AI
Fixing overestimation bias in continuous reinforcement learning
Introduction
In the last few years, reinforcement learning (RL) has shown excellent results that not so long ago seemed very difficult or even impossible to achieve:
AlphaStar beats one of the world’s strongest professional StarCraft players
OpenAI five had more than 99% win rate against humans in Dota2
AlphaGo defeated Go world champion
Moreover, recent work [1] argues that RL may be a sufficient tool to achieve artificial general intelligence.
We also made our contribution to this growing and prospective field.
In RL, an agent interacts with the environment for multiple steps trying to maximize rewards which are given for the “right” actions or sequences of actions. At each step, an agent observes the current state s of the environment, takes appropriate action a, and in response gets the next state s’ from the environment and the reward r evaluating the performance of the agent. For example, a state could be the position and speed of all joints of a robot, an action — force applied to the joints, and q reward — the movement speed of the robot.
To assess its performance, an agent learns for each state-action pair an estimate Q(s, a) of how much reward it will get in the future if it takes the action a right now, and then proceeds according to its current policy. It is called Q-function (or state-action value function) and usually is modeled by a neural network. The policy is trained via differentiation through Q-function.
Q-function is usually trained to predict the sum of immediate reward and discounted Q-function in the next state, which is called Temporal Difference learning (TD learning).

Overestimation bias in reinforcement learning
Overestimation bias occurs when estimated values Qθ(s, a) are in general greater than true values Q(s, a), thus the agent overestimates the expected future rewards. Policy seeks these erroneous overestimations and exploits them. It may lead to poor policy performance and propagation of estimation errors through TD learning. Origins of overestimation bias could be described from two points of view.
Informal view.
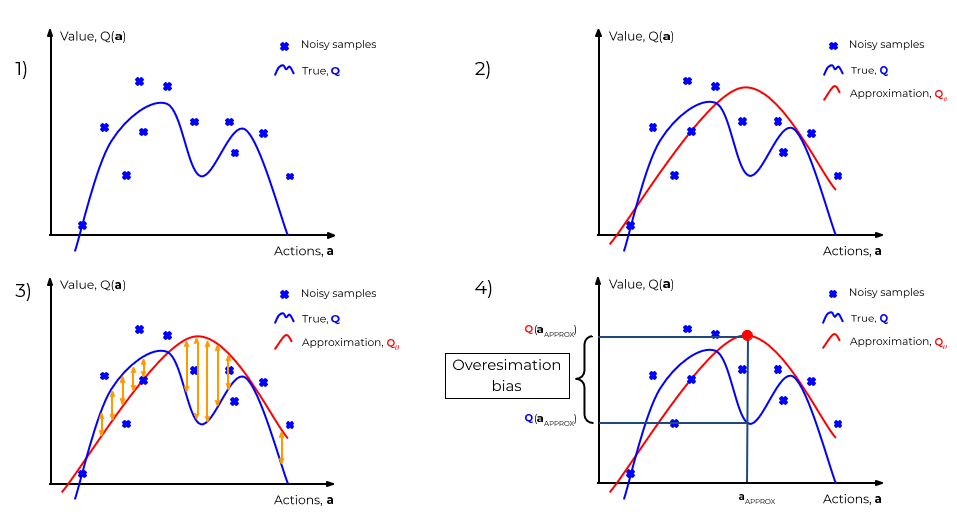
- 1) One wants to recover the true Q-values based on the stochastic samples marked by blue crosses.
- 2) Their approximation estimates the true Q-function being based on stochastic samples.
- 3) Since the optimization procedure is imprecise, approximation differs from the real Q-function.
- 4) The agent optimizes to select the action aapprox with the highest estimate. And when these estimates are erroneously high, the overestimation error occurs.
Formal view. Let us denote the difference between approximation and the true Q-function as additive noise U and assume it has zero mean. By applying Jensen inequality, we can show that maximization of the approximate Q-function leads to overestimation with respect to the true Q-function:

Controlling overestimation bias
State-of-the-art algorithms in continuous RL, such as Soft Actor Critic (SAC) [2] and Twin Delayed Deep Deterministic Policy Gradient (TD3) [3], handle these overestimations by training two Q-function approximations and using the minimum over them. This approach is called Clipped Double Q-learning [2].

- 1) One trains two approximations Qθ1 and Qθ1
- 2) Uses the minimum of these approximations as the target for training
If one approximation has a false hill in its landscape, the second approximation often will not have such an exact defect; a minimum of two will be a better estimation.
This method, however, has one serious drawback — limited flexibility. The required level of overestimation suppression may vary depending on the task, and all one can do is to change the number of networks to take the minimum of, and three networks usually work worse than two. However, one may want to get an intermediate level of overestimation control between a single network and two networks, or between two and three ones. Our method, Truncated Quantile Critics (TQC)[4], does not have this limitation.
Truncated Quantile Critics - TQC
Our work [4] proposes another way to alleviate overestimation bias. We use already known distributional critics [5]: instead of estimating an average return given state and action, a distributional critic estimates the whole distribution of returns. It does that by having multiple outputs, which model a uniform grid of quantiles of the return distribution [6]. The mixture of delta functions (atoms) in places of these quantiles model the whole distribution. The average of all atoms is used for policy optimization instead of a single Q-value.

We use N different Q-networks, each network outputs M quantiles of approximated distribution. To construct a target for TD-learning, we mix all the quantile outputs, sort them by their values, and truncate the predefined number of d atoms per network from the right tail of the resulting distribution. After that, we multiply the result by discount γ and add an immediate reward.

The idea here is, if we have an outlier network with inadequately large values, it will be trimmed, and its effect on the overall average value will be reduced. Also, outlier atoms in any of the critic networks are going to be removed from estimation. Interestingly, this procedure provides a better way to solve the overestimation bias problem than the previous one, which is demonstrated by experimental results. Moreover, the use of distributional critics boosts its performance.
Results
Ultimately, our method has several contributions to the field:
- For the first time, we incorporate the uncertainty of return into the overestimation control
- We decouple overestimation control and critics’ ensembling
- Our work ensembles distributional critics in a novel way
Our method achieves state-of-the-art results on the popular benchmark suite MuJoCo [7]. This benchmark suite consists of multiple locomotion tasks with 2D and 3D agents. Both SAC and TD3 methods have a minimum of 2 Q-functions as their overestimation alleviation technique. TrulyPPO is a variation of on-policy method PPO.

Here, a comparison of our learned agents and previous SOTA on the Humanoid-v3 environment is shown. As one can observe, 25% improvement in score translates into two times speed increase. A longer video can be viewed here.
Reinforcement learning research is as active as never before. We hope our paper encourages more work on specific problems that continuous Q-learning faces.
Link to the paper
http://proceedings.mlr.press/v119/kuznetsov20a/kuznetsov20a.pdf
Reference
[1] Silver, David, et al. "Reward Is Enough." Artificial Intelligence (2021): 103535.
[2] Fujimoto, Scott, Herke Hoof, and David Meger. "Addressing function approximation error in actor-critic methods." International Conference on Machine Learning. PMLR, 2018.
[3] Haarnoja, Tuomas, et al. "Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor." International Conference on Machine Learning. PMLR, 2018.
[4] Kuznetsov, Arsenii, et al. "Controlling overestimation bias with truncated mixture of continuous distributional quantile critics." International Conference on Machine Learning. PMLR, 2020.
[5] Bellemare, Marc G., Will Dabney, and Rémi Munos. "A distributional perspective on reinforcement learning." International Conference on Machine Learning. PMLR, 2017.
[6] Dabney, Will, et al. "Distributional reinforcement learning with quantile regression." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.
[7] Todorov, Emanuel, Tom Erez, and Yuval Tassa. "MuJoCo: A physics engine for model-based control." 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2012.





