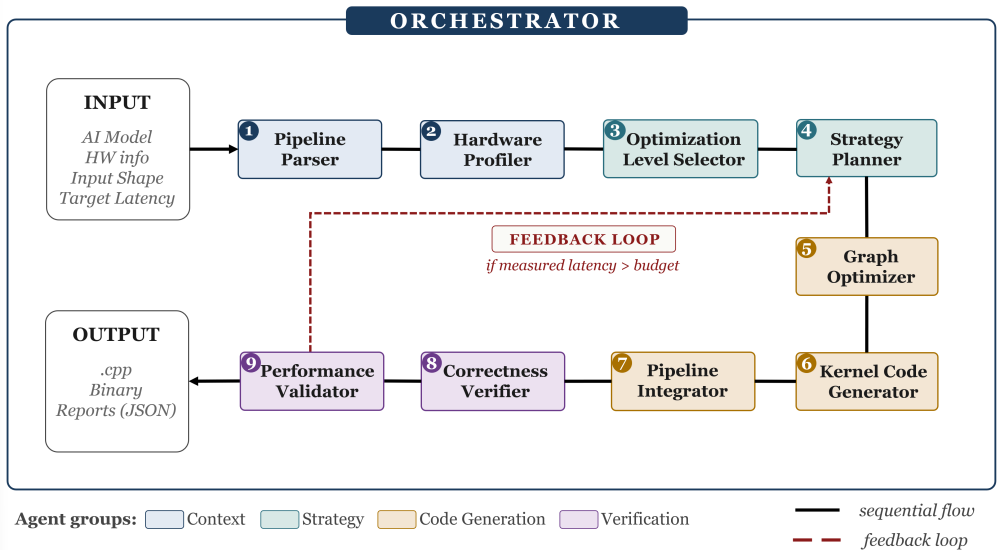
Figure 5. Architecture of the Multi-Agent AI Inference Optimization Compiler — Sequential execution of nine agents under a single Orchestrator, with a feedback loop on missed latency budgets.
5.3 Results and Discussion
We evaluated the multi-agent compiler on a representative collection of AI models drawn from 5G RAN signal-processing tasks, spanning three broad architectural families: compact DNNs, convolutional networks, and Transformer variants. For each model, we measured end-to-end inference latency under two configurations: expert-written hand-tuned C++ code and code generated by the multi-agent compiler. All measurements were performed on the same target single core of server-class Intel CPU with fixed frequency, averaged across 10,000 runs.
Fig. 6 summarizes the results, aggregated per architectural family. In every category, the multi-agent compiler produced lower average inference latency than the hand-tuned baseline. The fact that this advantage holds across architectural families spanning several orders of magnitude in workload size — without any per-family tuning — is itself a notable result: it shows that the compiler’s advantage is not specific to a particular workload class but generalizes across the diversity of models actually encountered in 5G RAN deployment.
Three factors, in our analysis, account for this outcome. The first factor concerns the scope of optimization reasoning. Hand-tuned code and the module-based compiler both ultimately rely on humans to look at a model and decide how to optimize it; for complex graph structures, the cognitive overhead of holding the entire computation graph in mind quickly exceeds what an engineer can reliably manage. The LLM-driven Strategy group can ingest the full graph as a single prompt, and reason about global optimization opportunities — cross-layer fusions, layout transformations spanning multiple operators, redundant data movement at non-adjacent nodes — that a human optimizer would miss not for lack of skill but for lack of bandwidth.
The second factor is the adaptability of code generation. The hand-tuned and module-based approaches are fundamentally constrained by the kernel library available to them. The multi-agent compiler suffers no such ceiling: the Code Generation group produces an AVX-512 SIMD kernel tailored to the exact operator, shape, and target microarchitecture of the request at hand, every time. The library is no longer a library but an open-ended generation capability — a structural difference that compounds as the diversity of input models grows.
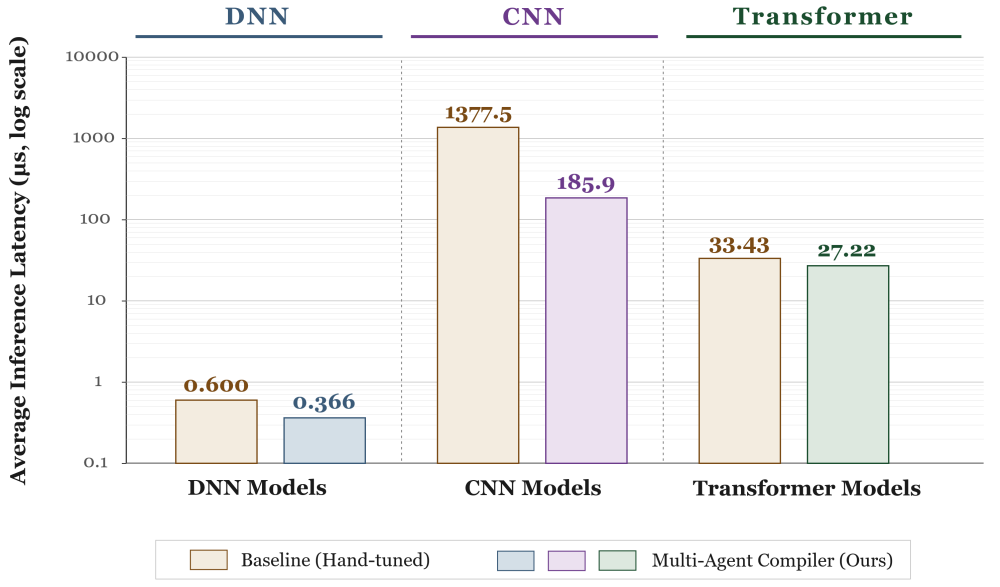
Figure 6. The multi-agent compiler outperforms hand-tuned baselines across all architectural families.
The third factor is the cumulative effect of the methodological design choices. Strict task scoping prevents any single agent from drifting outside its competence. The delegation of deterministic operations to Python tools removes a class of failure modes that would otherwise erode reliability. The feedback loop gives the compiler the freedom to take an aggressive optimization plan on its first pass and recover gracefully when the resulting latency falls short — something a one-shot pipeline simply cannot do. And the RAG-style repository ensures that every successful compilation contributes to the system’s future performance. None of these mechanisms is individually exotic, but their combination is what made low-level SIMD code generation by an LLM consistently better than expert work.
6. Conclusion
This blog has traced two generations of an automatic AI inference optimization compiler designed to meet the microsecond-level latency demands of 5G RAN signal processing. The first generation, a deterministic module-based compiler structured as Model Parser, Optimizer, and Code Generator, automated the manual optimization workflow into a reproducible three-stage pipeline producing self-contained AVX-512 SIMD C++ kernels. The second generation, an LLM-driven multi-agent compiler, replaced the rule-based decision substrate with nine cooperating reasoning agents coordinated by an Orchestrator, governed by three methodological principles — strict task scoping, delegation of deterministic work to Python tooling, and a RAG-style repository — and equipped with a feedback loop that re-plans optimization strategies when the latency budget is missed. Across our evaluation set, the multi-agent compiler delivered inference latencies that were on average 46.4% faster than expert hand-tuned implementations.
What this work reaffirms is that bringing AI into the RAN is not solved by a well-trained model alone: equally critical is whether that model can run fast enough to live inside the real-time pipeline it was meant to serve. Our compiler addresses precisely this half of the problem, turning what was once a multi-week manual engineering effort into a single automated invocation that produces deployment-ready AVX-512 SIMD C++ code. Within Samsung Research’s AI-native RAN roadmap, this compiler occupies the deployment-enabling layer that lets every AI model actually reach the inference budget the radio interface demands. As the diversity and sophistication of RAN AI workloads continue to grow, we expect the same architecture to keep pace with them.
References
[1] C. -X. Wang, M. D. Renzo, S. Stanczak, S. Wang and E. G. Larsson, "Artificial Intelligence Enabled Wireless Networking for 5G and Beyond: Recent Advances and Future Challenges," in IEEE Wireless Communications, vol. 27, no. 1, pp. 16-23, February 2020.
[2] 3GPP, “Study on Artificial Intelligence (AI)/Machine Learning (ML) for NR air interface,” 3rd Generation Partnership Project (3GPP), Technical Report (TR) 38.843, Release 18, 2024.
[3] T. Chen, T. Moreau, Z. Jiang, L. Zheng, E. Yan, M. Cowan, H. Shen, L. Wang, Y. Hu, L. Ceze, C. Guestrin, and A. Krishnamurthy, “TVM: An Automated End-to-End Optimizing Compiler for Deep Learning,” in Proc. 13th USENIX Symp. Operating Systems Design and Implementation (OSDI), Carlsbad, CA, USA, Oct. 2018, pp. 578–594.
[4] Intel Corporation, “OpenVINO Toolkit: Open-source toolkit for optimizing and deploying AI inference,” 2018. [Online]. Available: https://docs.openvino.ai/
[5] Intel Corporation, “Intel® Architecture Instruction Set Extensions and Future Features Programming Reference,” Order Number 319433-061, Mar. 2026.
[6] ONNX Project Contributors, “ONNX: Open Neural Network Exchange,” Github Repository, 2017. [Online]. Available: https://github.com/onnx/onnx
[7] D. Jin, “onnx-simplifier: Simplify your ONNX model,” GitHub Repository, 2019. [Online]. Available: https://github.com/daquexian/onnx-simplifier
[8] Google, “Protocol Buffers: A language-neutral, platform-neutral extensible mechanism for serializing structured data,” 2008. [Online]. Available: https://protobuf.dev/
[9] A. Fan et al., "Large Language Models for Software Engineering: Survey and Open Problems," in 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE), Melbourne, Australia, 2023, pp. 31-53.
[10] Q. Wu, G. Bansal, J. Zhang, Y. Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. Awadallah, R. White, D. Burger, and C. Wang, “AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation,” in Proc. Conf. on Language Modeling (COLM), 2024.
[11] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. Yih, T. Rocktäschel, S. Riedel, and D. Kiela, “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” In Neural Information Processing Systems (NIPS '20), Vol 33, 2020, pp. 9459–9474.