AI
A Reinforcement Learning-Based Rate Control for Neural Video Compression
1 Introduction
Past years have witnessed the explosive growth of end-to-end neural video compression (NVC) approaches. Benefiting from the powerful nonlinear modeling capability of deep neural networks (DNN) and end-to-end optimization with extensive training data, the compression performance of the latest NVC solutions has surpassed that of traditional standards. However, only a handful of attempts have investigated the rate control of NVC even though efficient and effective rate control is crucial for the successful adoption of video codecs in real-life applications.
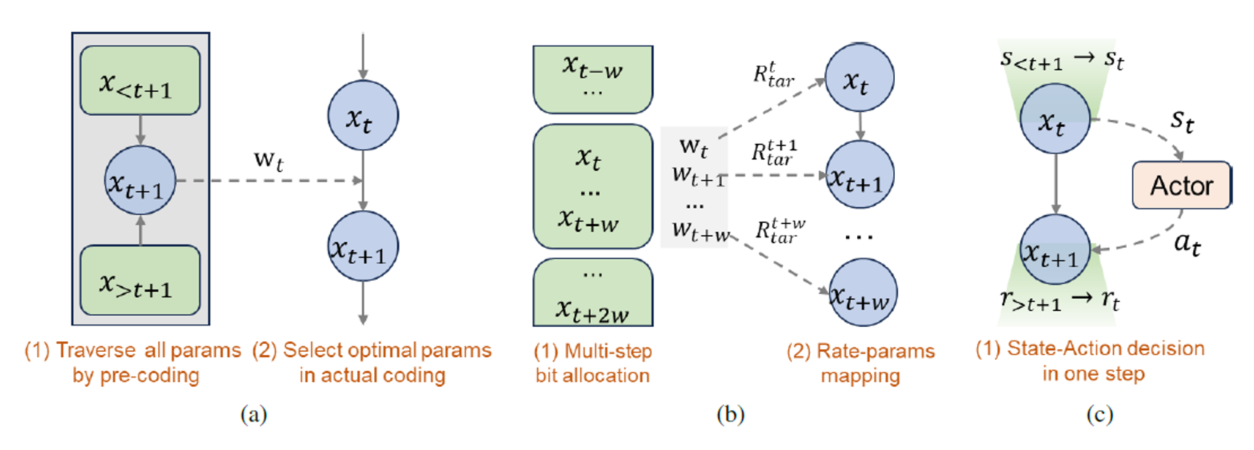
Figure 1. Illustration of different rate control paradigms.
(a) Brute-force global searching, (b) Local approximated solution
Our contributions can be summarized as follows: 1. We redefine NVC rate control as a sequential decision-making process (Sec. 3), addressing the shortcomings of temporal stationarity, enabling global reference independent of coding unit length, and achieving joint optimization without the need for a two-step approach. 2. We develop a dedicated Actor-Critic RL framework for NVC (Sec. 4), incorporating spatial-temporal state modeling, encouraging exploratory action sampling, and a joint quality-accuracy reward function to align with the unique characteristics of NVC.3. We extensively evaluate our method across multiple NVC architectures (Sec. 5), demonstrating state-of-the-art results, including an average -15.96% BD-Rate gains with only 1.30% rate errors and 19.7% encoding time savings. Our approach is more robust to content variations and rate fluctuations than existing methods.
2 Method
Whether based on handcrafted principles or neural networks, focus primarily on modeling the relationship between rate and distortion related coding parameters in NVC, such as the R-λ model (Zhang et al., 2023) and the R-D-λ hyperbolic model (Chen et al., 2023). These model-based methods approximate global rate control (RC) by reducing it to a manageable local optimization process (see Fig. 1b). To further analyze this simplification, we formalize the underlying assumptions behind them. To further analyze this simplification, we formalize the underlying assumptions behind them.
Assumption 1 (Temporal Stationarity). Given a video sequence X divided into multiple temporal coding windows3, each window W is assumed to exhibit similar content variance, leading to a uniform allocation of bitrate across windows.
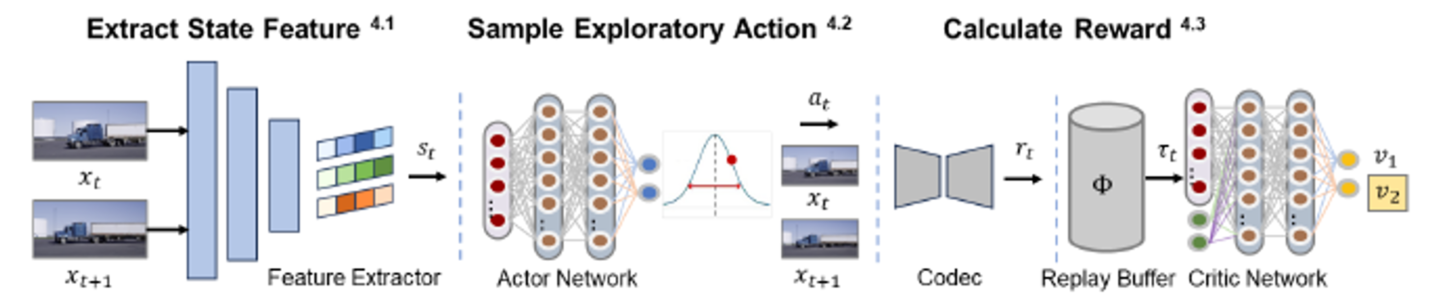
Assumption 2 (Sequential Decision-Making Rate Control). Given a frame xt, the coding parameters at are determined by a rate control policy π(at | st), where: (i) The current coding state st follows a Markov process, summarizing the past encoded frames’ states s Figure 2. Training pipeline of our Actor-Critic network for RC. The entire process consists of three main components, from state to action and then to reward in sequence
Building on the limitations identified earlier, we argue that an effective and practical RC methodology for NVC should meet three essential criteria:
1. Window Size-Independent Complexity: The solution complexity should be independent of the number of frames within a window, ensuring scalability and applicability across arbitrary window sizes in real-world scenarios.
2. Global Information Awareness: The RC mechanism should incorporate global contextual information to mitigate error propagation and maintain stable coding quality throughout the sequence.
3. Unified Modeling: The approach should avoid decoupling, enabling end-to-end optimization to achieve globally optimal solutions and practical scalability. These criteria inherently bypass the need for the temporal stationarity assumption, addressing the issues associated with existing methods. Inspired by the success of RL in sequential decision processes, we leverage RL to formulate the RC for NVC as a sequential decision-making process (see Fig. 1c).
During inference, only the Actor is employed, enabling one-step decisions for coding parameters based on the current state. This streamlined process contrasts with existing methods, which involve a two-step process: initial bitrate allocation followed by coding parameter derivation. By integrating decision-making into a single step, our approach improves practicality and reduces decision latency.
State representation plays a pivotal role in policy learning, where π(at|st) determines the coding parameters (action) based on the current state. Traditional approaches (Chen et al., 2018; Zhou et al., 2020) typically model state representations using simple statistical metrics (e.g., mean or
variance of temporal content). However, such handcrafted features fail to effectively capture the complex coding state in NVC, which involves high-dimensional features and nonlinear transformations.
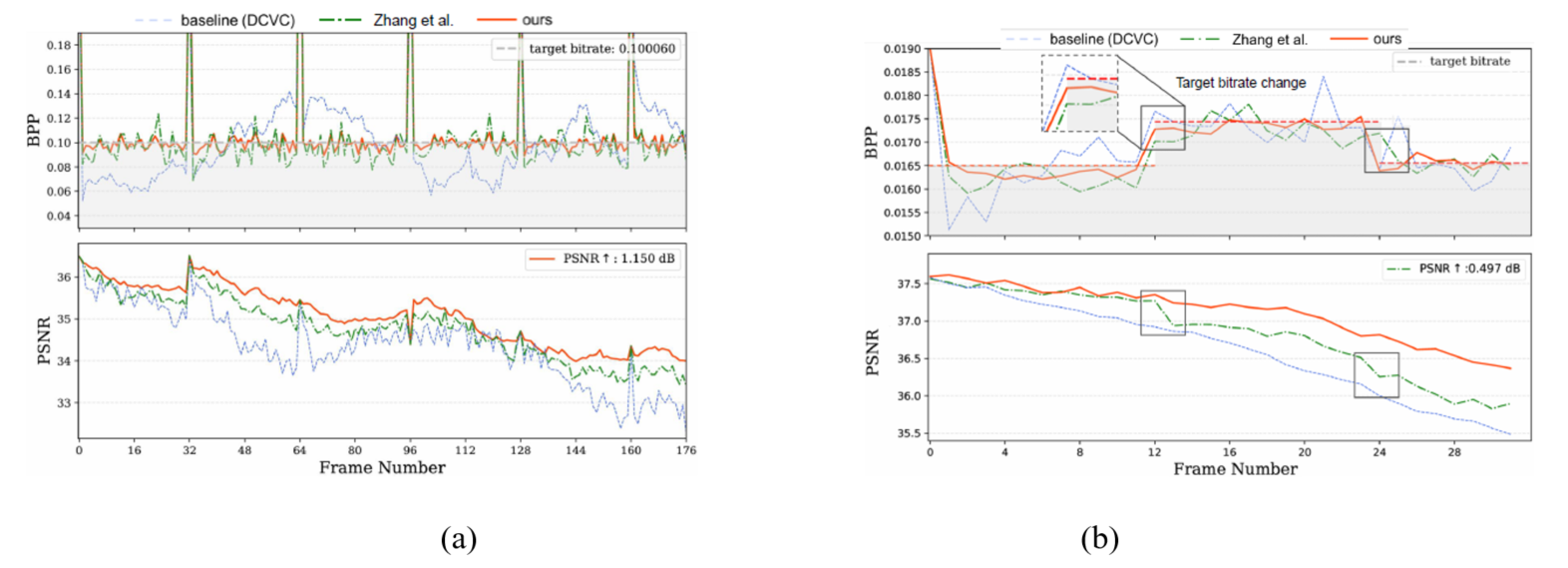
Figure 3. (a)Per-frame rate control visualization with a unified target bitrate 0.100006 BPP on BasketballDrive sequence, (b) Per-frame rate control visualization with a varying target bitrate 0.0163→0.0173→0.0166 BPP on Johnny sequence. The rate changes every 0.5 seconds
To address this limitation, we formulate the state as a learnable embedding conditioned on both the frame to be encoded and the encoded results of the previous frame. Specifically: As illustrated in Fig. 2, the current frame xt and the reference frame xt−1 are concatenated and processed through a cascaded residual network for feature extraction. Then several convolutional layers and average pooling operations refine the extracted spatial-temporal embedding. Additionally, auxiliary information such as the target bitrate and previous coding parameters is normalized, expanded, and embedded. These embeddings are concatenated to form a comprehensive state representation.
For inference, a greedy strategy selects the action with the highest probability. Additionally, mt may induce resolution differences. In such cases: The reference frame is resampled to match the current frame’s resolution, ensuring proper inter-frame prediction. Finally, the reconstructed frame undergoes bicubic upsampling to restore its original resolution for display or future reference. This joint λ-m action policy achieves precise rate control while accelerating the coding process by reducing computational complexity due to lower resolutions.
Base Codecs: We evaluate our method on three representative NVCs: DVC (Lu et al., 2019), DCVC (Li et al., 2021), and DCVC-DC (Li et al., 2023). The models are refined using their original training configurations. For training, we construct a mixed dataset combining BVI-DVC (Ma et al., 2021).
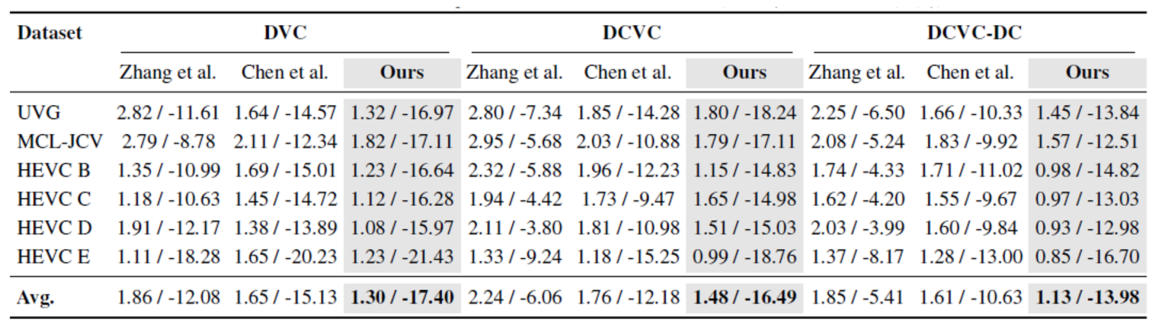
Table 1. Performance comparison with other methods(∆R↓BD-Rate(%)t
RC Benchmarks: We compare our approach against two state-of-the-art RC methods: (i) Chen et al. (2023) models the relationships (R-λ-m, D-λ-m) using a mathematically hyperbolic function with online updates. (ii) Zhang et al. (2023) uses a neural network to predict and adjust the R-λ mapping dynamically. For a fair comparison, we use raw
experimental data from their original papers. Some additional results are based on our faithful implementations due to unavailable sources.
Performance Analysis: As shown in Table 1, our proposed RC method demonstrates superior performance in both R-D performance and rate control accuracy. Even when applied to DCVC-DC—one of the most advanced NVC with complex inter-frame reference mechanism—our
approach achieves an average BD-Rate gain of -13.98% with a rate error of just 1.13%. These results validate the effectiveness of our RL-based sequential decision framework, which efficiently captures global dependencies and enables unified rate control modeling. To further analyze the effectiveness of proposed rate control strategy, we visualize per-frame performance and compare it with existing RC method (Zhang et al., 2023) as well as the baseline DCVC.
Complexity Analysis: We compare the computational complexity of our RC method with existing approaches (Li et al., 2022; Zhang et al., 2023; Chen et al., 2023), using DCVC as the baseline. The complexity metrics considered include network Parameter count (M), KMACs per pixel, Memory usage (G) and Encoding/ Decoding time (s). Each method is tested 10 times, and the average results are presented in Table 2. Our method uses a lighter network and down sampling factors, reducing computational cost. As a result, encoding and decoding times decrease by 19.7% and 26.5%, respectively. These results highlight the efficiency of our approach, making it a promising solution for real-time NVC applications while maintaining superior performance.
Despite the accepted benefits of more extensive reference, existing model-based RC paradigms struggle due to exponential complexity. In this work, we propose an RL-based RC method for NVC. Our key insight is to formulate RC as a sequential decision-making problem, allowing efficient global references with linear complexity. Through theoretical analysis and a dedicated RL network design, we establish the state-of-the-art RC for NVC while significantly improving
inference efficiency, making our approach a highly promising solution for real-time NVC applications. Future work can focus on jointly optimizing the coding model and the rate control module to achieve more adaptive rate control and superior R-D performance.
[1] Alibrahim, H. and Ludwig, S. A. Hyperparameter optimization: Comparing genetic algorithm against grid search and bayesian optimization. In 2021 IEEE Congress on Evolutionary Computation (CEC), pp. 1551–1559. IEEE, 2021.
[2] An, R., Li, Y., He, X., Gu, P., Zhao, M., Li, D., Hao, J., Wang, C., An, B., and Zhou, M. Improving unsupervised hierarchical representation with reinforcement learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 22946–22956, 2024.
2.2 Sequential Decision-Making RC
2.3 Actor-Critic Network for RC
3 Results
3.1 Experimental Setup
3.2 Experimental Results
4 Conclusion
References





