AI
A More Accurate Internal Language Model Score Estimation for the Hybrid Autoregressive Transducer
Language model (LM) adaptation in hybrid autoregressive transducer (HAT) is justified only when the transducer logits and the sum of speech and text logits in the label estimation sub-networks are approximately the same. The mean squared error (MSE) between the two logits was added to the HAT loss to encourage the HAT models to satisfy the required condition. It attained lower word error rates (WERs) compared to HAT in both cases with and without LM adaptation.
Keywords: contextual speech recognition, language model adaptation
Hybrid Autoregressive Transducer
HAT [1] is a variant of the recurrent neural network transducer (RNNT) [2]. HAT models are developed with a pair of sub-networks consisting of transcription, prediction, and joint networks to separately compute posterirors of blanks <b> and labels  , whereas RNNT models calculate the posterors of
, whereas RNNT models calculate the posterors of  through a single sub-network. The posterior at each node of a lattice is computed as follows:
through a single sub-network. The posterior at each node of a lattice is computed as follows:

where subscripts b and l indicate blank and label networks, respectively. f and g depict a transcription and prediction network output vector, respectively, for the tth input speech frame and uth label. Here, J represents a joint network and σ indicates a Sigmoid activation function. The uth local ILM score is defined as  and can be justified under special conditions when
and can be justified under special conditions when  . The sequence-level log probability of ILMs,
. The sequence-level log probability of ILMs, 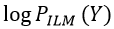 , is computed by normalizing each local ILM score with a log softmax function and summing them. The on-the-fly LM adaptation of HAT during decoding is formulated as follows:
, is computed by normalizing each local ILM score with a log softmax function and summing them. The on-the-fly LM adaptation of HAT during decoding is formulated as follows:

where the curly B is a function to convert alignment paths to label sequences [2].  is set to 1 in this study. This inference algorithm is mathematically justified as long as the aformentioned conditions are satisfied.
is set to 1 in this study. This inference algorithm is mathematically justified as long as the aformentioned conditions are satisfied.
Model Architecture

Figure 1. Our HAT model architecture
Our HAT model consists of two subnetworks that are a blank network and label network as depicted in Figure 1.
Constrained Learning with Mean Squred Error Loss
We devised the novel training method to encourage the output vectors of  satisfy the condition. Mean squred error (MSE) is used as an additional loss to minimize the difference between
satisfy the condition. Mean squred error (MSE) is used as an additional loss to minimize the difference between  and
and 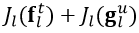 and is computed as follows:
and is computed as follows:

The sequence-level MSE loss is computed with the arithmetic average over the speech feature length T and text label sequence length U.

It is added to the HAT transducer loss as follows.
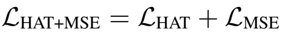
Experiments

Table 1. WERs of LM adaptation for the Librispeech corpus
Our models were evaluated on the Librispeech corpus [3] as in Table 1. HAT+MSE models exhibited lower WERs compared with HAT models over all evaluation sets and simultaneously minimize the accuracy degradation from RNNT models when LMs are not applied.
Conclusions
In this post, we explained HAT+MSE as a novel training method. A MSE loss was used in addition to a HAT loss to encourage justified LM adaptation. Compared to related work, our method does not need structural changes of HAT models. Thus, it can be successfully applied to HAT models either from scratch or after regular HAT training. The prior estimation can be improved by devising a new structure of RNNT variant models.
Link to the paper
https://www.isca-speech.org/archive/pdfs/interspeech_2023/lee23b_interspeech.pdfCite as
Lee, K., Kim, H., Jin, S., Park, J., Han, Y. (2023) A More Accurate Internal Language Model Score Estimation for the Hybrid Autoregressive Transducer. Proc. INTERSPEECH 2023, 869-873, doi: 10.21437/Interspeech.2023-213
References
[1] E. Variani, D. Rybach, C. Allauzen, and M. Riley, “Hybrid autoregressive transducer (HAT),” in ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 6139–6143.
[2] A. Graves, “Sequence transduction with recurrent neural networks,” in Representation Learning Workshop of International Conference on Machine Learning (ICML), 2012.
[3] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210.



