AI
Website Clustering via Transformer Context Models
Introduction
Individual characteristics as age, gender etc. are often relevant features in tasks such as lifetime value or uplift modelling. Those variables are sufficiently good in describing some high-level heuristics about a population. Unfortunately, they are unable to describe and assign each individual to a group of people with similar interests. Extracting knowledge about someone’s interests could make a great addition in clustering a population not only on easily descriptive features mentioned earlier, but also on a lower, behavioristic level.
We describe the use of BERTopic [1] to cluster webpages based on their semantic similarity. Those clusters can later be used to create features for each customer based on their browsing history.
Methodology
BERTopic is a state-of-the-art topic-modelling pipeline that consists of six steps: embedding extraction, dimensionality reduction, clustering, tokenizing, weighting and optionally fine-tuning found representations. In our modelling and analysis, we only use the first five.

Figure 1. BERTopic pipeline flowchart
Embeddings
In order to extract information from a text we do a common vectorising technique called embeddings. To transform given website descriptions to a 384 dimensional vectors, we use all-MiniLM-L6-v2, which is a popular sentence transformer model. It was trained by fine-tuning MiniLM-L6-H384-uncased [2] for the task of sentence similarity. Fine-tuning was performed on over 1 billion sentence pairs, mainly from reddit comment section [3]. The model allows us to create a space in which semantically similar websites are close to each other.
Dimensionality Reduction
Embedding space is good in terms of similarities between the samples, but is useless when it comes to clustering tasks, because of the curse-of-dimensionality. Thus, dimensionality reduction is essential. We use UMAP (Uniform Manifold Approximation and Projection) [4] algorithm to project the embedding space into a 15-dimensional latent space, preserving as much local and global dependencies as possible. UMAP belongs, just like TSNE, to the nearest neighbor graph based algorithms. First, the nearest neighbor graph is built on initial space. Then the graph is projected onto lower number of dimensions, while a certain objective function is being optimized.
Clustering
In our problem, we do not want to have any strict restrictions on a number of clusters. We are also far more interested in having well defined and dense groups based on semantics, instead of softer assignment with a greater coverage. That is why we use a density-based clustering algorithm called HDBSCAN. This way, filtering outliers is simple and if we were dissatisfied with the resulting topics or their number, we could merge or split a branch of clustering dendrogram.
Tokenizer & Weighting scheme
These two steps are responsible for topic extraction. We take the bag-of-words approach which extracts the information about frequency of each word. What is important, we do it on a cluster level, instead of a web page description level. To have meaningful and distinct topics between the clusters we have to weight this bag-of-words approach. If we don’t do it, words that appear frequently in several clusters could be used to describe topics. A common method to overcome this issue is using TF-IDF weighting scheme. Because we are interested in extracting the most important words for each cluster, we use class-based TF-IDF – c-TF-IDF.
Analysis
Our analysis was done on the data regarding most popular websites in France in early 2023. First, we present a 2-dimensional UMAP latent space, which was created only for visualization purposes. Colors represent clusters in a higher, 15-dimensional space. It is important because we could possibly see some inconsistencies. Fortunately, we can see that two dimensions are sufficient enough to explain most of the variance and dependencies. What is also worth mentioning is that colors to clusters mapping is not one-to-one, which means that one color can represent multiple groups. This is due to a large amount of clusters returned by the model.

Figure 2. Visually, the clustering algorithm performed very well
Visually, the clustering algorithm performed very well. Most of the clusters are dense and well separated from each other. To quantify that we use silhouette score which is a quality measure for clustering tasks. It is a mean of silhouette coefficients s_i, which are calculated for each sample with a following formula:

where 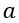 is the mean intra-cluster distance, and
is the mean intra-cluster distance, and 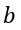 is the mean nearest-cluster distance. Each coefficient ranges from -1 to 1, where being close to -1 means that the sample is assigned to a wrong cluster. Values near 0 indicate that clusters are overlapping and the very positive ones correspond to a good assignment and well separated groups. What is worth noting is that one can aggregate silhouette coefficients in a few different ways. We decided to do that globally, meaning the overall silhouette score is simply a mean of coefficients over all of the observations. It can also be done cluster-wise, which would yield a “goodness of fit” score for each cluster separately.
is the mean nearest-cluster distance. Each coefficient ranges from -1 to 1, where being close to -1 means that the sample is assigned to a wrong cluster. Values near 0 indicate that clusters are overlapping and the very positive ones correspond to a good assignment and well separated groups. What is worth noting is that one can aggregate silhouette coefficients in a few different ways. We decided to do that globally, meaning the overall silhouette score is simply a mean of coefficients over all of the observations. It can also be done cluster-wise, which would yield a “goodness of fit” score for each cluster separately.

Figure 3. Violin plot of silhouette coefficients
Our overall silhouette score is over 0.62, although the distribution is highly left-skewed. Over a quarter of samples have a positive score of 0.80 or higher, and over a half have a score of at least 0.68. Having in mind the complexity of our data, we consider it to be a satisfactory result. In fact, silhouette score of over 0.6 could be considered by many as a decent result on a much simpler datasets such as, e.g. IRIS or MNIST.
In terms of cluster interpretability, we can simply examine topics generated for each cluster.

Table 1. Top 10 clusters and their generated topics
Generated topics consisting of only three words provide sufficient information for us to be able to interpret the semantic meaning of given cluster of websites. What is also interesting is that the further we go in popularity, the more specifically defined the topics become.

Table 2. Less popular clusters and their respective topics
Conclusions and Future work
We have presented a usage example of BERTopic on real world textual data. We have also performed an exploration of model results. The conclusions turned out to be easy to understand, simple heuristics, which further proves effectiveness of the presented methodology.
In our opinion, one of the biggest pros of the pipeline is its generalizability and ease of building upon it. Future work can consist of, e.g. exploration of transition probabilities from one cluster to another; iterative clustering, and thus improving its quality even further; or doing time-series forecasting on a trajectory of visited segments, which could possibly help us to generate better quality advertisements for each webpage and user.
References
[1] G. Maarten, "BERTopic: Neural topic modeling with a class-based TF-IDF procedure.,"arXiv preprint arXiv:2203.05794, 2022.
[2] W. Wang, F. Wei, L. Dong, H. Bao, N. Yang and M. Zhou, "MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers,"Advances in Neural Information Processing Systems 33, pp. 5776-5788, 2020.
[3] M. Henderson, P. Budzianowski, I. Casanueva, D. Gerz, G. Kumar, N. Mrksic, G. Spithourakis, P.-H. Su, I. Vulic and T.-H. Wen, "A Repository of Conversational Datasets,"arXiv preprint arXiv:1904.06472,, 2019.
[4] L. McInnes, J. Healy and J. Melville, "Umap: Uniform manifold approximation and projection for dimension reduction.,"arXiv preprint arXiv:1802.03426, 2018.





