AI
Unified Arbitrary-Time Video Frame Interpolation and Prediction
Introduction
The AI Vision Lab at Samsung R&D Institute China-Nanjing, with a broad mission, focuses on developing core AI vision technology to enhance user experience with Samsung devices. One of our research interests is picture quality enhancement using AI algorithms. Recently, our researchers developed the uniVIP model – a unified framework for arbitrary-time Video Interpolation and Prediction. With a single trained model, uniVIP delivers competitive results for video interpolation and outperforms existing state-of-the-art methods in video prediction. This work has been accepted by ICASSP 2025.
Video frame interpolation and prediction are long-standing tasks in computer vision. Video interpolation aims to synthesize intermediate frames between consecutive inputs, which is widely applied for video quality enhancement. Video prediction aims to synthesize frames subsequent to current ones. It often serves as a proxy task for representation learning, and can be applied in autonomous driving.
While closely related, these two tasks are traditionally studied separately. Although a few architectures can be applied for both tasks [1,2], they are not unified models, as the model weights have to be trained separately.
We ask: is it possible to train a single unified model for arbitrary-time video interpolation and prediction? We pursue this goal due to two reasons. (i) A unified model can enjoy improved generalization via multi-task learning, and reduce deployment cost in scenarios that involve both tasks. (ii) Existing video prediction methods cannot synthesize previous and subsequent frames at arbitrary time.
In this work, we introduce uniVIP, unified arbitrary-time Video Interpolation and Prediction. As shown in Fig. 1, our uniVIP can synthesize frames at arbitrary time (e.g., t = 1.4 or -0.6). By contrast, existing video interpolation methods can synthesize arbitrary-time frames between input frames but cannot go beyond; existing video prediction methods can only predict previous or future frames of integer indexes but cannot predict frames of floating indexes.
Our uniVIP achieves high accuracy for both video interpolation and prediction tasks. It provides competitive results for video interpolation, and outperforms existing state-of-the-arts for video prediction. Furthermore, uniVIP is the first model that enables arbitrary-time frame prediction.

Figure 1. Conceptual comparisons between our uniVIP and existing video interpolation and prediction models. We pursue unified modeling of both tasks to enable accurate and arbitrary-time frame synthesis with a single trained model.

Figure 2. Overview of our uniVIP at each pyramid level, within a pyramid (the pyramidal structure is ignored in this figure) recurrent framework as in UPR-Net.
Approach
Overview of UPR-Net for Frame Interpolation: Our uniVIP is built upon UPR-Net [3], a recent video interpolation model. UPR-Net iteratively refines both bi-directional flow and intermediate frame within a pyramid recurrent framework. At each pyramidal level, UPR-Net follows the standard procedure of forward-warping based interpolation: approximating the optical flow towards intermediate frame for forward warping; fusing warped input frames to synthesize the intermediate frame. In this work, without causing ambiguity, we ignore the pyramid structure of UPR-Net and our uniVIP to save space.
Designing our uniVIP Model: Fig. 2 gives an overview of uniVIP. Specifically, given I0 and I1, our goal is to synthesize It at arbitrary time: t∈[0,1] means interpolation; t<0 or t>0 means prediction. Our adaptations to UPR-Net consist of the following three steps.

Figure 3. For prediction (e.g., t = 2), positions of artifacts in warped frames are similar, but for interpolation (e.g., t = 0:5), the positions are quite different.
Training uniVIP Model on Mixed Samples: It is straightforward to train our uniVIP on mixed samples from Vimeo90K. Given triplet frames, when training for interpolation, we denote them as {I0; It; I1}, and t = 0.5 as it is the middle frame; when training for prediction, we randomly construct {It; I0; I1} with t = -1 indicating previous frame, or {I0; I1; It} with t = 2 indicating next frame.
Quantitative Results
We train uniVIP of different sizes: uniVIP-B of 1.7M parameters, and uniVIP-L of 6.6M.
Evaluation datasets: We evaluate our models on Vimeo90K, SNU-FILM, and X-TEST of 4K resolution. On Vimeo90K and SNU-FILM, we evaluate middle-frame interpolation and next-frame prediction. While for X-TEST, we use it for three purposes: multiple frame interpolation, next-frame prediction, and arbitrary-time frame prediction. We measure the peak signal-to-noise ratio (PSNR) and structure similarity (SSIM) for quantitative evaluation. For running time, we test our models with a RTX 2080 Ti GPU for interpolating 640x480 inputs.

Table 1. Comparisons results for video frame interpolation and next-frame prediction
Video frame interpolation: As shown in Table 1, uniVIP-L provides competitive results with state-of-the-art interpolation methods including RIFE-L[1], NCM-L[2], UPR-Net-L[3] and VFIformer[4]. These models (without retraining) can only perform interpolation, while our uniVIP can also handle frame prediction without retraining.
Next-frame prediction: Table 1 also shows that uniVIP-L sets new state-of-the-art on most of these benchmarks. With much less parameters than NCM (6.6M VS. 12.1M), our uniVIP-L outperforms NCM-L by a large margin.

Table 2. Comparisons results on arbitrary-time frame prediction
Arbitrary-time frame prediction: We evaluate uniVIP for arbitrary-time prediction on XTEST. As shown in Table 2, our uniVIP significantly outperforms RIFE-L and DMVFN [5], both of which can only predict frames of integer indexes.

Table 3. Comparisons on flexibility, parameters, and runtime
Flexibility, parameters and runtime: In Table 3, we compare uniVIP with RIFE and NCM on architecture, parameters and runtime, where uniVIP shows advantages in unified modeling and arbitrary-time prediction.
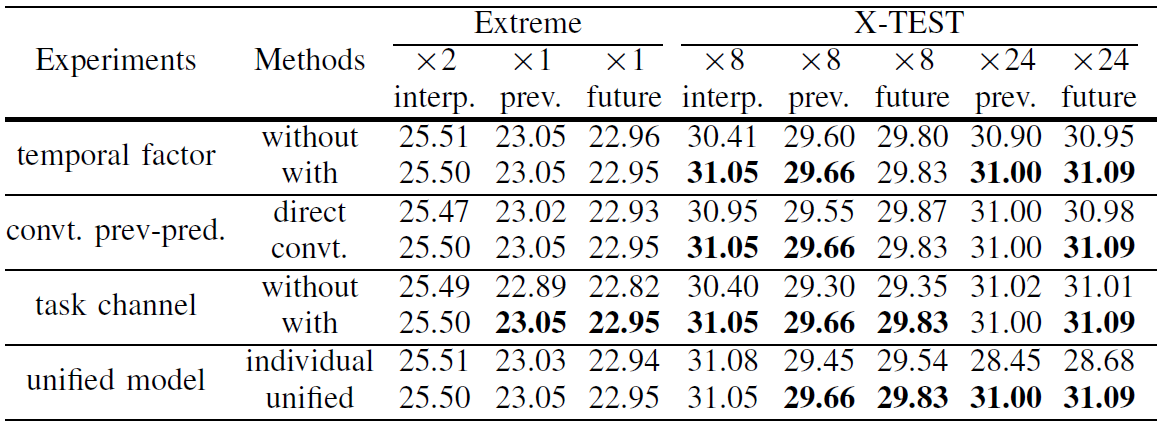
Table 4. Ablation study of our design choices
Ablation study: Table 4 verifies the design choices of our uniVIP. In particular, comapred to individually trained interpolation and prediction models, our uniVIP produces competitive results on extreme subset, and much better accuracy on X-TEST for prediction.
Qualitative Results

Figure 4. Left: examples from SNU-FILM and X-TEST for interpolation. Right: examples from SNU-FILM and X-TEST for prediction
Figure. 4 shows typical examples from SNU-FILM and X-TEST for video interpolation and prediction. Our uniVIP is robust to extreme large motion, with plausible synthesis of the regions close to image border which may suffer from serious artifacts in warped frames.
Conclusion
We presented uniVIP for arbitrary-time video interpolation and prediction. Despite its simple design, uniVIP achieved excellent accuracy for both tasks, and enabled arbitrary-time video frame prediction. In the future, we will seek to apply uniVIP on various real-life applications.
Our Paper
Xin Jin, Longhai Wu, Jie Chen, Ilhyun Cho, Cheul-hee Hahm. Unified Arbitrary-Time Video Frame Interpolation and Prediction. ICASSP. 2025.
Code and trained models: https://github.com/srcn-ivl/uniVIP
Paper link: https://arxiv.org/pdf/2503.02316
References
[1] Huang, Zhewei, et al. "Real-time intermediate flow estimation for video frame interpolation." ECCV, 2022.
[2] Jia, Zhaoyang, Yan Lu, and Houqiang Li. "Neighbor correspondence matching for flow-based video frame synthesis." ACM MM. 2022.
[3] Jin, Xin, et al. "A unified pyramid recurrent network for video frame interpolation." CVPR. 2023.
[4] Lu, Liying, et al. "Video frame interpolation with transformer." CVPR. 2022.
[5] Hu, Xiaotao, et al. "A dynamic multi-scale voxel flow network for video prediction." CVPR. 2023.




