AI
LookaheadKV: Fast and Accurate KV Cache Eviction by Glimpsing into the Future without Generation
1. Introduction
The deployment of Large Language Models (LLMs) for long-context applications is fundamentally constrained by the memory footprint of the Key-Value (KV) cache. As the sequence length increases, the memory required to store KV states grows linearly, leading to severe GPU memory bottlenecks and degraded inference throughput.
To mitigate this, KV cache eviction strategies [1, 2, 9, 11] are often employed to retain only the most critical tokens. However, determining an optimal eviction policy inherently requires anticipating which tokens will be necessary for future generation. Existing approaches [4, 7] attempt to estimate this future attention by utilizing draft models to explicitly generate surrogate tokens. This explicit autoregressive generation introduces substantial latency and computational overhead, often offsetting the intended efficiency gains of eviction.
We present LookaheadKV, a novel framework introduced at ICLR 2026, designed to resolve this accuracy-overhead trade-off. Rather than generating explicit draft tokens, LookaheadKV directly predicts future attention patterns to accurately estimate token importance. This is achieved through the integration of parameter-efficient mechanisms—specifically, learnable lookahead tokens combined with specialized LoRA modules—allowing the model to "glimpse" into future attention distributions with minimal computational cost.
In this post, we detail the underlying mechanics of the LookaheadKV architecture and examine its effectiveness on long-context LLM inference.
2. Background
KV Cache Bottleneck: During the autoregressive decoding phase of Transformer-based LLMs, previously computed Key and Value (KV) states are cached to avoid redundant matrix computations. While this mechanism is essential for maintaining inference speed, the memory required to store the KV cache scales linearly with the sequence length. In long-context applications, this memory footprint rapidly consumes available GPU VRAM, restricting maximum sequence lengths and severely limiting batch sizes and overall system throughput.
Heuristic-Based KV Cache Eviction: To alleviate this memory constraint, KV cache eviction methods [1, 2, 9, 11] are designed to maintain a manageable cache budget by dynamically discarding tokens. Conventional approaches primarily rely on heuristic indicators, such as historical or current attention scores, to approximate token importance. For instance, SnapKV [1] uses the suffix of input prompt to compute the estimate of the future importance scores.
However, these heuristic-based methods are fundamentally limited by their reliance on past contextual states. Attention mechanisms are highly dynamic; a token that appears insignificant during the initial prompt processing phase may become structurally critical during subsequent generation steps. Therefore, relying solely on historical attention distributions often leads to the eviction of essential tokens, resulting in context degradation.
Draft-Based Approaches: Recently, several studies [4, 7] reveal that leveraging the model's response, rather than the input prompt, can greatly improve the eviction quality. They have proposed to use a low-cost generator to generate a (partial) approximate response first, and subsequently use it to estimate the future importance scores. By simulating the future context, the model can approximate future attention demands and adjust the KV cache accordingly.
While this draft-based approach improves the accuracy of the eviction policy compared to heuristics, it introduces intrinsic latency. The explicit autoregressive generation of these draft tokens incurs significant computational overhead, establishing a clear trade-off between eviction accuracy and actual overhead.
3. Method
To overcome the challenge of fast and accurate importance prediction, we introduce LookaheadKV, a framework that augments the LLM with a set of lightweight learnable modules which are optimized to predict ground‑truth importance scores. LookaheadKV achieves the best of both worlds by glimpsing into the future without generation: 1) it eliminates the need for the explicit draft generation step, resulting in significantly faster KV cache eviction. 2) it employs learned special tokens that serve as implicit future response for importance estimation, leveraging the strength of draft-based methods without their computational overhead.
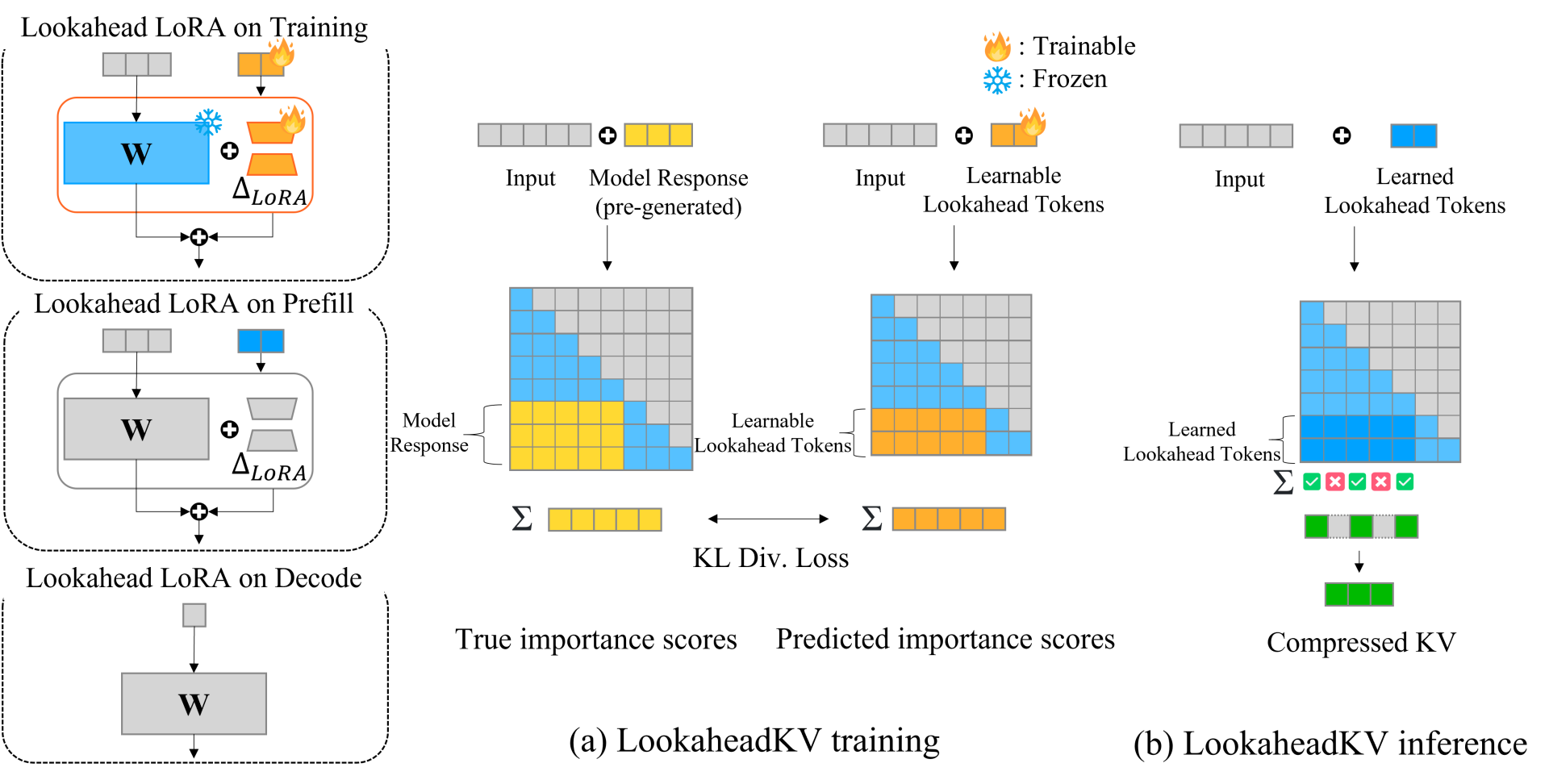
Figure 1. An overview of LookaheadKV (a) Training: During training, lookahead tokens and lookahead LoRA are trained to predict the ground-truth importance scores obtained with pre-generated model response via a KL divergence loss. (b) Inference: During prefill, LookaheadKV utilizes the learned modules to identify essential tokens and compress the KV cache, facilitating memory-efficient decoding
3.1. Main Components
Learnable Lookahead Tokens: LookaheadKV performs KV cache eviction using a set of learnable special tokens during the prefill phase, followed by auto-regressive decoding with the preserved KV cache. For a given input sequence X, our framework appends a sequence of trainable soft lookahead tokens $P=\{p_1,…,p_{n_{lookahead}}\}$ whose queries in each attention head are used to estimate the attention pattern of the true model response. In other words, these tokens are trained to compress the attention information of the true response to serve as the “observation window” in the eviction phase. These are initialized randomly and added to the vocabulary before training. Note that the lookahead tokens are used during the prefill stage only for eviction, and introduce no overhead for the decoding stage.
Lookahead LoRA: To enhance the quality of estimation, we introduce lookahead LoRA, a novel low-rank adapter module that only activates for the lookahead tokens. Lookahead LoRA provides complementary performance gains by allowing these tokens to learn richer representations, enabling their queries to more accurately predict token importance. The selective activation mechanism of the LoRA modules ensures that the outputs of normal input tokens are unchanged, preserving the original model behavior. Since the original model weights remain unaltered, LookaheadKV modules can be selectively enabled or disabled depending on the particular requirements of a given application, thereby broadening the method’s applicability.
Combining the modules together, LookaheadKV computes the queries and keys of the complete sequence as follows:
$Q_{LKV}= {X \atopwithdelims [ ] P}W_q + {0 \atopwithdelims [ ] P}∆W_q, ~~~~ K_{LKV}= {X \atopwithdelims [ ] P} W_k + {0 \atopwithdelims [ ] P}∆W_k,$
where $P$ denotes the hidden states of the lookahead embeddings, and $∆W_q$, $∆W_k$ are the lookahead LoRA modules for query and key projections. Similar to prior methods [1, 2, 11], we use the attention matrix $ A_{LKV}=Softmax(\frac{Q_{LKV} K_{LKV}^T}{\sqrt d}) $, to estimate the importance score $ \widetilde{s_j} = \frac{1}{n_{lookahead}}\sum_{i = n_{in} +1}^{n_{in} +n_{lookahead}} A_{LKV ~~ i,j} $ , and retain Top-K KV pairs with the highest importance scores.
3.2. LookaheadKV Training
We train LookaheadKV modules to compress the attention pattern of the true future response, using the model-generated responses as target. Given a data pair (X,Y), one iteration of LookaheadKV training consists of the following steps:
$ L_{LKV}=\frac{1}{L⋅H} \sum_{l}^{L} \sum_{h}^{H} D_{KL}(\hat{s}_{GT}^{l,h} || \hat{s}_{LKV}^{l,h}), $
Training Objective: Inspired from works on distilling attention scores [6, 8], we minimize the KL divergence between these normalized attention scores. As our attentions scores are normalized, this KL divergence is equivalent to the popular ListNet [12] ranking loss, with ϕ of ListNet as identity instead of exp.
4. Results
We evaluate LookaheadKV on a comprehensive suite of benchmarks: LongBench [14], RULER [5], LongProc [10], and MT-Bench [13]. We compare LookaheadKV against popular KV cache eviction methods: 1) SnapKV [1], 2) PyramidKV [2], 3) StreamingLLM [9]. Additionally, we include stronger, more recent baselines that involve costly approximate future response generation, including 4) Lookahead Q-Cache (LAQ) [7], and for 8B-scale models, 5) SpecKV [4].
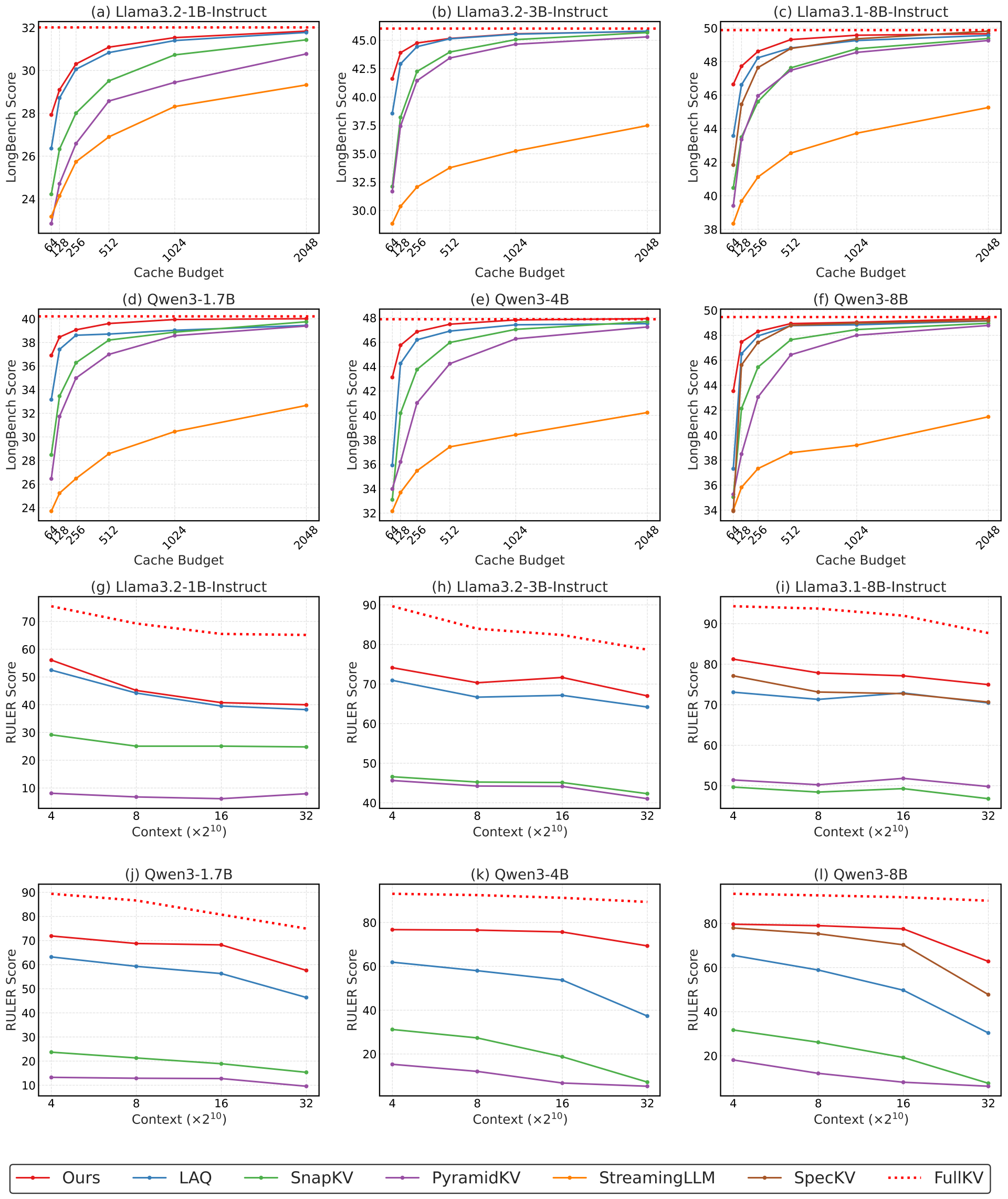
Figure 2. Upper rows: Average LongBench results across multiple budgets and models. Lower rows: Average RULER results across varying context lengths with a fixed budget of 128. Across all tested models, budgets and context lengths, LookaheadKV consistently demonstrates superior performance.
LongBench Evaluation: Figure 2 shows the average LongBench [14] scores of LookaheadKV and baselines, across cache budget settings ranging from 64 to 2048. LookaheadKV consistently demonstrates superior performance across all models and all budgets tested, demonstrating the effectiveness and robustness of our approach. Overall, results show that expensive draft-based methods (e.g., LAQ and SpecKV) outperform simple baselines, corroborating that employing approximate future response for importance estimation is effective. Nevertheless, LookaheadKV significantly outperforms draft-based approaches, especially at lower budget settings, highlighting that learning to estimate future importance is crucial for performance preservation.
RULER Evaluation: We report the RULER [5] evaluation results of all methods with a fixed budget of 128 in Figure 2. LookaheadKV consistently outperforms other baseline approaches here as well, maintaining strong performance across all evaluated context lengths. Despite being trained on a maximum sequence length of 16K, LookaheadKV effectively generalizes to a longer context length of 32K.
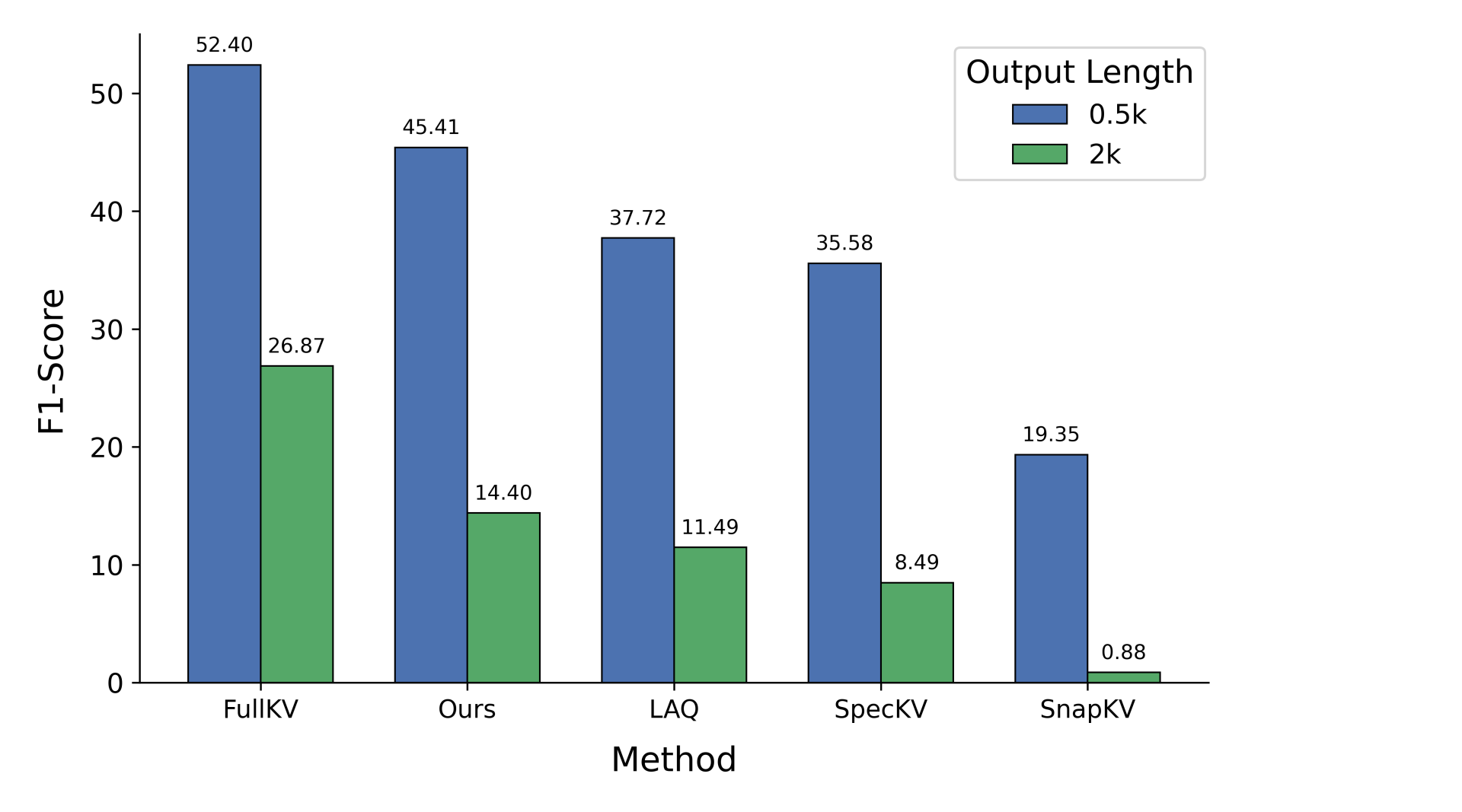
Figure 3. HTML-to-TSV evaluation results using LLaMA3.1-8B.
Long-form Output Evaluation: To further validate LookaheadKV's ability to generate long-form outputs, we evaluate it on the HTML to TSV task from LongProc [10]. Across both sequence-length configurations, LookaheadKV consistently outperforms prior approaches. We hypothesize that LookaheadKV, learning to predict the attention pattern of the entire future response, is particularly superior in long-form generation tasks compared to draft-based methods that rely only on partial future response as the observation window.
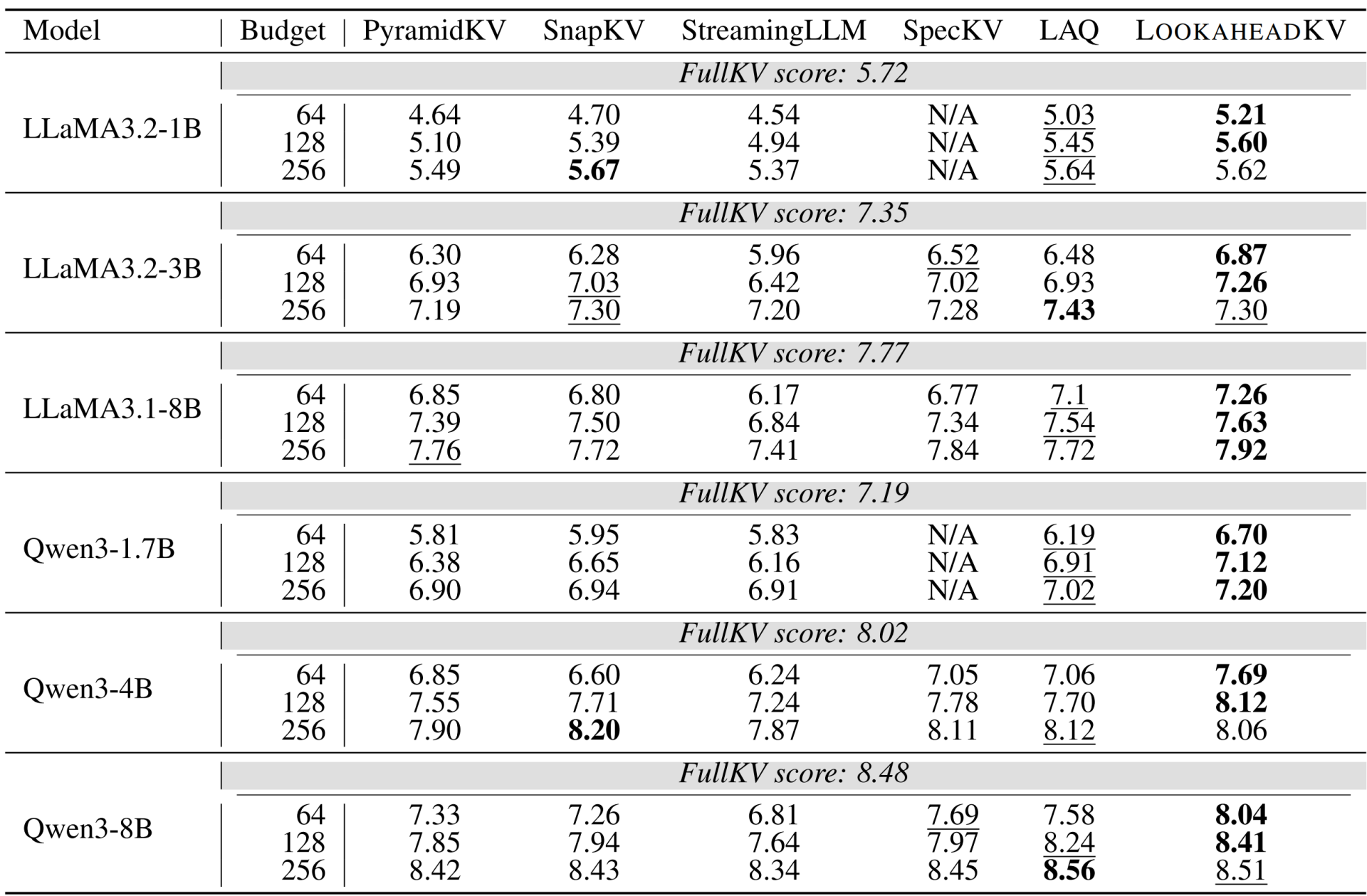
Table 1. MT‑Bench evaluation results. Bold and underlined values indicate best and second best scores, respectively.
Multi-turn Evaluation: To test LookaheadKV under multi-turn conversation setting, we evaluate LookaheadKV and baselines on MT-Bench [13]. The results in Table 1 indicate that LookaheadKV is either on par or superior across all models and budgets tested. LookaheadKV is particularly robust in lower budget settings, where it consistently outperforms all other methods.
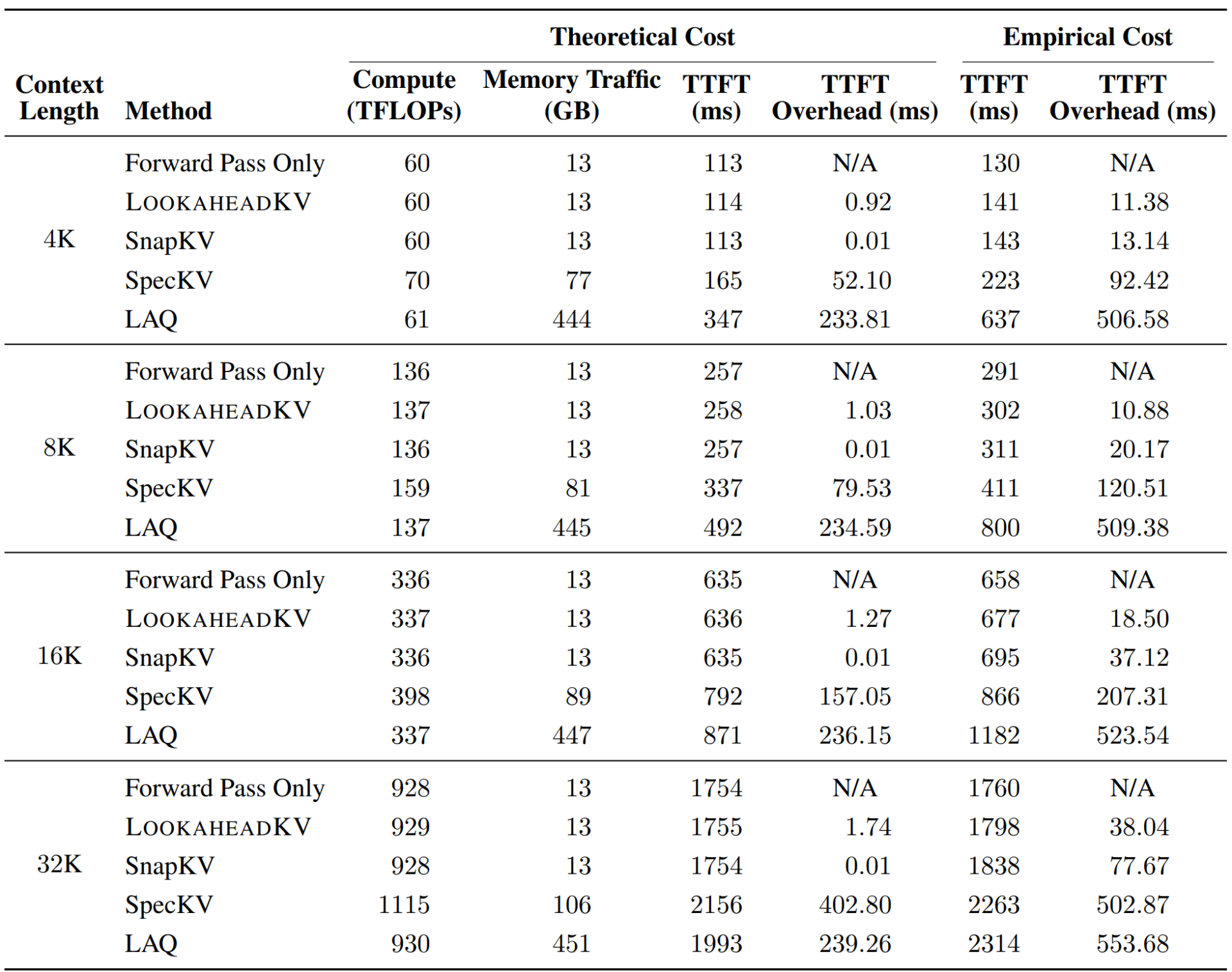
Table 2. Theoretical and empirical cost analysis of LLaMA3.1-8B with a cache budget of 128.
Efficiency: Efficiency is assessed by measuring the Time-To-First-Token (TTFT) for LLaMA-3.1-8B across multiple context lengths. Because the latency of a method can vary significantly depending on the implementation, we conduct rigorous analysis and derive the theoretical latency for each method, based on the analytical model proposed in [3].
Table 2 presents the results of the TTFT analysis from 4K to 32K context length. Overall, we observe that draft-based methods incur significant overhead, either due to increased computation or memory traffic. On the contrary, LookaheadKV requires marginal additional cost across all tested context lengths, reducing eviction overhead by 14.5× compared to LAQ at 32K sequence length.
5. Conclusion
In this post, we explored LookaheadKV, a novel KV cache eviction framework that resolves the accuracy-overhead trade-off in KV Cache Eviction. By decoupling future attention estimation from explicit token generation, LookaheadKV accurately identifies structurally critical tokens in advance without the computational burden associated with draft generation.
The integration of learnable lookahead tokens and specialized LoRA modules enables the model to compute future attention distributions directly. This generation-free approach allows the model to optimize its eviction policy with marginal computational overhead, effectively reducing the KV cache memory footprint while preserving the generative accuracy of the model.
As the demand for processing extensive contexts continues to scale, mitigating memory bottlenecks remains a primary challenge. Parameter-efficient methodologies like LookaheadKV provide a robust pathway for deploying high-throughput, scalable LLMs, particularly in resource-constrained environments where memory efficiency is paramount.
References
[1] Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: LLM knows what you are looking for before generation. In Advances in Neural Information Processing System (NeurIPS), 2024.
[2] Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, et al. PyramidKV: Dynamic KV cache compression based on pyramidal information funneling. In Second Conference on Language Modeling (COLM), 2025
[3] Michael Davies, Neal Crago, Karthikeyan Sankaralingam, and Christos Kozyrakis. LIMINAL: Exploring The Frontiers of LLM Decode Performance, ArXiv preprint, abs/2507.14397, 2025.
[4] Kevin Galim, Ethan Ewer, Wonjun Kang, Minjae Lee, Hyung Il Koo, and Kangwook Lee. Draft based approximate inference for llms. In International Conference on Learning Representations (ICLR), 2026.
[5] Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models? In First Conference on Language Modeling, 2024.
[6] Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self- attention distillation for task-agnostic compression of pre-trained transformers. In Advances in Neural Information Processing System, 2020.
[7] Yixuan Wang, Shiyu Ji, Yijun Liu, Yuzhuang Xu, Yang Xu, Qingfu Zhu, and Wanxiang Che. Looka- head Q-cache: Achieving more consistent KV cache eviction via pseudo query. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025.
[8] Gautier Izacard and Edouard Grave. Distilling knowledge from reader to retriever for question answering. In International Conference on Learning Representations (ICLR), 2021.
[9] Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. In International Conference on Learning Representations (ICLR), 2024.
[10] Xi Ye, Fangcong Yin, Yinghui He, Joie Zhang, Howard Yen, Tianyu Gao, Greg Durrett, and Danqi Chen. Longproc: Benchmarking long-context language models on long procedural generation. In Second Conference on Language Modeling (COLM), 2025.
[11] Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R´e, Clark W. Barrett, Zhangyang Wang, and Beidi Chen. H2O: heavy-hitter oracle for efficient generative inference of large language models. In Advances in Neural Information Processing System, 2023.
[12] Zhe Cao, Tao Qin, Tie-Yan Liu, Ming-Feng Tsai, and Hang Li. Learning to rank: from pairwise approach to listwise approach. In Proceedings of International Conference on Machine Learning (ICML), 2007.
[13] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In Advances in Neural Information Processing System (NeurIPS), 2023.
[14] Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao DongW, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024.