AI
Enhancing Noise Resilience in Face Clustering via Sparse Differential Transformer
1 Introduction
The method used to measure relationships between face embeddings plays a crucial role in determining the performance of face clustering. Existing methods employ the Jaccard similarity coefficient instead of the cosine distance to enhance the measurement accuracy. However, these methods introduce too many irrelevant nodes, producing Jaccard coefficients with limited discriminative power and adversely affecting clustering performance. As shown in Figure 1, the Jaccard similarity coefficients computed by FC-ESER [1] for different faces are very close, which introduces challenges to discriminative face identification. To address this issue, we propose a prediction-driven Top-K Jaccard similarity coefficient that enhances the purity of neighboring nodes, thereby improving the reliability of similarity measurements. Nevertheless, accurately predicting the optimal number of neighbors (Top-K) remains challenging, leading to suboptimal clustering results. To overcome this limitation, we develop a Transformer-based prediction model that examines the relationships between the central node and its neighboring nodes near the Top-K to further enhance the reliability of similarity estimation. However, vanilla Transformer, when applied to predict relationships between nodes, often introduces noise due to their overemphasis on irrelevant feature relationships. To address these challenges, we propose a Sparse Differential Transformer (SDT), instead of the vanilla Transformer, to eliminate noise and enhance the model's anti-noise capabilities. Extensive experiments on multiple datasets, such as MS-Celeb-1M, demonstrate that our approach achieves state-of-the-art (SOTA) performance, outperforming existing methods and providing a more robust solution for face clustering. As shown in Figure 1, our method captures facial similarity more accurately than FC-ESER.

Figure 1. The facial similarity score with different methods.
2 Method
The framework of our face clustering method as shown in Figure 2. Similar to existing methods [1], we first construct a face graph. Subsequently, we employ a Transformer-based Adaptive Neighbor Discovery strategy to predict neighboring boundaries Top-K. Then we use the Top-K to refine the face graph. Due to the inherent inaccuracy of the predicted Top-K, noise nodes are inevitably retained. Therefore, we utilize a neural network (Sparse Differential Transformer) to alleviate the impact of noise nodes. Finally, we employ the Map Equation [1-2] method to perform face clustering.
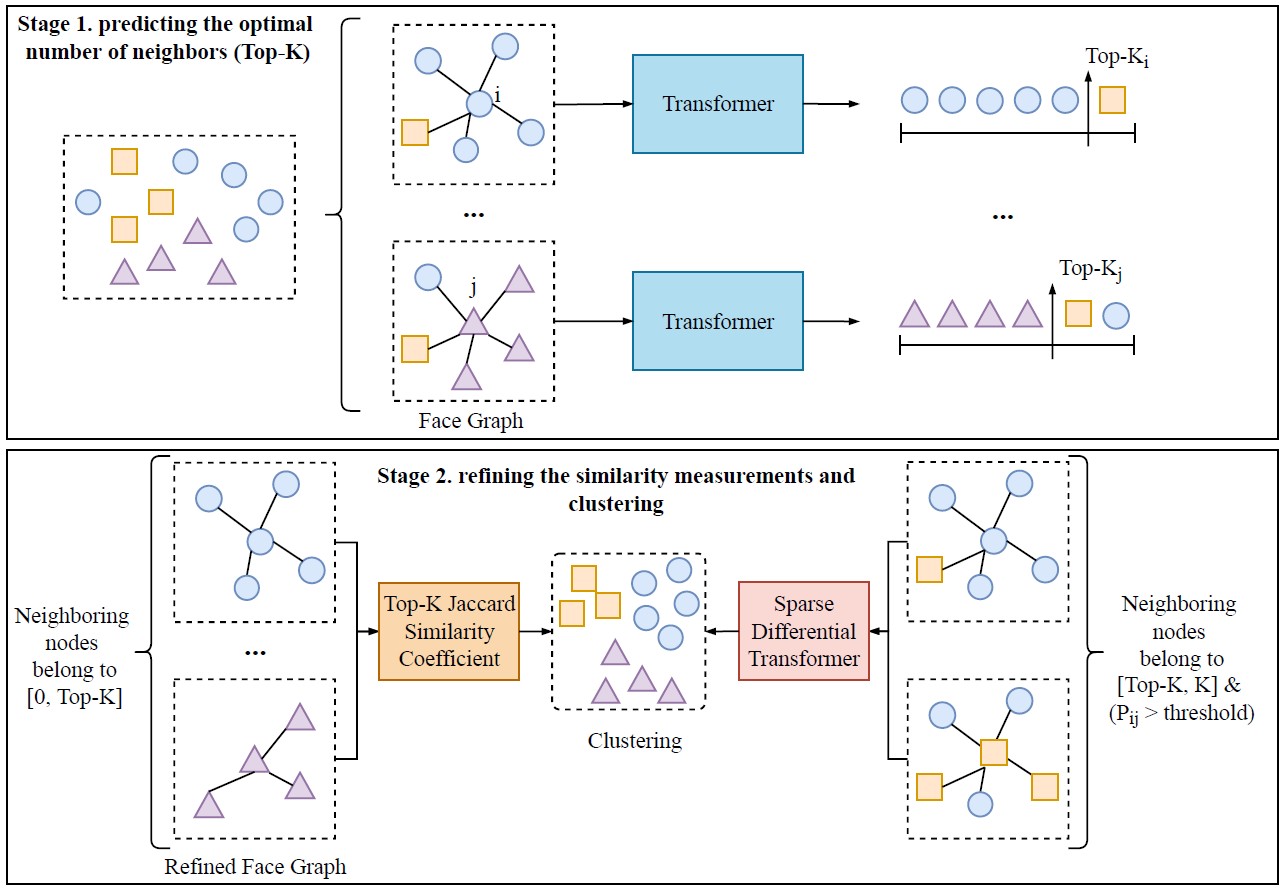
Figure 2. The framework and network architecture of our face clustering method.
2.1 Top-K Jaccard Similarity Coefficient
Given a set of $N$ face images, we extract face features $f_i∈R^d$ for each image $i = 1, 2, … , N,$ where $\$d\$$ is the dimension of the face features.
For each sample $i$, we calculate the cosine similarity between $f_i$ and all other features $f_j$ as $a_{ij}=\frac{(f_i∙f_j)}{‖f_i ‖‖f_j‖}$, and then select the K nearest neighbors of $f_i$ based on the sorted cosine similarity values to construct the similarity matrix $S∈R^{N×K}$ and adjacency matrix $N∈R^{N×K}$.
Simple distance metrics, such as cosine similarity, may not fully capture the complex relationships between faces.
Inspired by Ada-NETS [3] and FC-ESER [1], we use the Jaccard similarity coefficient to measure the similarity between two samples in the face graph.
Let $N_i$ and $N_j$ be the sets of k nearest neighbors of two face samples $i$ and $j$ respectively.
In Ada-NETS, the Jaccard similarity coefficient $J(N_i,N_j)$ between $i$ and $j$ is defined as: $J{N_i,N_j}=\frac{|N_i⋂N_j|}{|N_i⋃N_j|}$.
FC-ESER improves the Jaccard similarity coefficient and redefines it as neighbor-based edge probability
$\widetilde{p_{ij}}=J(N_i,N_j )=\frac{∑_{h_{ij}∈M_{ij}}(\widehat{p_{ih}}+\widehat{p_{hj}})}{∑_{h_i∈N_i}\widehat{p_{ih}}+∑_{h_j∈N_j}\widehat{p_{hj}}}$.
where $M_{ij}=N_i⋂N_j$ is the intersection of $N_i$ and $N_j$.
$h_{ij}$ represents the common neighbors of samples $i$ and $j$.
$h_i$ and $h_j$ represent neighbors of samples $i$ and $j$, respectively.
$\hat{p}$ is the edge probability between $i$ and $j$ that defined in FC-ESER as:
$d_{ij}=2-2*a_{ij},\space\space\space p_{ij}=e^{-\frac{d_{ij}}{τ}}, \space\space\space \widehat{p_{ij}}=\frac{p_{ij}}{s_i}$
where $a_{ij}$ is the cosine similarity between $f_i$ and $f_j$, $τ$is a temperature parameter. However, $p_{ij}=e^{-\frac{d_{ij}}{τ}}$ has a critical flaw, it reduces the similarity between two face features, leading to two significant issues: 1) Faces belonging to the same identity are fragmented into multiple subclusters (reducing recall). 2) The differences in Jaccard similarity coefficients are diminished, causing different identities to be clustered together (reducing precision). In addition, Ada-NETS and FC-ESER introduce a large number of irrelevant samples when calculating the Jaccard similarity coefficient, which also results in the Jaccard similarity coefficients between different identity samples being very close. To address first problem, we redefine the distance transform function as $P_{ij}=\frac{1}{1+e^{7.5d_{ij}-5}}$. The sigmoid-like function used in our formula helps to amplify small differences in the original distance, making it easier to distinguish between similar and dissimilar face images. To address the second issue, we refine the Jaccard similarity formula based on an adaptive neighbor discovery strategy. Specifically, we employ the adaptive filter to predict the optimal number of neighbors, denoted as Top-K. When calculating the Jaccard similarity coefficient, we consider only the samples preceding Top-K to reduce the number of irrelevant samples. Therefore, the neighbor-based edge probability is redefined as:
$\widetilde{p_{ij}}=\frac{∑_{h_{ij}∈M_{ij}^{ki}}(\widehat{p_{ih}}+\widehat{p_{hj}})}{∑_{h_i∈ N_i^{ki}}\widehat{p_{ih}}+∑_{h_j∈N_j^{ki}}\widehat{p_{hj}}}$
2.2 Sparse Differential Transformer
The predicted Top-K near its optimal number of neighbors, which may either omit relevant nodes or introduce irrelevant ones. This necessitates a thorough examination of the relationships between the central node and its neighboring nodes near the Top-K. To address this problem, we develop a Transformer-based model to predict these relationships in this paper. We propose the Sparse Differential Transformer (SDT). Our SDT model applies a sparsity constraint to the attention mechanism, ensuring that only the most relevant nodes are attended to, while irrelevant or noisy relationships are ignored. The sparsification process is implemented through Top-k selection, where we utilize the predicted Top-K as the threshold.
$[Q_1,Q_2]=xW_Q,[K_1,K_2]=xW_K,V=xW_V$
$F_{att}=(S(M((\frac{Q_1 K_1^T}{\sqrt{d}})-λS(M((\frac{Q_2 K_2^T}{\sqrt{d}}))V$
where $M$ denotes the Top-K Attention Mask, $S$ is the softmax function, $λ$ is a learnable scalar.
3 Results
Table 1 presents a comprehensive comparison of face clustering performance on the MS1M dataset. Our method achieves SOTA results across all tested scales of data (584K to 5.21M), highlighting the effectiveness of the proposed Sparse Differential Transformer (SDT). Traditional clustering algorithms such as K-Means, HAC, and DBSCAN exhibit significant performance degradation as the dataset scale increases. GCN-based methods like L-GCN and GCN(V+E) show improved robustness but still suffer from noise edges caused by fixed kNN graphs, which propagate erroneous features during message passing. Our adaptive neighbor discovery strategy alleviates this issue, maintaining high performance with only a minor drop (from $F_P$=95.46 at 584K to 90.08 at 5.21M). Transformer-based methods such as Clusformer and LCEPCE better capture long-range dependencies but are prone to attention noise. In contrast, our SDT employs a Top-K sparse differential attention mechanism that selectively emphasizes relevant nodes while masking irrelevant ones, effectively reducing noise interference.
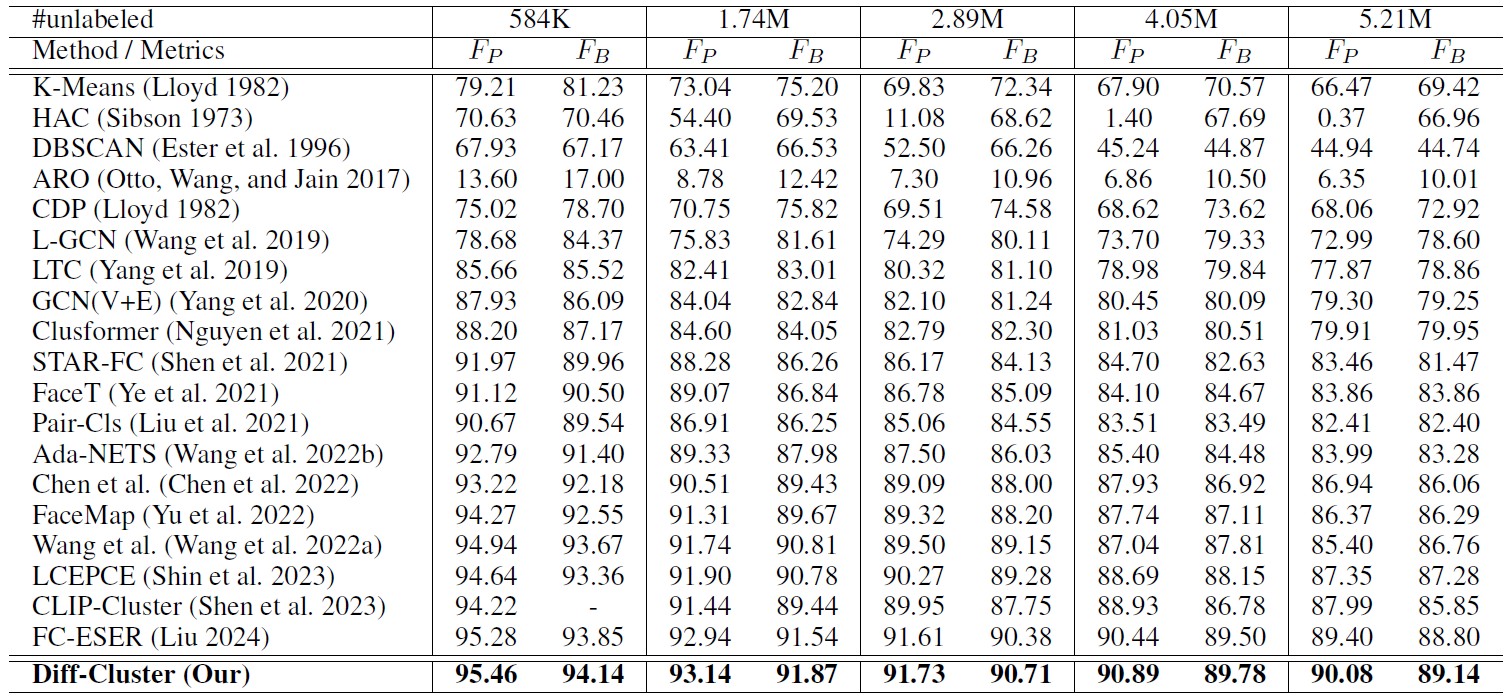
Table 1. Comparison on face clustering when training with 0.5M face images and testing with different numbers of unlabeled face images. All results are obtained on the MS1M dataset. The proposed SDT consistently outperforms other face clustering baselines on different scale of testing data
4 Conclusion
In this paper, we proposed a novel face clustering framework that enhances noise resilience and neighbor prediction accuracy in graph-based clustering. Traditional kNN-based methods often suffer from noise edges, leading to unreliable clusters. To address this, we introduced the Top-K Jaccard Similarity Coefficient to refine face similarity measurement and designed a neural predictor to adaptively estimate optimal neighbor relationships. Furthermore, the proposed Sparse Differential Transformer (SDT) employs a Top-K sparse attention mechanism to suppress irrelevant feature dependencies and strengthen anti-noise capability. Extensive experiments on MS1M, DeepFashion, and MSMT17 confirm that our approach consistently outperforms state-of-the-art methods in both accuracy and robustness. Overall, the integration of adaptive neighbor discovery, enhanced distance metrics, and noise-resilient attention enables a scalable and generalizable clustering solution across face and non-face domains.
References
[1] Liu J. Face Clustering via Early Stopping and Edge Recall[J]. arXiv preprint arXiv:2408.13431, 2024.
[2] Rosvall M, Axelsson D, Bergstrom C T. The map equation[J]. The European Physical Journal Special Topics, 2009, 178(1): 13-23.
[3] Wang Y, Zhang Y, Zhang F, et al. Ada-nets: Face clustering via adaptive neighbour discovery in the structure space[J]. arXiv preprint arXiv:2202.03800, 2022.