AI
LaMa - New Photo Editing Technology that Helps Removing Objects from Images Seamlessly

Abstract
Have you ever tried to remove something from a photo of a precious moment? Wires in the sky, trash on streets or photobombers? Tools for this task have been around for years - from various magic eraser tools in professional graphical editors to specialized mobile applications. Under the hood these apps are powered by so-called inpainting methods, which take an image and a selected area as input and produce an image with the selected area re-generated (and the rest of the image is kept untouched).
If there are lots of tools for that on the market, why more research is needed? How do they work in general? What are the important components for a simple-yet-effective inpainting method? In this article we answer these questions and present LaMa - an inpainting method developed in Samsung AI Center Moscow.
What Is Inpainting and How It Evolved

Figure 1. An inpainting algorithm takes an image and a binary mask and removes and regenerates the masked areas in a plausible way.
image source
From the user perspective, inpainting takes an image and re-fills the selected areas in a natural way - so one cannot notice that the image is edited or something was removed (Figure 1). Inpainting belongs to the area of conditional image generation and often is implemented with the image2image class of generative neural networks.
Historically first, in a pre-deep learning era methods relied on heuristic and combinatorial optimization to rebuild the needed areas in a form of mosaic of patches borrowed from the input image or the similar ones [1, 2, 3]. These methods can handle homogeneous textures (e.g. grass or sand) very well - because they use fragments of real textures. However, they rely only on pixel-level similarities - and thus cannot handle semantically complex and non-homogeneous fragments (e.g. composite objects and consistent boundaries between them).

Figure 2. Principal scheme from the classical DeepFill v1 [4], which is the foundation for many other inpainting methods. The generator takes a masked image as input and first produces a coarse filling (which minimizes per-pixel reconstruction loss) and then refines it with more fine details (trained adversarially with discriminators).
After 2016 generative adversarial networks came into play and established a new strong baseline for inpainting methods - image2image generators trained in a self-supervised manner with a combination of reconstruction and adversarial losses (Figure 2). Self-supervised training means that no data labeling is needed to prepare the training data, just a lot of virtually uncurated images. During training, a batch of random images is loaded and combined with randomly generated masks - and the generator is tuned so it reconstructs the masked areas more precisely and nicely. This data-driven approach achieved significantly better image quality and semantic consistency compared to exemplar-based patch-level inpainting. Most works on inpainting in 2021 and 2022 still rely on the same principal framework while changing lesser - but still very important aspects - data generation process, architectures, loss functions.
In 2021 and 2022 the area received a boost after the visual transformers expansion and denoising diffusion probabilistic models. Visual transformers are a more generic architecture than convolutions - which are the de-facto standard in computer vision - and thus transformers are capable of capturing more complex patterns [5, 6]. Diffusion probabilistic models [7] offer a completely different approach to generative modeling, not involving adversarial training, but rather applying many iterations of noising and denoising. Transformers combined with diffusion result in even better image quality and new editing capabilities [8]. While these two fresh streams of methods offer extremely good image quality, they are much more expensive in terms of computation resources for training and predictions. Both transformer-based and diffusion-based methods are slower than traditional feedforward image2image-based solutions by an order of magnitude or even two.
What are the Difficulties for Inpainting in 2022?
Despite significant progress achieved throughout the years, the inpainting problem is far from being completely solved. Actually, inpainting is a pretty fundamental problem, which needs both scene understanding and high fidelity image generation.
The most important characteristics of inpainting methods include:1. ability to handle images in high resolution
2. structural consistency
3. computational cost
4. diversity of the generated scenes and objects
5. handling of inherent uncertainty (inpainting is an ill-posed problem)
6. generation of fine-grained details
In our work we focus on the first three characteristics, significantly improving image quality and structural consistency in high resolution while staying within the practical computation budget.

Figure 3. LaMa with Fourier convolutions can handle large-scale structures and repetitive patterns significantly better than very competitive baselines CoModGAN [9] and MADF [10]. image source
Highly structured and repetitive patterns are ubiquitous in human-made environments - cityscapes and interiors. On the contrary, pictures of nature often possess less rigid structure, textures are more homogeneous and the repetitiveness is not that strict. This variability makes natural scenes easier to handle for previous methods. However, human-made environments often pose a difficulty for these methods (Figure 3).
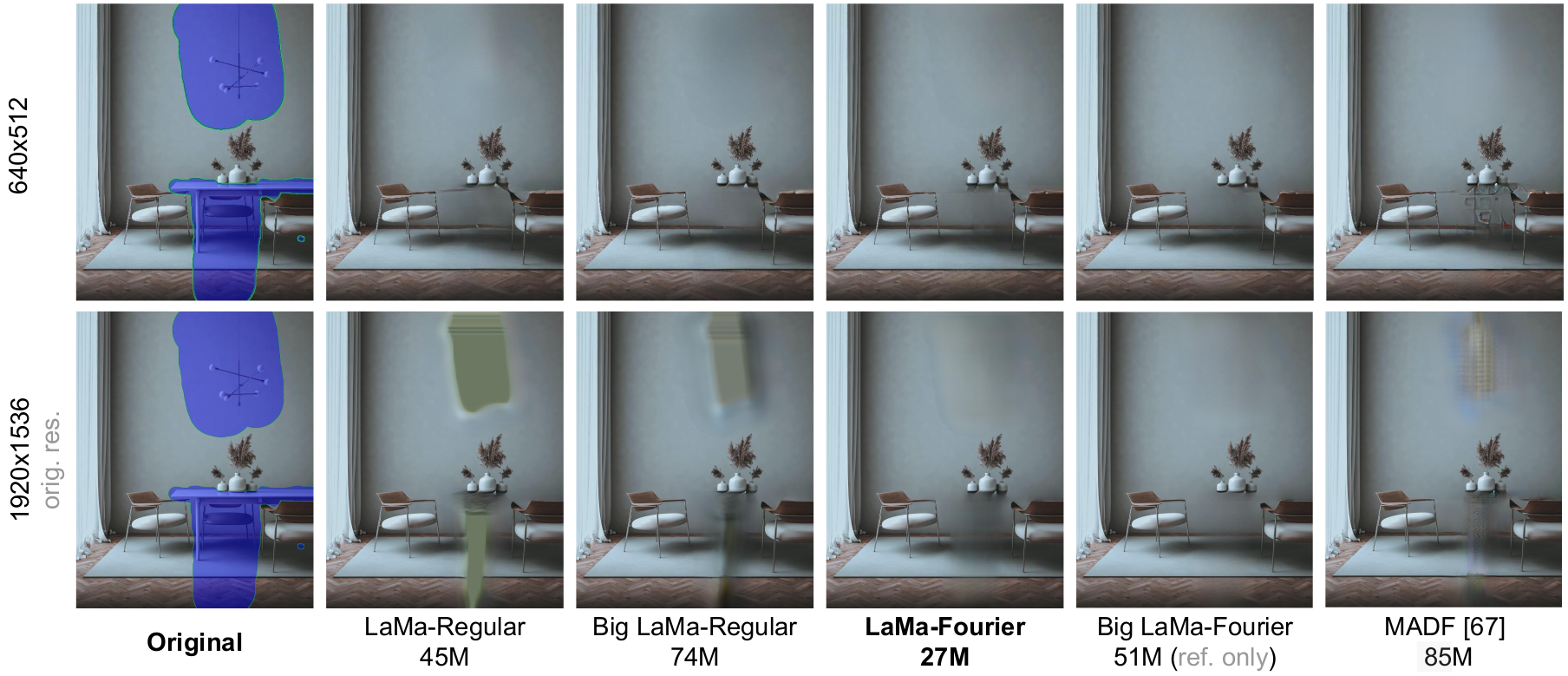
Figure 4. LaMa with Fourier convolutions is significantly more robust to large input resolution during inference, compared to all baselines. Note that LaMa is trained using images in 256x256 while MADF is trained using 512x512 images - and still performs better in 1920x1536 (6 times bigger resolution!).
image source
Most research papers present methods and experiments with images of relatively small resolution - 256x256 to 512x512 - but images from smartphone cameras are 4000 pixels high or more! There are three options to handle high resolution images: (1) use an inpainting method in low-resolution and then refine results with a separate superresolution model, which is very expensive at prediction time and the quality is still inferior; (2) train an inpainting method in extremely high resolution, which is prohibitively expensive at training time; (3) train an inpainting method in low resolution, but empower it with ability to generalize to high resolution without significant loss of quality. Thanks to Fourier convolutions, we follow the latter path and develop a method, which can perform well even on images, which are x6 times bigger (or more!) than those used in training (Figure 4).
What Is LaMa?
LaMa (shortcut for Large Mask Inpainting) technically belongs to the class of image2image generative methods and thus consists of three major components: training data generation process, generator architecture, loss function. Ideologically we started the project from the classical pix2pix [11], but later on revisited all the components. In this section we briefly discuss the importance of each modification we made.
Wide masks improve both image quality and robustness. Unlike most previous methods, we stress that it is important to use wide masks during training - and highlight the difference between the area of a mask and its width. Area is the percent of pixels covered with a mask. Width is an average distance from each covered pixel to its closest known pixel. Large area can be covered with both narrow or wide masks - so these two characteristics are nearly orthogonal. Wide masks work better probably because they motivate the generator to propagate information further within itself - thus increasing its effective receptive field.

Figure 5. Comparison of our wide and diverse masks to those used in a popular baseline (source)

Figure 6. Wide masks (right) make the generator more robust with large missing areas at the inference stage, compared to the same generator trained with narrow masks (middle). These generators are fully-convolutional (LaMa-Regular) and were trained in identical conditions except for mask width. image source
Large efficient receptive field is crucial for robust inpainting of large masks in large resolution. Receptive field can be thought of as a maximum distance between two input pixels, which can affect the same output pixel. It can be defined theoretically (based on hyperparameters of layers) and empirically (by measuring information flow). In the context of convolutional networks and inpainting, an effective (empirical) receptive field depends on the training resolution, width of masks and the architecture. Width of masks and the training resolution is inevitably limited by the available computation resources. The most traditional way to increase theoretical receptive field of an architecture is to use dilated convolutions - and they do help for more robust inpainting, but they are suboptimal because the effective receptive field is restricted by the training resolution. We propose to use Fast Fourier Convolutions [12] and adapt them for inpainting. FFC have a global (image-wide) receptive field by construction and they capture periodic and regular patterns naturally. They also empower our inpainting network with an ability to generalize to very high resolutions (2k and more) while being trained only using image crops of 256x256 (Figure 7).


Figure 7. Major effects of using Fast Fourier Convolutions include (1) ability to capture and regenerate repetitive and regular patterns and (2) generalization to much higher resolutions with smaller loss of image quality. image source
Perceptual loss benefits from a ResNet-50 backbone, which was pretrained on ImageNet classification and fine-tuned on Ade20k semantic segmentation. Perceptual loss is an important component of every image2image setup - it stabilizes and regularizes training and helps to keep predictions closer to the original image. It is a known fact that many convolutional networks, which were trained on ImageNet classification, pay more attention to textures and less attention to object shapes and boundaries [13]. VGG-19 - the most common backbone for the perceptual loss - is an example of such a network. On the contrary, the clear notion of object boundaries is natural and necessary for good semantic segmentation. This is why we replaced the traditional perceptual loss with the segmentation-based one [15]. An additional benefit of this HRF-PL is that it has a modified ResNet-50 architecture with more dilations - making the receptive field and the resolution of features higher. As a result, the inpainting network learns to draw object contours with more confidence and consistency (Figure 8). We show empirically that both pretext task and extra dilations help.

Figure 8. High receptive field perceptual loss helps to produce better object boundaries compared to the traditional VGG-based one. image source
Taking advantage of these three components, LaMa achieves better image quality while having a significantly smaller inpainting network, compared to many of recent and strong baselines (Figure 9).

Figure 9. LaMa outperforms most baselines on most benchmarks while being significantly smaller. For more metrics and comparisons, please refer to the
project page, the paper and the supplementary materials.
Conclusion
To sum up, our method - LaMa - significantly improves state of the art in terms of image quality in high resolution - while staying within the practical computational budget and model size. While some of the more recent methods based on diffusion and transformers can generate better images, LaMa provides significantly better quality-cost tradeoff.
Our Paper
Suvorov, Roman, et al. "Resolution-robust Large Mask Inpainting with Fourier Convolutions." Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2022. https://saic-mdal.github.io/lama-project/
Link to the paper
https://arxiv.org/abs/2109.07161
References
1. Marcelo Bertalmio, Luminita A. Vese, Guillermo Sapiro, and Stanley J. Osher. Simultaneous structure and texture image inpainting. In 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2003), 16-22 June 2003, Madison, WI, USA, pages 707–712. IEEE Computer Society, 2003.
2. Antonio Criminisi, Patrick P ́erez, and Kentaro Toyama. Object removal by exemplar-based inpainting. In 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2003), 16-22 June 2003, Madison, WI, USA, pages 721–728. IEEE Computer Society, 2003.
3. Barnes, Connelly, et al. "PatchMatch: A randomized correspondence algorithm for structural image editing." ACM Trans. Graph. 28.3 (2009): 24.
4. Yu, Jiahui, et al. "Generative image inpainting with contextual attention." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
5. Esser, Patrick, Robin Rombach, and Bjorn Ommer. "Taming transformers for high-resolution image synthesis." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
6. Chang, Huiwen, et al. "MaskGIT: Masked Generative Image Transformer." arXiv preprint arXiv:2202.04200 (2022).
7. Saharia, Chitwan, et al. "Palette: Image-to-image diffusion models." arXiv preprint arXiv:2111.05826 (2021). https://iterative-refinement.github.io/palette/
8. Nichol, Alex, et al. "Glide: Towards photorealistic image generation and editing with text-guided diffusion models." arXiv preprint arXiv:2112.10741 (2021). https://github.com/openai/glide-text2im
9. Shengyu Zhao, Jonathan Cui, Yilun Sheng, Yue Dong, Xiao Liang, Eric I Chang, and Yan Xu. Large scale image completion via co-modulated generative adversarial networks. In International Conference on Learning Representations (ICLR), 2021.
10. Manyu Zhu, Dongliang He, Xin Li, Chao Li, Fu Li, Xiao Liu, Errui Ding, and Zhaoxiang Zhang. Image inpainting by end-to-end cascaded refinement with mask awareness. IEEE Transactions on Image Processing, 30:4855–4866, 2021.
11. Isola, Phillip, et al. "Image-to-image translation with conditional adversarial networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
12. Chi, Lu, Borui Jiang, and Yadong Mu. "Fast fourier convolution." Advances in Neural Information Processing Systems 33 (2020): 4479-4488.
13. Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A. Wichmann, and Wieland Brendel. Imagenet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. In International Conference on Learning Representations, 2019.
14. Semantic Segmentation on MIT ADE20K dataset in PyTorch
https://github.com/CSAILVision/semantic-segmentation-pytorch





