AI
Task Generalizable Spatial and Texture Aware Image Downsizing Network
Background
Convolutional neural networks (CNNs) are widely used today in various vision tasks such as classification, detection and segmentation. To make full use of GPU in CNN model processing and to use batch normalization, images of various resolutions are usually resized to the same resolution in the pipeline with mostly used bilinear interpolation. As higher resolution image tends to obtain higher accuracy by preserving more image information, some models resize the image to higher resolution. However, the computational load greatly increases for high resolution. Thus, low resolution image is still preferred in many conditions, especially in speed and memory demanding applications. We analyze that the interpolation in many methods only consider relative distance in inferring the interpolation coefficients. This causes the information loss in image downsizing. In contrast, if the texture is considered in inferring the interpolation coefficients, more texture details or more image information may be preserved. There are some methods which use semantic feature to infer the filter coefficients in feature map downsizing. Zou et al. [1] propose to learn image feature adaptive filter kernels for feature map blurring with a sub-network before max-pooling, and they obtain consistent improvements on several tasks. However, they only consider the feature map semantic information in inferring the filter kernels. Besides, it is not an interpolation method and cannot deal with arbitrary downsizing scales.
To solve the image information loss problem, we propose a simple yet efficient interpolation method DownsizeNet which performs interpolation with a CNN sub-network to downsize image at the image pre-processing stage. To our best knowledge, we are the first to introduce texture feature into CNN based interpolation coefficient inference process. A special floating type pooling layer is designed to spatially align the extracted CNN texture feature and the encoded relative distance map. Our interpolation method can retain the pixel position information and also adapt to the local texture variation. Besides, compared to traditional convolution network, our method can tackle arbitrary resolution scale resizing effectively with the specifically designed pooling layer.
In another part, our model has good generalization ability. This enables the DownsizeNet module to be trained on one task and used on another task directly with fixed weights in interpolation sub-network. In many conditions, for fast implementation with fewer training epochs or when the training set is small, the pre-trained backbone weights, e.g. VGG16, are fixed and only the regression or classification head sub-network is trained. In this condition, the input to the backbone is required to be an image to use the pre-trained model, and our proposed DownsizeNet can meet this requirement by keeping the interpolation result being still an image.
Network Architecture (DownsizeNet)
Our aim is to provide a fast and effective CNN based interpolation method for image downsizing, to replace the hand-crafted bilinear interpolation widely used in CNN pipelines at the image preprocessing stage. There can be other methods to preserve the information in image downsizing, e.g. auto encoder. However, auto encoder cannot deal with arbitrary downsizing scale as our method. Besides, our model is easy to be implemented and has good generalization by retaining the downsized result being still an image. The proposed interpolation network structure is as shown in Figure 1. We first infer the spatially different interpolation coefficients with a sub-network, and then perform interpolation with these coefficients. The obtained low resolution image is used in the following CNN task.
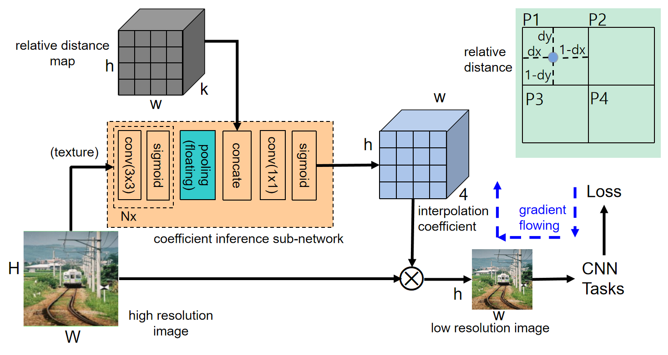
Figure 1. The structure of the proposed DownsizeNet interpolation model
The interpolation coefficients are different for different pixels. For a specific point Q on the low resolution image, given the pixel intensity  and interpolation coefficients
and interpolation coefficients  of its four corresponding neighbor pixels on the high resolution image, its pixel intensity is defined as:
of its four corresponding neighbor pixels on the high resolution image, its pixel intensity is defined as:

The main part of the proposed DownsizeNet is the interpolation coefficient inference sub-network. Different from previous interpolation methods which only use the relative distance between projected pixel and its neighbors, we also introduce the texture feature into the coefficient inference process. In this way, the interpolation coefficient can reflect the texture variation. Here, the texture feature for each pixel is extracted by performing convolutions on local image patch. As in Figure 1, in this coefficient inference sub-network, we first extract feature map from the high resolution image with 2~4 convolution layers with 3x3 kernels, and then concatenate it with the relative distance map, and then make the new feature map pass a 1x1 convolution layer and a sigmoid layer. In this way, the pixel-wise fusion of CNN texture and the relative distance is obtained. Then, we can obtain the interpolation coefficient map where sum to 1 constraint is used before interpolation. With sigmoid and sum to 1 normalization, the constraint in above Equation is fulfilled. Note that the last sigmoid in the coefficient inference subnetwork can be replaced by softmax, then the sum to 1 operation is not needed in the following interpolation operation any more. The constraint guarantees that the resized output is still an image. As pre-trained backbone models, e.g. VGG16, are trained on images, this constraint guarantees that the pre-trained backbone models can be fixed for feature extraction to reduce the training time.
Our network is easy to implement. Asides from the traditional convolution and sigmoid layer, there is one special floating point pooling layer to align spatially the texture feature map and the relative distance map. For this layer, for each pixel Q on the low resolution feature map, we project it to the high resolution feature map. Given P as the top left pixel of the four neighbor pixels of the projected pixel, we select the feature vector at P as the feature vector of Q. That is, only selection operation is needed in the special pooling layer. This selected feature vector contains the local context information due to the receptive field of the convolution operation.
There can be various ways to define the relative distance map, according to the offset dx and dy which represent the offset between the projected pixel and the upper top pixel on the high resolution image (top right of Figure 1). That is, the relative distance vector can be defined as  for a specific pixel on the low resolution image, where K is the channel number. The
for a specific pixel on the low resolution image, where K is the channel number. The 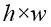 relative distance vectors construct the relative distance map, where h and w are the height and width of the low resolution image respectively. The bilinear interpolation can be considered as a special case of our method. In this condition, we define the coefficient inference sub-network as follows.
relative distance vectors construct the relative distance map, where h and w are the height and width of the low resolution image respectively. The bilinear interpolation can be considered as a special case of our method. In this condition, we define the coefficient inference sub-network as follows.
We define  . And define the 1x1 convolution filters as
. And define the 1x1 convolution filters as 
 where only the (C+k)-th element is 1 for
where only the (C+k)-th element is 1 for  . C is the channel number of the feature map before pooling. The last sigmoid is removed. Then, our method becomes bilinear interpolation.
. C is the channel number of the feature map before pooling. The last sigmoid is removed. Then, our method becomes bilinear interpolation.
The downsized image can be used for various following CNN tasks such as detection and segmentation. The loss function of DownsizeNet module is the same as the loss function of the following tasks. When having obtained the gradients of the interpolated image, the gradient is back-propagated to the interpolation coefficient inference module. In this way, we obtain an end-to-end trainable system.
Experimental Results
We test the validity of our method on four detection pipelines, i.e., RefineDet [2], CenterNet [3], LightHead [4] and DETR [5] (Table 1), and three semantic segmentation pipelines, i.e., FCN [6], DeepLabv3+ [7] and SPNet [8] (Table 2). And we tested our method on four datasets, i.e. Pascal VOC 2007 [9], MS COCO [10], Pascal VOC 2012 Segmentation [9] and CityScapes [11]. From Table 1 and Table 2, we can see that our method consistently outperforms Bilinear by 0.2%~0.9% mAP on detection pipelines and 0.5%~0.9% mIoU on segmentation pipelines. In another part, as smaller resolution images tend to have lower performance and the image resolution is smaller than the original paper, for example DETR uses larger than ~800 resolution while it is 165x165 here, the performance here is lower than the official reports.
Besides, we also tested Bicubic interpolation, Area interpolation and DownsizeNet on RefineDet and VOC2007, and obtained 57.1%, 58.9% and 59.4% mAP respectively. We are 2.3% and 0.5% higher. The resolution is reduced from 300x300 to 100x100. We redesigned the relative distance vector using Bicubic coefficients and use 4x4 neighbor pixels. In this condition, we have larger advantage. As more neighbor pixels contain more semantic information, it is more suitable for DownsizeNet.

Table 1. The performance (mAP) comparison between Bilinear and ours on four detection pipelines

Table 2. The performance (mean IoU) comparison between Bilinear and ours on three segmentation pipelines
We also test the generalization ability of DownsizeNet. We first pretrain DownsizeNet on DeepLabv3+, and then use it directly on LightHead with the weights fixed. In Table 3, we compare bilinear and ours when pretraining the downsizing modules with different epochs in DeepLabv3+. From Table 3, we can see that when pretraining the proposed DownsizeNet using 100, 200 and 300 epochs, the performance on LightHead varies. When using more training epochs, we can see we have larger advantage than Bilinear. As there are random data augmentation in DeepLabv3+, more training epochs can be considered as more training samples of various textures are involved in training. In this way, the model can cover more image texture variations, and then larger advantage is obtained. We also make a generalization test where we first pretrain the downsizing module on LightHead and then use it on DeepLabv3+. But we find that the performance is not as good as bilinear interpolation. We analyze that it is because DeepLabv3+ can be considered as a classification task and LightHead a regression task (though the bounding box class needs classification), and classification model can extract more discriminative feature which has better generalization ability (such as VGG16 pretrained on classification task).

Table 3. Test on LightHead about the generalization ability of the pretrained DownsizeNet model on Pascal VOC2007 (mAP metric). The interpolation sub-network is pretrained on DeepLabv3+ for 100, 200 and 300 epochs separately. The LightHead is re-trained with 10 epochs. The image is resized to 0.3 times of the high image resolution for both LightHead and DeepLabv3+.
In another part, the proposed DownsizeNet only uses 2~4 convolution layers each of which has 16 channels. The computational load is small compared with the following CNN architecture (the CNN layers after DownsizeNet). We test the time on 1 K80 GPU. With the setting as in Table 1, bilinear interpolation needs 31.4 ms/image, while ours need 34.2 ms/image, 35.2 ms/image and 37.6 ms/image with 2, 3 and 4 convolution layers respectively. We see that when using 2 convolution layers, our method and Bilinear needs approximate time while our method outperforms Bilinear by 0.7% mAP. Thus, we can have relatively large performance improvement with little extra time cost.
Conclusion & Discussion
We propose an interpolation method DownsizeNet which aims to preserve image information in image downsizing at the image pre-processing stage. Besides the relative distance, we also introduce the texture feature information into inferring the interpolation coefficient with the sub-network. Our method can achieve consistent performance improvement than bilinear interpolation while retaining high speed with a few extra convolution layers. Besides, our method has good generalization ability to other pipelines which facilitates the training process on new tasks. However, downsizing the image while retaining high performance is still a challenging task. We wish our work could have some inspirations for more effort to find more effective image information preservation method.
The DownsizeNet proposed in this paper has the potential to act as a basic module in image resizing process, specifically for image downsizing as in this paper. Also, this proposed module can also be used as an interpolation method in feature map downsizing (or upscaling) and ROI pooling. By introducing the semantic information into inferring the interpolation coefficients, we can expect better performance than only using relative distance.
Link to the paper
https://bmvc2022.mpi-inf.mpg.de/0315.pdfReferences
[1] X. Zou, F. Xiao, Z. Yu, et al.. Delving deeper into antialiasing in convnets. BMVC, 2020.
[2] S. Zhang, L. Wen, B. Xiao, et al.. Single-shot refinement neural network for object detection. CVPR, 2018.
[3] X. Zhou, D. Wang, and P. Krahenbuhl. Objects as points. arXiv:1904.07850, 2019.
[4] Z. Li, C. Peng, G. Yu, et al.. Light-head R-CNN: In defense of two-stage object detector. arXiv:1711.07264, 2017.
[5] N. Carion, F. Massa, G. Synnaeve, et al.. End-to-end object detection with transformers. ECCV, 2020.
[6] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. CVPR, 2015.
[7] L. Chen, Y. Zhu, G. Papandreou, et al.. Encoder-decoder with atrous separable convolution for semantic image segmentation. ECCV, 2018.
[8] Q. Hou, L. Zhang, M. Cheng, et al.. Strip pooling: Rethinking spatial pooling for scene parsing. CVPR, 2020.
[9] T. Lin, M. Maire, S. Belongie, et al.. Microsoft COCO: Common objects in context. ECCV, 2014.
[10] M. Cordts, M. Omran, S. Ramos, et al.. The Cityscapes dataset for semantic urban scene understanding. CVPR, 2016.





