AI
GOHSP: A Unified Framework of Graph and Optimization-based Heterogeneous Structured Pruning for Vision Transformer
Abstract
The recently proposed Vision transformers (ViTs) have shown very impressive empirical performance in various computer vision tasks, and they are viewed as an important type of foundation model. However, ViTs are typically constructed with large-scale sizes, which then severely hinder their potential deployment in many practical resources-constrained applications. To mitigate this challenging problem, structured pruning is a promising solution to compress model size and enable practical efficiency. However, unlike its current popularity for CNNs and RNNs, structured pruning for ViT models is little explored. We propose GOHSP, a unified framework of Graph and Optimization-based Structured Pruning for ViT models. We first develop a graph-based ranking for measuring the importance of attention heads, and the extracted importance information is further integrated to an optimization-based procedure to impose the heterogeneous structured sparsity patterns on the ViT models. Experimental results show that our proposed GOHSP demonstrates excellent compression performance. On CIFAR-10 dataset, our approach can bring 40% parameters reduction with no accuracy loss for ViT-Small model. On ImageNet dataset, with 30% and 35% sparsity ratio for DeiT-Tiny and DeiT-Small models, our approach achieves 1.65% and 0.76% accuracy increase over the existing structured pruning methods, respectively.
Background
The recent success of applying transformer architecture to computer vision has opened up new possibilities for foundation model design. Vision transformers (ViTs) have demonstrated impressive performance in various computer vision tasks, such as image classification, object detection, and video processing. However, ViTs are typically constructed with large model sizes, huge memory footprints and extensive computational costs, which can hinder their deployment in resource-constrained applications, such as mobile devices.
Numerous structured pruning methods have been proposed and studied in previous literature, with a focus on channel-level sparsity in Convolutional Neural Networks (CNNs). However, the structured sparse ViT models can exhibit multi-granularity sparsity (i.e., head-level and column-level) in the different component modules (i.e., attention head and multi-layer perception (MLP)). The co-existence of heterogeneous sparse patterns presents new research challenges and questions for efficient structured pruning strategies for ViT models. For instance, we need to determine the appropriate pruning criterion for each component module to achieve its specific sparse pattern. Moreover, we need to optimize the overall compression and task performance by performing the pruning process across different modules with varying levels of granularity sparsity.
Our Method of Structured Pruning for ViTs
Considering the inherent architectural heterogeneity of ViTs, three types of structured sparse patterns can co-exist with different levels of granularity across different modules. For the multi-head attention module, because each attention head is processing the information individually in a parallel way, the pruning can be performed at the head-level to sparsify this component. In addition, consider the weights in the heads are represented in the matrix format; the column-level sparsity can also be introduced towards structured pruning. Meanwhile, because the MLP consists of multiple weight matrices as well, the column-level of granularity sparsity can be imposed on this back-end module at the same time. Consequently, a structured pruned ViT model can exhibit heterogeneous structured sparsity (Fig 1.).

Figure 1. Our heterogeneous sparsity patterns of ViT transformer model after structured pruning
Based on the above analysis, the structured pruning of a vision transformer model with loss function  can be formulated as the following general optimization problem:
can be formulated as the following general optimization problem:

where  and
and  are the desired number of columns and the desired number of heads after pruning, respectively.
are the desired number of columns and the desired number of heads after pruning, respectively.  and
and  are the column-based and head-based group
are the column-based and head-based group  -norm, which denote the number of non-zero columns and the number of non-zero heads, respectively.
-norm, which denote the number of non-zero columns and the number of non-zero heads, respectively.
Fig. 2 shows the overall framework of our proposed GOHSP - a unified framework of Graph and Optimization-based Structured Pruning for ViT models.

Figure 2. Our proposed multi-stage structured pruning approach
Graph-based Head Ranking: We propose a graph-based approach to measure and determine the importance of different attention heads, which can be further used for the follow-up pruning. Our key idea is to model the inter-head correlation as a graph, and then leverage the graph-based ranking to select important attention heads. We first construct a graph  to represent the attention heads and their similarities in the block of a ViT model. Then, we quantify the importance of each attention head via calculating the stationary distribution in our constructed Markov chain. Once the importance score for each state is obtained via calculating the stationary distribution, the corresponding attention heads can be ranked. Using a binary mark matrix
to represent the attention heads and their similarities in the block of a ViT model. Then, we quantify the importance of each attention head via calculating the stationary distribution in our constructed Markov chain. Once the importance score for each state is obtained via calculating the stationary distribution, the corresponding attention heads can be ranked. Using a binary mark matrix  to indicate the weight entries associated with the least important heads that should be removed, we have:
to indicate the weight entries associated with the least important heads that should be removed, we have:

where  is element-wise product.
is element-wise product.
Optimization-based Structured Pruning: We propose to use advanced optimization technique to perform systematic structured pruning. We adopt “soft-pruning” strategy via optimizing the entire ViT models towards the desired structured sparse formats. In other words, the three types of sparsity pattern are gradually imposed onto the attention heads and MLPs.

where  is the coefficient that controls the influence of quadratic term.
is the coefficient that controls the influence of quadratic term.
Final Hard-Pruning and Fine-Tuning: After the above optimization procedure, the structured sparse patterns have been gradually imposed onto the ViT model. In other words, the weight values of the masked attention heads, as well as some columns of MLPs and attention heads, become extremely small. At this stage, we can now prune those small weights and then perform a few rounds of fine-tuning to achieve higher performance.
Experiments
CIFAR-10 Dataset. Table 1 shows performance comparison on CIFAR-10 dataset between our proposed GOHSP and other structured pruning method (structured one-shot magnitude pruning (SOMP) [1] and structured gradually magnitude pruning (SGMP) [2]) for ViT-Small model. It is seen that with the same sparsity ratio, our approach brings significant performance improvement. Compared to SGMP approach, GOHSP achieves 0.96% accuracy increase with the same pruned model size. Even compared with the baseline, the structured sparse model pruned by GOHSP can outperform the uncompressed model with 40% fewer parameters while 80% compressed model achieves only 0.45% worse than the full ViT-Small model.

Table 1. Performance comparison between GOHSP and SOMP/SGMP of ViT-Small model on CIFAR-10 dataset
ImageNet Dataset. Table 2 summarizes the performance on ImageNet dataset between GOHSP and other structured pruning approaches (SOMP, SGMP, Talyer pruning (TP), Salience-based Structured Pruning (SSP) and S2ViTE [3]) for DeiT-Tiny and DeiT-Small models. It is seen that due to the limited redundancy in such small-size model, the existing pruning approaches suffer from more than 2.5% accuracy loss when compressing DeiT-Tiny. Instead, with the even fewer parameters and more FLOPs reduction, our GOHSP approach can achieve at least 0.68% accuracy increase over the unstructured pruning approaches. Compared to the structured pruning approach (SSP), our method enjoys 1.65% accuracy improvement with lower storage cost and computational cost. In addition, when compressing DeiTSmall model, with fewer parameters and more FLOPs reduction, our GOHSP approach can achieve 0.76% accuracy increase as compared to the state-of-the-art structured pruning method S2ViTE and can even outperform the original DeiT-Small. With 50% pruned DeiT-Small we achieve similar accuracy to the full DeiT-Small. Finally, we report 26.57% improvement in run-time efficiency with our 50% pruned DeiT-Small.
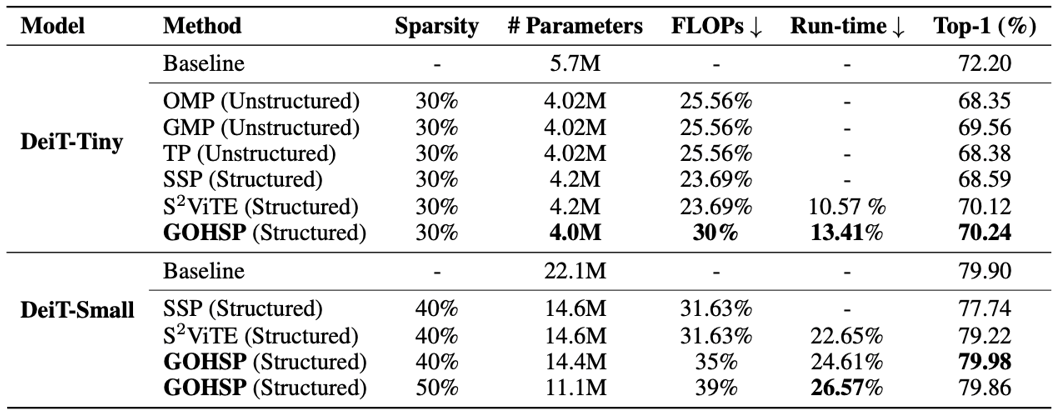
Table 2. Performance comparison between GOHSP and other structured and unstructured pruning methods on ImageNet
Link to the paper
https://arxiv.org/pdf/2301.05345.pdfReferences
[1] Song Han, Huizi Mao, William J. Dally: Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding. ICLR 2016.
[2] Michael Zhu, Suyog Gupta: To Prune, or Not to Prune: Exploring the Efficacy of Pruning for Model Compression. ICLR 2018.
[3] Tianlong Chen, Yu Cheng, Zhe Gan, Lu Yuan, Lei Zhang, Zhangyang Wang: Chasing Sparsity in Vision Transformers: An End-to-End Exploration. NeurIPS 2021.





