AI
Prompt Based and Cross-Modal Retrieval Enhanced Visual Word Sense Disambiguation
Introduction
The Visual Word Sense Disambiguation (VWSD) shared task aims at selecting the image among candidates that best interprets the semantics of a target word with a short-length phrase for English, Italian, and Farsi. The limited phrase context, which only contains 2-3 words, challenges the model's understanding ability, and the visual label requires image-text matching performance across different modalities. In this paper, we propose a prompt based and multimodal retrieval enhanced VWSD system, which uses the rich potential knowledge of large-scale pretrained models by prompting and additional text-image information from knowledge bases and open datasets. Under the English situation and given an input phrase, (1) the context retrieval module predicts the correct definition from sense inventory by matching phrase and context through a biencoder architecture. (2) The image retrieval module retrieves the relevant images from an image dataset. (3) The matching module decides that either text or image is used to pair with image labels by a rule-based strategy, then ranks the candidate images according to the similarity score. Our system ranks first in the English track and second in the average of all languages (English, Italian, and Farsi).
System Overview
The system description in this section is under the English situation. Italian and Farsi are translated to English and only apply a partial sub-system with- out image sense involved. For English, we divide the VWSD task into three main modules, including (1) context retrieval module, (2) image retrieval module, and (3) matching module, as shown in Figure 1. The two retrieval modules perform dis- ambiguation among senses and are regarded as a WSD-specific modules. Word Sense Disambiguation (WSD) is a challenging task of Natural Language Processing,

Figure 1. The overall architecture of our system. Three main modules: (1) Context Retrieval module performs disambiguation and retrieves best definitions, (2) Image Retrieval module collects relative images from LAION, and (3) Matching module computes the similarity with candidate image labels.
Context Retrieval Module
In this module, the most suitable text prompt in- terpreting the meaning of the target word will be selected. We use the definitions and synonyms as the context and match them with the given phrase, which is a similar setup to the traditional WSD task. However, this approach still needs more in- formation on the short-length phrase when match- ing with context. We use translation to gain ex- tra knowledge by back-translating the phrase from another language to English with multiple online translators (Luan et al., 2020) and concatenate the results. Then, we put the augmented phrase and the customized context into the biencoders, which separately encode phrase and context as shown in the Text Encoder part of Figure 1. To further im- prove the WSD performance, we apply weighted similarity to minimize the distance to the phrase. We disambiguate the confused senses of the target word and maximize the similarity with the phrase with equation 1,
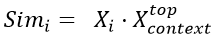

and  determines the disambiguation weight. As a result, compute the similarity between phrase and candidate contexts, which gives the nearest embeddings to represent the correct sense.
determines the disambiguation weight. As a result, compute the similarity between phrase and candidate contexts, which gives the nearest embeddings to represent the correct sense.
Image Retrieval Module
Instead of constraining in text space, we are in- spired to obtain cross-modal information by Ba- belPic (Calabrese et al., 2020), a multimodal dataset for non-concrete concepts. Although the domain of BabelPic does not match with the task dataset, it is observed that there are a considerable number of specific entities in both training and test- ing datasets that benefit from image information. Therefore, we collected the extra image data using clip retrieval (Beaumont, 2022), which retrieves im- ages according to the similarities between phrase and LAION image embeddings.
Matching Module
With the text context and image sense as the inputs, the final module will match them with candidate image labels and produce the image ranking accord- ing to similarities. The decision function chooses either text context or image sense to be used for final matching. We investigated the BabelNet infor- mation and found that it provides valuable proper- ties of target words. We designed a series of rules to decide using text or images based on the word properties. The selection strategy is designed ac- cording to the sense properties of BabelNet shown in Figure 2, and an overall decision process is based on the error analysis of training data. For instance, named entities of geographic places and biological creatures benefit from images and have a higher similarity than text context. However, concepts have various visual representations, and images might involve more mistakes than text prompts. Then the final context is processed through the cor- responding encoder with the image labels. The encoders are from a large pre-trained VLM, and we believe that the pre-training data contains po- tential knowledge that benefits WSD purpose and the alignment capability, which is significant to ob- tain correct text-image pairs. Therefore, we use a huge version of CLIP trained on LAION-5B as our module backbone for feature extraction.
Sense Inventory and Data Augmentation
The WSD task resource is an inventory contain- ing all possible senses of the target word, and the widely-used sources are semantic networks such as WordNet and BabelNet. As the given phrase is too short for the model to extract information, we collected extra data from Wikipedia, Word- Net, BabelNet, and another online dictionary using the target word (phrase if available). The details of data collection are introduced in Section 3.1. The online dictionaries involve extra text knowl- edge over the traditional knowledge base, which is proved to be useful (Bevilacqua et al., 2021). The quality of sense inventory significantly affects the WSD results, and a good inventory should contain sufficient and understandable information for the model to match with phrases and image labels. Our sense inventory contains abundant and high-quality information on the predicting words after a post- processing strategy.
Results and Discussion
In this session, we mainly analyze the English re- sults of the approaches in our system and discuss how it contributes to the results. The training and testing data are further compared and analyzed in the behavior of different training strategies Our system achieves a hit rate of 84 on the En- glish testing set, which ranks 1st out of 56 teams on the English leaderboard. The baseline approach uses the Most Frequent Sense from sense inventory as the input context and matches it with image la- bels. There is a huge gap between the results of the training and the testing set, and the constructed val- idation set has limited ability to eliminate the gap, as shown in Table 1. By applying a SimCSE-based biencoder to select the correct sense, the results sig- nificantly increase the testing set, which is related to the more multi-sense words in the testing set than the training set listed in Table 1. Another ma- jor improvement is adding synonyms to the prompt, which has contributed a lot to WSD ability. After analyzing the CLIP results, we find out that the synonyms can match the pre-training data of CLIP and transfer the potential knowledge of pre-trained models. To further improve the WSD performance, we back-translate the phrase for augmentation and add weighted similarity to minimize the distance to the phrase, which leads to a hit rate of 78 with text only.
The involvement of image representation pro- vides cross-modal information for disambiguation. The basement results of the image are not as ex- pected, but the overlap of wrong instances is small, which means the combination of image and text covers a broader range of correct instances. Those words represented well by visual information, such as named entities, are replaced by images and, as a result, we achieve the final result of 84 hit rate on the testing set.

Table 1. Performance of different approaches on English measured in hit rate, where MFS refers to Most Frequent Sense.
Conclusion
We describe our prompt and biencoder-based Vi- sual WSD system and investigate how the potential knowledge of large-scale pre-trained VLM con- tributes to disambiguation and modal alignment. The well-designed prompt template connects the input phrase and the potential knowledge of the pre- trained model, which also prevents the zero-shot generalization capability. The sense inventory is the fundamental element for WSD tasks, and con- text quality determines the performance boundary. The involvement of images in the WSD module further extends the coverage of sense interpretation ability. With the combination of text context and image representation, our system achieves a hit rate of 84 and ranks first in the English track.
In future work, more research on the modal fusion strategy will be completed, and the auto- matic fusion approach that applies to the different datasets will be designed. Rather than selecting a single modality based on rules, extracting useful in- formation from both text and images could benefit the disambiguation performance.
Link to the paper
https://aclanthology.org/2023.semeval-1.60/References
[1]. Romain Beaumont. 2022. Clip retrieval: Easily com- pute clip embeddings and build a clip retrieval sys- tem with them. https://github.com/rom1504/ clip-retrieval.
[2]. Michele Bevilacqua, Tommaso Pasini, Alessandro Ra- ganato, and Roberto Navigli. 2021. Recent Trends in Word Sense Disambiguation: A Survey. In Pro- ceedings of the Thirtieth International Joint Con- ference on Artificial Intelligence, pages 4330–4338, Montreal, Canada. International Joint Conferences on Artificial Intelligence Organization.
[3]. Federico Bianchi, Giuseppe Attanasio, Raphael Pisoni, Silvia Terragni, Gabriele Sarti, and Sri Lak- shmi. 2021. Contrastive language-image pre- training for the italian language. arXiv preprint arXiv:2108.08688.
[4]. Terra Blevins and Luke Zettlemoyer. 2020. Moving Down the Long Tail of Word Sense Disambiguation with Gloss-Informed Biencoders. ArXiv:2005.02590 [cs].
[5]. Agostina Calabrese, Michele Bevilacqua, and Roberto Navigli. 2020. Fatality Killed the Cat or: BabelPic, a Multimodal Dataset for Non-Concrete Concepts. In Proceedings of the 58th Annual Meeting of the Asso- ciation for Computational Linguistics, pages 4680– 4686, Online. Association for Computational Lin- guistics.
[6]. Fredrik Carlsson, Philipp Eisen, Faton Rekathati, and Magnus Sahlgren. 2022. Cross-lingual and multilin- gual clip. In Proceedings of the Language Resources and Evaluation Conference, pages 6848–6854, Mar- seille, France. European Language Resources Asso- ciation.
[7]. Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. 2020. UNITER: UNiversal Image-TExt Representation Learning. arXiv:1909.11740 [cs].
[8]. Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. 2022. Reproducible scaling laws for con- trastive language-image learning. ArXiv:2212.07143 [cs].
[9]. Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2022. SimCSE: Simple Contrastive Learning of Sentence Embeddings. ArXiv:2104.08821 [cs].
[10]. Yixing Luan, Bradley Hauer, Lili Mou, and Grzegorz Kondrak. 2020. Improving Word Sense Disambigua- tion with Translations. In Proceedings of the 2020 Conference on Empirical Methods in Natural Lan- guage Processing (EMNLP), pages 4055–4065, On- line. Association for Computational Linguistics.
[11]. George A. Miller. 1995. WordNet: a lexical database for English. Communications of the ACM, 38(11):39– 41.
[12]. Roberto Navigli and Simone Paolo Ponzetto. 2012. Ba- belNet: The automatic construction, evaluation and application of a wide-coverage multilingual semantic network. Artificial Intelligence, 193:217–250.
[13]. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learn- ing Transferable Visual Models From Natural Lan- guage Supervision. ArXiv:2103.00020 [cs].
[14]. Alessandro Raganato, Iacer Calixto, Asahi Ushio, Jose Camacho-Collados, and Mohammad Taher Pilehvar. 2023. SemEval-2023 Task 1: Visual Word Sense Disambiguation. In Proceedings of the 17th Interna- tional Workshop on Semantic Evaluation (SemEval- 2023), Toronto, Canada. Association for Computa- tional Linguistics.
[15]. Amir Ahmadi Sajjad Ayoubi, Navid Kanaani. 2022. Clipfa: Connecting farsi text and images. https://github.com/SajjjadAyobi/CLIPfa.
[16]. Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. 2022. OFA: Unifying Ar- chitectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework.
[17]. Xing Wu, Chaochen Gao, Liangjun Zang, Jizhong Han, Zhongyuan Wang, and Songlin Hu. 2022. ESim- CSE: Enhanced Sample Building Method for Con- trastive Learning of Unsupervised Sentence Embed- ding. ArXiv:2109.04380 [cs].
[18]. Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. 2022a. Conditional Prompt Learning for Vision-Language Models. ArXiv:2203.05557 [cs].
[19]. Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. 2022b. Learning to Prompt for Vision- Language Models. International Journal of Com- puter Vision, 130(9):2337–2348.





