AI
Find Details in Long Videos: Tower-of-Thoughts and Self-Retrieval Augmented Generation for Video Understanding
|
IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) is an annual flagship conference organized by IEEE Signal Processing Society. And ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. It offers a comprehensive technical program presenting all the latest development in research and technology in the industry that attracts thousands of professionals. In this blog series, we are introducing our research papers at the ICASSP 2025 and here is a list of them. #4. Text-aware adapter for few-shot keyword spotting (AI Center - Seoul) #7. Find Details in Long Videos: Tower-of-Thoughts and Self-Retrieval Augmented Generation for Video Understanding (Samsung R&D Institute China-Beijing) #8. Globally Normalizing the Transducer for Streaming Speech Recognition (AI Center - Cambridge) |
1 Introduction
The Large Vision-Language Model (LVLM) has achieved impressive performance in the field of visual-language understanding. However, its ability to understand longer videos is still limited due to the length and information diversity of multi-modal videos. Moreover, accurately matching detailed content within videos remains an open research problem. We design a new framework for LVLM inference, Tower of Thoughts (ToT), which extends the “Chain-of-Thought” (CoT) approach to the visual domain and constructs the high-dimensional semantics of the complete videos from the bottom up. Meanwhile, to achieve question-answering for video details within the constraints of the restricted context window, we propose a method of self-retrieval augmented generation (SRAG), which makes it possible to obtain details from long videos by storing and accessing video text as dense vectors in non-parametric memory. The solution of combining the ToT with SRAG enables our model to have cross-modal high-density semantic fusion and comprehensive and accurate generation capabilities, thereby achieving rationalized video answers. Experiments on public benchmarks demonstrate the effectiveness of our proposed method. In addition, we also conducted experiments on multi-modal long videos in the open world and achieved remarkable outcomes. These results provide new perspectives and technical routes for the future development of visual language models.
2 Method
As shown in Figure.1, we describe our method mainly in the order of the generation process. Specifically, in the construction phase of the ToT, we obtain description sentences at different granularities of the video in a bottom-up and hierarchical manner. In the subsequent answer generation phase, we propose the method of self-retrieval augmentation. We use a retriever to search all the text in the ToT for question matching and then use a text generator to answer the input question. It is worth noting that all of our procedures do not require additional training.

Figure 1. Overview of the proposed method. Lower: The building process of the ToT. We perform detailed descriptions of dense frames through VLM and fuse various information through LLM to obtain description texts of various granularities. Upper: Process of SRAG. The final answer sentence is obtained by retrieving the content that best matches the question from all the caption texts as supplementary input.
2.1 The Construction of Multi-level Semantics: Tower of Thoughts
Consider one’s thought process when performing a complex multi-modal long video understanding task. Normally, we make sense of small pieces of each video gradually and then integrate those pieces to form a higher level of understanding. The goal of this section is to design a step-by-step reasoning process for LVLM so that the model has the ability to gradually pile up different levels of semantic information. Similar to CoT, ToT can also be interpreted as a solution, but we choose to call it the tower of thoughts to represent the bottom-up building process and how non-parametric memory is stored and used.
Establishment of Low-density semantics. In video analysis, the objects and their interactions form the foundational semantic layer. This low-level information is exactly the detailed content explored in this paper and is crucial for accurate identification. Within a non-parametric memoization framework, an extensive corpus of textual descriptions can be compiled to enrich this analysis. For a specific video V of Nf frames, the dense frame sampling technique is adopted, and the frames f={fi}i=1Nf are processed by a visual language model (VLM) to obtain the detailed captions {ci}i=1Nf of each frame. This methodology offers multiple advantages. Primarily, although VLMs are generally optimized for static images and might not directly interpret prolonged video sequences with high efficacy, they are adept at analyzing individual frames. Secondly, dense sampling ensures that subtle nuances in the video are neither missed nor misrepresented, enhancing the accuracy and depth of the video interpretation.
Semantic aggregation with an LLM. Obviously, long videos often contain multiple scenes, and we need to integrate the frame-level descriptions to get a description of coherent actions. Through the scene detection module, we cut the video into several segments of different scenes, and use LLM to integrate the frame descriptions to obtain the visual description of the video at the scene level {ci}i=1Ns1. Although there is less multimodal information in videos on public datasets, we should not ignore other modal information in long videos. In many cases in the complex open world, such as news and documentary, the audio separated from the video and the character information extracted from the keyframes will greatly help us to understand the relationship between short videos in different scenarios. We feed the scene-level visual description together with the speech and subtitle text to the LLM and let it describe the video segments to obtain the segment-level multimodal description {ci}i=1Ns2. Finally, by integrating this part of the description through LLM, we obtain a complete summary description cv of the long video which is the highest density of semantic information in the ToT. Thus we have caption statements of various granularities C={ci}i=1n, where n is the total number of description statements at all levels.
2.2 Self-Retrieval Augmented Generation for VQA
Once we have descriptions of the video at different granularities, a simple idea is to feed them all to LLM for question-answering tasks. However, due to the large text information of the ToT corresponding to long videos, the above idea cannot be realized. In addition, too many irrelevant caption sequence inputs will also affect the output results of LLM. To this end, we propose self-retrieval augmentation, which treats ToT as a retrieval document and selects the augmentation input in a RAG-Sequence manner. Specifically, the top K documents are retrieved using the retriever, and the generator generates the output sequence probability for each document, which is then marginalized.
Assume we have a question-answer pair (Q,A), where Q is the question and A is the answer. We first define a retrieval function R, which based on the keywords KQ of the question Q, retrieves the most relevant set of descriptive texts {c1,c2,⋯,ck,}.
The retrieval function can be formalized as:
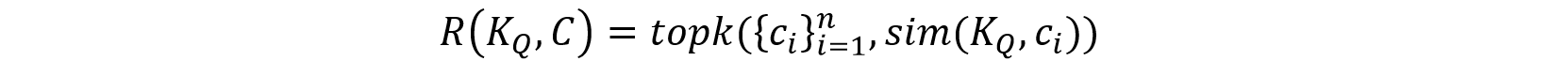
where C represents the set of all descriptive texts, and sim is a similarity measure function that assesses the relevance between the keywords of the question and each descriptive caption.
Combining the retrieved captions {c1,c2,⋯,ck,}, the RAG utilizes these captions as context to generate the answer A. The probability of generating the answer can be expressed as:

where |A| is the length of the answer, At is the t-th word in the answer, and A<t are the words before t in the answer.
3 Experiments
3.1 Performance Comparison
The experimental results of our method on the publicly available multiple-choice and open-ended VQA datasets are presented in Table 1. Compared with all other methods that do not use additional videos for training, our method achieves state-of-the-art performance on all metrics. In addition, it is worth noting that our method does not require any training process and can still outperform the pre-training process on some data sets. The slightly worse performance on MSVDQA is mainly due to the fact that most of the videos in the dataset are short videos, which mainly focus on the behavior understanding of a single scene. In this case, our dense frame sampling technology loses its advantage, and the construction of the thinking tower lacks hierarchy and diversity. In future work, it is a good idea to design a more suitable data set for long video content understanding and question answering in rich scenarios, and it is also the work we will consider extending next.

Table 1. Comparison of video QA models on public benchmarks.
3.2 Qualitative results
It is foreseeable that as video length and modal information increase, the corresponding text generated grows, making the impact of ToT-SRAG more pronounced. Current public datasets, often short and limited in modality, fail to showcase the advantages of ToT and SRAG adequately. We demonstrate this with experiments on network news videos, as depicted in Figure 2, comparing our method against video-llava for long video descriptions and question-answering tasks. Here, ToTSRAG operates without frame-level descriptions for clarity and fair comparison, utilizing video-llava for clip-level captioning. We also incorporate mistral-7b as the LLM to ensure robustness, compensating for video-llava’s lack of multi-modal input by adding ASR and OCR text data. The results reveal that video-llava’s lack of a ToT-SRAG strategy significantly hampers its performance in both tasks, underscoring that merely integrating additional modal information into a VLM does not suffice for deep multi-modal understanding of long videos. This inefficacy may stem from the VLM’s diminished linguistic capabilities post-fine-tuning, and the observed hallucinations in question-answering further support the hypothesis that a limited number of visual tokens inadequately represent comprehensive visual information.

Figure 2. A typical example of ToT-SRAG for multi-modal long video understanding on the Internet. It can be seen that on the video summary description task, our proposed method can generalize and summarize the information of video multi-modal more effectively. For the question-answering task, our method can perform retrieval queries for details such as necklaces, while also successfully retrieving things that appear multiple times.
4 Conclusion
In this work, we introduced the ”Tower of Thoughts” (ToT) framework, an extension of ”Chain-of-Thought” processing to the visual domain, which enables nuanced multi-modal comprehension by structurally parsing video data into highdimensional semantic representations. Complemented by our Self-Retrieval Augmented Generation (SRAG) method, ToT significantly improves the retrieval and synthesis of details from extended video inputs through a non-parametric memory system. Our evaluations on public benchmarks and open-world scenarios show that ToT and SRAG not only achieve deeper semantic integration across modalities but also produce precise and contextually relevant responses. Further refinement of these frameworks could advance AI-driven video analysis, enhancing interpretative and interactive capabilities for practical applications.




