AI
Vision-Language Model Guided Semi-Supervised Learning for No-Reference Video Quality Assessment
|
IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) is an annual flagship conference organized by IEEE Signal Processing Society. And ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. It offers a comprehensive technical program presenting all the latest development in research and technology in the industry that attracts thousands of professionals. In this blog series, we are introducing our research papers at the ICASSP 2025 and here is a list of them. #3. Vision-Language Model Guided Semi-supervised Learning for No-Reference Video Quality Assessment (Samsung R&D Institute India-Bangalore) #4. Text-aware adapter for few-shot keyword spotting (AI Center - Seoul) #8. Globally Normalizing the Transducer for Streaming Speech Recognition (AI Center - Cambridge) |
Introduction
The widespread adoption of mobile devices has led to a rapid growth of video content that is captured, transmitted and shared on various social media platforms. Various camera product manufactures and social media platforms use Video Quality Assessment (VQA) metrics to monitor and control the quality of user-generated videos for a better user experience. The lack of a reference/ distortion-free videos in such applications require the design of No-Reference (NR)-VQA metric.
Existing deep learning-based algorithms demand a large amount of human-annotated video for learning a robust NR-VQA metric. However, the user-generated videos suffer from a wide range of distortions such as spatial & motion blur, compression, flicker, stabilization, poor object detailing, semantic artefacts, etc. In addition, due to the ever-evolving camera-pipeline and novel generative artefacts created by new-age generative models, it is difficult to collect and manually annotate such a wide variety of distorted videos.
In this blog post, we bring to you a semi-supervised learning based NR-VQA metric that learns from a small number of human-annotated & unlabelled videos. This algorithm could be finetuned for any application-specific use-case using a handful of relevant annotated videos. Towards this, we propose a quality-aware semantic-aware VQA (QASA-VQA) that incorporates both low-level quality distortions e.g. blur, compression, noise and high-level semantic artefacts.
Overview of Quality-Aware Semantic-Aware VQA (QASA-VQA)
QASA-VQA consists of a dual-model framework where a quality-aware model captures low-level distortions and a vision-language (VL) model captures high-level semantics.
Quality Aware Model (QAM):
To effectively capture the low-level information present in video frames, we consider fragmented samples of the original video. Fragments are generated by stitching randomly cropped patches at the original resolution of video frames to learn video quality using end-to-end in deep networks. In order to preserve temporal distortions in videos, the fragments are selected from continuous video frames. We use a feature encoder viz. spatio-temporal video quality representation learning (ST-VQRL) [1], that is pre-trained in a self-supervised manner to capture low-level video distortions. Further, we attach a regressor-head on top of ST-VQRL to predict final quality of the input video to this framework. ST-VQRL has a Video Swin transformer [2] architecture as its backbone while the regressor-head is two 3D CNN layers of 1 × 1 ×1 convolution filter size. Let, gϕ(⋅) and Fθ(⋅) denote the 3D regressor-head and ST-VQRL backbone, respectively.
The predicted quality of any video x∈(Vv∪U), where Vv={vi}(i=1)Nl is given as:

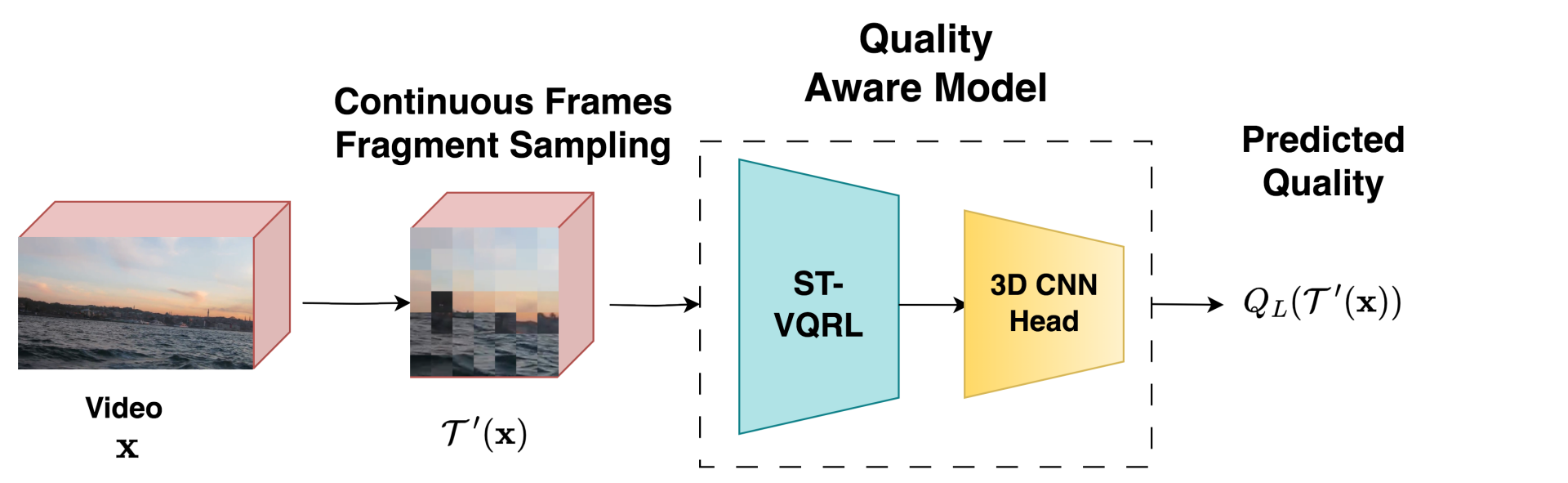
Figure 1. Framework of Quality Aware Model (QAM)
Semantic Aware Model (SAM):
To capture semantic information in videos, we use a popular vision-language model viz. CLIP [3]. Given any video x={Ii}N(i=1)where Ii is the ith frame of the video, we apply CLIP to encode the video using its visual encoder Ev. While feeding frames to CLIP, we spatially downsample the video frame using S(⋅) and feed temporally sparse frames of the videos to the CLIP visual encoder. Thus, the CLIP visual encoder has lesser sensitivity to low-level spatial distortions such as blur, noise, and compression and temporal distortions such as motion blur, camera shake, and flicker.
We choose two pairs of quality aware antonym prompts (1) [````a good photo.’’, ````a bad photo.’’] (P0,+,P0,-) and (2) [````a high quality photo.’’, ````a low quality photo.’’] (P1,+,P1,-) . Let the frozen CLIP text encoder be Et(⋅), and the text representation be ftP= Et(P). The predicted quality for any video x with CLIP visual representation fx=1/N ∑ Ni=1Ev(S(Ii)) is:

where D(S(x),Pi,+,Pi,-)=fx.ftPi,+-fx.ftPi,-. Ev is trainable while Et is frozen. And the overall quality of the video is given as (QL (τ' (x))+QH (S(x)))/2.
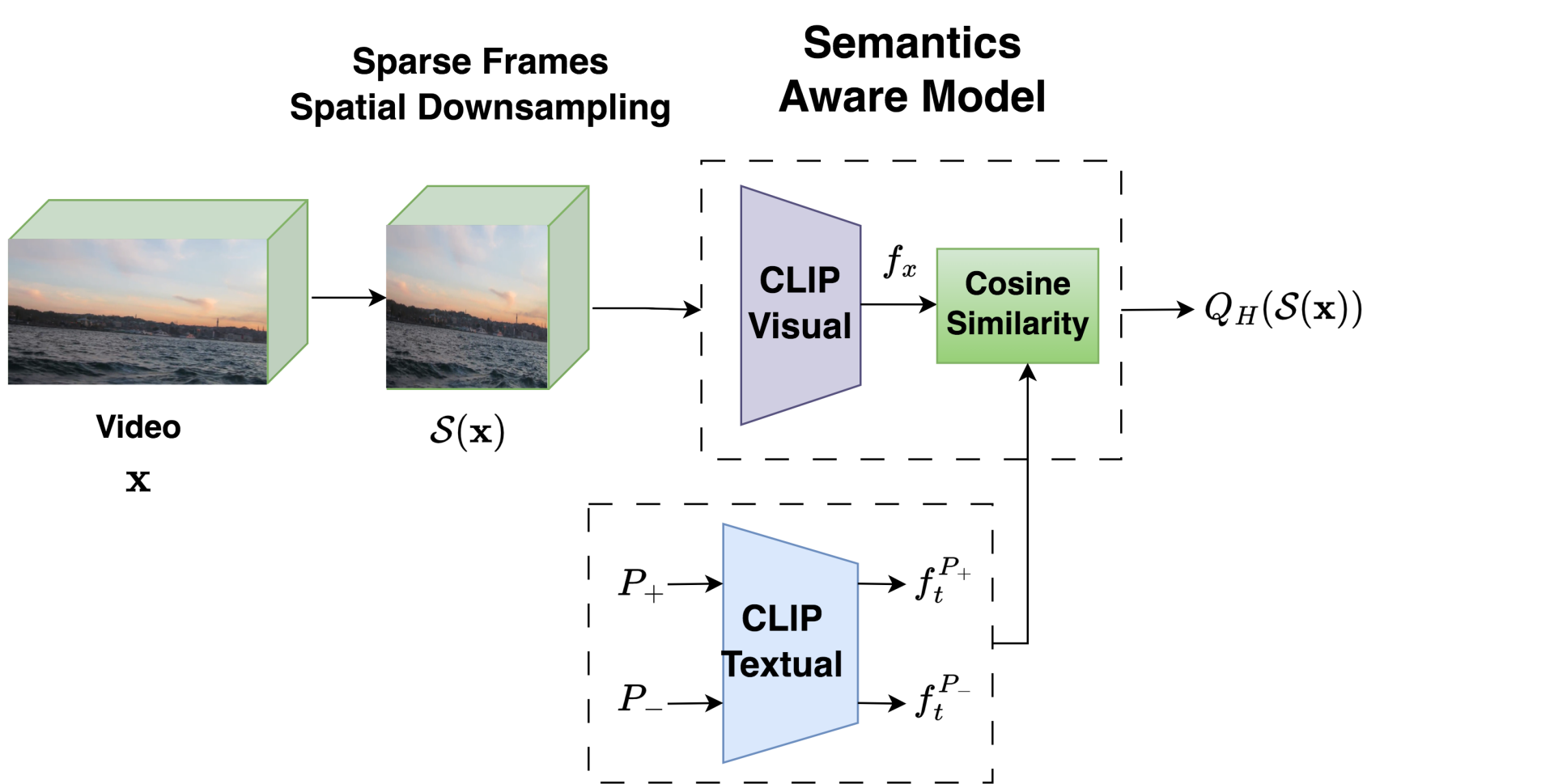
Figure 2. Framework of Semantic Aware Model (SAM)
Training Objective:
Let V = {(v1,y1),(v2,y2),⋯ ,(vNl,yNl)} be a set of labelled (human-annotated) videos and U = {u1,u2,⋯ ,uNu} be a set of unlabelled videos. As shown in Fig. 3, we design a dual-model learning setup comprising of a low-level Quality Aware Model (QAM) and a high-level Semantic Aware Model (SAM). On the labelled set, both the models learn video quality using human opinion supervision. We learn from the unlabelled data by transferring knowledge between QAM and SAM by estimating their reliability.

Figure 3. Overview of the QASA-VQA method
Supervised Loss:
We use the differentiable Pearson’s Linear Correlation Coefficient (PLCC) loss on a mini-batch of labelled videos v={vi}Bli=1 with y={yi}Bli=1 as human-opinion score, where {(vi,yi)}Bli=1∈V and Bl as the mini-batch size. Thus, the supervised loss is formulated as,

where S(v)={S(vi)}Bli=1 and τ'(v)={τ'(vi)}Bli=1.
Intra-Model Consistency (IMC) Loss:
We evaluate the model consistency through the intra-model prediction error between the augmented video clips for each model. Since video fragments are generated by stitching random crops of patches, we randomly crop multiple local quality-consistent patches to generate multiple video fragments. Let τ'(x), and τ''(x) be the two-quality consistent augmented fragments for a mini-batch of videos x∈(Vv∪U) fed to the QAM. We apply semantically invariant geometric flips to the downscaled video frames to generate augmented video pairs S(x) and SF(x) for SAM. The intra-model consistency loss is given as

Knowledge Transfer (KT)-based loss:
The major contribution is leveraging quality information in unlabelled videos by transferring knowledge between high-level SAM and low-level QAM. Depending on the distortions present in a certain video (low-level or high-level or both), either the SAM or QAM prediction could be more accurate. Thus, if knowledge is transferred in both ways between the two models, an inaccurate prediction of one model may affect the learning of the other model. To overcome this limitation, we incorporate a teacher-student type learning framework, where the model whose prediction is more stable with respect to an augmented pair of a video is considered the teacher, while the other model is the student. Let ϵH and ϵL denote the consistency error of SAM and QAM where,

The prediction of the more stable (teacher) model (with lesser consistency error) is used as a pseudo-label for the other model i.e. the student model. The knowledge transfer loss function for a minibatch is given as:

where m= 1(ϵH>ϵL) is the stability condition and sg(⋅) denotes the stop gradient operation. We use a combination of the supervised loss, intra-model consistency loss, and knowledge transferable loss to train our model as

where λc and λU are the weights to balance the loss terms.
Experiments and Results:
Training Database: We train our model using the official trainset of LSVQ [4]. We randomly sample 2000 videos from the entire set for our work. Of these 2000 videos, 500 are randomly selected to be used as labelled data, whereas the remaining 1500 are used as unlabelled data. This selection is done 3 times such that the labelled videos are different in each set.
Evaluation Database: In intra-database setting, we evaluate our model using the official test split of LSVQ viz. LSVQ-test comprising of 7400 videos with resolution between 240p and 720p. We also evaluate on the 1080p resolution test split of LSVQ namely LSVQ-1080p encompassing 3600 videos. For inter-database setting, we evaluate on KoNViD-1k [5], and LIVE VQC [6] consisting of 1200 and 585 UGC videos, respectively. We analyse performance using Spearman’s rank order correlation coefficient (SRCC) and PLCC.
Implementation Details: We use the pre-trained ST-VQRL[1] encoder having Video Swin-transformer [2] architecture as the backbone of our QAM. τ' and τ'' sample a clip of 32 continuous frames of size 224 ×224 from the video. For SAM, we use a pre-trained CLIP [3] with Vit-B/32 backbone. S spatially resizes 32 frames randomly sampled from the video to a size 224 ×224, while SF also randomly flips it.
Semi-supervised performance analysis: We compare our QASA-VQA with semi-supervised NR-VQA methods such as LPR [14] and SSL-VQA [1] in Tab. 1. We also benchmark popular semi-supervised learning methods such as Mean Teacher [7], Meta Pseudo-Label [8], and FixMatch [9]. We see QASA-VQA gives a substantial improvement over existing methods by leveraging quality and semantic information in videos. We also infer that the performance of QASA-VQA deteriorates if trained without IMC or KT losses. Our KT loss is crucial in achieving superior semi-supervised performance.

Table 1. Median Performance comparison of QASA-VQA with other SSL benchmarks on intra and inter database test settings
Evaluation on Limited Labelled Data: In this experiment, we evaluate QASA-VQA with popular NR-VQA methods trained on only limited labelled data and without any unlabelled data. In Tab. 2, we see that QASA-VQA outperforms recent state-of-the-art methods such as CSVT-BVQA [10], FAST-VQA [11], DOVER [12] and ModularVQA [13]. We also analysed the individual components of QASA-VQA viz. QAM and SAM. Though individually quality (QAM) and semantic (SAM) aware models give acceptable performance, their ensemble (QASA-VQA) gives a considerable performance boost.

Table 2. Median SRCC performance comparison of QASAVQA with other NR-VQA methods when trained with only limited (500) labelled videos from LSVQ trainset
Qualitative Analysis of QAM and SAM: To show the complementarity of QAM and SAM, we analyse the absolute error in prediction of QAM (EQAM) and SAM (ESAM) for two unlabelled videos. In Tab. 3, we show a frame from different videos. For Video 1, QAM’s prediction is poorer comparative to SAM’s as the background blur is measured without taking the context into account. For Video 2, QAM’s prediction is more accurate as the video suffers from compression artefacts while SAM’s prediction is highly erroneous as the semantics of the scene is good.

Table 3. Absolute error in prediction of QAM (EQAM) and SAM (ESAM) for two videos from LSVQ trainset where the scores are on 0-100 scale
Conclusion:
We leverage the potential of vision-language (VL) models to effectively capture and utilize semantic information for semi-supervised no-reference video quality assessment (NR-VQA). Specifically, our approach integrates the strengths of a low-level quality-aware model and a high-level semantic-aware model, enabling knowledge transfer on unlabelled data. Our proposed QASA-VQA method significantly narrows the performance gap between semi-supervised and fully supervised NR-VQA models, achieving competitive results using minimal human-annotated labels.
Link to the paper
https://ieeexplore.ieee.org/abstract/document/10890466
References
[1] S. Mitra and R. Soundararajan, “Knowledge guided semi supervised learning for quality assessment of user generated videos,” Proceedings of the AAAI Conference on Artificial Intelligence, 2024.
[2] Z. Liu, J. Ning, Y. Cao, Y. Wei, Z. Zhang, S. Lin, and H. Hu, “Video swin transformer,” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2022.
[3] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” Proceedings of the International Conference on Machine Learning (ICML), 2021.
[4] Z. Ying, M. Mandal, D. Ghadiyaram, and A. Bovik, “Patch-VQ: ‘patching up’ the video quality problem,” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[5] V. Hosu, F. Hahn, M. Jenadeleh, H. Lin, H. Men, T. SzirÅLanyi, S. Li, and D. Saupe, “The Konstanz natural video database (KoNViD-1k),” Proceedings of the 2017 Ninth International Conference on Quality of Multimedia Experience (QoMEX), 2017.
[6] Z. Sinno and A. C. Bovik, “Large-scale study of perceptual video quality,” IEEE Transactions on Image Processing, 2019.
[7] A. Tarvainen and H. Valpola, “Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results,” Proceedings of the Conference on Neural Information Processing Systems (Neurips), 2017.
[8] H. Pham, Z. Dai, Q. Xie, and Q. V. Le, “Meta pseudo labels,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2021.
[9] K. Sohn, D. Berthelot, C.-L. Li, Z. Zhang, N. Carlini, E. D. Cubuk, A. Kurakin, H. Zhang, and C. Raffel, “FixMatch: Simplifying semi-supervised learning with consistency and confidence,” Proceedings of the International Conference on Neural Information Processing Systems (NIPS), 2020.
[10] B. Li, W. Zhang, M. Tian, G. Zhai, and X. Wang, “Blindly assess quality of in-the-wild videos via qualityaware pre-training and motion perception,” IEEE Transactions on Circuits and Systems for Video Technology, 2022.
[11] H. Wu, C. Chen, J. Hou, L. Liao, A. Wang, W. Sun, Q. Yan, and W. Lin, “FAST-VQA: Efficient end-to-end video quality assessment with fragment sampling,” Proceedings of the European Conference on Computer Vision (ECCV), 2022.
[12] H. Wu, E. Zhang, L. Liao, C. Chen, J. Hou, A. Wang, W. Sun, Q. Yan, and W. Lin, “Exploring video quality assessment on user generated contents from aesthetic and technical perspectives,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
[13] W. Wen, M. Li, Y. Zhang, Y. Liao, J. Li, L. Zhang, and K. Ma, “Modular blind video quality assessment,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
[14] S. Mitra, S. Jogani, and R. Soundararajan, “Semisupervised learning of perceptual video quality by generating consistent pairwise pseudo-ranks,” IEEE Transactions on Multimedia, 2023.




