AI
TrickVOS: A Bag of Tricks for Video Object Segmentation
Motivation
Tracking objects in a video is a foundational task in computer vision and has many practical applications, such as robotics, extended reality and content creation. Semi-supervised Video Object Segmentation (SVOS) does exactly that; given a number of masks in the first frame, SVOS aims to track the objects (indicated with the masks) across the video on a pixel-level. The pixel-level tracking makes SVOS ideal for content editing tasks, such as removing objects, applying localized filters on videos and many more.
SVOS is a notoriously hard problem, since it must be robust against occlusions, object classes, shape changes and motion. Among different SVOS approaches, space-time memory (STM) [1] based solutions are the most feasible, as they do not require per-scene tuning [2] or expensive flow calculation [3]. Despite their accuracy, there is still a significant room for improvement, both to make them faster and more accurate.
In this work, we identify three key points to improve STM-based SVOS methods; i) supervisory signal, ii) pretraining and iii) spatial-awareness. We then propose TrickVOS, a method agnostic bag of tricks that addresses these points with a i) structure-aware hybrid loss, ii) simple yet effective decoder pretraining regime and iii) a cheap tracker that filters model predictions on historical motion patterns. We show that each trick improves results on multiple benchmarks, and their combination leads to further improvements. When applied to a significantly small network, TrickVOS makes it competitive to state-of-the-art methods, and unlocks real-time performance on mobile devices.

Figure 1. TricksVOS tricks visualized. Trick 1 proposes a hybrid loss function, Trick 2 presents a simple pretraining regime and Trick 3 filters predictions via a cheap tracker with two variants, constant velocity (CV) and parametric tracker (PT).
TrickVOS
Our work consists of three contributions (e.g. tricks), each of which target different areas of improvement for SVOS performance. In short, Trick 1 is a new loss formulation, Trick 2 is a simple pretraining regime and Trick 3 is a new prediction filtering mechanism.
Trick 1 – A Better Loss Function
SVOS is a dense classification task; therefore, most methods train with a form of cross-entropy (CE) loss [4]. However, CE considers each pixel as independent, and this is not a correct assumption, as SVOS requires structural information to model appearance and shape changes. Furthermore, focusing on the foreground (e.g. objects) during training is also desirable to achieve more accurate masks.
Trick 1 augments the CE loss with two new terms; SSIM and IoU. SSIM [5] provides much needed structural information thanks to its patch-based nature. IoU [6] measures the alignment with the predicted and ground-truth masks, and thus naturally leads to foreground focus. Our loss is formulated as
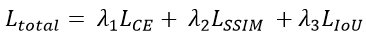
where loss weights are  . This loss is also shown to be effective in salient object detection [7], which shares similarities with SVOS.
. This loss is also shown to be effective in salient object detection [7], which shares similarities with SVOS.
Trick 2 – Decoder Pretraining
ImageNet-pretrained models are used as encoders in dense prediction tasks, as the representations learned over ImageNet are often a better initialisation for network weights. A similar initialisation for decoders are not as successful; decoders often directly produce the result and are thus tailored for different tasks, which makes their transferability less accurate.
Unlike complex approaches like self-supervised learning [8] or generative pretraining [9], Trick 2 proposes an embarrassingly simple decoder-pretraining regime; we first train a model and save the decoder weights. We then train another model with random weight initialisation (for encoders), but initialise decoder weights from the saved decoder weights. This regime avoids model overfitting and shows improvements on all datasets.
Trick 3 – Prediction Filtering
STM-based methods store previous frames in a memory bank, and then perform global feature matching between memory frames and the current frame. An inherent issue with this is that global matching leads to erroneous results when multiple objects of same appearance are present in the frame. Existing prediction filtering methods are either computationally expensive [10] or require significant architectural changes [11].
Trick 3 is built on a simple idea; we track a bounding box (per mask/object) throughout the video that encapsulates an object mask and filter out predictions outside the bounding box area. We propose two variants of Trick 3; Constant Velocity (CV) and Parametric Tracker (PT).
CV is as simple as trackers get; it is not a tracker at all! We simply assume constant velocity for objects; we calculate motion between two bounding boxes, and apply it to find the next bounding box. PT is a simple extension of CV, where we use a small MLP to predict the next bounding box. This MLP takes in the previous motion, and then predicts the current motion required to calculate the bounding box. Algorithm 1 shows a detailed breakdown of Trick 3.

Algorithm 1. Trick 3 pseudocode.
Experiments
We perform our experiments with a lightweight baseline we proposed in [12], which runs in real-time on a mobile device. This model, however, has low accuracy, which we aim to improve with TrickVOS. We refer the readers to our full paper for further details; here we present some key highlights. We leverage the commonly used metrics J&F for quantitative analyses and comparison.
Ablation Studies
We now analyse the effect of our tricks, as well as the components that form them. The results are shown in Table 1.
Trick 1 results show that both SSIM and IoU losses improve our baseline result. Their combination produces the best result on all datasets (except DAVIS’16).
Trick 2 shows the value of decoder pretraining; consistent improvements across all datasets are observed. The improvements on all datasets verify that our pretraining does not lead to overfitting.
Both Trick 3 variants show improvements, where PT is slightly better than CV, as it explicitly models the motion with an MLP network. On the other hand, it is computationally more expensive than CV.

Table 1. Ablation study J&F values for TrickVOS. CV and PT are variants of Trick 3.
An important question still remains; would using all tricks together lead to even better results? Table 1 shows that Trick 1 and Trick 2 combined beats individual tricks, and all three tricks combined (e.g. TrickVOS) produces the best results; leading up to a 3.3 point improvement on YouTube dataset.
Comparison with the State-of-the-art
Finally, we compare TrickVOS against the state-of-the-art and show the results in Table 2. CC indicates constant cost; these methods use bounded memory in their memory bank and they are our primary competitors. That is because methods with unbounded memory (non-CC) eventually run out of memory, and thus not suitable for on-device operation.

Table 2. Comparison with the state-of-the-art methods on multiple datasets. FPS values are measured on an RTX 3090 GPU.
The results show that TrickVOS makes our lightweight baseline network competitive to other constant-cost methods. Note that we are 2.5x faster and have 32x fewer parameters than RDE-VOS [13], which is the existing fastest/most compact method. We become even faster on DAVIS’17 (approximately 3x); it is a multi-object benchmark and thus is more closer to a real-life use case.
TrickVOS and Other Methods
Another advantage of TrickVOS is that it is method-agnostic; it can be used with other methods as well. We verify this by integrating TrickVOS into STCN [14], a state-of-the-art SVOS architecture. Similar to what we observed for our lightweight baseline, TrickVOS manages to improve STCN results significantly up to 2.1 J&F.
Qualitative Results
Figure 2 shows several examples of TrickVOS results. As highlighted by red boxes/arrows on the images, the baseline methods often fails to either track objects (e.g. gun in leftmost image) or produces erroneous masks (e.g. wheel and the mountain). Trick 1, Trick 2 and TrickVOS improve the results by alleviating such problems.

Figure 2. Images show results for ground-truth, baseline, Trick 1, Trick 2 and TrickVOS (top to bottom).
Conclusion
We present TrickVOS, a method-agnostic bag of tricks for improving STM-based semi-supervised video object segmentation methods. Each of our three tricks improves the results, and they work best when they are combined. TrickVOS makes a lightweight, mobile-friendly model competitive to the state-of-the-art, and also manages to improve other methods.
Link to the paper
Our paper “TrickVOS: A Bag of Tricks for Video Object Segmentation” will appear at IEEE International Conference on Image Processing (ICIP), 2023.
https://arxiv.org/abs/2306.15377References
[1] S. W. Oh, J.-Y. Lee, N. Xu and S. J. Kim, “Video object segmentation using space-time memory networks,” in ICCV, 2019.
[2] X. Li and C. C. Loy, “Video object segmentation with joint re-identification and attention-aware mask propagation,” in ECCV, 2018.
[3] Y.-H. Tsai, M.-H. Yang and M. J. Black, “Video segmentation via object flow,” in CVPR, 2016.
[4] H. K. Cheng, Y.-W. Tai and C.-K. Tang, “Rethinking space-time networks with improved memory coverage for efficient video object segmentation,” in NeurIPS, 2021.
[5] Z. Wang, E. P. Simoncelli and A. C. Bovik, “Multiscale structural similarity for image quality assessment,” in The Thirty-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, 2003.
[6] G. Mattyus, W. Luo and R. Urtasun, “Deeproadmapper: Extracting road topology from aerial images,” in ICCV, 2017.
[7] X. Qin, Z. Zhang, C. Huang, C. Gao, M. Dehghan and M. Jagersand, “Basnet: Boundary-aware salient object detection,” in CVPR, 2019.
[8] E. A. Brempong, S. Kornblith, T. Chen, N. Parmar, M. Minderer and M. Norouzi, “Denoising Pretraining for Semantic Segmentation,” in CVPR, 2022.
[9] B. Zoph, G. Ghiasi, T.-Y. Lin, Y. Cui, H. Liu, E. D. Cubuk and Q. Le, “Rethinking pre-training and self-training,” in NeurIPS, 2020.
[10] H. Xie, H. Yao, S. Zhou, S. Zhang and W. Sun, “Efficient regional memory network for video object segmentation,” in CVPR, 2021.
[11] B. Miao, M. Bennamoun, Y. Gao and A. Mian, “Region aware video object segmentation with deep motion modeling,” in arXiV, 2022.
[12] R. Miles, M. K. Yucel, B. Manganelli and A. Saa-Garriga, “MobileVOS: Real-Time Video Object Segmentation Contrastive Learning meets Knowledge Distillation,” in CVPR, 2023.
[13] M. Li, L. Hu, Z. Xiong, B. Zhang and P. a. L. D. Pan, “Recurrent dynamic embedding for video object segmentation,” in CVPR, 2022.
[14] H. K. Cheng, Y.-W. Tai and C.-K. Tang, “Rethinking space-time networks with improved memory coverage for efficient video object segmentation,” in NeurIPS, 2021.





